




在数字化业务高度依赖数据的今天,数据库的毫秒级延迟可能意味着数百万的损失,而一次宕机更是可能演变为品牌危机。
现代数据库监控工具已经超越了简单的“仪表盘”角色,进化为保障业务连续性的智能中枢,其核心能力正围绕两大关键指标展开:平均检测时间(Mean Time to Detect,MTTD) 与平均修复时间(Mean time to repair,MTTR)。它们共同构成了从异常“观测”到问题“解决”的完整闭环,是衡量运维体系效能的核心标尺。
性能工程专家、Netflix前性能架构师Brendan Gregg曾讲过一段非常有启发的话:
The most critical function of a monitoring system is not just data collection, but the ability to translate those data into actionable insights and immediately alert on deviation from baseline performance. Mean Time To Detect (MTTD) directly impacts Mean Time To Recovery (MTTR).
这句话的意思是说,监控系统最重要的功能不仅是数据收集,更重要的是将这些数据转化为可执行的洞察,并在性能偏离基线时立即发出警报。平均检测时间 (MTTD) 直接影响平均恢复时间 (MTTR)。
一、MTTD:感知的广度与智能的深度
降低MTTD的本质,是将被动告警变为主动预测,其核心是构建无处不在的感知网络(数据采集)与智能分析能力。数据库从来不是单独的存在,其与系统的耦合性必然要求更全面的感知与数据探查。
-
多层次监控与统一可观测性:现代工具不再局限于CPU、内存等基础指标,而是构建了从基础设施层(服务器、存储)、数据库层(慢查询、锁等待、连接池)到应用层(业务事务性能)的全栈监控。通过整合日志(Logs)、指标(Metrics)和追踪(Traces),实现统一可观测性,让任何角落的性能劣化都无处遁形。云和恩墨zCloud数据库监控功能,通过全面的数据采集和整合展示,删繁就简,让突出问题与状况一目了然。如图1所示,数据库所在主机的CPU、内存使用情况同时展示出来,此外,数据库最突出等待事件、使用率增长最快的表空间同列显示,让DBA可以一目了然,有问题可以下钻,平安无事则可略过泰然处之。
 图1 数据库实例监控列表
