




一、字符串string
1、reids的字符串是动态字符串SDS,内部结构实现类似于ArrayList,是一块连续的内存空间,采用预分配冗余空间的方式来减少内存的频繁分配,即会先为字符串分配一个内存空间,当字符串的长度小于1M时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间,需要注意的是字符串最大长度为512M。
2、redis字符串又被称为SDS(Simple Dynamic String简单动态字符串),是由一个个字符组成,每个字符有8位字节,在内存中字符串是以字节数组的形式存在,其数据结构如下:
struct SDS {
T capacity; // 数组容量,分配内存空间大小,最小1个字节长度
T len; // 数组长度,实际字符串大小,最小1个字节长度
byte flags; // 特殊标识位,不理睬它,最小1个字节长度
byte[] content; // 数组内容
}
content字段中存储了字符串真实的内容;创建字符串时,capacity和len是一样长的,不会多分配冗余空间,这是因为大多数情况下不会使用append来修改字符串;capacity和len使用泛型T,而不是使用int类型,是因为当字符串比较短时,len和capacity可以使用byte或short来表示,这样会节省内存空间
3、redis对象头结构,RedisObject总共占用16字节的存储空间
struct RedisObject {
int4 type; // 4bits,不同的对象具有不同的类型
int4 encoding; // 4bits,同一个类型的 type 会有不同的存储形式 emb形式和raw形式
int24 lru; // 24bits 记录lru信息
int32 refcount; // 4bytes 每个对象的引用计数,当引用计数为0时,对象就会被销毁,内存被回收
void *ptr; // 8bytes,64-bit system ptr指针将指向对象内容 (body) 的具体存储位置
} robj;
一个字符串占用的存储空间最小为19个字节(16为头结构的字节+SDS最小的3个字节)
4、redis字符串有两种存储方式emb和raw,当字符串长度超过44时,使用raw进行存储,为什么是44个字节呢?
首先上面已经描述了一个字符串最少会占用19个字节,SDS结构中的content字符串是以\0结尾的字符串,所以还会占用一个字节,之所以多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数,以及为了便于字符串的调试打印输出;而内存分配器分配内存大小的单位是以2的n次方来进行分配的(2、4、8、16、32、64),为了能容纳一个完整embstr对象(最少19个字节),所以会为embstr分配最小32字节大小的内存空间,如果字符串再大一些,那就是64字节的空间,如果总体超出了64字节,Redis认为它是一个大字符串,不再使用emdstr 形式存储,而该用 raw 形式。所以emdstr最大能容纳content的长度为64-19-1=44个字节,如果超过了44个字节,则会使用raw来进行存储
5、emb和raw两种存储结构的区别是什么?
embstr存储形式,它将 RedisObject 对象头和SDS对象连续存在一起,使用malloc方法一次分配内存;而raw存储形式需要两次malloc方法分配内存,两个对象头在内存地址上一般是不连续的
6、字符串容量扩容策略
当字符串长度小于1M时,扩容空间采用加倍的策略,当字符串长度大于1M时,为了避免加倍后的冗余空间过大而导致浪费,每次扩容只会添加1M的冗余空间
7、字符串string应用场景
字符串结构应用比较广泛,可以用来存储json格式的数据,比如缓存用户信息、数据库字典json数据等
二、列表list
