




大家好,我是OceanBase,截至2021年12月13日,我最新版本是3.1.1。通过官网地址可以下载,https://open.oceanbase.com/softwareCenter/community ,目前有社区版和企业版,两者都是同样的内核处理引擎,但是商业版提供更多的功能服务和技术支持,保障你生产集群稳定健康的运行,当然喜欢白嫖的同事可以使用社区版,免费的东西也很香。2021年6月1日,我正式开源,这次我是认真的,生态环境在大力建设,社区在布道解惑, 我们努力构建开发者和用户生态。我的目标是打造中国人的数据库,事实上在阿里巴巴内部,我们已经成功把Oracle替代下来,在保障业务顺利平滑的基础上,而且运行得更快。既然这么好,为什么我不出来奉献社会,发挥更大的价值空间。公司领导决定把我商业化、产品化,下面我把我的故事,我的前世今生和各位观众一一阐述。
2008年,信息业务的高速发展,集团感受巨大的威胁,集团对国外基础设施的需求越来越多。终于发起轰轰烈烈的去IOE运动,我的库生信仰很明确,那就是把Oracle取替下来。我的其中一个爸爸就是杨传辉,为了我还写一本书《大规模分布式存储系统》 ,里面介绍单机数据库的数据模型、事务与并发、故障恢复、存储引擎、数据压缩以及分布式数据库的数据分布、数据复制、一致性、容错性、可扩展性等工程特性,包括其它系统如分布式文件系统、分布式键值系统 、分布式列簇系统以及分布式数据相关代表作品的技术原理和架构设计,调研对象有世界OLTP第一的spanner,以及OLAP的皇者vertica,还有数据分析领域的的长青树Greeplum。我的爸爸妈妈生我的时候多少辛苦啊,那时我还不到1.0.0版本。在众多位爸爸妈妈咬牙切齿,日夜奋斗的情况下,2011年8月底,我悄悄开源,当时开源力量不是很大,所以知道的人也比较少。既然我能够开源见人,当然是已经在集团关键核心业务稳定运行的前提下。