图1 数据库实例监控列表
数据库监控实例列表在数据库数量变多(20套、30套…等)的情况下,作用会更突出,DBA管理员可以选择关注的重点,并全面的了解数据库资产的资源负载情况。 -
智能基线告警与异常预测:摒弃简单的静态阈值,工具通过学习历史数据,为每项指标建立动态的智能基线。它能识别出“周二上午的查询本就比周末慢30%”的正常模式,却能在“同一查询突然激增200%”时精准告警。更进一步,通过时序预测算法,部分工具能在容量即将耗尽、性能拐点出现前发出预警,实现真正的事前干预。图2显示了zCloud在实例列表页面,即可通过鼠标悬停展示重点预警项,超过基线的风险项随时可以提示出来。
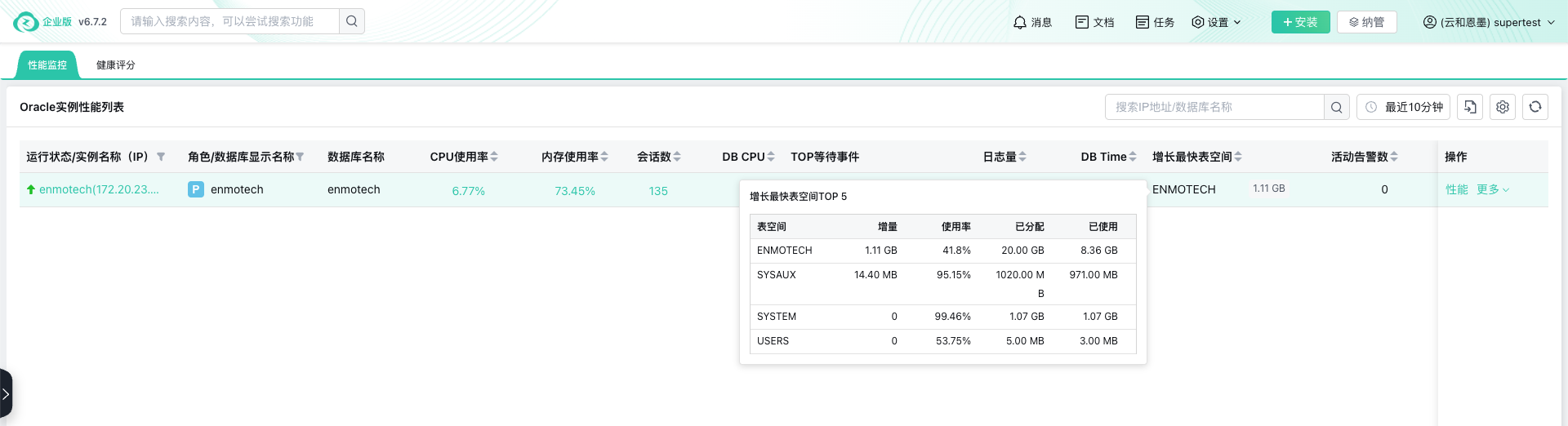
图2 空间增长的快捷预警 -
根因关联与快速定位:当告警触发时,真正的挑战才开始。高级监控工具通过拓扑映射与因果分析,能自动关联异常。例如,它不仅能发现API响应变慢,更能自动追溯到是某个数据库分片磁盘I/O饱和所致,再关联到一条最近上线的、未加索引的批量查询语句,将根因定位时间从小时级缩短至分钟级。云和恩墨zCloud数据库监控能够准确识别出性能问题,并给出解决方案。例如 图3 中展示了一个Oracle数据库的监控曲线,通过TOP SQL的列表,可以识别出性能隐患。
