




目录
- 为什么磐维这类 MPP 数据库大表 join 反而更快?
- 第1章 所有人第一次接触 MPP 时都会遇到这道“思想反差”
- 第2章 单机 JOIN 的世界:所有 JOIN 都要“挤过一扇门”
- 2.1 单机数据库只有“一扇门”:所有数据必须挤进一个实例
- 2.2 单机 JOIN 绝不是“扫一遍表”那么简单
- 2.3 单机 JOIN 的性能瓶颈,本质上是“三个固定”
- 2.4 单机数据库的 JOIN 成本模型,是线性的,甚至是超线性的
- 2.5 单机优化器最怕三件事:大表、大表、大表
- 第3章 MPP JOIN 的世界:不再是一扇门,而是 N 扇门 + N 个执行器
- 3.1 MPP 的核心思想:分布数据、分布计算、分布执行
- 3.3 决定 MPP JOIN 快慢的不是表大小,而是“要不要搬数据”(Motion)
- 3.4 大表在 MPP 看起来“大”?实际上已经被切成“小块”
- 第4章 为什么大表 JOIN 反而更快?——四个关键原因拆开讲
- 4.1 原因 1:大表更容易“分布得均匀”,并行度能完全发挥**
- 4.2 原因 2:大表常常“分布键一致”(DK 一致原则),天然命中本地 JOIN
- 4.3 原因 3:大表扫描在 MPP 中是“顺序 IO + 向量化 + 多节点同时扫”
- 4.4 原因 4:大表 JOIN 不会触发“广播小表”的昂贵代价
- 4.5 原因 5:大表统计信息更充分,优化器更容易“走对路”
- 第5章 用一个具体场景,让你从头到尾看懂:为什么大表 JOIN 反而快?
- 5.1 先看单机怎么执行(为什么慢)
- 5.2 再看 MPP:第一步就是把大表切碎
- 5.3 JOIN 字段和分布键一致 → 完全本地 JOIN
- 5.4 更关键的:每个节点的 JOIN 都是“轻量级”的
- 5.5 再看为什么“小表 JOIN 大表”反而容易变慢
- 5.6 最终结论:看看整个场景的全链路逻辑
- 第6章 在磐维数据库OLAP型中,这种差异更加突出
- 第7章 在 MPP 里,大表 JOIN 本质上是在“多节点上处理小表 JOIN”
为什么磐维这类 MPP 数据库大表 join 反而更快?
——反直觉背后的分布式执行真相
第1章 所有人第一次接触 MPP 时都会遇到这道“思想反差”
第一次接触 MPP 的人,都会经历一次“价值观崩塌”。
在单机数据库(Oracle、MySQL、PostgreSQL)里,大家从第一天就被教育:“大表 JOIN 很危险。”
在传统系统中,只要听到“几亿行的大表 JOIN 大表”,开发和 DBA 的第一反应几乎都是本能的:
- “能不能改成预处理?”
- “能不能拆成多次查询?”
- “能不能用缓存?”
- “要不……先把表缩一缩?”
因为经验告诉我们:大表 JOIN 就像堵车,一旦堵上,整个系统都不好受。
但到了 MPP 系统,一切突然反过来了——这是感受到的第一个冲击。
你把业务迁到 Greenplum、Vertica、OushuDB 或磐维数据库OLAP型这样的 MPP 架构之后,运行的第一条大表 JOIN 常常会发生这样的戏剧性变化:
-
**在单机里:**两张 5 亿行表的 JOIN,能跑到怀疑人生。
-
**在 MPP 里:**同样级别的大表 JOIN,几十秒甚至十几秒就跑完了。
而更匪夷所思的事情发生了:
- 两个每天千万级的数据事实表 JOIN → 飞快
- 大表 JOIN 大表 → 稳定、速度还惊人
- 大表 JOIN 小表 → 偶尔还慢得莫名其妙
- 小表 JOIN 小表 → 也可能比预期慢很多
