




导读
进入年底,系统运维中的“安全问题”再次成为焦点。每年这个阶段,随着业务冲刺、系统扩容与变更频繁,运维压力陡增,操作风险也随之攀升。稍有不慎,就可能引发严重事故——从核心表被误删,到关键配置被覆盖,甚至造成长时间业务中断。
为此,我们邀请到云和恩墨联合创始人、资深数据库技术专家杨廷琨带来一场主题分享《数据库日常运维中的不可回退操作》
本文整理自直播分享,部分语句在不改变原意的基础上做了更改。
演讲资料:https://www.modb.pro/doc/147598
视频回放:https://www.modb.pro/video/10758

杨廷琨
云和恩墨联合创始人、资深数据库技术专家
ACOUG核心专家,高级咨询顾问,称"杨长老";数年如一日坚持进行Oracle技术研究与写作,号称"Oracle的百科全书",在自己的博客上累计发表了超过3000篇文章。
为什么说 DDL 操作无法回滚?
在日常数据库维护中,DBA 几乎每天都要与各种结构调整打交道:建表、加列、删字段、改索引、甚至调整参数。然而,很多人忽视了一个关键事实——并不是所有操作都能回滚。有些命令一旦下达,就意味着“没有回头路”。
Oracle 的设计理念里,DDL 操作属于数据定义语言,它修改的对象是数据字典(Data Dictionary),也就是数据库的“元数据”。
为了确保数据字典的安全和一致性,Oracle 在执行 DDL 时会自动做两件事:
- 操作前自动执行一次 commit;
- 操作完成后再次自动执行 commit。
这意味着 DDL 操作是原子且立即生效的,没有回滚空间。哪怕你中途发现命令写错,按下 Ctrl+C、强制终止,之前的事务也已经被隐式提交。
简单来说,Oracle 为了保证系统的完整性,牺牲了 DDL 的可逆性。这就是为什么我们常说:“DDL 没有后悔药”。
那些不可撤销的操作
以下几类操作在日常中最容易引发严重后果。看似简单,却可能让数据库陷入长时间回滚、锁等待,甚至“瘫痪”。

图1:不可撤销的操作
1、DROP 类操作 —— 对象彻底删除
DROP用于删除数据库对象,执行后对象及其内容会永久丢失。
| 命令 | 说明 |
|---|---|
| DROP TABLE PURGE | 删除表并绕过回收站(Recycle Bin),无法通过 FLASHBACK 恢复 |
| DROP DATABASE | 删除整个数据库,包括所有数据文件、控制文件和日志文件 |
| DROP PLUGGABLE DATABASE | 删除可插拔数据库(PDB),数据文件被直接移除 |
2、TRUNCATE 类操作 —— 快速清空数据
TRUNCATE用于清空表或簇(cluster)中的所有记录,但保留结构定义。
| 命令 | 说明 |
|---|---|
TRUNCATE TABLE |
清空指定表的所有数据 |
TRUNCATE CLUSTER |
清空一个数据簇中的所有表内容 |
3、ALTER 类操作 —— 修改结构定义
ALTER系列命令用于修改对象定义(如表、索引、用户等),但部分操作具有不可逆的后果。
| 命令 | 说明 |
|---|---|
ALTER TABLE SET UNUSED COLUMN |
将列标记为“未使用”,无法直接恢复显示,只能彻底删除 |
ALTER TABLE DROP COLUMN CHECKPOINT n |
删除表列并分阶段提交,若中断可能导致结构不一致 |
ALTER INDEX REBUILD ONLINE |
在线重建索引,若异常中断可能导致索引不可用 |
ALTER USER ENABLE EDITIONS |
启用版本控制后不可禁用,需重新创建用户;启用版本功能后,该用户无法关闭该功能,除非重建用户。 |
4、OTHER 类操作 —— 特殊系统行为
除了常见的结构性 DDL,还有一些特殊命令同样具备不可撤销特性。
| 命令 | 说明 |
|---|---|
ALTER SYSTEM SET COMPATIBLE |
修改数据库兼容性版本号,一旦升高不可降低;修改数据库兼容性版本号,一旦升高不可降低,除非使用downgrade流程。 |
KILL SESSION |
强制终止会话,若事务未提交,会导致长时间回滚甚至系统性能下降;强制中止会话前,需要评估该会话未提交事务大小,如果是大事务,可能会导致长时间回滚、系统性能下降等问题 |
案例分享
为了更直观地理解风险来源,我们不妨从几个实际案例出发,看看当这些命令在生产环境中被误用时,会带来什么样的连锁反应。
案例一:删除字段引发的连锁反应
在一次客户系统维护中,DBA 打算删除大表中的一个废弃字段。为了避免 undo 空间不足,他在语句中加上了 checkpoint参数,以为能“稳妥”一点。