1、redis的list数据结构相当于java中的双向链表LinkedList,内存是不连续的,是一个链表而不是数组,所以redis list的插入和删除都非常快,时间复杂度为O(1),索引定位(查询)很慢,时间复杂度为O(n);当list链表中弹出最后一个元素后,list链表会被删除,回收其内存
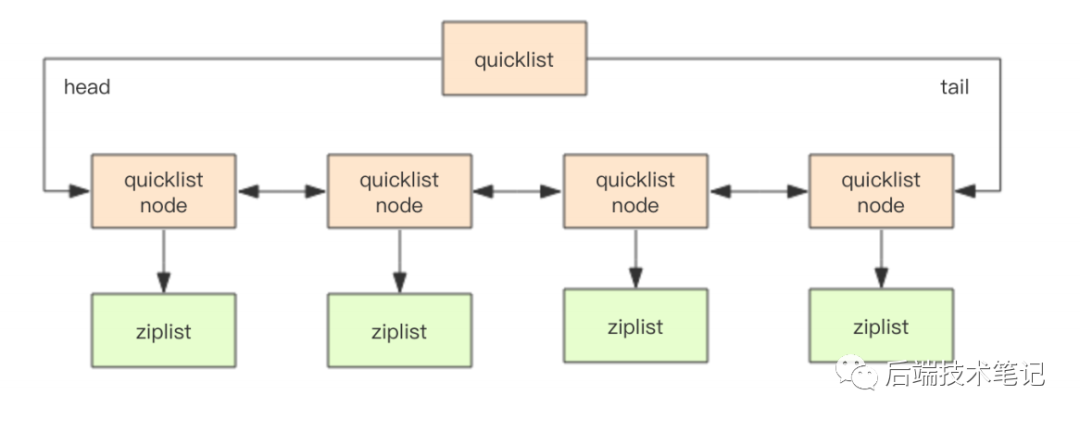
2、redis底层存储的不是一个简单的linkedlist,而是称为快速链表quicklist的数据结构。首先会在列表元素较少的情况下使用一块连续的内存存储,这个结构是ziplist(压缩列表,连续的内存块),它将所有的元素紧挨着一起存储,分配的是一块连续的内存,当数据量比较多的时候才会改成quicklist。Redis将linkedlist链表和ziplist组合起来组成了quicklist,将多个ziplist使用双向指针串起来使用,这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
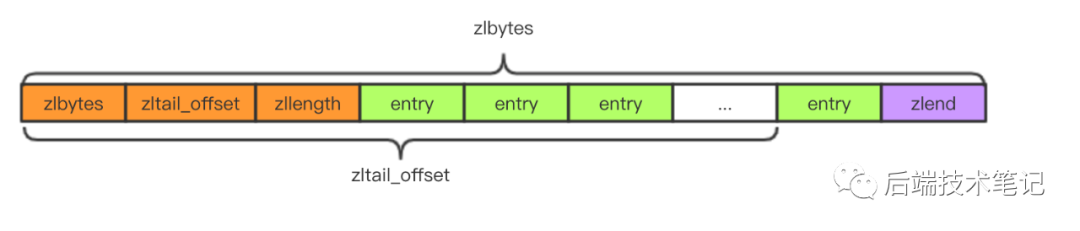
3、ziplist是一块连续的内存空间,通常是用来存储小数据的,存储结构如下:
struct ziplist<T>{
int32 zlbytes; //整个压缩列表占用的字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
zltail_offset字段是为了支持双向遍历,用来定位最后一个节点的位置,便于倒着遍历,ziplist其结构如图
entry数据结构格式为:
struct entry{
int<var> prevlen; //前一个entry的字节长度
int<var> encoding; //元素类型编码
optional byte[] content; //元素内容
}
当压缩列表倒着遍历时,需要通过prevlen来快速定位到前一个entry元素;redis为了节约存储空间,对encoding进行了比较复杂的设计,根据其前缀为来区分内容;content字段在结构体中定义为 optional 类型,表示这个字段是可选的,对于很小的整数而言,它的内容已经内联到 encoding 字段的尾部了,不再需要content字段来存储数据。
4、ziplist优缺点:由于ziplist是连续内存,所以插入元素时,如果内存不够,需要扩充内存,即会重新申请一块更大的内存,将之前的数据全部copy到新内存中,如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。因为是连续的内存,所以在查询定位数据时,会快很多,时间复杂度是O(1)
5、list链表结构:quicklist是ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用ziplist来紧凑存储,多个ziplist之间使用双向指针串接起来。
//链表结构
struct list {
listNode *head; //头节点
listNode *tail; //尾节点
long length; //链表长度
}
// 链表的节点
struct listNode {
listNode* prev; //上一节点
listNode* next; //下一节点
T value; //值
}
quicklist 内部默认单个 ziplist 长度为8k字节,超出了这个字节数,就会新起一个 ziplist
6、列表list应用场景
常被用来当作异步队列使用,将需要延后处理的任务结构体序列化成字符串塞进Redis的列表,另一个线程从这个列表中轮询数据进行处理
三、集合set
1、Redis 的set集合相当于Java语言里面的HashSet,它内部的键值对是无序的唯一的,它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值NULL,当集合中最后一个元素移除之后,数据结构自动删除,内存被回收