这时大多数人的反馈都是:“怎么跟我想的不一样?”、 “不科学啊?”、 “哪里有问题?”、 “是不是优化器在胡来?”,尤其是第一次看到 Explain 的时候,那种违和感更强:
- 明明大表 JOIN,执行计划却干干净净,全是本地算子
- 明明小表 JOIN,反而 Motion(数据搬移)满天飞
- 明明数据库资源很多,但慢的部分总是“网络传输”
- 明明逻辑一样,性能表现却差得离谱
**为什么这种现象让人困惑?因为我们脑子里的 JOIN 认知来自“单机时代”。在单机数据库里,JOIN 的性能几乎由一件事决定:“表有多大”。**越大越慢,这在单机世界里几乎是自然规律。但 MPP 的世界不是这样运行的。它的运行逻辑背后有两个隐藏前提:
前提 1:表越大,越容易“被并行切得相对均匀”
前提 2:JOIN 的成本不是看表多大,而是“需不需要跨节点搬数据”
这两个前提颠覆了我们对 JOIN 的原有理解,也直接导致:在 MPP 中,大表 JOIN 反而通常“更不容易出错”,更快跑完。
而小表往往因为:
- 分布不一致
- JOIN 字段基数低
- 统计信息不完善
- 非等值或表达式 JOIN
- Motion 频繁
- 倾斜严重
反而成为性能黑洞。所以这里的核心只有一个:重置大家的旧世界观。
我们希望大家意识到:
- 单机经验 ≠ MPP 经验。
- 单机直觉 ≠ MPP 真相。
- 大表 ≠ 慢,小表 ≠ 快。
JOIN 的本质,在 MPP 中完全变成了另一套逻辑。在大家的旧经验里:
- 大表 JOIN 是“问题源头”
- 它越大越慢,越让人害怕
但在 MPP 的世界里:
- 大表 JOIN 是“被平均切开的任务”
- 算子在多节点间分散执行
- 网络不动,JOIN 就能飞
所以这章我们只是希望大家先建立一个心理准备:**你以为的 JOIN,不是 MPP 执行器眼里的 JOIN。
第2章 单机 JOIN 的世界:所有 JOIN 都要“挤过一扇门”
在解释“大表 JOIN 为什么在 MPP 里反而更快”之前,我们必须先回到单机数据库的世界,看看它是怎么执行 JOIN 的。只有看清楚“单机为什么慢”,才能真正理解“MPP 为什么快”。
这一章的目的就是把单机 JOIN 的瓶颈讲透。
2.1 单机数据库只有“一扇门”:所有数据必须挤进一个实例
无论是 Oracle、MySQL、PostgreSQL、SQL Server,本质上都有个共同点:所有 SQL 最终都要在一个数据库实例里跑完。
它们当然有多线程、有并发、有缓冲池, 但 JOIN 的核心执行依然要挤过同一个“执行通道”:
- 同一块 CPU(或者同一组 CPU)
- 同一块内存(buffer pool)
- 同一套磁盘路径
- 同一份中间结果存储空间
你可以把单机数据库理解成:**一台高速收费站,无论你有多少车,都要从这一个口通过。**表越大,车越多,这条道就越堵。
2.2 单机 JOIN 绝不是“扫一遍表”那么简单
很多人以为 JOIN 的成本是:“扫描表 + 匹配行”,其实远不止如此。
单机 JOIN 的主要成本包括:
-
1) 扫描两张表(或索引)
而且扫描通常受 I/O 限制。
-
2) 构建哈希表(Hash Join)或建立嵌套循环(Nested Loop)
哈希表越大,内存压力越大;溢出后要写临时文件。
-
3) 搜索匹配行
大表 → 哈希表大 → CPU 开销大。
-
4) 合并中间结果
输出结果可能比输入表还大,进一步施压内存和磁盘。
-
5) 排序、聚合等额外步骤(如果包含 ORDER/GROUP BY)
以上所有东西都要在同一台机器上完成。 这才是单机 JOIN 越大越慢的根本原因。
2.3 单机 JOIN 的性能瓶颈,本质上是“三个固定”
