




前言
昨天在群里发了几张执行计划可视化的图,不少群友都在问是什么工具如此给力。今天正式介绍一下 (本文基于论文 — Jovis: A Visualization Tool for PostgreSQL Query Optimizer) 在传统 PostgreSQL 里,当我们要分析一个 SQL 性能问题时,我们最多只能看到:
EXPLAIN / EXPLAIN ANALYZE 最终选出的执行计划
PEV、pgAdmin 这类工具,把最终的计划树画出来
缺失的一块是:
优化器在背后到底考虑了哪些候选路径、join 顺序、考虑了哪些算子组合?
为什么最后选了这个 plan?哪些 plan 被淘汰了、成本如何?
这些 rows 是如何预估出来的?
Jovis 的定位就是把 PostgreSQL 标准 DP 优化器 + GEQO 的内部决策过程 (search space, paths, costs) 完整记录下来,并用可视化方式呈现,同时允许用户通过 hint / GEQO 配置参与优化过程。
Jovis 的核心优势
现有工具只显示最后的 Plan Tree,Jovis 显示的是:
标准优化器:所有 path / join order / 算子组合的 DAG + 成本演化
GEQO:每一代 population 中各个 gene (join 序列) 的 cost、进化过程
它会告诉你为什么选这个 PLAN,以及各个 PLAN 的计划对比。同时覆盖两种优化策略:DP + GEQO。另外值得一提的是,用户可引导优化:Jovis 还整合了 pg_hint_plan,用 /*+ ... */ 语法对算子 / join order 下 hint,看 hint 对 search space / costs 的影响。
架构组成
Patched PostgreSQL,此 patch 会在优化器内部增加详细日志输出,并将日志写入文本 log 文件,对原有优化逻辑干扰很小,论文称之为 lightweight / non-intrusive patch。比如
标准优化器:path 枚举信息、每个 path 的成本、join 序列等
GEQO:每一代的 gene(join 序列)、cross-over 操作、各 gene 的 cost
Backend:一个 python 服务:
接收前端提交的 SQL
调用带补丁的 PostgreSQL 执行:
完整优化 + 执行
同时生成优化器 log
解析 log:
判断使用的是标准优化器还是 GEQO
提取 path 列表、join 序列、cost 信息等
转换为结构化 JSON,连同查询结果一起发给前端进行可视化
Frontend (React + D3.js)
提供 SQL 编辑、Presets/History 管理、查询选择等 UI
两大核心视图:
标准优化器规划视图(DAG)