虽然我开源了,但是我还没有给大众接受,因为我还有很多问题,尤其可用性和易运维性特别严重,只有阿里工程师才能操作使用这套数据库,而且阿里工程师还要努力与研发工程师配合协调一致才能够把这套数据库系统稳定下来。领导发话,这个不是世界的数据库,这只是阿里的数据库,严重违背设计我的初衷。我0.4的时候开源,但是接近1.0.0却闭源,很大一个原因是架构设计臃肿,普通工程师难以使用。当时我是由mergeServer、UpdateServer、RootServer、ChunkServer四大块组成,架构设计如下。
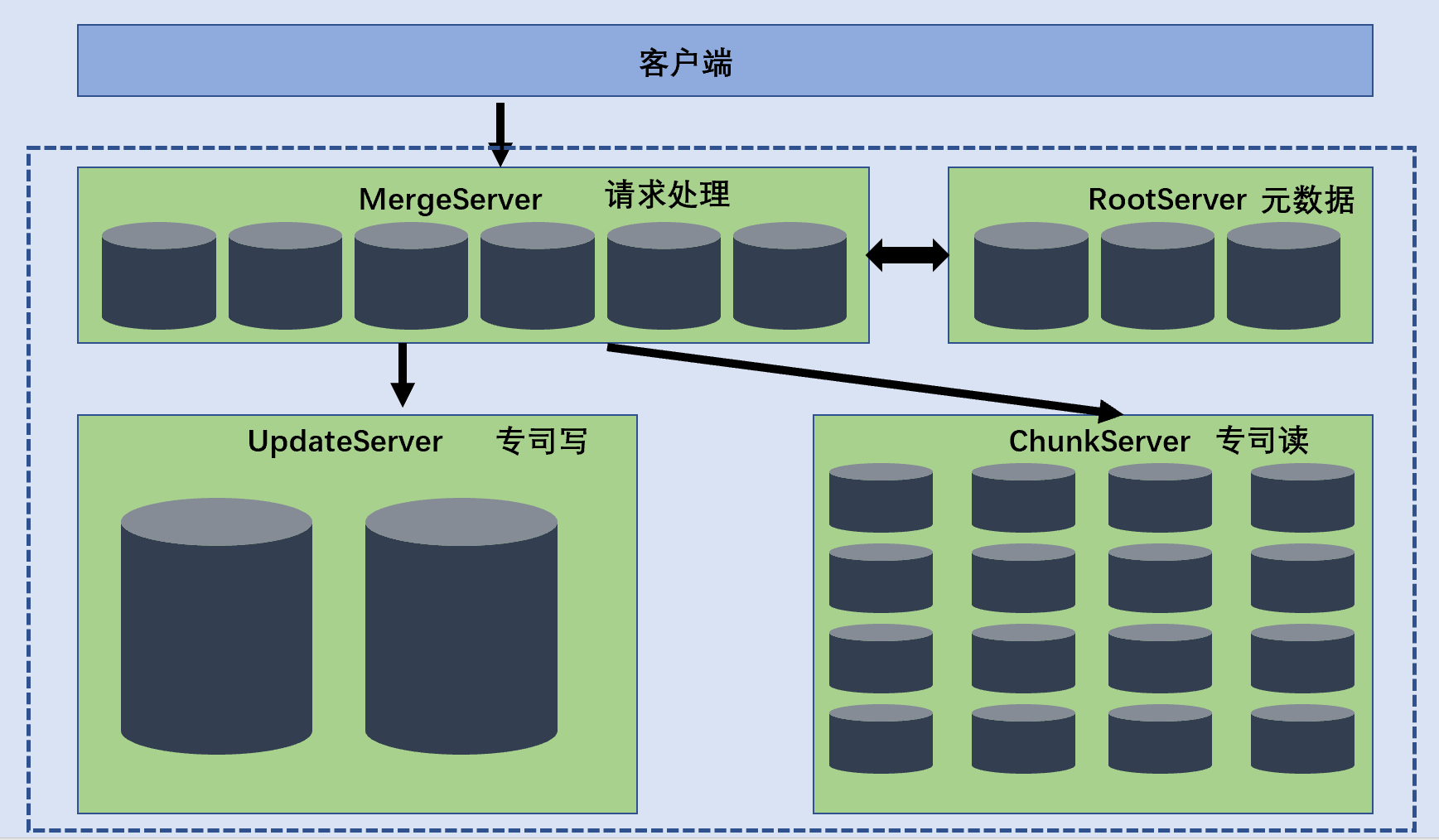
- 客户端: 用户使用OceanBase的方式和MySQL数据库完全相同,支持 JDBC、C客户端使用。基于MySQL数据库开发的应用程序、工具能够直拉迁移到OceanBase。
- RootServer: 管理集群所有的服务器,子表数据分布以及副本管理,RootServer一般为一主一备,主备之间数据强同步。
- UpdateServer: 存储OceanBase系统的增量更新数据。UpdateServer一般为一主一备,主备之间可以配置不同的同步模式。部署时,UpdateServer进程和RootServer进程可以选择共用物理服务器。
- ChunkServer:存储OceanBase系统的基线数据,基线数据一般 存储两分或者 三份,可配置。
- MergeServer: 接受并解析用户的SQL请求,经过词法分析、语法分析、查询优化等一系列操作转发给相应的我ChunkServer或者UpdateServer。如果请求的数据分布在多个ChunkServer上, MergeServer还要对多个ChunkServer返回的结果进行合并。客户端和MergeServer之用原生的MySQL通信协议,MySQL客户端可以直接访问MergeServer。
如果要实现异地多机房方案,每个机房部署一个包括RootServer、MergeServer、ChunkServer以及UpdateServer的完赖OceanBase集群,每个集群由各自的RootServer负责数据划分、负载均衡、集群服务器管理等操作,集群之间数据同步通过主集群的主UpdateServer往备集群同步增量更新操作日志实现。客户端配置了多个集群的RootServer地址列表,使用者可以设置每个集群的流量分配比例,客户端根据这个比例将读写操作发往不同的集群。