2、应用场景
set 结构可以用来存储活动中奖的用户 ID,因为有去重功能,可以保证同一个用户不会中奖两次。
3、intset小整数集合,当set集合容纳的元素都是整数并且元素个数较小时,redis会使用intset来存储集合元素,intset是紧凑的数据结构
struct intset<T>{
int32 encoding; //决定整数位宽是16位、32位还是64位
int32 length; //元素个数
int<T> contents; //元素内容
}

四、哈希hash
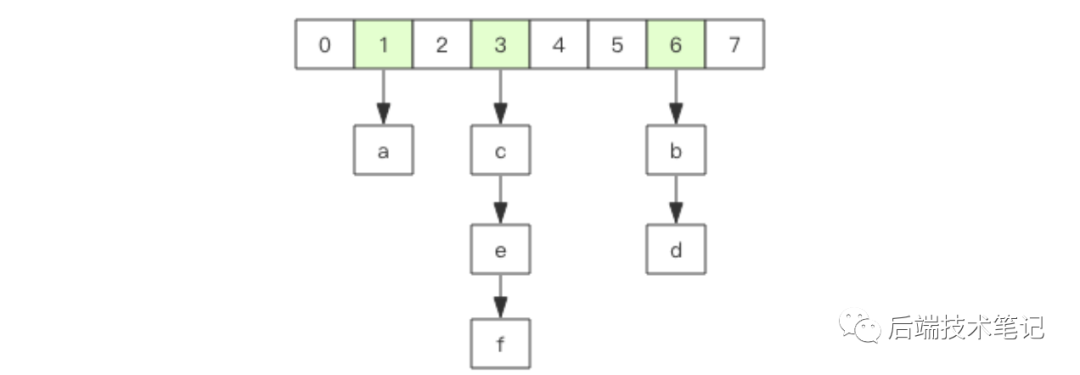
1、redis的hash数据结构相当于java中的HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构,第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。hash的底层是字典
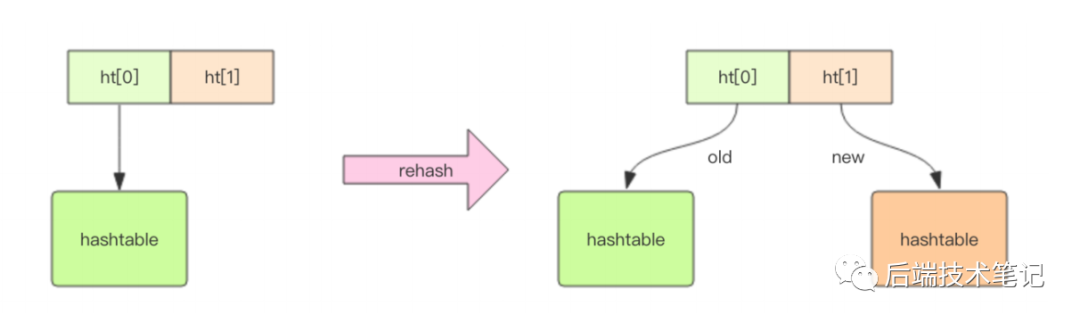
2、dict 是 Redis 服务器中出现最为频繁的复合型数据结构,除了 hash 结构的数据会用到字典外,整个 Redis 数据库的所有 key 和 value 也组成了一个全局字典,还有带过期时间 的 key 集合也是一个字典,zset 集合中存储 value 和 score 值的映射关系也是通过 dict 结构实现的。dict结构内部包含了两个hashtable,通常情况下只有一个hashtable有值,但是在dict扩容和缩容时,需要分配新的hashtable,然后进行渐进式搬迁,这时候两个hashtable存储的分别是旧的hashtable和新的hashtable,搬迁结束后,旧的hashtable被删除,新的hashtable取而代之。hashtable的结构和java的HashMap几乎是一样的
五、有序集合zset
1、它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫做「跳跃列表」的数据结构。zset的内部实现是一个hash字典(类似java的hashmap)加一个跳跃列表skiplist
2、zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,跳跃列表最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。

redis的跳跃表一共有64层,最多可以容纳2的64次方个元素,同一层的kv块使用指针串起来形成一个双向链表,是有序排列的,每一个层元素的遍历都是从 kv header 出发,每一个kv块的数据结构如下所示:
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map ht; // hash 结构的所有键值对
}
struct zslnode {
string value;
double score; //代表value的权重
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
3、应用场景
zset可以用来存粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间进行排序。zset还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们 可以对成绩按分数进行排序就可以得到他的名次。
4、Redis五大数据结构中,能作为字典使用的有hash和zset,hash不具备排序功能,zset则按照score进行排序
六、字典
1、redis中的key都是存储在字典中