GEQO 规划视图(基因 heatmap + cost 曲线 + cost 分解图)
另有 EXPLAIN 视图,把最终计划画成树,类似 PEV2
实践
部署过程就不演示了,以如下 SQL 为例
postgres=# explain SELECT c.customer_id,
count(*) AS cnt,
sum(o.amount) AS total_amount
FROM (
SELECT * FROM customer
WHERE credit_score > 700
) c
JOIN (
SELECT * FROM orders
WHERE status = 0
) o
ON o.customer_id = c.customer_id
GROUP BY c.customer_id
ORDER BY total_amount DESC
LIMIT 100;
QUERY PLAN
---------------------------------------------------------------------------------------------
Limit (cost=31579.98..31580.23 rows=100 width=44)
-> Sort (cost=31579.98..31642.79 rows=25125 width=44)
Sort Key: (sum(orders.amount)) DESC
-> HashAggregate (cost=30305.66..30619.72 rows=25125 width=44)
Group Key: customer.customer_id
-> Hash Join (cost=2595.06..28698.29 rows=214316 width=10)
Hash Cond: (orders.customer_id = customer.customer_id)
-> Seq Scan on orders (cost=0.00..23864.00 rows=853000 width=10)
Filter: (status = 0)
-> Hash (cost=2281.00..2281.00 rows=25125 width=4)
-> Seq Scan on customer (cost=0.00..2281.00 rows=25125 width=4)
Filter: (credit_score > 700)
(12 rows)
EXPLAIN 类似 PEV,树状的结构

在左侧的 Query Planning 中,可以看到还有 NLP,MergeJoin,毋庸置疑,这二者的代价肯定要比 Hash Join 高,被优化器淘汰了,我们可以通过 PLAY 按钮观察路径选择方式。
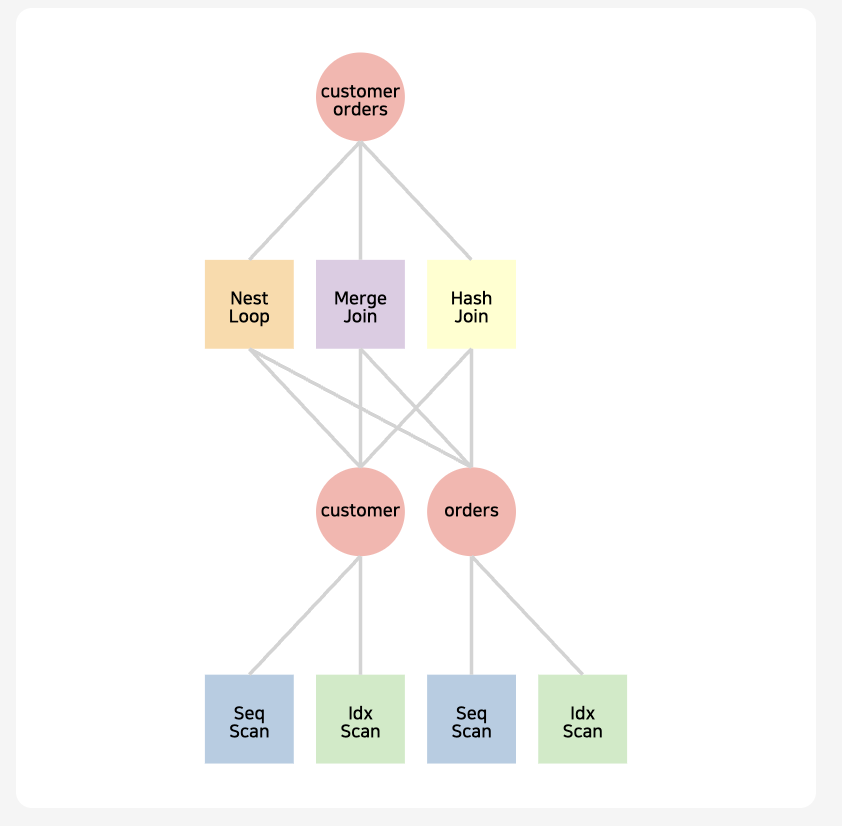