图2-3:问题模拟重现
结果却事与愿违,删除操作持续了很久,期间大量业务 DML 被阻塞。当那位技术人员试图中止操作时,系统立刻陷入更严重的锁等待。几分钟后,几乎所有业务查询都卡死。
背后的原因很典型:
加上 checkpoint后,操作不再是一个原子事务,而是分段提交。此时再去终止,等于把结构修改停在半路上,数据字典与表数据之间出现不一致。
更安全的做法是:
- 使用
ALTER TABLE SET UNUSED暂时弃用字段,而非直接删除; - 或采用 Oracle 提供的 在线重定义(DBMS_REDEFINITION),在不影响业务的情况下完成结构调整。
想了解完整案例细节,可在视频 00:15:00 处观看讲解。
案例二:长事务的“回滚地狱”
如果说前一个案例体现了对结构性操作风险的误判,那么接下来这个案例,则揭示了在事务层面上“终止即灾难”的隐患。
某金融行业客户在日常批处理任务中,因程序逻辑错误,在同一事务中误插入了上千万条重复数据。这个事务持续运行了一整天,直到 DBA 发现数据库 I/O 异常、表空间迅速膨胀后,才意识到问题的严重性。
出于紧急止损的考虑,DBA 选择了直接执行 KILL SESSION 来中止事务。然而,这一操作并没有立刻释放资源,反而引发了新的问题——
- 数据库进入长时间回滚状态;
- 涉及表被锁定,其他业务会话全部阻塞;
- 整个系统近乎冻结,业务全面中断。
根因在于:事务回滚的成本与执行时间几乎等量级。换句话说,一个运行了 8 小时的事务,系统可能也需要 8 小时甚至更久来完成回滚。数据库在撤销过程中需逐条回退已执行的 DML 操作,占用大量 undo 空间与资源。若此时强制中断或重启,将触发后台的回滚,如果有并发的修改或DDL则进一步导致数据字典锁死,导致并发访问被锁定,甚至引发数据库级别的事故。
遇到类似问题时,盲目“Kill”往往只会加剧风险。正确做法是先评估事务规模与影响。例如:
- 事前防御——大事务检查:通过监控 vtransaction、vsession_longops 等视图,定期发现运行时间长、undo 占用高的事务,提前预警,避免问题扩大。
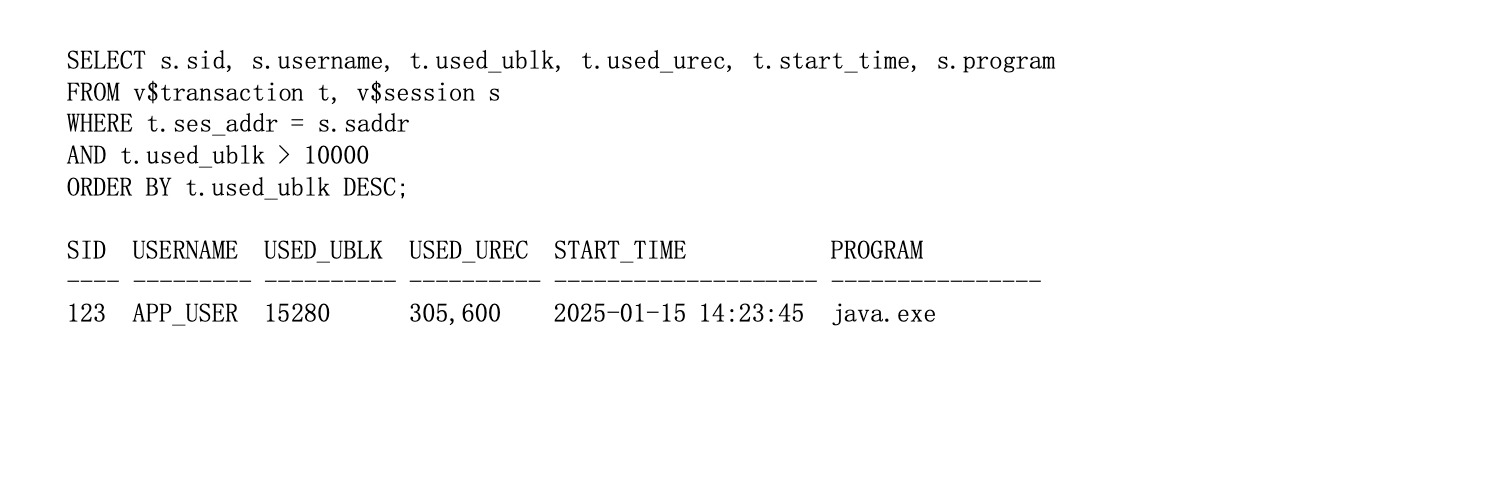
图3:大事务检查
- 事中诊断——死事务检查
当系统出现卡顿或回滚异常时,检查是否存在死锁或死事务,确认问题源头,防止误重启或误杀。 修改为:当出现死事务时,可以通过如下的方法来评估回滚所需的时间。