当时我非常膨胀,由于我支持双十一的高峰流量和众多产品线,我不仅性能好,还有异地容灾等强大功能,有人称我为水利工程的三峡大坝。
直到一天工程师带我去见客户,客户的需求是一个小水库。在方案演讲时,工程师介绍,我们都可以做到,要把这里炸掉,那里填平,运输十万吨花岗石,二十万吨钢材,客户面面相觑。
我才惊讶我这么多缺点,因为参考了vertica的存储机制,我在读写上解耦分离,UpdateServer专门写增量数据,ChunkServer专门读数据,UpdateServer按策略把数据写入到ChunkServer,UpdateServer有且只有一个存储服务器,一个优点是面对高并发的OLTP请求,OceanBase进行事务处理不需要跨行跨表,不需要进行任何分布式活动, 你不需要考虑 raft协义和paxios协议,不需要考虑两阶段提交,直接写进去就完了。缺点是面向OceanBase的读写请求都必须经过 UpdateServer,这个对UpdateServer提出更高的要求。为此,集团对UpdateServer进行了个性化定制软硬件改造,在内存操作、网络运行、磁盘操作方面做了大量的优化。大量的个性化使我变成了复杂的工程性作品,而不是简单的产品性作品,无法进入客户的心。
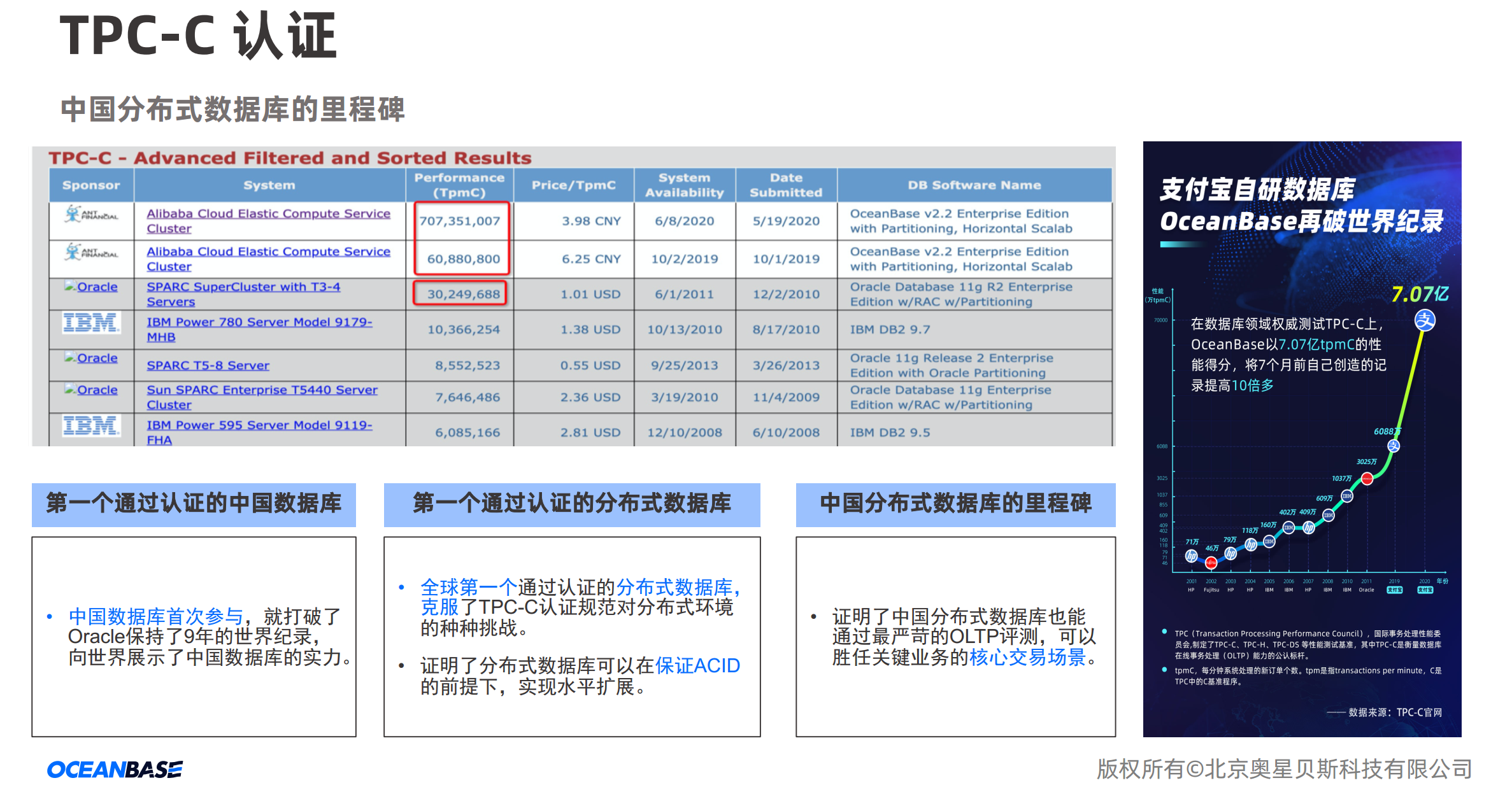
在深入了解民间疾苦后,我的爸爸妈妈决心在我回炉重造,不对公众开放,却有指向性对一些企业投入经营试点,例如南京银行、天津银行等等,根据客户的需求,产品更轻量级,架构重新组织,更关心交易处理时数据的完整性和数据审核性。2019年10月2日,我在TPC-C测试中打破了Oracle保持的世界纪录,以6088万tpmC值的成绩,成为首个登顶TPC-C榜单的中国数据库。
这时侯我的架构设计与以前大不一样了,既追求力量性能,又追求平衡协调。如下。
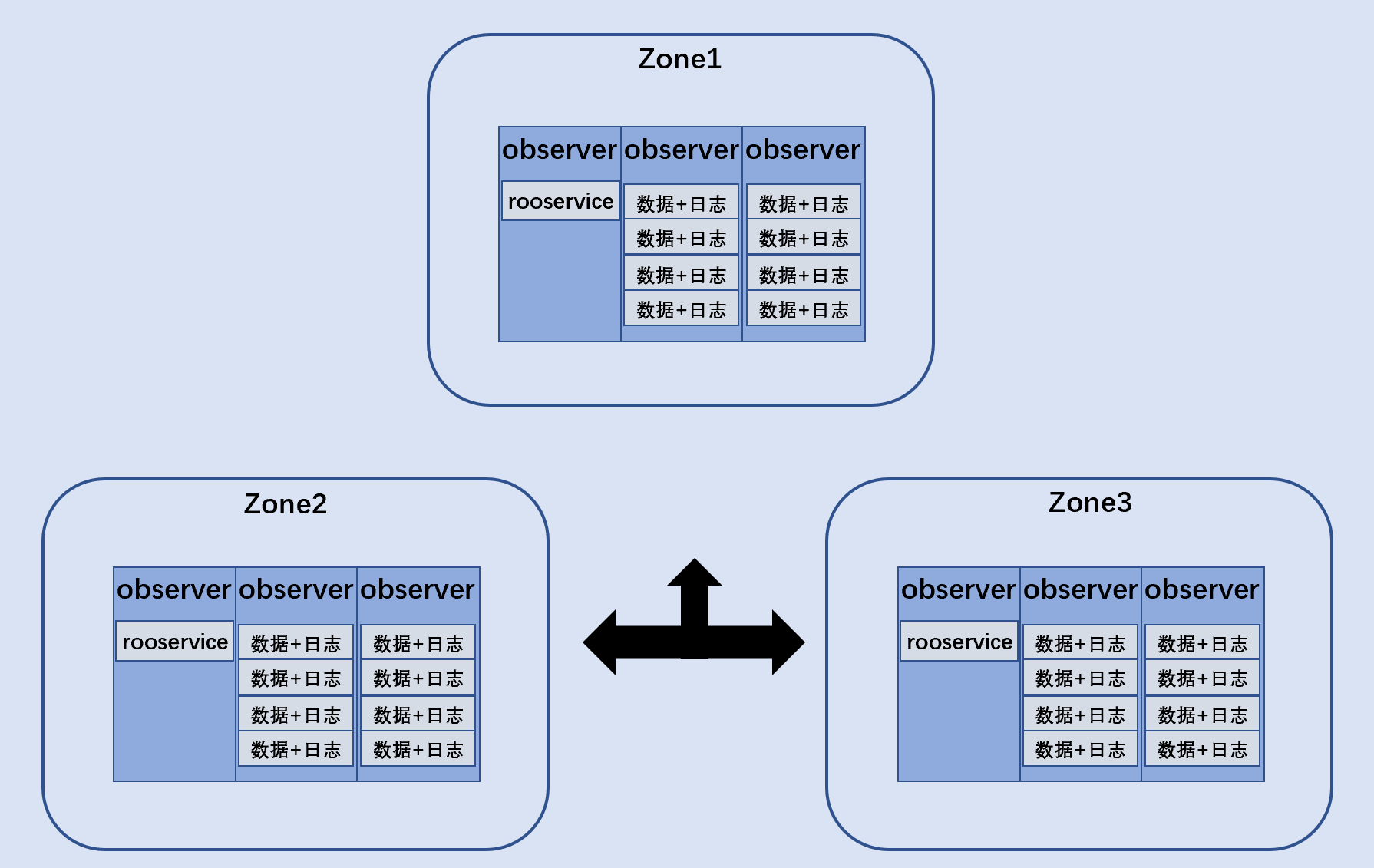