单机无论 CPU 再强,都无法改变三个事实:
-
固定的 I/O 带宽
磁盘吞吐固定。大表必须“从头扫到尾”,无法跳过。
-
固定的内存容量
哈希表太大 → spill → 临时文件,临时文件太大 → 随机 I/O → 性能暴死
-
固定的 CPU 资源
CPU 超不过物理上限,JOIN 算子再高效也只能实现“有限加速”。
所以单机时代会有一句经验之谈:越大的表,越拖慢 JOIN;越多个 JOIN,越让执行计划恶化。
这不是开发写得差,而是单机执行模型天然如此。
2.4 单机数据库的 JOIN 成本模型,是线性的,甚至是超线性的
简单表示如下:
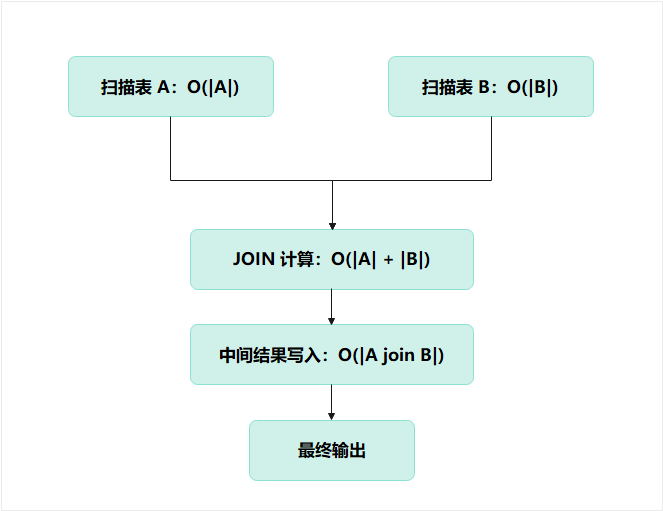
表越大:
- 扫描越久
- 哈希表越大
- spill 越严重
- 中间结果越大
- 随机 I/O 越多
最终 JOIN 的代价可能是超线性增长的。
例如:
| 表大小 | JOIN 预期时间(理想) | 实际时间(可能) |
|---|---|---|
| 1GB | 1x | 1x |
| 10GB | 10x | 20–30x |
| 100GB | 100x | 300–1000x |
这就是为什么单机的 DBA 和开发对大表非常敏感。
2.5 单机优化器最怕三件事:大表、大表、大表
单机里所有性能事故的“罪魁祸首”几乎都跟大表有关:
- 大表 JOIN 大表
- 大表 JOIN 小表,但选择 Nested Loop
- 大表上没有合适的索引
- 大表上的统计信息不准
- 大表需要排序
最终导致:
只要业务里听到“大表”两个字,大家下意识先紧张。
而这个“根深蒂固的直觉”会在迁移到 MPP 后带来巨大的误解 ——因为你会继续用单机的“恐惧”在看 MPP 查询。
但 MPP 的 JOIN 完全不是这么工作的。
第3章 MPP JOIN 的世界:不再是一扇门,而是 N 扇门 + N 个执行器
上面我们讲清楚了: 单机 JOIN 的慢,本质是 —— 所有数据挤同一扇门:
- 一个 CPU(或少数几个)
- 一块内存
- 一组磁盘带宽
- 一个执行器
这决定了单机 JOIN “越大越慢”几乎是物理定律。但在 MPP(Massively Parallel Processing)架构里,整套逻辑完全翻转:
MPP 不是“把大表交给一台机器算”,
而是“把大表切碎,让几十台机器一起算”。
如果说单机是“一条高速公路的收费站”,那 MPP 就像:几十个收费站一起放车。 而你的 JOIN,就是几十条车道在同时通行。
下面我们完整展开。
3.1 MPP 的核心思想:分布数据、分布计算、分布执行
所有 MPP(Greenplum、Vertica、磐维等)都遵循同一套运行哲学:
(1)数据不是放在一个地方,而是“水平切片”放在多个节点
你的一张 100 亿行大表,实际上长这样:
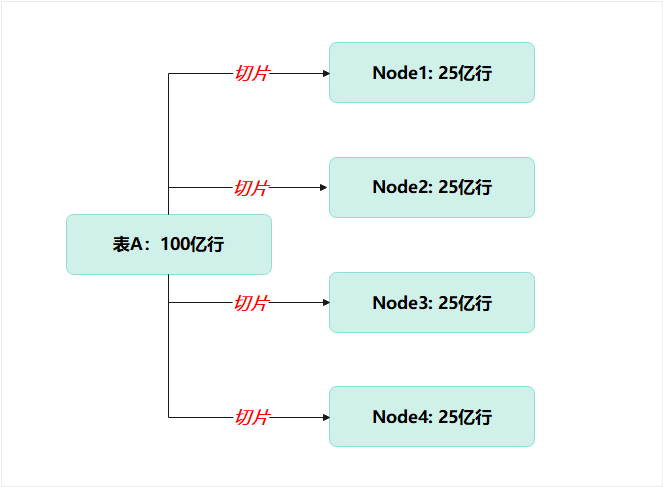
这是 MPP 的基础: 你以为是一个大表,其实是很多小表拼成的。
(2)每个节点都有自己的执行器(QE)“独立干活”
执行计划在 MPP 里不是一份,而是 N 份:
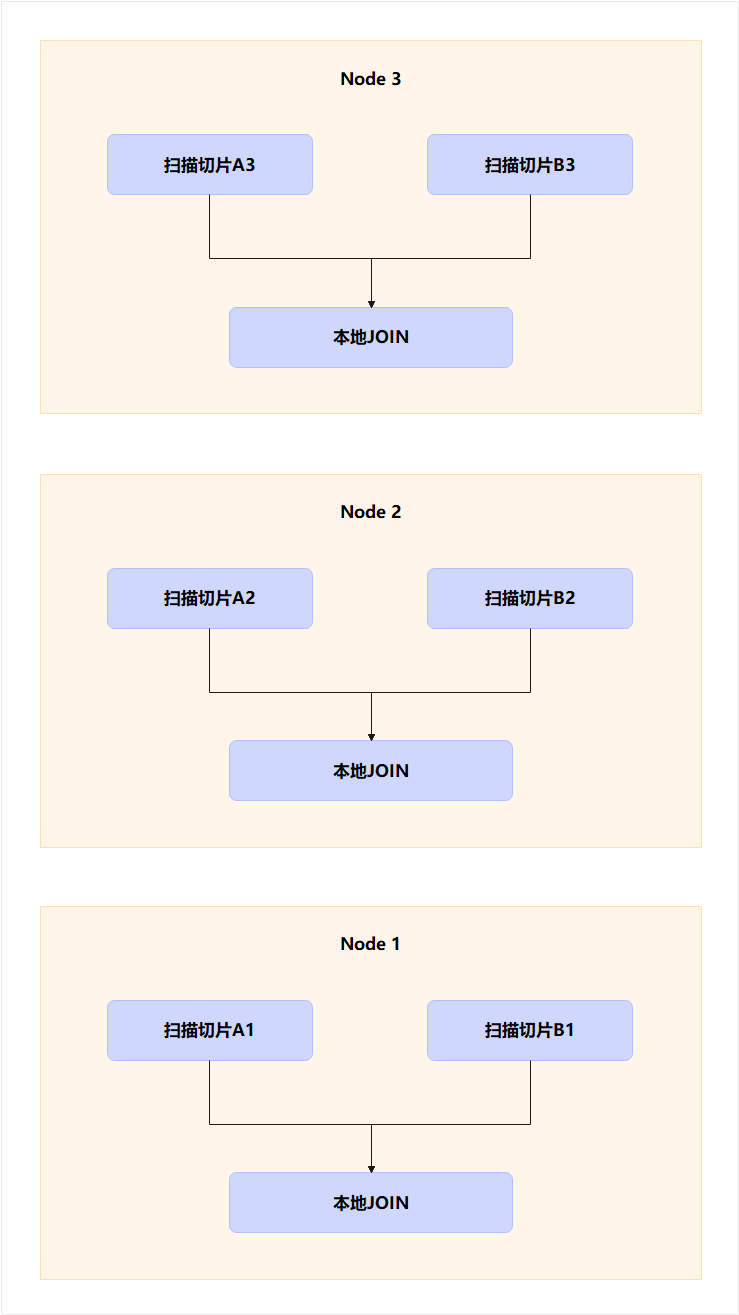
这意味着:
- 一个 JOIN,本质上是 N 个 JOIN 并行执行
- 每个节点只处理“自己那一份”
- 所需的内存也只是 1/N
- 构建的哈希表也是 1/N
- 扫描的数据量也是 1/N
大表被“切碎”,每个节点都只在处理“小表”。
这是整个“反直觉”的根源。
(3)JOIN 的执行是完全分布式的
单机 JOIN 是:
一台机器计算所有事情
MPP JOIN 是:
N 台机器分别做自己那份 JOIN
最后再合并结果
就像跑步接力:
- 每个节点跑自己那段
- 不是让一个人把全程跑完
所以 JOIN 的速度取决于:
最慢的那个节点,而不是表的绝对大小。
这就导致:
- 大表被切得很平均 → 跑得很快
- 小表分布不均 or 需要 shuffle → 可能跑得慢
3.2 MPP 的执行分工:QD 派活、QE 干活
MPP 比单机多一个角色:
- QD(Query Dispatcher):大脑
- QE(Query Executor):多节点的工人
整体流程如下:
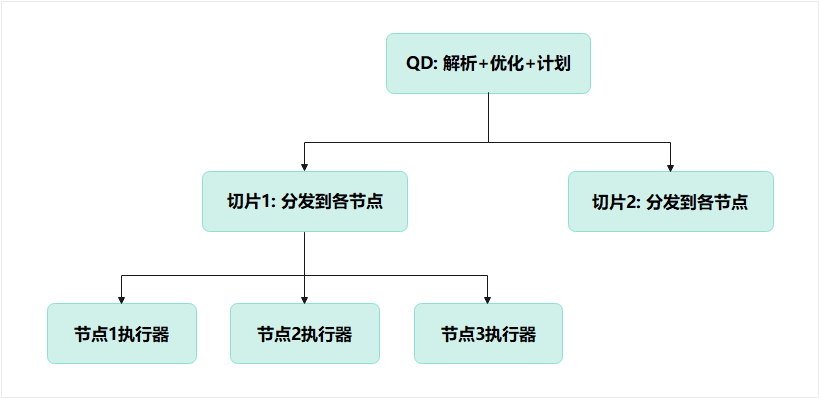
你写的是一条 SQL, 但数据库实际执行的是:
- 几十份不同的子查询
- 每个节点执行属于自己的那一份
- 整体共同完成一条 JOIN
最终 QD 汇总结果返回给你。
3.3 决定 MPP JOIN 快慢的不是表大小,而是“要不要搬数据”(Motion)
这是理解 MPP JOIN 的绝对关键:在 MPP 中,JOIN 的最大成本 = 网络传输(Motion)
NOT:
- CPU
- 内存
- 扫描
- 哈希
- 排序
它们都不是第一开销。因为这三者都被并行切开了:
- CPU 切开 → 每个节点 CPU 足够
- 内存切开 → 哈希表变小
- IO 切开 → 扫描更快
真正的瓶颈是:数据是否需要从一个节点广播到另一个节点?
一旦 JOIN 字段不一致、分布键不同,就会触发这两种恶名昭彰的 Motion:
1)Redistribute(重分布)——把数据洗牌一遍
某些 MPP 甚至称其为“洗发水算法”:本地乱、中间乱、对端乱。成本非常高。
2)Broadcast(广播)——把小表全复制一遍
小表每增加 1GB,广播到 16 节点就是 16GB 传输。节点越多,开销越吓人。
结论:
在 MPP 里 JOIN 的“真正敌人”从来不是表大不大,而是:是不是本地 JOIN,不要 Motion!
这就是为什么:
- 大表 JOIN 大表 → 分布一致 → 本地 JOIN → 快
- 小表 JOIN 大表 → 分布不一致 → Motion → 慢
3.4 大表在 MPP 看起来“大”?实际上已经被切成“小块”
我们用数字直观感受一下:
假设:
- 表 A = 10 亿行
- 表 B = 50 亿行
- 集群节点数 = 20
单机眼里:
A = 巨型表
B = 超巨型表
JOIN = 天崩地裂
MPP 眼里:
| 节点 | A 子表行数 | B 子表行数 |
|---|---|---|
| Node1 | 0.5 亿 | 2.5 亿 |
| Node2 | 0.5 亿 | 2.5 亿 |
| Node3 | 0.5 亿 | 2.5 亿 |
| … | … | … |
| Node20 | 0.5 亿 | 2.5 亿 |
每个节点只处理:
- A 的 1/20
- B 的 1/20
- 哈希表大小 1/20
- 扫描量 1/20
JOIN 的本质变成:“1000万行 JOIN 2500万行” × 20 并行。难度瞬间从“巨无霸大 JOIN”→ “中等 JOIN × 多次并行”。
第4章 为什么大表 JOIN 反而更快?——四个关键原因拆开讲
现在,我们已经知道:
- 单机 JOIN 的瓶颈是 资源只有一份
- MPP JOIN 的底层逻辑是 分布式并行
- 真正决定 JOIN 性能的不是“表大不大”,而是 是否需要跨节点搬数据(Motion)
接下来,我们把整篇文章最关键的问题彻底讲明白:为什么在 MPP 里“大表 JOIN 大表”反而很快?