图4:死事务检查
- 事后加速——回滚优化
如果确实碰到回滚大事务时间过长,可以通过设置隐含参数:_cleanup_rollback_entries来加速回滚。

图5:加速回滚
想了解完整案例细节,可在视频 00:33:10 处观看讲解。
案例三:ONLINE REBUILD中止
某运营商系统在进行索引分区维护时,操作人员忘记加上 ONLINE 关键字。结果,DDL 操作直接锁表,所有业务 DML 请求被阻塞。
面对突发业务中断,管理员急于恢复,选择了强制终止 session。然而,这一“止损”操作却带来了更大的损失——部分索引分区被标记为 UNUSABLE,导致查询与写入全面失败,系统瞬间瘫痪。
这类问题在旧版本数据库(尤其是 12c 以前)中尤为常见。虽然新版本在 DDL 并发与在线修改方面已有显著改进,但仍需格外谨慎。
- 在执行任何在线结构操作前,应当:
- 确认操作关键字与参数(如 ONLINE、PARALLEL 等);
- 评估对象依赖关系与锁风险;
- 在中断或异常后,及时验证对象状态,例如:
SELECT index_name, status FROM dba_indexes WHERE table_name = 'XXX';
任何被标记为 UNUSABLE 的索引,都必须尽快重建,以恢复数据访问能力。
想了解完整案例细节,可在视频 00:43:45 处观看讲解。
规避方法
经过以上几个案例可以看到,数据库的高危操作往往并非源于技术难度,而是源于“习惯性风险”——错误的经验、自以为稳妥的操作方式、以及对机制的不充分理解。
以下几点实践经验,值得每一位 DBA 和运维人员参考:

图6:规避方法
数据库的每一次 DDL,看似只是几行命令,其实背后连接着整个系统的安全。DDL 的不可撤销,是 Oracle 的设计选择,而“有备无患”,是每一位 DBA 应该养成的职业习惯。
以上就是我今天的所有分享内容,谢谢大家!