淬火重铸后,我由中心化架构演变成去中心架构,过去分为紫白金青,各有所职,现在每个节点的角色都是平等的。我用上改良后的分布式一致性算法,由标准的两阶段(4次日志延心+2次RPC延迟)到OB两阶段(1次日志延迟+2次RPC延迟)。另外我使用了现在非常流行的LSM Tree作为存储引擎保存数据的基本数据结构,LSM Tree更适合写多读少的应用场景。在LSM的基础上,我额外开发了数据分发功能 ,当内存中的数据合并到硬盘之前,我提前预先分发数据到硬盘上,这样提高了性能。
我的主业依然是OLTP业务场景,毕竟我出身电子商务世家,在我埋首闭源不见世人的时候,我经常与各个银行打交道,了解它们的业务需求并满足它们的需求。我也有一个副业OLAP,副业是为我的主业服务,为此我的存储引擎打造就与orc一样,先按行组织排列,再按列分组,这样虽然不是100%的列式存储,但是你们不要忘了,每个数据产品的列式引擎处理时都需要加载数据,必须要ETL花费大量的时间。而我的数据是交易分析同位一体,这样省掉了大量的时间。
这次我卷土重来,特别关注了开发者的使用体验,毕竟我是为码民服务,所以我加强了索引设计和分区设计。我有唯一索引、全局索引、本地索引,分区有我一级分区和二级分区,索引细粒度划分是让你去指定的范围去找还是整个集群去找,分区的细致划分也是电商复杂业务的需求,某些查询需要更精确的划分。同时我们提供Oracle和Mysql的协议访问,让Oracle和Mysql的开发者可以轻易接入我们。
我最大的一个变化是去中心化,市面上去中心化的数据产品也不少,例 如Cassandra和ElasticSearch都是去中心化,他们都有不俗的性能。为什么 Cassandra会比hbase快,除了Cassandr副本一致性可协调策 略,Cassandr充分使用了每个节点的IO性能,而hbase的master节点很空闲。去中心化是对外说的,对内部而某些节点上面有rootservice,这个就是管理节点,你不用提心,如果它宕掉了会自动选择一个出来。去中心化仍然保留rootservice来做全局管理,如何保障rootservice的高可用性,我通过改良的分布性一致性算法和行业最出名的paxos保障这一点。paxos理论上可比raft、zap等难多了,我的爸爸妈妈非常刻苦才克服了这个难题。
