




1、问题复现
今天优化一个多表JOIN语句,调整顺序后,使性能提升7倍,这个提升在我以往文章中算是很低的提升了,但在实际性能优化过程中,不要只去优化那种能提升十倍,百倍的SQL, 哪怕是一个SQL要执行5ms优化到3ms也是有意义的,而且大多数优化均是小幅提升,特别是那种执行频繁的SQL,优化几ms对性能也是极大的提升。
经过简化后的慢SQL如下
select * from a
left join b on a.xx=b.xx
left join c on b.xx= c.xx
left join d on c.xx = d.xx
left join e on d.xx = e.xx
left join e1 on d.xx = e1.xx
left join e2 on c.xx =e2.xx
left join e3 on d.xx = e3.xx
left join e4 on c.xx =e4.xx
left join f on b.xx = f.xx
left join g on f.xx = g.xx
where a.col = ? and b.col =? and f.col =? and g.col =?
该SQL执行时间为16.7秒
2、问题排查
a、排查第一步 查看执行计划
执行计划如下
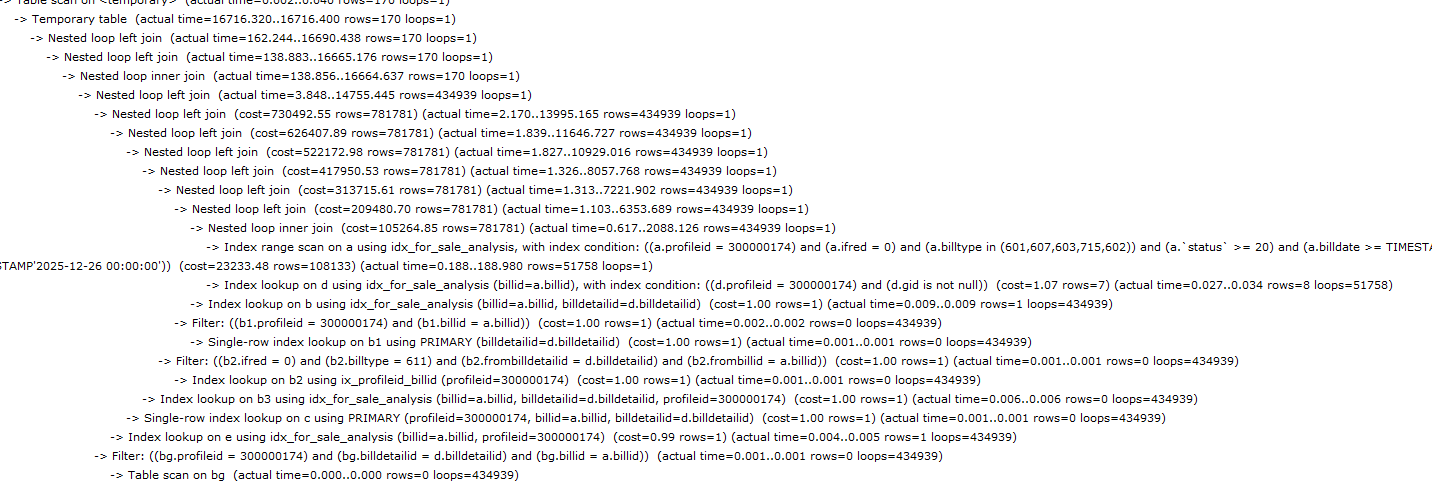
从执行计划可以看到。符合条件的驱动表行数=51758,
但在join第二张表后数据膨胀到了 434939行
join 第九张表后数据讯速下降到170行。
b、检查JOIN顺序
从上面的SQL可以看到 join的第九张表为
left join f on b.xx = f.xx
f表join的依赖顺序为a,b 只需要a,b表之后即可
那我们通过hint强制指定join顺序,下面写出两种指定顺序的方法,在MySQL8.0版本支持。5.X版本不支持。
#通过JOIN_ORDER指定
select
/*+ JOIN_ORDER(a,b,f) */
* from a
left join b on a.xx=b.xx
left join c on b.xx= c.xx
left join d on c.xx = d.xx
left join e on d.xx = e.xx
left join e1 on d.xx = e1.xx
left join e2 on c.xx =e2.xx
left join e3 on d.xx = e3.xx
left join e4 on c.xx =e4.xx
left join f on b.xx = f.xx
left join g on f.xx = g.xx
where a.col = ? and b.col =? and f.col =? and g.col =?
