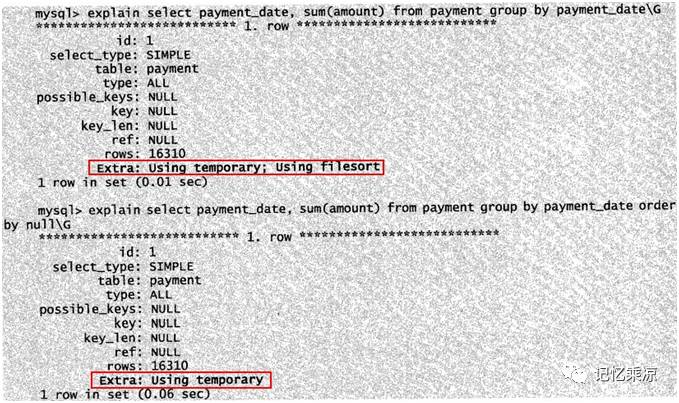
202:针对一个 SQL,会将主外表以及主外键找出来,画出关联关系,找到严格限制条件。
203:多列索引的致命弱点。
5.6 版本中,多列索引建立的时候,尽量将选择性高的列放在前面
使用多列索引会按照列的索引顺序执行,前面的列不使用索引,后面的也不会走索引。
多列索引相对于单列更有优势,会节省空间提高效率,建立多列索引时,应该将最热的列放在前面,相同热度的情况下将严格的索引放在前面,前者是为了能够更多的选择使用索引,后者是为了走索引筛选的力度更大,效率更高。
204:分析一个SQL的资源消耗情况,分别对应的场景,包括 IO、cpu、用户线程、网络。
以下过程都需要耗时耗资源:
1.应用程序与数据库服务器建立链接
2.sql发送到数据库,数据库验证是否有执行的权限
3.进入语法解析器,进行词法与语法分析
4.进入优化器生成执行计划,部分dbms会检查是否有可重用的执行计划
5.根据执行计划依次扫描相关表中的行,不在数据缓冲区的走io
6.同时对于被扫描的行可能加锁,同时也可能会被其他sql阻塞
7.扫描的行足够放入查询缓存则开始运算或直接返回,不够则生成临时表,可能消耗io
8.对sql结果进行计算(可能)
9.将计算完成的结果全部写入网络io(可能)
10.如果事务完成则同步事务日志并释放锁,具体方式取决于dbms和当前配置
11.关闭连接(可选)
205:糟糕 SQL 的定义。
1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2.I/O吞吐量小,形成了瓶颈效应。
3.没有创建计算列导致查询不优化。
4.内存不足
5.网络速度慢
6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)
7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)
8.sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9.返回了不必要的行和列
10.查询语句不好,没有优化
造成以上情况的SQL就是糟糕的SQL。
206:innodb_rows_read的定义,包含索引和表访问行数。
innodb_rows_read: 平均每秒从innodb表读取的行数
207:多列索引的存储规则、对应的使用特点。
MySQL能在多个列上创建索引。一个索引可以由最多15个列组成。(在CHAR和VARCHAR列上,你也可以使用列的前缀作为一个索引的部分)。
一个多重列索引可以认为是包含通过合并(concatenate)索引列值创建的值的一个排序数组。
当你为在一个WHERE子句索引的第一列指定已知的数量时,MySQL以这种方式使用多重列索引使得查询非常快速,即使你不为其他列指定值。
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 andb = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b= 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinctcol)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
208:多列索引的高效使用。
1、where 条件中必须有多列索引的第一个列;
2、尽量将 card 高的列放在前面,否则索引本身的效率不高,但是不影响对表的访问效率;
3、多列的几个条件必须是 and;
4、误区题目
对于一个表来说,where条件中经常出现 a、b、c、bc、ac,请问该如何建立索引?
建立bc和ac的联合索引和c单列索引;
209:使用索引去除排序
1、 改写 SQL,改写 order by 列
MySQL中的两种排序方式:
①通过索引顺序扫描直接返回有序数据,不需要额外排序,效率较高 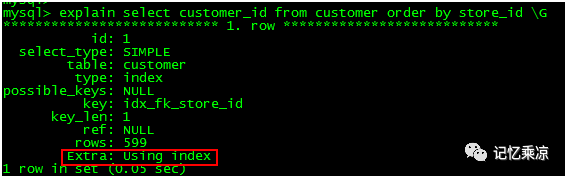
②通过对返回数据进行排序,也就是通常说的 filesort 排序
总结:

2、 增加索引、force hints 强制走排序索引
FORCE INDEX
强制MySQL使用一个特定的索引,可以在查询中使用 FORCE INDEX 作为HINT。
210:使用索引去除排序的应用场景
1、产生了极大数据量的排序,造成严重的 Sort_merge_passes;
2、不能通过 set @@session.sort_buffer_size=32M;来轻易解决;
3、尽量不要使用索引来解决排序问题,而要使用索引来解决过滤问题;
211:在 group by 分组列上建立索引来消除分组聚合产生的排序行为。
①默认情况下,所有的group by都要进行排序;
②如果显示的包含了一个相同列的ORDER BY子句,则对性能影响不大;
③如果想要避免排序结果的消耗,可以指定 ORDER BY NULL 禁止排序;