





编者按
日前,由 OceanBase 联合华东师范大学研究团队(蔡鹏教授、李思佳博士生)联合发表的论文《APQO:自适应参数化查询优化框架》登上数据库顶会—— SIGMOD2026。
SIGMOD 是 ACM 旗下的年度会议,是数据库领域公认的权威会议。在参数化查询优化领域,本论文提出的 APQO,是首个支持计划缓存在线持续演化的学习型PQO方法。
以下为论文介绍。
对于结构相同但参数不同的 SQL 查询(参数化查询),引入计划缓存(Plan Cache)可以让这些查询共享执行计划。在许多实际场景中,相比每次重新生成计划,直接从缓存中获取计划的开销通常至少低一个数量级,因此计划缓存能够显著降低计划生成成本,从而有效缩短 SQL 的响应时间。
在参数化查询优化(PQO)的相关研究中,学习型方法通常会基于历史工作负载离线准备好一组候选计划,并为这些固定的计划训练相应的计划选择模型。然而,当查询参数分布发生漂移(即动态工作负载)时,事先构建好的静态计划缓存中往往缺少真正适合当前查询的计划,缓存中糟糕计划的执行会导致 SQL 响应时间显著延长。
为了解决动态工作负载下静态计划缓存易失效的问题,本文提出 APQO,一个自适应的参数化查询优化框架,是首个支持计划缓存在线持续演化的学习型 PQO 方法。
简介
APQO 通过“持续演化的计划缓存”来处理动态参数化查询工作负载。框架由多个组件组成(图 1),协同实现对存在分布漂移的参数化查询工作负载的自适应处理。其核心创新在于:APQO 拥有面向动态计划缓存的计划选择能力。为实现这一能力,APQO 设计了离线训练的基础预测模型和在线训练的轻量级校准器模型,两者配合完成对动态计划缓存的智能决策.
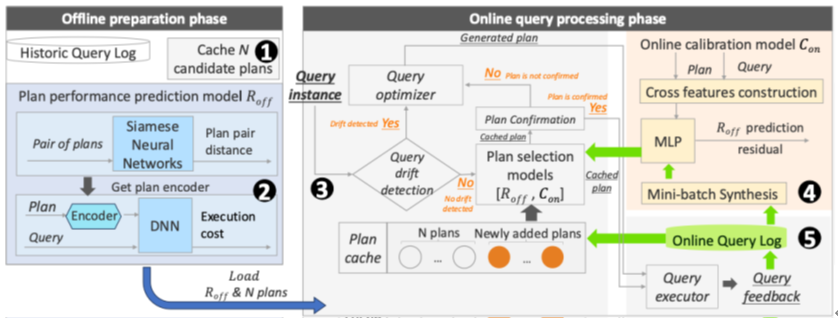
图 1 APQO 框架图
自适应参数化查询优化
APQO 的整体工作流程包含离线和在线两个阶段。
在离线阶段,对于一个参数化查询模板及其对应的历史工作负载,APQO 首先使用贪心算法选取候选计划集合;随后,根据历史工作负载以及相应的优化器计划,训练基础预测模型。该基础预测模型用于预测参数化查询在不同计划下的执行性能,其中包含一个用于捕捉参数化计划性能特征的计划嵌入模型。
在在线阶段,APQO 会根据查询参数的分布特征为每个查询选择执行计划。对于参数分布已经完全偏离历史工作负载的查询,APQO 调用查询优化器生成新计划;如果当前缓存计划集中不存在该计划(或与之高度相似的计划),则将该计划加入缓存,以便后续查询重用。而对分布内的查询,APQO 使用基础预测模型和在线校准器,对缓存计划的性能进行预测,并据此选择合适的执行计划。
基础预测模型
基础预测模型的任务是在给定缓存计划和查询参数的情况下,预测该计划执行查询时的性能。尽管已有工作对查询性能预测问题进行了研究,但由于同一查询模板下不同可执行计划之间往往存在大量相似的局部结构,传统方法很难直接从中学习出计划之间的性能差异。
针对这一问题,APQO 设计了一种专门针对参数化查询计划的嵌入学习方法(图 2),用以增强预测模型的泛化能力。该计划嵌入表示能够捕捉不同计划之间潜在的性能相似性:当两种计划在多种参数绑定下表现出相近的执行性能时,它们在嵌入空间中的表示也会更为接近。
基于这一执行计划嵌入,APQO 构建基础预测模型,以计划嵌入与查询参数为输入,输出对应的执行性能预测,为后续的计划选择提供依据。
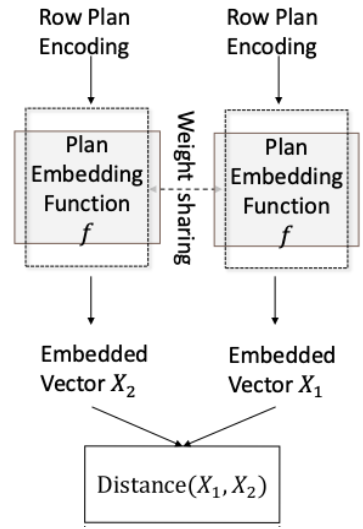
图 2 用于计划嵌入学习的孪生神经网络结构
在线校准器
嵌入技术的引入可以显著提升基础模型对新计划的性能预测能力。然而,由于基础模型对新计划的认知仍然有限,再加上在线执行环境中计划性能可能随时间波动,仅依赖离线训练仍难以达到理想效果。为此,APQO 提出了一种基于在线学习的校准模型,通过持续学习查询的真实执行反馈,对基础预测模型的预测误差(残差)进行动态修正。
在在线环境中,训练数据往往稀疏且呈偏态分布。为应对这一挑战,除了收集在线环境中特定“计划–查询组合”的真实性能反馈外,APQO 采用混合学习数据增强策略,将模拟数据与反馈数据相结合,在保证模型轻量化的同时,加速在线训练过程中的收敛。最终,在线校准模型与离线训练的基础预测模型协同工作,共同完成面向动态负载的计划选择任务。
性能成果
实验表明,在处理存在分布漂移的动态工作负载时,APQO 的自适应能力可以在保持较高计划缓存命中率的同时,将使用计划缓存的查询相对延迟的长尾分布相较于既有学习型 PQO 方法降低三个数量级。
这表明 APQO 能够有效缓解在动态工作负载场景中,由静态计划缓存失效所带来的劣质计划执行,延迟大幅升高的问题,使“计划重用”这一机制得以自然扩展到更加复杂的动态环境中。
基于公开 benchmark 和真实工业负载的评测结果显示,APQO 可以节省约 40%–60% 的查询延迟。

在线咨询

优质资料下载

往期推荐