核心原因有四个,每一个单独看都很合理,放在一起就形成了那种让人“恍然大悟”的反直觉。
4.1 原因 1:大表更容易“分布得均匀”,并行度能完全发挥**
倾斜,是 MPP 的头号敌人。但越大的表,它的分布往往越自然、越均匀。
原因非常简单:
🎯 大表 JOIN 常用的字段(order_id、user_id 等)基数都很高
高基数字段 → hash 后更均匀 → 每个节点分到的数据量接近。
我们用数字举例:
假设:
- lineitem = 30 亿行
- orders = 10 亿行
- 分布键是 order_id(基数巨大)
切到 20 个节点,每个节点大概是:
- lineitem:1.5 亿行
- orders:5000 万行
差距不大,负载均衡。
JOIN 在每个节点都像这样跑:
没有哪个节点“特别慢”。
这意味着:
并行度可以 100% 发挥。
这就是为什么你会看到“大表 JOIN 大表”的查询跑得特别稳定、特别快。
4.2 原因 2:大表常常“分布键一致”(DK 一致原则),天然命中本地 JOIN
这是大部分 MPP 初学者忽略的核心。
在数据仓库/大数据场景里,两个大事实表几乎一定会按照相同的业务主键分布:
- fact_order
- fact_order_item
- fact_payment
- fact_clickstream
这些表共同的分布键通常是:
- order_id
- user_id
- session_id
- device_id
所以当它们 JOIN 时,天然满足:
JOIN 字段 与 分布键一致(DK 一致)
→ 直接走本地 JOIN
→ 无需要 Redistribute / Broadcast
→ Motion = 0
这是所有 MPP 的最优执行路径。
我们用图表示一下这一幕:
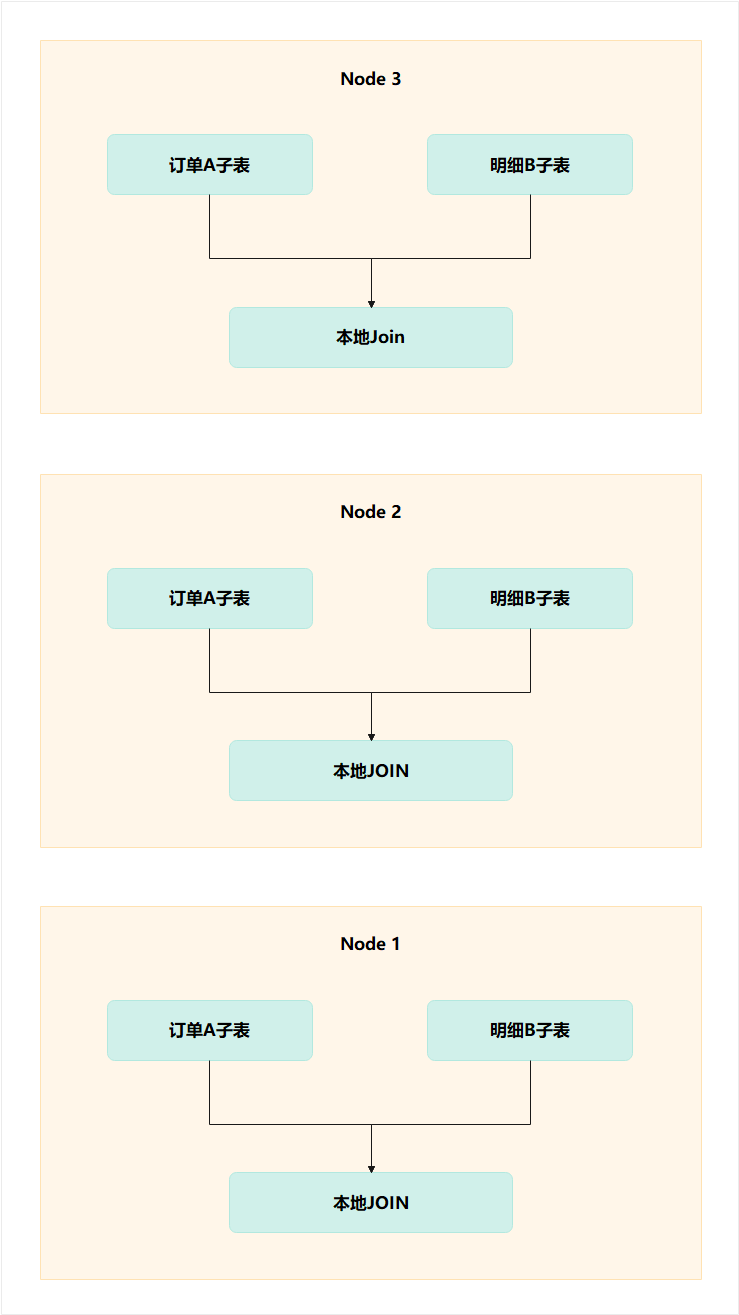
没有 Motion,没有网络瓶颈,每个节点各扫各的,各算各的。
JOIN 的执行成本变成:max(各节点 JOIN 时间) (而不是所有数据汇聚到一个节点)
这就是你看到“大表 JOIN 大表反而稳定”的原因。反例小表我后面会在例子里对比。
4.3 原因 3:大表扫描在 MPP 中是“顺序 IO + 向量化 + 多节点同时扫”
很多 DBA 看大表会本能紧张:“扫描会很慢吧?”但这是单机时代的直觉。
在现代 MPP(例如磐维数据库OLAP型等)中,大表扫描是整个系统最“擅长”的事情,甚至称得上是:
MPP 最欣赏你给它一个大表,让它尽情顺序扫。
为什么?
1) 大表的文件组织通常是 AO、列存或 MOR(merge-on-read)结构
顺序扫描效率惊人。
2) 扫描行为被切成 20 份、40 份同时进行
单机只能一口气吃;
MPP 是“二十口一起吃”。
3) 向量化执行器对大批量数据最友好
大表比小表更容易触发向量化路径,反而发挥执行器的优势。
4) I/O 在各节点同时拉取
整个集群 I/O 合力 > 单机 N 倍。
所以你会看到一种特别反直觉的体验:**在 MPP 上,扫描越大的表,总体性能越“线性稳定”。**小表反而可能因为“凑不齐批处理”导致执行器效率不高。
换句话说:大表在 MPP 眼里不是“巨兽”,而是“一堆更好处理的小块”。
4.4 原因 4:大表 JOIN 不会触发“广播小表”的昂贵代价
这一条非常非常关键。
很多人误以为:
“小表 JOIN 大表肯定快。”
但在 MPP 中,小表 JOIN 触发 Broadcast 的概率非常高。
Broadcast 的代价是什么?
