




索引碎片:性能下降的隐形杀手
当数据库表频繁经历插入、更新和删除操作时,索引这个本应加速查询的"引擎"会逐渐变得低效。想象一下,原本整齐排列的B树索引结构,在无数次数据修改后,叶子节点的物理顺序与逻辑顺序严重脱节,就像一本页码混乱的字典——这就是索引碎片。根据Microsoft Learn的定义,碎片会导致查询需要更多随机I/O操作,在高并发场景下,一个严重碎片化的索引可能使查询性能下降50%以上。
碎片的双重面孔:内部与外部碎片
索引碎片主要分为两种类型。内部碎片是指索引页未被充分利用,就像装了半箱的集装箱,空间利用率低下。当更新操作使行大小变化或删除操作移除数据时,页内会产生空洞,导致avg_page_space_used_in_percent指标下降。而外部碎片则是叶子页的物理存储顺序与逻辑顺序不匹配,就像按章节排列的书页被打乱了顺序,使得磁盘磁头需要频繁跳转。
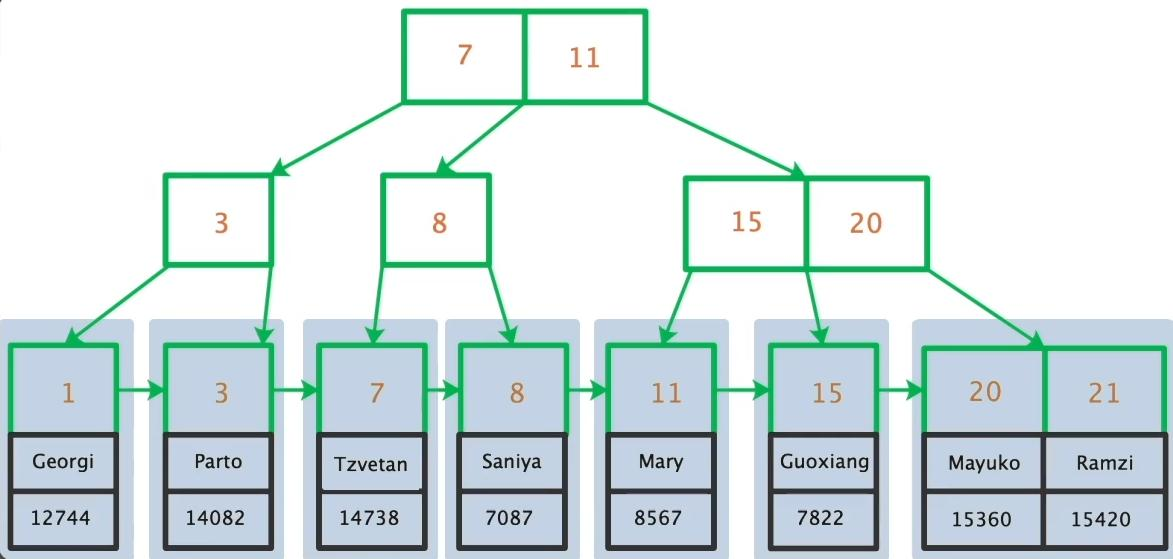
上图清晰展示了B树结构因页分裂导致的外部碎片:当新数据插入已满的页时,SQL Server会拆分页面并分配新页,虽然逻辑上通过指针保持顺序,但物理存储已不连续。这种碎片化在非聚集索引中尤为明显,因为其叶节点指向的数据页可能分布在磁盘各处。
碎片的量化检测
通过sys.dm_db_index_physical_stats动态管理视图可精确测量碎片程度。以下查询能快速定位需要维护的索引:
SELECT
OBJECT_NAME(ips.object_id) AS TableName,
i.name AS IndexName,
ips.avg_fragmentation_in_percent,
ips.avg_page_space_used_in_percent,
ips.page_count
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') ips
JOIN
sys.indexes i ON ips.object_id = i.object_id AND ips.index_id = i.index_id
WHERE
ips.avg_fragmentation_in_percent > 5
ORDER BY
ips.avg_fragmentation_in_percent DESC;
通常认为:碎片率低于5%无需处理,5%-30%适合重组,超过30%则需要重建。但这个阈值并非绝对,还需结合页数量和业务场景调整——对于仅包含100页的小索引,即使碎片率达40%,其性能影响也可能微不足道。
索引重新组织:轻量级的碎片修复
当索引碎片率处于5%-30%的中等水平时,REORGANIZE是更经济的选择。这个操作就像整理凌乱的书架,通过重新排列现有页来恢复顺序,而非推倒重来。
工作原理:页级别的精细调整
索引重组的核心过程是对叶级页面进行物理重排,使其与逻辑顺序一致。SQL Server会扫描索引的叶节点,将分散的页重新组织为连续的物理块,并压缩页面以提高avg_page_space_used_in_percent。与重建不同,重组不会创建新索引结构,而是在原有页结构上进行优化,因此只需8KB的临时空间用于页面移动。
这个过程始终在线执行,通过持有意向排他锁(IX)允许并发查询和数据修改。根据SQL Server官方文档,REORGANIZE操作的锁粒度是页级别的,不会长时间阻塞表访问,这使其成为OLTP系统白天维护的理想选择。
执行效率与资源消耗
重组操作的耗时与碎片程度正相关,碎片越多需要移动的页面越多。在实验环境中,对一个包含100万行、碎片率25%的非聚集索引执行重组,平均耗时约为重建操作的1/3。但要注意,当碎片率超过30%时,重组的性价比会显著下降——此时重建通常更快。
事务日志方面,REORGANIZE在所有恢复模式下都是完全记录的,但会拆分为多个小事务,避免日志文件暴涨。这与重建在FULL模式下产生单一大事务形成鲜明对比,对于日志空间有限的系统更友好。
操作示例与监控
执行索引重组的语法简洁明了:
ALTER INDEX IX_Order_CustomerID ON Sales.Order REORGANIZE;
若要监控进度,可查询sys.dm_exec_requests视图的percent_complete列:
SELECT
command,
percent_complete,
estimated_completion_time/1000 AS EstimatedSecondsRemaining
FROM sys.dm_exec_requests
WHERE command LIKE 'REORGANIZE%';
需要注意的是,重组不会更新统计信息,完成后可能需要手动执行UPDATE STATISTICS以确保查询优化器获得最新数据分布。
索引重新生成:彻底的结构重建
当索引碎片率超过30%或页密度极低时,REBUILD操作成为必要选择。这相当于拆除旧楼重建,通过创建全新的索引结构来消除所有碎片。
实现机制:新旧索引的无缝切换
索引重建的过程本质是创建新索引替换旧索引。在离线模式下,SQL Server会首先获取架构修改锁(Sch-M),这会阻塞所有表访问,然后扫描旧索引数据,按排序键重新组织并写入新页。完成后删除旧索引,释放空间。这个过程能彻底重置索引结构,使avg_fragmentation_in_percent接近0%。
企业版用户可使用ONLINE = ON选项实现联机重建,此时SQL Server会维护新旧两个索引版本,通过行版本控制允许读写并发。但这需要额外的tempdb空间和更多CPU资源,重建时间通常比离线模式长30%-50%。
通过查询sys.dm_exec_requests可实时跟踪percent_complete。值得注意的是,联机重建在最终切换阶段仍需短暂获取Sch-M锁,可能导致瞬间阻塞。
资源消耗与性能影响
重建操作的资源需求相当可观。它需要至少相当于索引大小的空闲空间(离线重建),在FULL恢复模式下会生成与索引大小相当的事务日志。一个10GB的索引重建可能导致日志暴涨,因此建议在BULK_LOGGED模式下执行以减少日志量。
CPU方面,重建会使用并行度(MAXDOP)设置,默认使用所有可用CPU核心。通过MAXDOP = 1选项可限制并行度,但会延长操作时间。内存消耗主要用于排序操作,若内存不足会使用tempdb,导致I/O增加。
高级选项与最佳实践
重建索引时可配置多项高级选项:
FILLFACTOR:控制页填充度,为未来插入预留空间
SORT_IN_TEMPDB:指定在tempdb中排序,减轻用户数据库I/O
DATA_COMPRESSION:启用页或行压缩,减少存储空间
示例:
ALTER INDEX PK_OrderID ON Sales.Order
REBUILD WITH (
ONLINE = ON,
FILLFACTOR = 80,
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE,
MAXDOP = 4
);
最佳实践表明,对于分区表应采用分区级重建(PARTITION = N),避免全表锁定;对于大型聚集索引,联机重建结合MAXDOP = 1和ONLINE = ON可实现完全排序,获得最佳性能。
核心区别对比与决策框架
重建与重组并非对立关系,而是各有适用场景的维护手段。理解它们的本质差异是制定有效索引维护策略的关键。
机制与效果对比
维度 | REORGANIZE | REBUILD |
操作本质 | 页级重排与压缩 | 新建索引替换旧索引 |
碎片消除 | 部分消除(约70%-80%) | 完全消除(接近0%) |
空间回收 | 有限(仅压缩页) | 彻底回收未使用空间 |
统计信息更新 | 不更新 | 自动更新 |
事务日志 | 多事务小日志 | 单事务大日志(FULL模式) |
并行度 | 不支持 | 支持MAXDOP配置 |
最显著的差异在于操作粒度:重组是"整理现有房间",而重建是"推倒重建"。这导致重建能获得更好的碎片消除效果和页面密度,但代价是更高的资源消耗。
锁机制与可用性对比
锁行为是选择维护方式的关键考量。重组全程持有意向排他锁(IX),允许并发查询和DML操作,仅在单个页操作时短暂获取页锁(X)。而离线重建会获取架构修改锁(Sch-M),完全阻塞表访问;联机重建虽通过快照隔离允许读取,但在最终切换阶段仍需短暂Sch-M锁,可能导致瞬间阻塞。
生产环境中曾出现过因未使用WAIT_AT_LOW_PRIORITY选项,联机重建的Sch-M锁等待导致业务中断的案例。因此对于7×24系统,重组通常是白天维护的更安全选择。