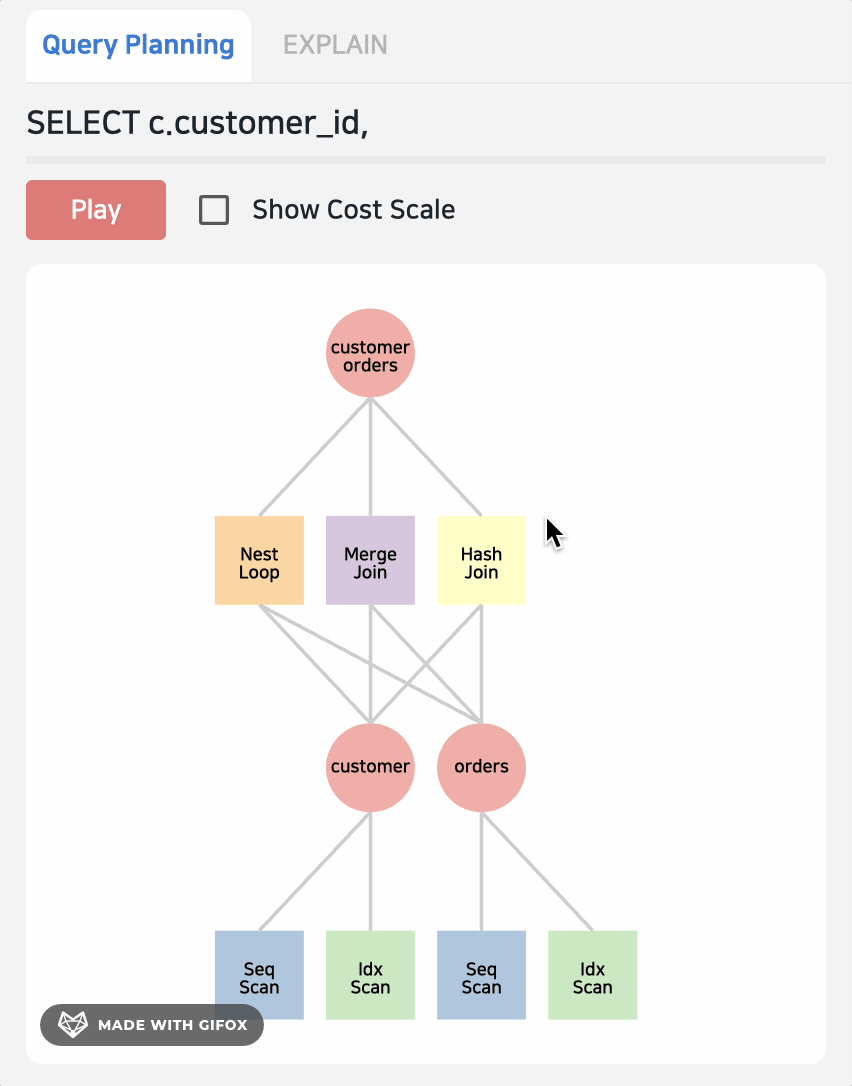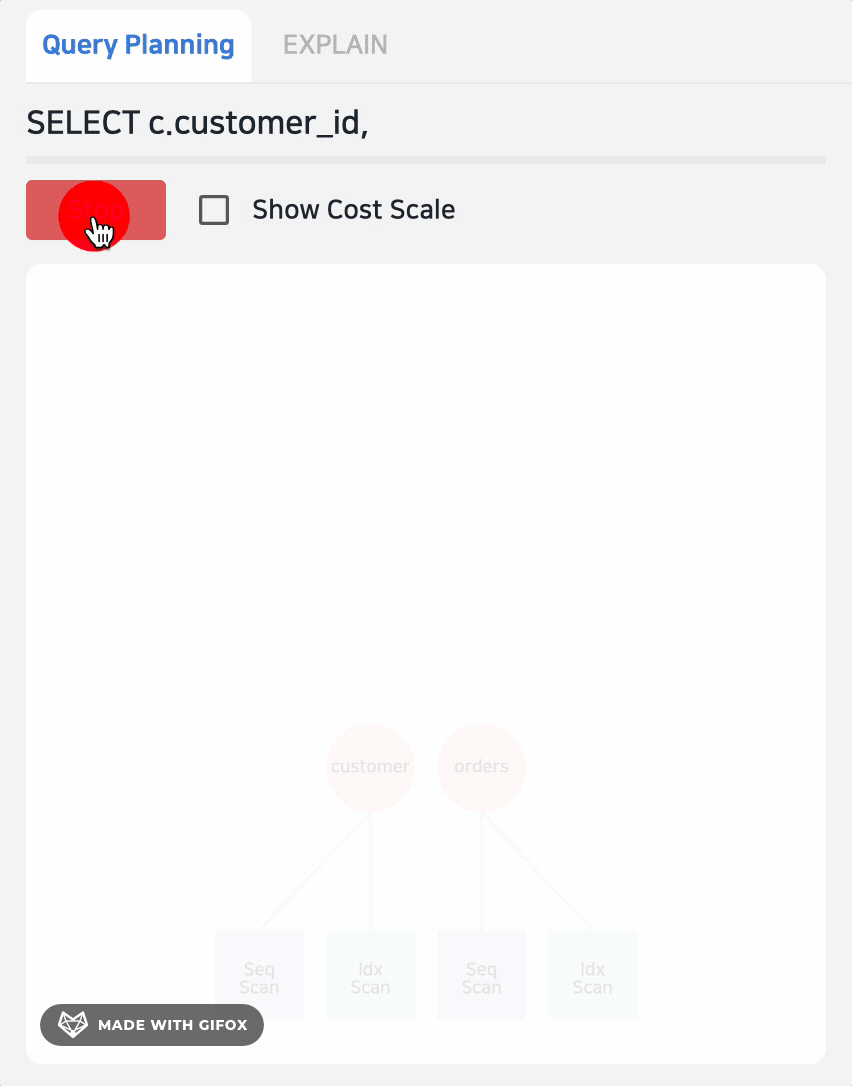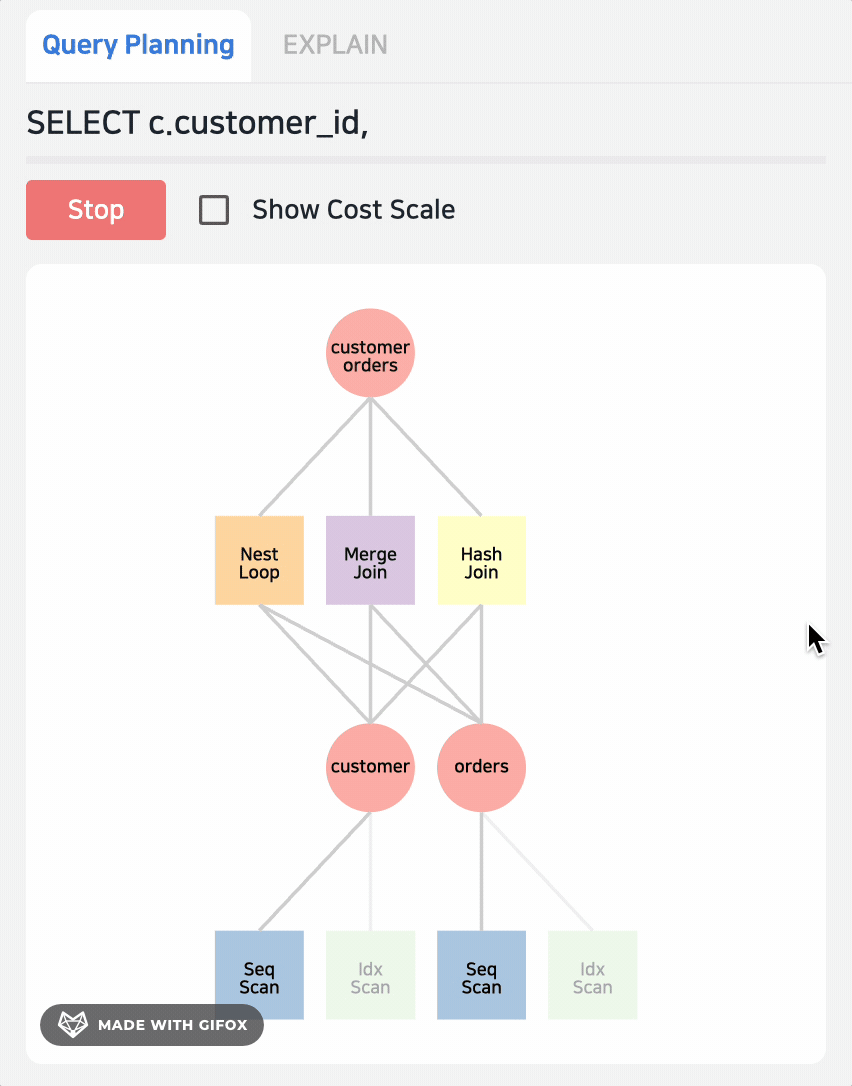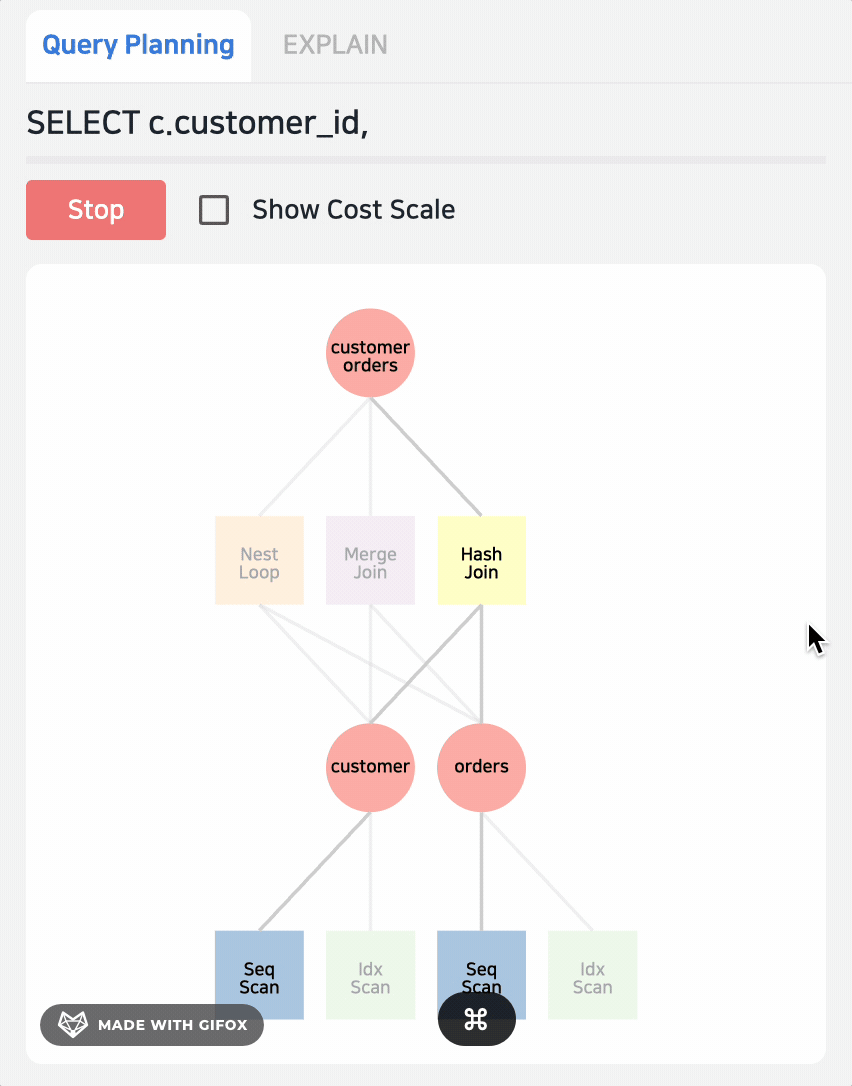
很多时候,优化器会选择一个错误的执行路径,但是我们并没有太好的方式,要么通过 HINT,要么手动会话级调整;有了 Jovis 的帮助,我们可以了解其内部,点击具体的算子可以看到其详细计算过程,比如此例的 NestLoop 的成本是 58142,以及相应的 rows
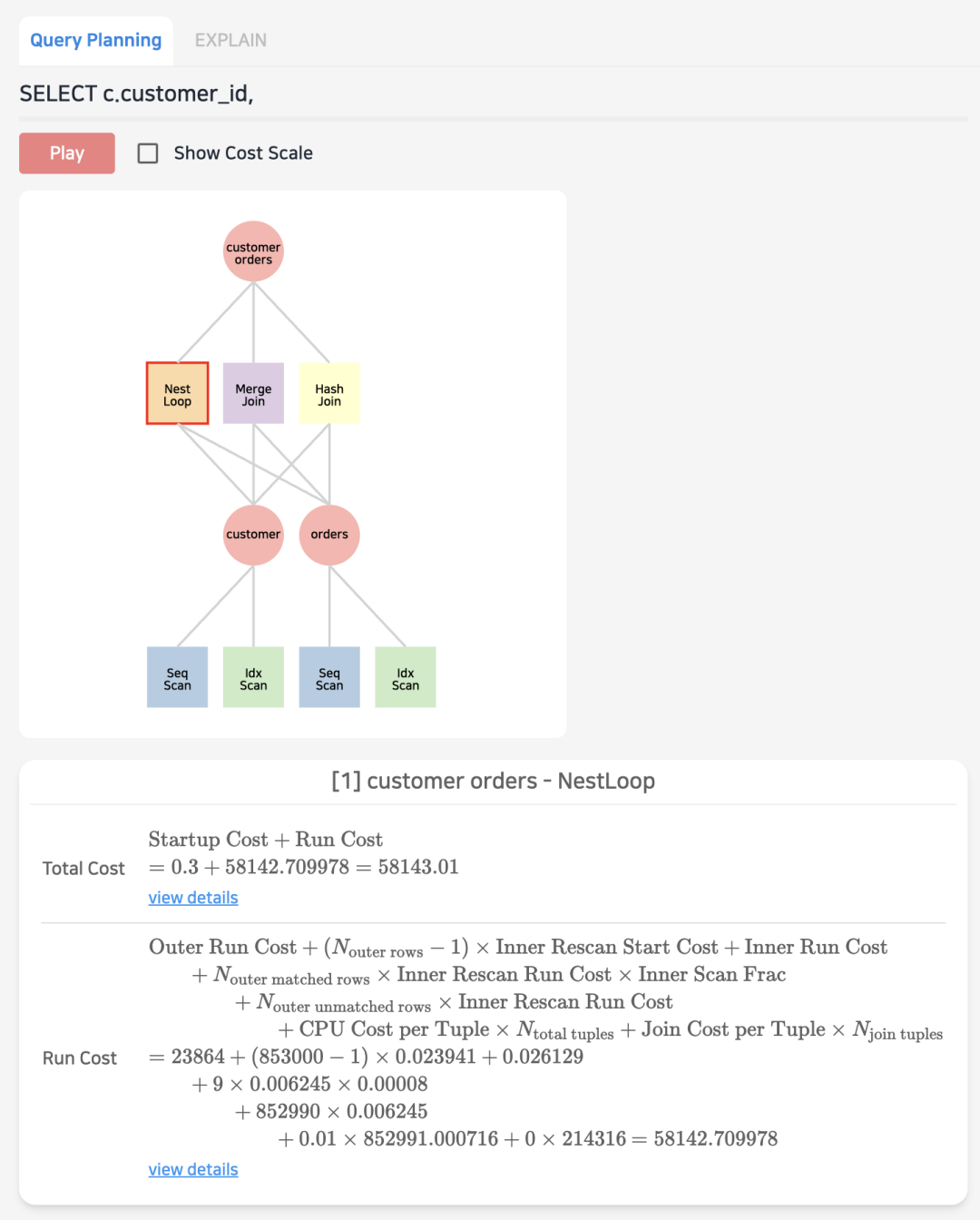
让我们在数据库中确认一下,可以看到总成本确实是 58143.01
postgres=# set enable_hashjoin to off;
SET
postgres=# explain SELECT c.customer_id,
count(*) AS cnt,
sum(o.amount) AS total_amount
FROM (
SELECT * FROM customer
WHERE credit_score > 700
) c
JOIN (
SELECT * FROM orders
WHERE status = 0