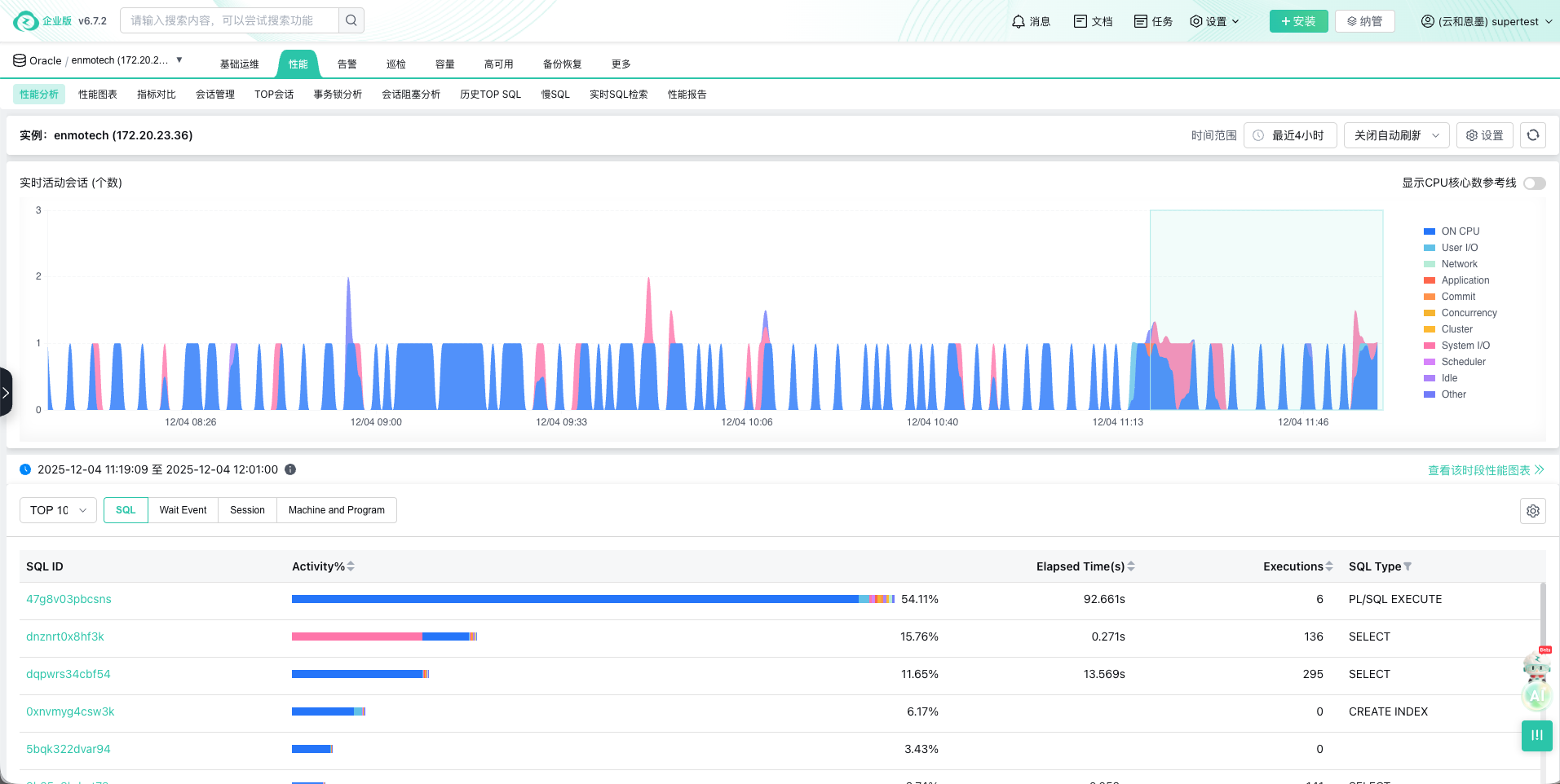
图3 数据库监控的性能主页面
二、MTTR:行动的效率与恢复的确定性
降低MTTR的目标,是将手忙脚乱的故障救火,变为高效、有序、可沉淀的恢复流程。
-
集成诊断与上下文共享:优秀的工具在告警通知中,不仅包含“发生了什么”,更附带“可能的原因”与一键直达的诊断面板。它将相关的性能图表、错误日志、变更记录(如最近的部署)和拓扑上下文打包呈现,让运维人员无需在多个系统间拼凑信息,开箱即用,极大地缩短了诊断时间。云和恩墨的zCloud数据库监控平台,在识别到问题之后,可以快速解决。如图4 所示,性能问题的成因在于一条新的业务SQL。相关数据表缺乏统计信息,执行计划选择不优化,也缺乏有效的所以。可以通过收集统计信息,为数据库执行计划给出正确的指引。
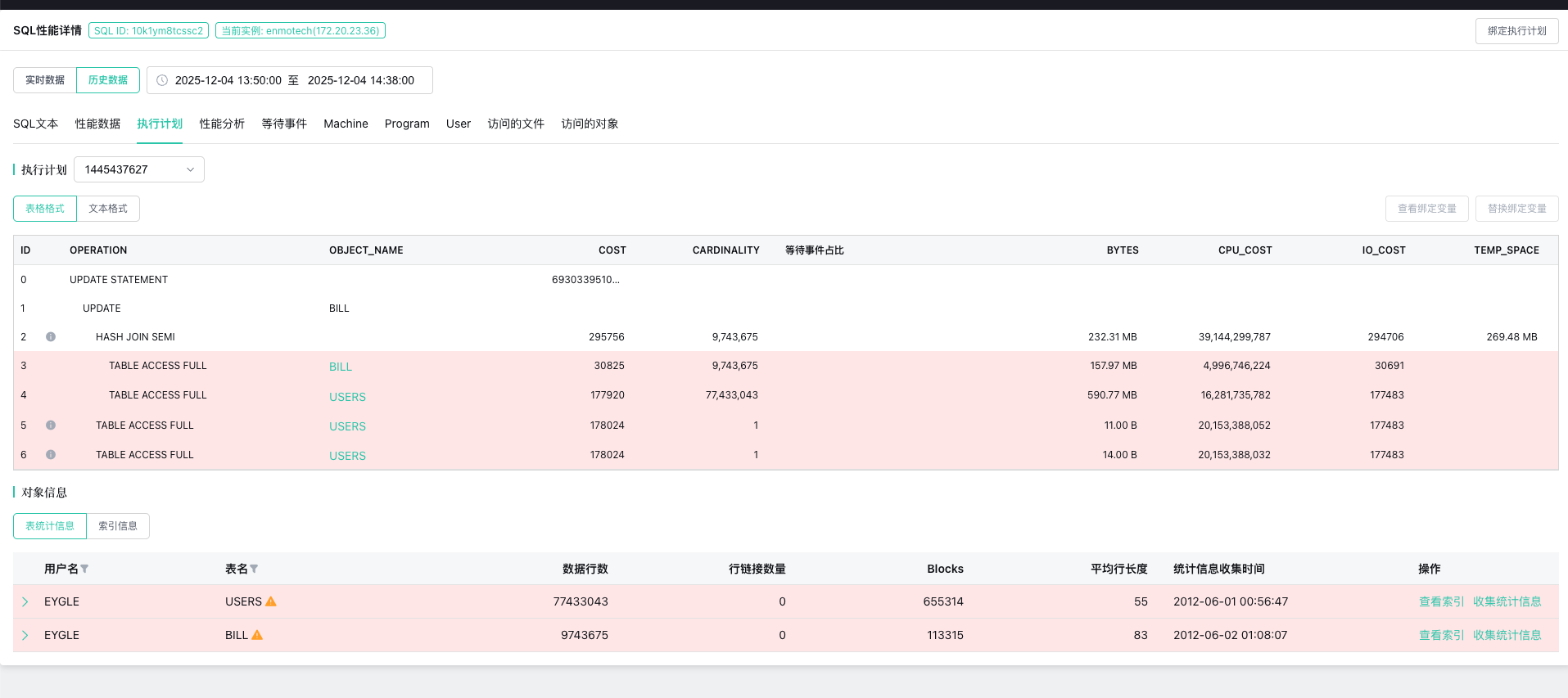
-
预案自动化与安全修复:针对已知的常见故障模式(如主从切换、索引重建、连接池清空),监控工具可与自动化运维平台集成,提供标准化、可审批的修复预案。