小表大小 × 节点数量
假设:
- 小表是 1GB
- 集群是 16 节点
- Broadcast = 1GB × 16 = 16GB 传输量
如果维表稍微再大一点,比如 10GB:
10GB × 16 = 160GB
160GB 的网络传输,性能再好的 MPP 都扛不住。
反观大表 JOIN 大表:
- 分布键一致
- 没有 Broadcast
- 也不需要 Redistribute
- 纯本地 JOIN
不需要动网络,自然更快、更稳。
所以我们第一次得出一个颠覆常识的结论:在 MPP 中,大表 JOIN 大表(只要分布对齐),远比“小表 JOIN 大表”要轻松得多。
4.5 原因 5:大表统计信息更充分,优化器更容易“走对路”
这是容易被忽略但非常真实的一点。
MPP 优化器需要依赖统计信息来判断:
- 是否广播
- 是否重分布
- JOIN 顺序
- JOIN 算法(Hash / Merge / NestedLoop)
- Motion 的最优策略
大表由于数据多,统计信息收集:
- 误差更小
- 分布更可预测
- 选择率更稳定
优化器更容易生成正确计划。
但小表呢?
- cardinality 偏差大
- 分布可能很偏
- 选择率经常“猜不准”
- 可能误判为“小表可广播”
- 结果走了最糟糕的路径
所以:
大表 JOIN 更容易走到“理想计划”;
小表 JOIN 更容易走到“错误计划”。
第5章 用一个具体场景,让你从头到尾看懂:为什么大表 JOIN 反而快?
为了把前面四个原因“串起来”,我们用一个在几乎所有企业里都真实存在的业务场景:订单事实表 JOIN 订单明细事实表。
这不是虚构案例,而是每个零售、电商、物流行业都必然有的模型。
我们假设场景如下:
1)两张大表:每天产生数据千万级
- orders(订单表):例如每天 1000 万行
- lineitem(订单明细表):例如每天 3000 万行
2)两表都按 order_id 分布(DK一致原则)
事实表天然适合按业务主键分布。
3)查询需求:找出最近一天所有订单及其明细
非常常见的场景。
SQL 非常朴素:
select *
from lineitem l
join orders o
on l.order_id = o.order_id
where l.dt = '2024-01-01';
5.1 先看单机怎么执行(为什么慢)
假设把同样数据放在单机(哪怕 64 核机器):执行流程如下:
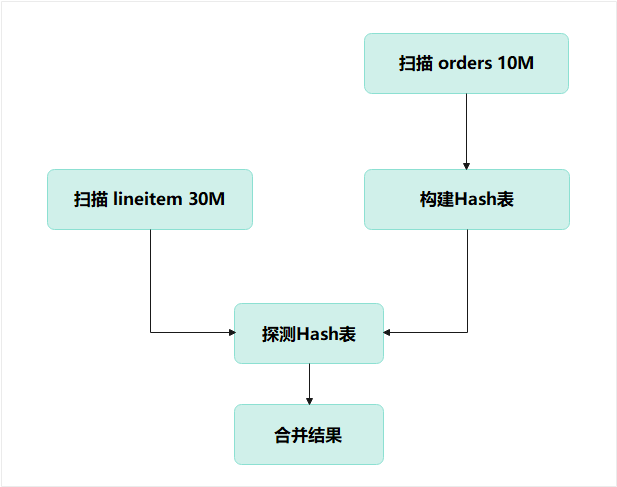
单机成本:
- 扫描:40M 行
- 哈希表:10M 键
- 探测:30M 次
- 中间结果写临时空间
- CPU + 内存 + I/O 全挤在一台机器上
只要数据再涨一点(如 100M+), 单机 JOIN 就很容易开始“喘不上气”。
5.2 再看 MPP:第一步就是把大表切碎
假设集群有 20 个节点,两张表的分布如下:
| 节点 | orders 子表 | lineitem 子表 |
|---|---|---|
| N1 | 50 万行 | 150 万行 |
| N2 | 50 万行 | 150 万行 |
| … | … | … |
| N20 | 50 万行 | 150 万行 |
整套操作不再是“40M JOIN”,而是:
每个节点执行“200 万 JOIN 50 万” × 20 并行
这已经把难度从“巨型运算”降成了“中等运算 × 多次并行”。
5.3 JOIN 字段和分布键一致 → 完全本地 JOIN
这一步是关键,也是本例中大表 JOIN 快的原因。
因为两张表都按 order_id 分布,所以每个节点上:
- lineitem 子表里的 order_id 范围
- orders 子表里的 order_id 范围
完全对应。
因此 JOIN 完全不需要 Motion:不需要广播,不需要重分布,不需要跨节点传输。
执行图如下:
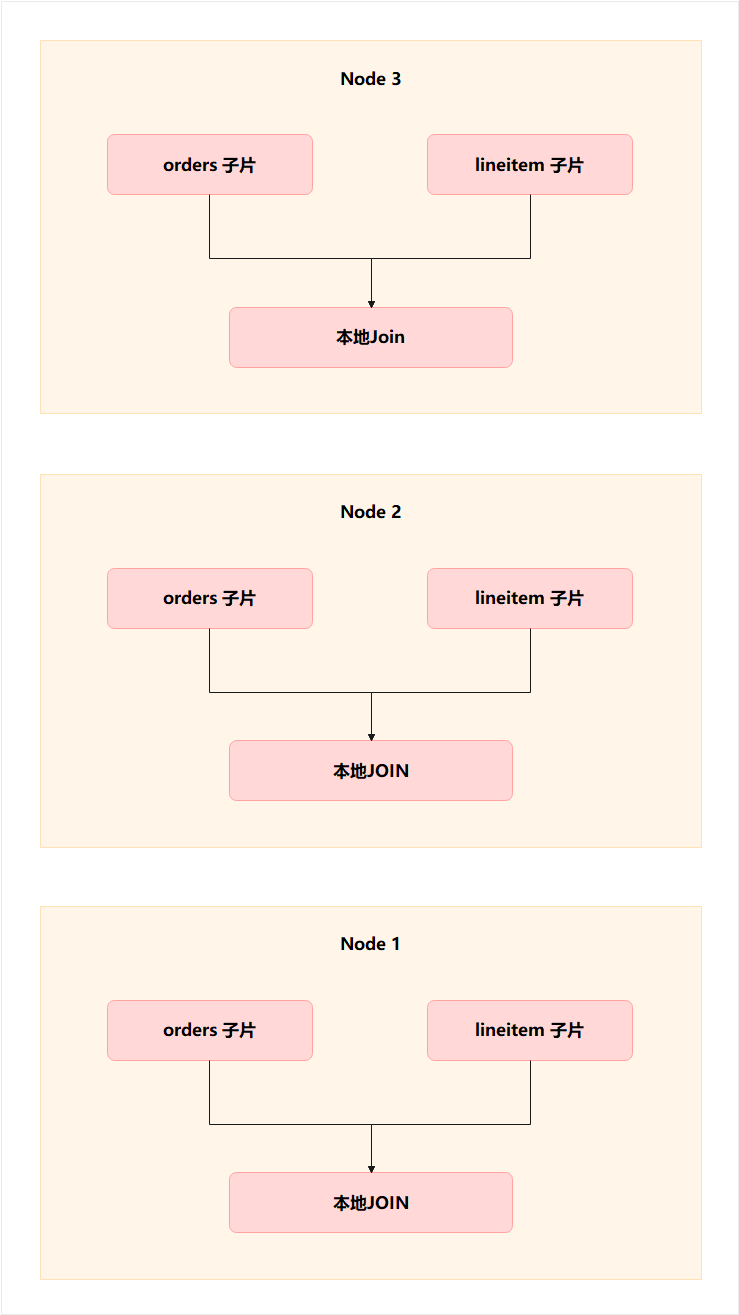
