




在 Oracle 数据库中,log file sync 是一个非常常见、但也极容易被误解的等待事件。
它并不一定代表磁盘慢、也不一定是 LGWR 有问题,更多时候它反映的是 提交路径上的“同步等待”。
本文将结合原理、架构、以及多个真实生产场景,对 log file sync 进行系统性拆解。
一、log file sync 是什么?
log file sync 表示:
前台会话在执行 COMMIT / ROLLBACK 时,等待 LGWR 将对应 redo 写入 redo log 文件并确认完成。
只要用户会话没有收到 LGWR 的“写完成”信号,就会一直处于 log file sync 等待状态。
二、log file sync 原理图
1. 单实例提交路径原理
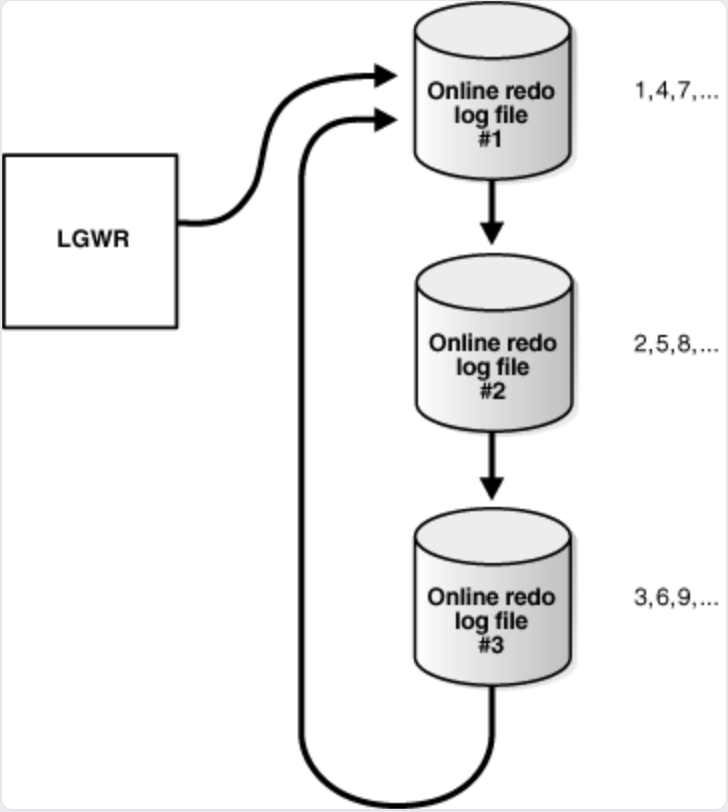
基本流程如下:
- User Session 执行
COMMIT - 提交请求通知 LGWR
- LGWR 将 redo buffer 写入 redo log file
- 写入成功后,LGWR 通知 User Session
- User Session 返回 commit 成功
只要第 3、4 步被拖慢,就会产生 log file sync。
三、log file sync 的主要原因分类