决策框架:碎片率与业务场景的平衡
建立索引维护决策树需考虑三个核心因素:
碎片程度:使用avg_fragmentation_in_percent作为基础指标
索引大小:小索引(<1000页)即使高碎片也可直接重建
业务窗口:OLTP系统需优先考虑联机操作,数据仓库可接受离线维护
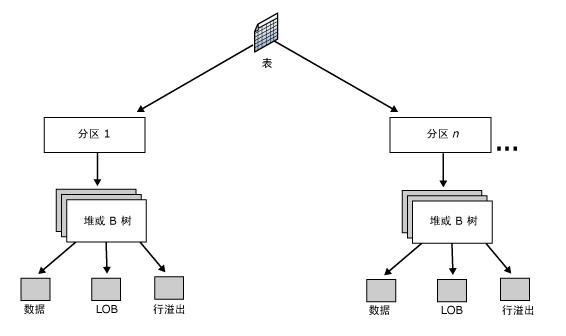
上图展示了表分区与索引维护的关系,通过将大表拆分为多个分区,可实现对活跃分区的精准维护,降低整体维护成本。
典型策略如下:
碎片率<5%:不处理,微小碎片对性能影响可忽略
5%≤碎片率≤30%:执行REORGANIZE,平衡资源与效果
碎片率>30%:执行REBUILD,彻底消除碎片
特殊场景:日志空间有限选重组,需要压缩选重建;停机窗口大选离线重建,否则选联机重建
企业级维护策略与自动化实现
索引维护不是一次性任务,而是需要持续优化的过程。成功的维护策略应实现自动化、智能化,并与业务周期协同。
维护窗口的精准规划
不同类型系统需要差异化的维护时间安排:
OLTP系统:选择业务低谷期(如凌晨2-4点)执行重建,白天可对联机操作影响小的索引执行重组
数据仓库:在ETL加载完成后、查询高峰期前执行维护
混合工作负载:采用分区索引维护,对活跃分区高频重组,非活跃分区低频重建
某电商平台的实践表明,将维护窗口与用户访问低谷期对齐,可使索引维护对业务的影响降至0.3%以下。关键是通过sys.dm_db_index_usage_stats识别 unused索引,避免对未使用索引进行无效维护。
自动化脚本与工具
Ola Hallengren的索引维护脚本(https://ola.hallengren.com/)是行业标准解决方案,它能根据碎片程度自动选择维护方式,并支持并行处理、日志记录和邮件通知。核心特性包括:
按碎片阈值动态选择REBUILD/REORGANIZE
支持分区索引和列存储索引维护
集成Ola的备份和完整性检查解决方案
简化版自动化脚本示例:
EXECUTE dbo.IndexOptimize
@Databases = 'USER_DATABASES',
@FragmentationLow = 'INDEX_REORGANIZE',
@FragmentationMedium = 'INDEX_REORGANIZE,INDEX_REBUILD_ONLINE',
@FragmentationHigh = 'INDEX_REBUILD_ONLINE',
@FragmentationLevel1 = 5,
@FragmentationLevel2 = 30,
@UpdateStatistics = 'ALL',
@LogToTable = 'Y';
云环境中的特殊考量
在Azure SQL DB等云数据库中,传统维护策略需要调整。Azure提供自动索引优化功能,通过AI分析查询性能和碎片趋势,自动执行重建/重组。但用户仍需关注:
弹性池资源限制可能导致维护操作节流
区域冗余存储使I/O成本不同于本地环境
无服务器层级的自动暂停特性可能中断长时维护
某Azure SQL托管实例用户的案例显示,结合自动索引建议与自定义维护计划,可使关键查询性能提升40%,同时降低30%的维护成本。
总结:构建可持续的索引健康体系
索引维护不是孤立的技术操作,而是数据库性能治理的有机组成部分。成功的索引管理需要:
定期体检:通过监控工具持续跟踪碎片趋势,而非被动响应性能问题
精准施策:根据索引类型、大小和使用模式选择合适维护方式
风险控制:维护前备份关键数据,使用ONLINE选项和低优先级锁减少影响
持续优化:结合查询性能反馈调整维护频率和阈值
记住,没有放之四海而皆准的维护策略。就像园艺需要根据植物特性和季节变化调整养护方案,索引维护也应根据业务周期、数据变化模式和性能目标动态优化。通过本文阐述的原理和方法,数据库管理员可构建一套平衡性能、可用性和资源消耗的索引健康体系,让索引真正成为数据库的"加速引擎"而非性能瓶颈。
正如Microsoft Learn强调的:"在许多工作负荷中,提高页面密度比减少碎片化对性能的积极影响更大"。索引维护的终极目标不是追求零碎片,而是通过科学管理使数据库在业务需求和系统资源间找到最佳平衡点。