这是 MPP 最理想执行模式:Local Hash Join,全程不动网络。
5.4 更关键的:每个节点的 JOIN 都是“轻量级”的
在每个节点:
- 扫描量 ≈ 200 万
- 构建 hash ≈ 50 万条
- 探测 hash ≈ 150 万条
对现代 MPP 的向量化执行器来说,这几乎是小菜一碟。
扫描时间短、内存压力小、溢出概率低、CPU 算子效率高。
换句话说:这不是大表 JOIN,而是“20 个小表 JOIN”同时执行。
最终的速度取决于:**20 个节点中最慢的那一个。**但因为大表分布均匀,这个“最慢”节点也不会太慢。
5.5 再看为什么“小表 JOIN 大表”反而容易变慢
我们对比一下这个 SQL:
select *
from lineitem l
join d_user u on l.user_id = u.user_id;
d_user 小表(例如 2 万行),但问题在于:
- 可能是随机分布
- 可能按 user_type 分布(基数低)
- JOIN 字段不是大表的分布键
- 统计信息可能不完整
优化器可能选择:
- Broadcast u
- Redistribute l
- 或者两边都 Redistribute(最糟糕)
你会看到这样的执行路径:
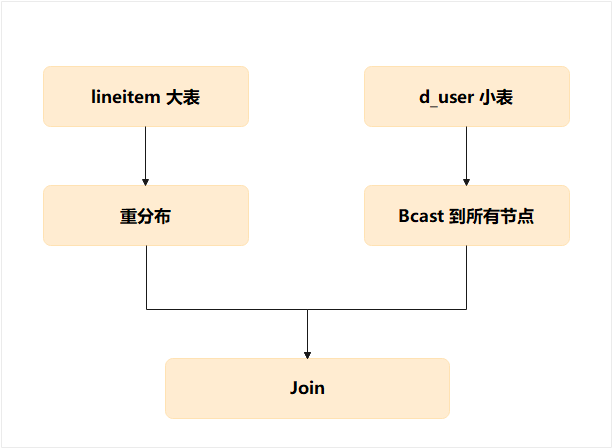
这样一来:
- lineitem (30M 行)被洗牌
- d_user (2 万行)被广播
- Motion × 节点数,网络开销暴涨
- 分布不对齐 → 可能出现倾斜
最终结论:小表 JOIN 大表,并不一定比大表 JOIN 大表快,小表还可能成为性能的真正瓶颈。
其中“最坑”的是:d_user 很小,但它本身的分布设计非常随意,反而拖垮了整个查询。
5.6 最终结论:看看整个场景的全链路逻辑
我们把两种 JOIN 的全链路总结在一张图里:
✔ 大表 JOIN 大表(DK 一致)

❌ 小表 JOIN 大表(DK 不一致)

这就是为什么你在 MPP 上会遇到一个强烈反直觉:大表 JOIN 大表(反而快),小表 JOIN 大表(反而慢)
当你理解了这个例子,你就看懂整个 MPP JOIN 体系的核心规律。
第6章 在磐维数据库OLAP型中,这种差异更加突出
前面几章说的,其实都是所有 MPP 的共性:只要是“切片存储 + 多节点并行 + 分布式执行”的架构,大表 JOIN 反而更快这件事,都会不同程度存在。
那为什么我会专门拉出一个小节,单讲一下磐维数据库OLAP型?不是为了夸一句“磐维更快”,而是想说一件更实际的事:在磐维这样的新一代 MPP 上, “大表 JOIN 反而更快”这件事, 不仅客观存在,而且“看得更清楚、感受更强烈”。
原因主要有三点。
1. 磐维的 JOIN 本来就偏向“本地化 + 向量化”
从架构设计上看,磐维数据库OLAP型属于:
- MPP 架构(多计算节点并行)
- 存算分离(计算节点可以弹性扩缩)
- 配合列式/向量化执行(对大批量扫描和大表 JOIN 更友好)
这直接带来一个效果:
- 只要分布键选得合理(DK 一致),大表 JOIN 几乎天然走“本地 JOIN + 向量化扫描”的路径;
- 而一旦触发 Motion(Redistribute / Broadcast),那段网络+调度开销会在 Explain 里非常扎眼。
也就是说:
- 大表 JOIN,分布对齐 → 很容易跑出“教科书级别”的并行效果;
- 小表 JOIN,如果分布乱写 → 很容易在执行计划里暴露出“Motion 满天飞”的情况。
磐维没有帮你“遮丑”,反而把 MPP 的执行逻辑摊开给你看。
2. Explain 把 Motion、“大表本地 JOIN”这些行为直接摊在表面上
在很多传统数据库里,Explain 输出只告诉你:
- 走了什么索引
- 用了什么 JOIN 算法
- 大概扫描行数是多少
但在磐维这类 MPP 系统里,你能看到的东西明显更多,例如(抽象描述一下):
- 是否存在 Redistribute Motion / Broadcast Motion