2、Java 的 HashMap 在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果 HashMap 中元素特别多,线程就会出现卡顿现象。Redis 为了解决这个问题,它采用渐进式 rehash。它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于 rehash 中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面去寻找。
七、线程 IO 模型
1、Redis是单线程程序,除此之外NodeJS和Nginx也是单线程程序
2、Redis 单线程为什么还能这么快?因为它所有的数据都是在内存中,所有的运算也是在内存中运算的
3、Redis 单线程如何处理那么多的并发客户端连接?redis底层使用了事件轮询 (多路复用)
4、非阻塞IO:当我们调用套接字的读写方法,默认它们是阻塞的,比如 read 方法要传递进去一个参数 n,表示读取这么多字节后再返回,如果没有读够线程就会卡在那里,直到新的数据到来或者连接关闭了,read 方法才可以返回,线程才能继续处理。而 write 方法一般来说不会阻塞,除非内核为套接字分配的写缓冲区已经满了,write 方法就会阻塞,直到缓存区中有空闲空间挪出来了
5、事件轮询API是用来解决什么时候告诉线程可以读取数据、什么时候线程可以写数据(或者说是当数据到来时,如何通知线程,写不完的数据何时可以继续写),最简单的事件轮询 API 是 select 函数;通过 select 系统调用同时处理多个通道描述符的读写事件,因此将这类系统调用称为多路复用 API。最新的多路复用 API已经不再使用select函数,而改用 epoll(linux)和 kqueue(freebsd & macosx),因为 select 系统调用的性能在描述符特别多时性能会非常差,两者的形式略有差异,但本质是一样的;事件轮询 API 就是 Java 语言里面的 NIO 技术
6、Redis会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
7、Redis 同样也会为每个客户端套接字关联一个响应队列。Redis 服务器通过响应队列来将指令的返回结果回复给客户端。
8、redis的定时任务会记录在最小堆的数据结构中,最快要执行的任务排在堆的最上方,在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是 select 系统调用的 timeout 参数。因为 Redis 知道未来 timeout 时间内,没有其它定时任务需要处理,所以可以安心睡眠 timeout 的时间。Nginx 和 Node 的事件处理原理和 Redis 也是类似的
八、持久化
1、redis的持久化是用来保证 Redis 的数据不会因为故障而丢失的一种机制;redis有两种持久化机制,一种是快照,一种是AOF日志;快照是一次全量备份,AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本,AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。 所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
(2)RDB快照原理(数据的备份),redis使用操作系统的多进程copy on write机制来实现快照持久化;redis在持久化时会调用glibc的函数fork一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端的请求;子进程刚产生时,会共享父进程内存里的的代码片段和数据段,这样做是为了节约内存资源;子进程做持久化,不会修改现有内存的数据结构,只会对数据进行遍历读取,然后序列化写到磁盘中。数据段是由很多操作系统的页面(每页数据为4K)组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后对这个复制的页面进行修改。这时子进程相应的页面是没有变化的,还是进程产生时那一瞬间的数据。子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固了,再也不会改变,这也是为什么 Redis 的持久化叫「快照」的原因