工程师在确认后,可一键安全执行,避免手动操作失误。这不仅能将修复动作从小时级压缩至分钟级,更将操作过程标准化、可审计。云和恩墨的zCloud数据库监控平台,还内置了AI助手,可以通过AI分析问题SQL,给出只能建议。如图5所示,建议非常精准。
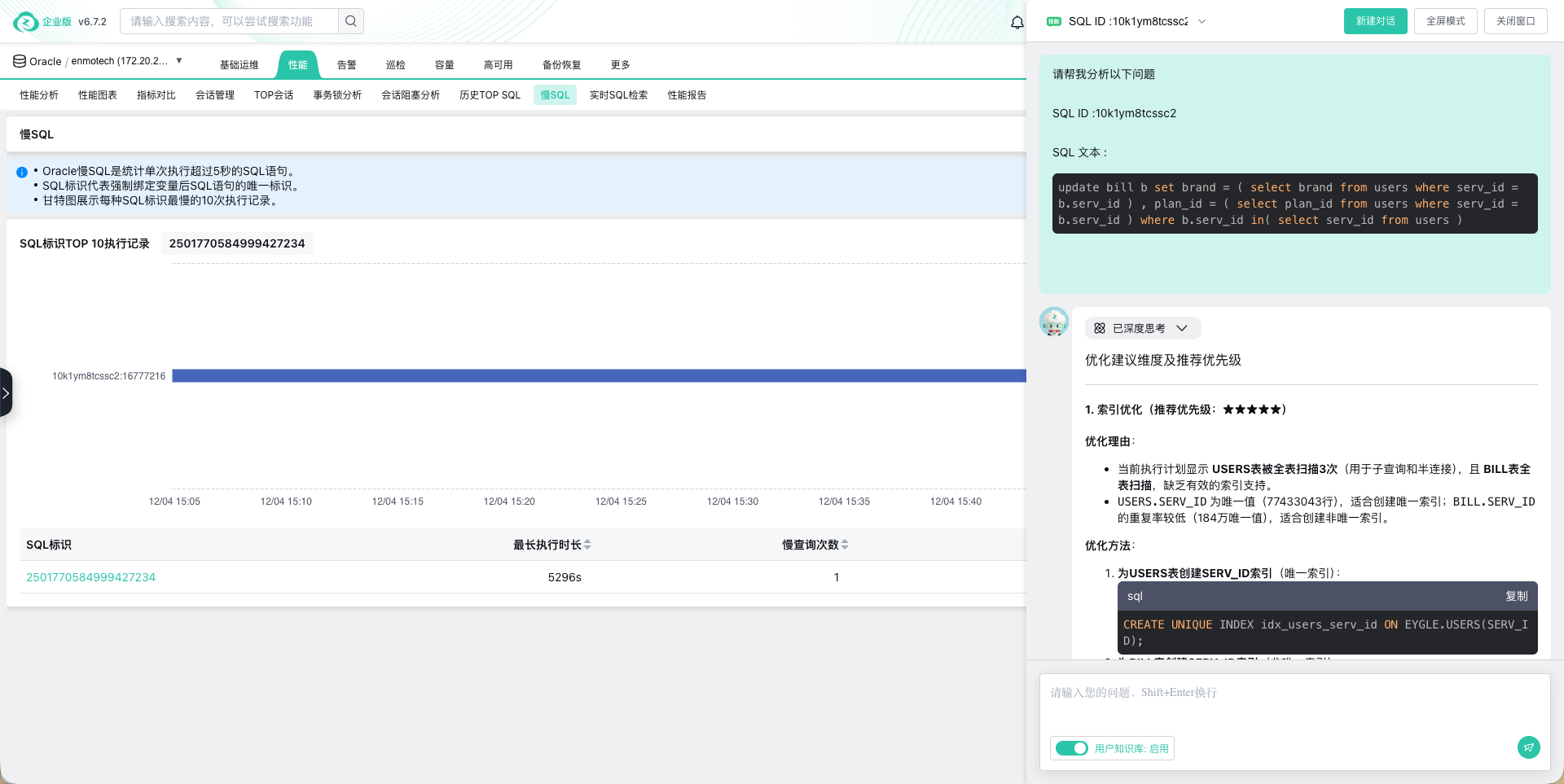
-
影响评估与变更验证:修复完成后,系统是否真正恢复正常?工具通过持续比对修复前后的核心业务指标(如交易成功率、响应时间P99值),提供客观的恢复验证。同时,它还能评估本次故障影响的用户数、交易量或收入,为事后的故障复盘提供精准的数据支持。
三、协同闭环:从指标到业务韧性
MTTD与MTTR并非孤立存在,而是相互促进的飞轮。更短的MTTD为修复争取了宝贵的时间窗口,可能将问题扼杀在影响用户之前;而每一次MTTR的实践,又为知识库添加了新的预案,使系统对未来同类故障的MTTD趋近于零。
最终,衡量一个数据库监控工具价值的,不再是它有多少华丽的图表,而在于它是否能持续地、可度量地压缩从异常发生到业务恢复的“痛苦时间”。通过将MTTD与MTTR这对核心指标深度融入产品设计,现代监控工具正使运维团队从被动的“救火队”,转变为保障业务韧性的主动防御者与价值创造者。