#通过JOIN_FIXED_ORDER指定
select
/*+
qb_name(qb1)
JOIN_FIXED_ORDER(@qb1)
*/
* from a
left join b on a.xx=b.xx
left join f on b.xx = f.xx
left join c on b.xx= c.xx
left join d on c.xx = d.xx
left join e on d.xx = e.xx
left join e1 on d.xx = e1.xx
left join e2 on c.xx =e2.xx
left join e3 on d.xx = e3.xx
left join e4 on c.xx =e4.xx
left join g on f.xx = g.xx
where a.col = ? and b.col =? and f.col =? and g.col =?
再次查看执行计划
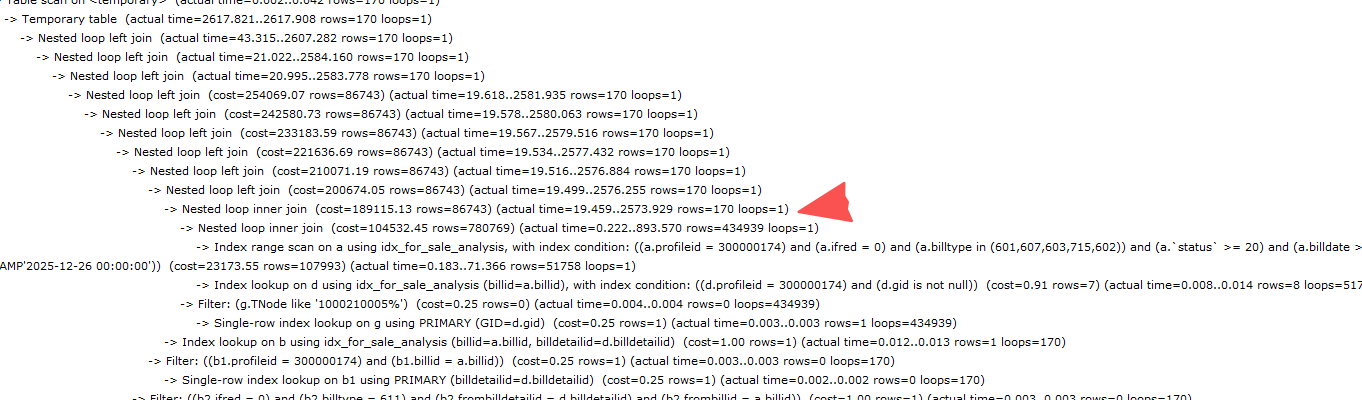
通过执行计划看到在第三张表后。行数就讯速下降到170行了。而因为join顺序依赖关系,f表是不能放在b表前面的。
这里多说一句,为什么明明是left join join后的行数下降了。这是因为虽然写的是left join 只要where 条件上有left join 右表的过滤条件。 MySQL会自动优化为 inner join 这个行为是可观测的,如果不知道怎么观测这个left join 自动转化为inner join的。可以评论区留言,我给大家写个演示。
通过执行计划可以看到最终执行时间为2.67S
这里还有另外一优化手段:将b,f表写到子查询中先过滤,这个优化手法叫延迟关联,在这篇文章中就不展开了。有兴趣的可参见这篇MySQL/SQL Server分页优化(三)
不需要做多大的调整去改写SQL.只需要调整join顺序就有这样的性能提升。
3、多表join该如何确定顺序
a、驱动表的选择
多表join 第一件大事就是确定驱动表,MySQL join 原则:小表驱动大表。所以常规来说一定要小表做驱动表。
select * from a
inner join b on a.xx = b.xx
where a.xx=? and b.xx=?
原则上就是a与b哪个表小,那个表就会被选为驱动表。 但这里有一个情况会打破这个常规。如果大表的where条件过滤性很好。比如a表数据10W. b表数据1000W 但执行b.xx=?后。b表只会剩下30W。 那这个时候也该选b表做驱动表
b、被驱表的顺序排列
join 关系只会有两种 1:1 和1:N
join顺序就该把1:1的放在前面。这样就不会导致join数据迅速膨胀。然后再按照N的大小来排,N的大小可以通过 show index from tablename的区分度+表行数来估算
区分度大+行数小的也要先join
最后再排区分度小+表行数大的表,这类表往往是导致join结果快速膨胀的凶手。
还有一个特列就是 where条件有很好的过滤性。能大幅过滤行数的也要放在join顺序靠前位置。
本贴的SQL就属于这种情况。