(3)AOF日志原理(指令的持久化),AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。redis会在收到客户端指令后,先进行参数校验,如果没有问题,就立即将指令的文本存储到AOF日志文件中,也就是先存到磁盘,然后再执行指令;随着redis实例运行时间越来越长,AOF日志也会越来越多,如果redis实例宕机,重访AOF日志会非常耗时,所以需要对AOF日志进行瘦身;Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身,其原理是开辟一个子进程对内存进行遍历转换成一系列的指令命令,然后序列化到一个新的 AOF 日志文件中,序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件,瘦身工作就完成了。AOF日志写的时候,是先写到内核分配的一个内存缓存中,然后再异步将数据刷到磁盘中,如果此时服务器突然宕机,内存缓存中的数据还没有刷到磁盘中,就会导致数据丢失;linux的glibc提供了fsync函数,可以将指定文件的内容强制从内核缓存刷到磁盘。只要 Redis 进程实时调用 fsync 函数就可以保证 AOF日志不丢失
(4)快照的持久化是通过开启一个子进程来完成的,会遍历整个内存,大块写磁盘会加重系统负载;AOF的fsync 是一个耗时的 IO 操作,也会降低 Redis 性能;所以redis的主节点是不会进行持久化操作,持久化操作主要在从节点进行
(5)混合持久化:在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。只使用rdb快照数据来恢复数据,会丢失大量的数据;只使用AOF日记来恢复数据,性能相对于rdb会很慢,所以使用混合持久化,将 rdb 文件的内容和增量的 AOF 日志文件存在一起
九、管道Pipeline
1、将多个读操作合并在一起只花费一次网络来回,将多个写操作合并在一起只花费一次网络来回
2、一次完整的请求交互流程
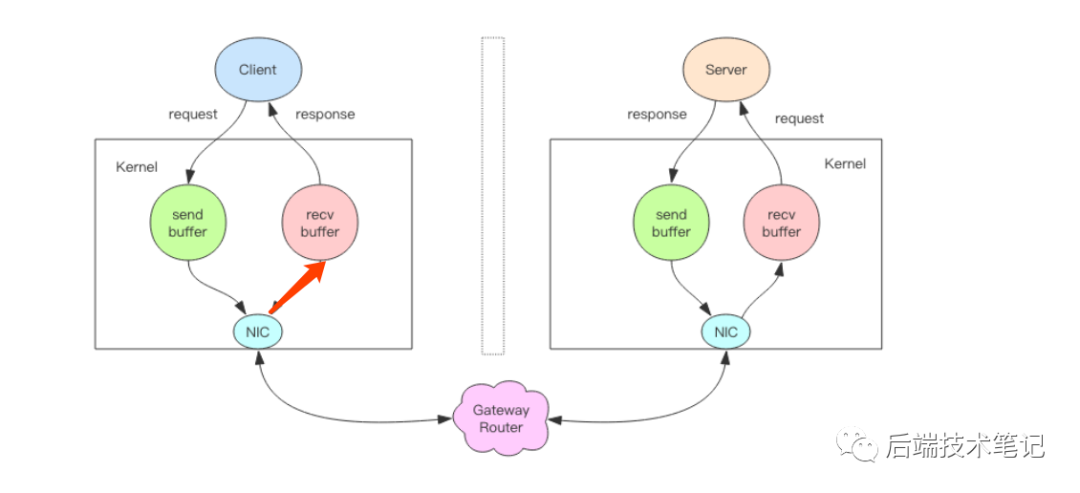
a、客户端进程调用 write 将消息写到操作系统内核为套接字分配的发送缓冲 send buffer。
b、客户端操作系统内核将发送缓冲的内容发送到网卡,网卡硬件将数据通过「网际路由」送到服务器的网卡。
c、服务器操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer。
d、服务器进程调用 read 从接收缓冲中取出消息进行处理。
e、服务器进程调用 write 将响应消息写到内核为套接字分配的发送缓冲 send buffer。
f、服务器操作系统内核将发送缓冲的内容发送到网卡,网卡硬件将数据通过「网际路由」送到客户端的网卡。
g、客户端操作系统内核将网卡的数据放到内核为套接字分配的接收缓冲 recv buffer。
h、客户端进程调用 read 从接收缓冲中取出消息返回给上层业务逻辑进行处理。
3、真正的write操作只负责将数据写到本地操作系统内核的发送缓冲然后就返回了,剩下的事交给操作系统内核异步将数据送到目标机器;真正的read操作只负责将数据从本地操作系统内核的接收缓冲中取出来就结束了,其余的都是操作系统内核去完成的