) o
ON o.customer_id = c.customer_id
GROUP BY c.customer_id
ORDER BY total_amount DESC
LIMIT 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Limit (cost=61024.70..61024.95 rows=100 width=44)
-> Sort (cost=61024.70..61087.52 rows=25125 width=44)
Sort Key: (sum(orders.amount)) DESC
-> HashAggregate (cost=59750.38..60064.44 rows=25125 width=44)
Group Key: customer.customer_id
-> Nested Loop (cost=0.30..58143.01 rows=214316 width=10)
-> Seq Scan on orders (cost=0.00..23864.00 rows=853000 width=10)
Filter: (status = 0)
-> Memoize (cost=0.30..0.33 rows=1 width=4)
Cache Key: orders.customer_id
Cache Mode: logical
-> Index Scan using customer_pkey on customer (cost=0.29..0.32 rows=1 width=4)
Index Cond: (customer_id = orders.customer_id)
Filter: (credit_score > 700)
(14 rows)
另外让我们演示一下 GEQO
WITH x AS
(
SELECT *
FROM generate_series(1, 1000) AS id
)
SELECT *
FROM x AS a
JOIN x AS b ON (a.id = b.id)
JOIN x AS c ON (b.id = c.id)
JOIN x AS d ON (c.id = d.id)
JOIN x AS e ON (d.id = e.id)
JOIN x AS f ON (e.id = f.id)
生成时间有点长,毕竟是 "穷举"
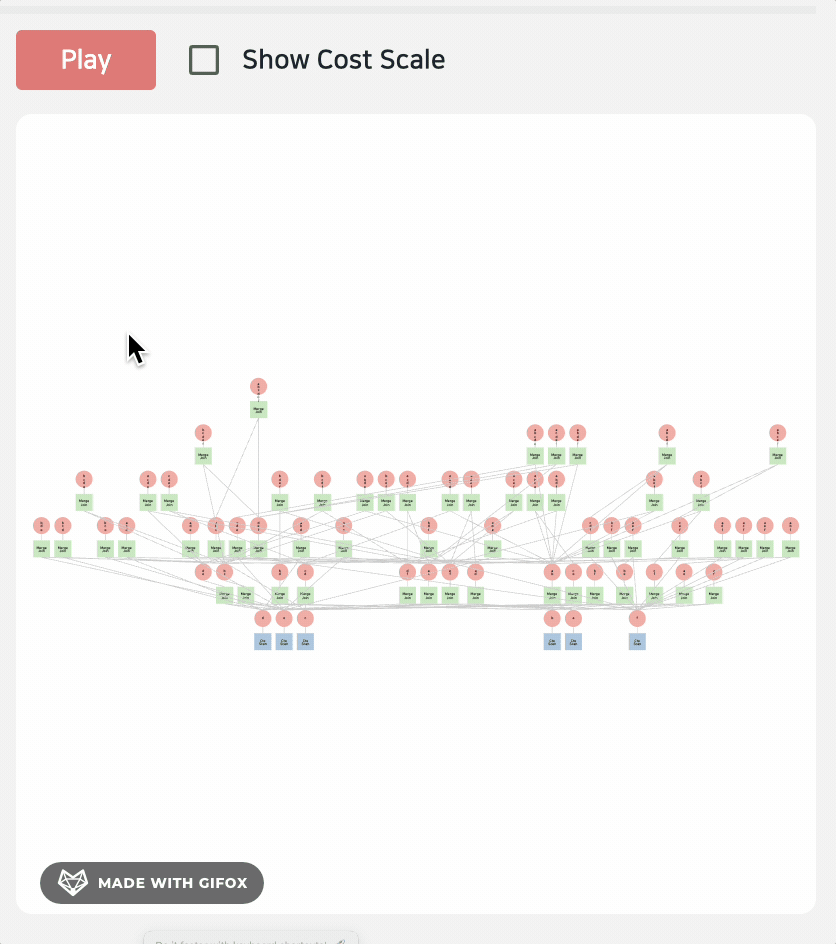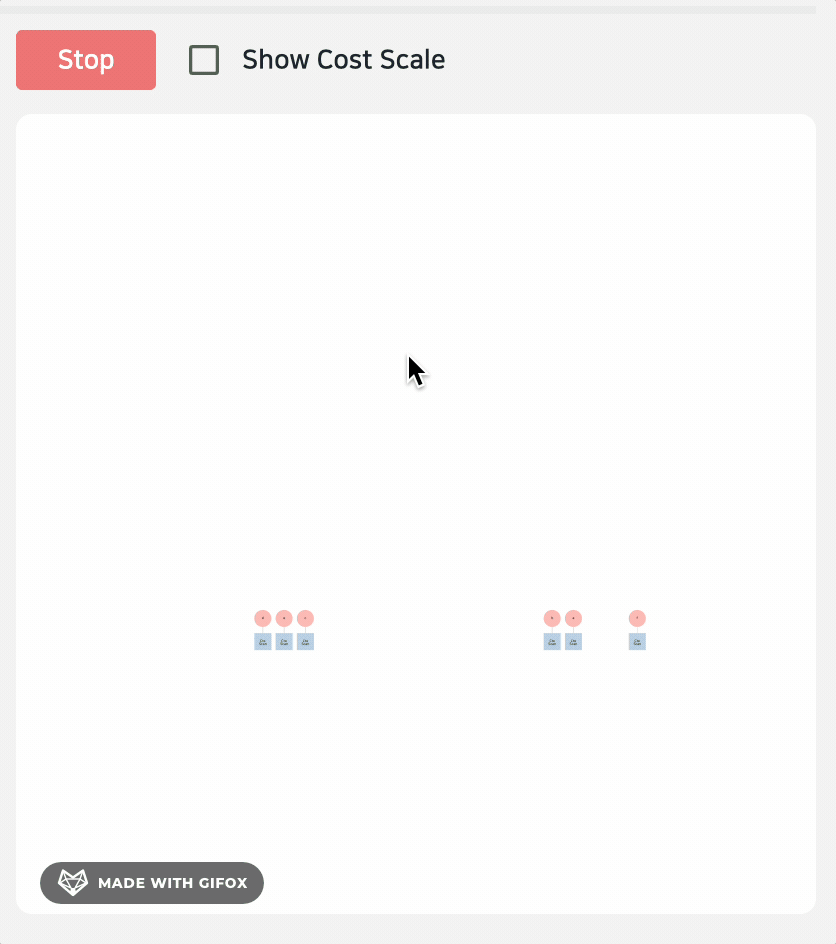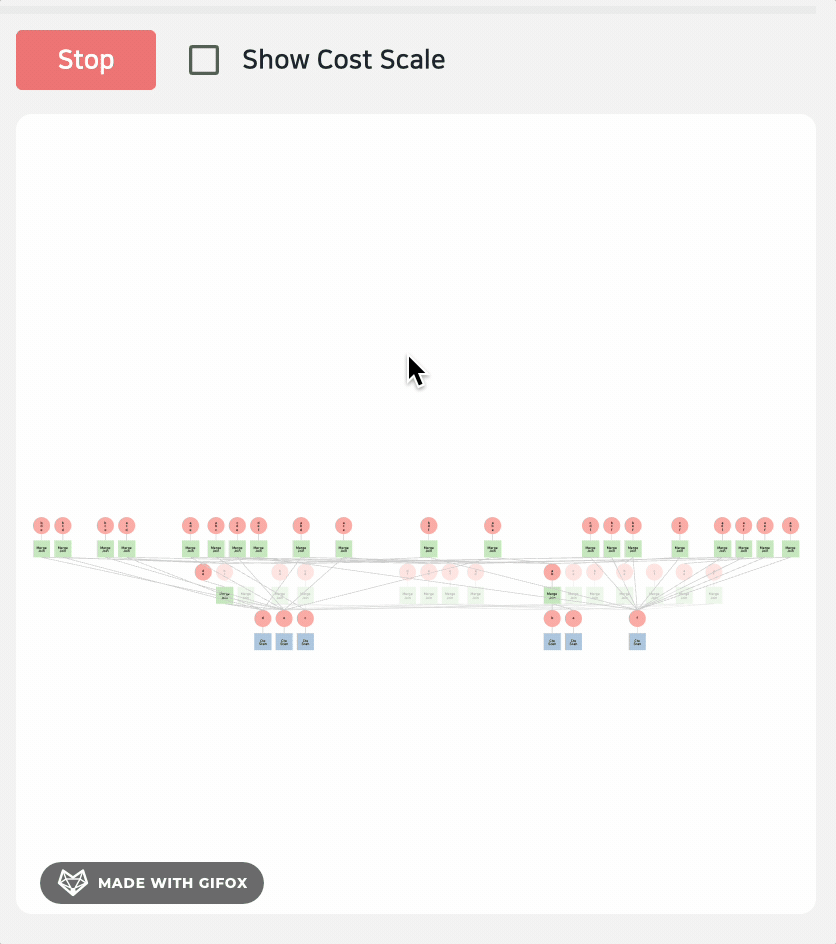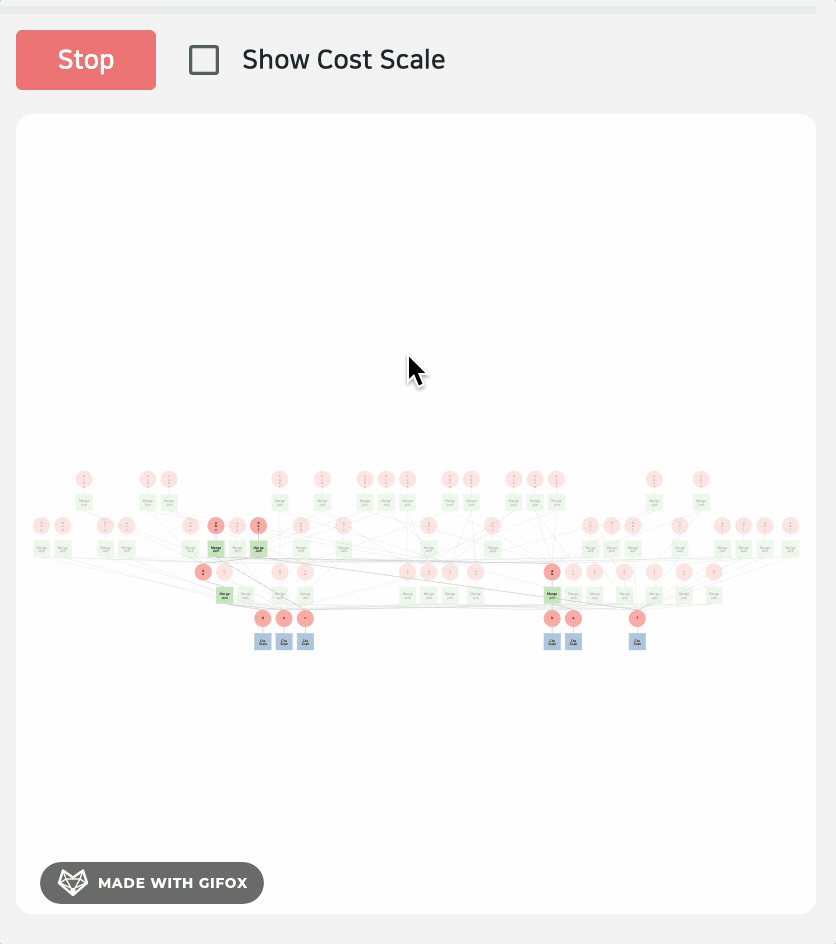