- Motion 前后的行数估计
- 各个切片(slice)的执行顺序
- 每一层算子对应的是QD 还是 QE
你会直观地看到两类典型执行计划:
1) 大表 JOIN 大表、分布对齐:
- 多个 Segment 上各自 Scan + Hash Join
- 中间没有或只有极少 Motion
- 上面只是一层 Gather,把结果汇总回前端
2) 小表 JOIN 大表、分布乱写:
- 小表被 Broadcast 到所有节点
- 大表被 Redistribute 一次甚至两次
- Explain 中 Motion 行数巨大
- 运动带来的延迟在实际执行时间里非常明显
用一句更口语的话来说:在磐维里,大表 JOIN 快不快、慢在哪里,你基本一眼就能从 Explain 里看出来,不用猜。
这会强化一种直观感受: 原来大表 JOIN 根本不可怕,真正可怕的是“到处 Motion 的 JOIN”。
3. 实际使用中,大家更容易“走到正确的路径上”
还有一个比较微妙但很现实的点:
- 磐维的典型推荐建模方式,是把订单、明细、支付、日志这类事实表统一按业务主键分布;
- 再加上列存/向量化执行器对大表扫描非常友好,
- 所以在不刻意调优的情况下,大表 JOIN 本来就更容易落在“正确的执行路径”上。
反过来,小表如果随便设计:
- 分布键乱选
- 没有统一规范
- 统计信息也不太在意
那在 Explain 里就会经常看到: 看起来“很轻”的一个维表 JOIN, Motion 的代价甚至比大事实表还高。
这就会把本文前面讲的那件事放大得特别明显:**真正拖累 JOIN 的,常常不是大表,而是乱七八糟的小表。**磐维只是把这个事实,用更透明的方式呈现给你。
所以,这里想传递的并不是一句“磐维很厉害”,而是:在磐维这种 MPP 架构里,大表 JOIN 反而快这件事情, 一方面是真实存在,另一方面是“可观测、可解释、可复现的”。
只要你愿意打开 Explain,看一眼 Motion 和各节点的执行片段,就会发现:
- 之前对“大表 JOIN”的恐惧,大多来自单机时代;
- 在 MPP + 磐维这样的架构下,大表更多时候是“好学生”,小表才是“捣蛋鬼”。
第7章 在 MPP 里,大表 JOIN 本质上是在“多节点上处理小表 JOIN”
这篇文章想表达的中心思想就是:
- 在 MPP 里,你眼中的“大表 JOIN”
- 在系统内部,其实是“很多个小表 JOIN 同时在跑”。
更准确一点说:
-
你看到的是:
- 一条 SQL,两个巨大的事实表 JOIN 在一起
-
MPP 看到的是:
-
20 台机器、40 个执行器,各自拿着自己那一小块数据,在做本地 JOIN
-
每个 JOIN 的规模都不算大,只是大家一起干活,看起来像“大表 JOIN 跑得飞快”。
-
这也是本文标题的真正含义:“为什么 MPP 大表 JOIN 反而更快?” 因为它根本不是在做一件“大”的事, 而是在做很多件“小但并行”的事。
换一个更形象的比喻:
-
在单机里,大表 JOIN 像什么?
像让一个人, 一口气把几十层的楼梯跑完。 楼层越多,越容易在半路趴下。
-
在 MPP 里,大表 JOIN 像什么?
像是把这几十层楼梯,切成很多段, 分给二十个人,每人只跑其中一小段, 然后把所有人的结果拼在一起。只要分配得均匀,每个人跑的那段都不算累, 整体看起来就像“这群人跑楼梯跑得特别轻松”。
-
而小表 JOIN 大表是什么?
如果你把楼梯的分段切得乱七八糟,有的人只跑两级台阶,有的人要跑二十层,最终整队的速度,还是被那位跑二十层的人拖住。
在 MPP 中,这个“楼梯怎么切”、“每段分给谁”、 就是我们前面反复提到的:
- 分布键设计
- DK 一致原则
- Motion 开销
- 倾斜与否
在单机时代, **我们害怕的是“大表”。**在 MPP 时代, 我们真正该害怕的,是“乱分布的小表”和“到处乱飞的 Motion”。
理解了这一点,再看“大表 JOIN 反而更快”,就不再是一个反直觉的怪现象,而是一个可以被设计、被利用、甚至被借力发挥的系统特性。