我还有一个特性是资源管理,如何把硬件资源(cpu、内存)分配到最需要数据上,如何实现不同租户之间资源分配,我都已经在数据库层面实现了,相对其它厂商都是在云上或者应用层面实现的。我这个可是了不起的亮点,试想一下僧多了,我这碗小粥也可以按需分配,不至于某些人会饿死,某些人撑得太多。
我是100%独立自主研发,知名TiDB基于rocketsDB研发的,而GaussDB也是立足postgres9.2.4上,我不一定是他们之中最优秀的,但可能是吃苦最多的,毕竟我从0开始,一开场我拿到手是一个sstable文件,这是啥玩意啊?裁判说你把它组成一个数据库,凭什么他们都有选择参考,我却要从无到有开发一个DBMS,裁判叼着一根雪茄,说我的使命与众不同,多年奋斗,我获得的奖项如下。

下面我介绍一下我在蚂蚁集团的内部应用,首先是支付宝核心交易,支付宝最常用的模块,如交易,支付,积分等业务的核心链路都运行在 OceanBase 上,日常每秒都有上万笔交易,双十一期间,每秒可以达到几十万笔交易。支付宝是典型的在线 OLTP 数据库场景,支付宝对 OceanBase 所有核心特性进行了验证,包括响应时间、处理速度、事务的完整性、并发量等,将 OceanBase 真正打磨成了金融级数据库。从产品成熟度上来讲,证明了 OceanBase 能够承担金融在线交易的场景。国内其他的数据库产品很少有机会能够在这么大的场景下,进行实实在在的打磨。第二个应用收藏夹是典型的“写少读多”场景(一次写入、多次读取),峰值的数据读取请求量达到数百万次/秒;而且,由于淘宝巨大的活跃用户体量,这些读请求要访问几个数据量很大的表才能拿到所需数据,其中最大的表保存了数千亿条记录。OceanBase 数据库借助完备的分布式事务能力、完备的 SQL 引擎、优异的性能以及线性水平扩展等能力,很好地解决了海量数据下的在线、高并发、低延时查询等等需求,为数亿淘宝用户提供了良好的使用体验。
2013年斯诺登事件,2018年孟晚舟事件,老外靠不住,国货当自强,敢做领头羊,我是OceanBase,我是中国人打造的数据库,从复杂工程级走到简单产品级,以后我会努力走下去,走入千万家,谢谢大家。