4、为什么redis不支持回滚事务,因为只有当被调用的Redis命令有语法错误时,这条命令才会执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现
十、内存回收机制
1、有时进行redis内存回收时,会发现内存变化不会太大,因为操作系统的内存回收是按照页为单位,如果这个页上只要有一个key还在使用,就不会回收掉这页的内存,而redis的key是分散到很多页上的,每个页都还有其他key存在,这就导致了内存不会立即被回收
2、使用flushdb,然后再去观察内存会发现内存确实被回收了,因为所有的key都被删除掉了,大部分使用的页都完全干净了,会立即被操作系统回收。Redis虽然无法保证立即回收已经删除key的内存,但是他会重用那些尚未回收的空闲内存
十一、redis过期策略
1、redis会将每个设置了过期时间的key放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的key;除了定时遍历外,还会使用惰性策略来删除过期的key,惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除;定时删除是集中处理,惰性删除是零散处理
2、定期扫描策略:redis默认会每秒进行10次过期扫描,过期扫描不会遍历过期字典中所有的key,而是采用一种贪心策略,从过期字典中随机检查20个key,然后删除20个key中已经过期的key,如果过期的key比率超过了1/4,则重复上述步骤;为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过25ms。
3、如果所有的key在同一时间过期,redis会持续扫描过期字典(循环多次),直到过期字典中过期的key变得稀疏,才会停止;redis循环扫描会造成读写请求出现明显的卡顿现象。
4、从库的过期策略:从库不会进行过期扫描,从库对过期的处理是被动的,主库在key到期时,会在AOF文件中增加一条del指令,同步到所有的从库,从库通过执行这条del指令来删除过期的key
5、redis提供了maxmemory配置参数来限制内存的大小,当实际内存超出maxmemory时,redis提供了一些策略来让用户自己决定如何腾出新空间来提供读写服务
a、noeviction策略:不会继续执行写请求,读请求和del请求继续继续服务,这是默认的淘汰策略
b、volatile-lru策略:尝试淘汰设置了过期时间的key,最少使用的key优先淘汰,没有设置过期时间的key不会被淘汰
c、volatile-ttl策略:尝试淘汰设置了过期时间的key,key的剩余寿命ttl的值越小,越优先淘汰
d、volatile-random策略:随机淘汰设置了过期时间的key
e、allkeys-lru策略:从所有key集合中淘汰最少使用的key,没有设置过期时间的key也会被淘汰
f、allkeys-random策略:从所有key集合中随机淘汰一部分key
6、LRU算法:实现LRU算法除了需要key/value字典外,还需要一个附加的链表,链表中的元素按照一定的顺序进行排列,当空间满的时候,会踢掉链表尾部的元素,当字典中的某个元素被访问时,他在链表中的位置会被移动到表头,所以链表的元素排列顺序就是元素最近被访问的时间顺序,位于链表尾部的元素就是不被重用的元素,所以会被踢掉。位于表头的元素就是最近刚刚被人使用过的元素,所以暂时不会被踢。
7、redis使用近似LRU算法,因为LRU算法需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造;近似LRU算法则很简单,它给每个key增加了一个额外的小字段,这个字段长度是24bit,用来存储最后一次被访问的时间戳;redis的近似LRU算法是就是随机采样出5(可以配置)个key,然后淘汰掉最旧的key,如果淘汰后内存还是超出maxmemory,那就继续随机采样淘汰,直到内存低于maxmemory为止。