不过演示过程中也有一些小 BUG,比如渲染失败,算子 Undefined 等等,毕竟论文展示的是一个 研究原型,包括大量可视化能力、GEQO 动画、DAG、heatmap 等复杂视图。但公开发布的 GitHub 仓库只是 Demo 代码的一个极简子集,并没有完整包含论文里的全部功能。
“This is a demonstration system.”
“We built a prototype…”
“Some components are not released yet…”
小结
虽然当前开源版本的 Jovis 仍然是论文原型的一部分,距离完整的研究系统还有不少差距 — 诸如 GEQO 的进化过程、完整的 DAG 搜索空间动画、成本分解可视化等高级能力暂未完全公开 — 但瑕不掩瑜。哪怕是如今这一“轻量级 Demo”,已经足以让我们窥见 PostgreSQL 优化器强大机制的冰山一角。
通过它,我们得以从传统 EXPLAIN 的“结果视角”,跨越到理解优化器内部“思考路径”的“过程视角”。这不仅让执行计划背后的推导逻辑变得更直观,也为教学、调优乃至未来探索更智能的优化器形式奠定了基础。可以说,此论文为 PostgreSQL 社区补上了一块长期缺失的、极具价值的观察窗口。
随着研究团队后续可能逐步开放更多组件与可视化能力,Jovis 有望成为我们理解优化器内部原理、探索 PG 性能潜力的重要工具。值得持续关注,也值得在未来的实践中继续深入使用与研究。