原因一:事务频繁提交 / 回退(过度 commit / rollback)
1. 事务过度提交(最常见原因)
事务过度提交是引起 log file sync 等待事件的主要原因之一。
- 默认情况下,每次事务提交:
- LGWR 立即(immediate)
- 同步(wait) 写 redo
- 提交越频繁:
- LGWR 写日志越频繁
log file sync等待越明显
本质问题不是 I/O 慢,而是 commit 太多。
解决思路
最优解(应用层):
- 将多个小事务合并为一个大事务
- 减少无意义的频繁 commit
但现实中:
- 修改应用成本高
- 依赖应用厂商配合
DB 端可用手段(10g 以后)
Oracle 10g 起提供参数:
commit_write = nowait,batch
含义:
• 提交时不立即写日志
• redo 采用异步 + 批量写
⚠️ 风险提示:
• 数据库异常宕机时,可能丢失最近一小部分事务
• 需要业务可接受
其他辅助方式
• 使用临时表
• 使用 NOLOGGING
• 尽可能减少 redo 产生量
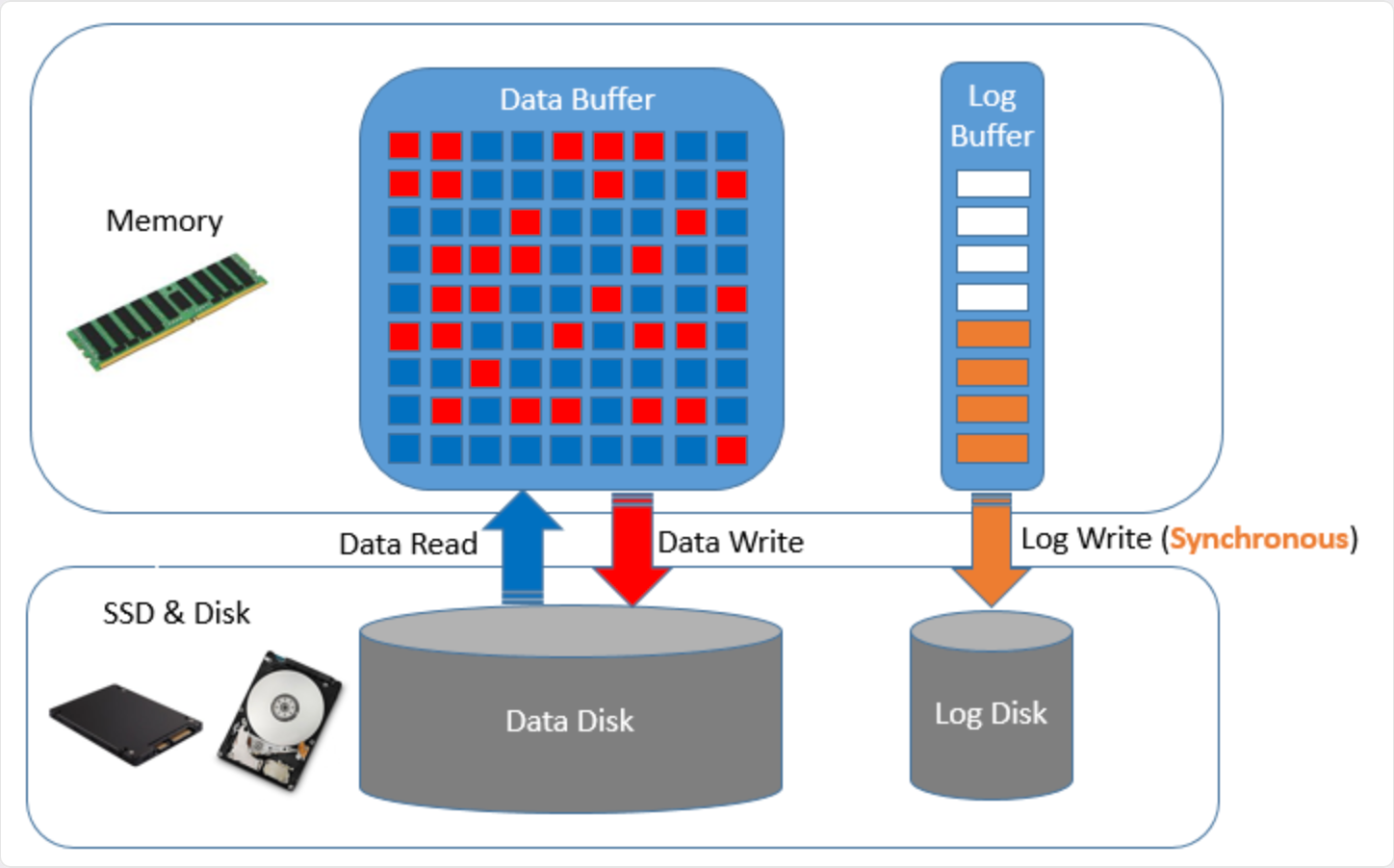
原因二:存储 I/O 资源紧张,LGWR 写入缓慢
1. LGWR 的 I/O 特性
• 顺序写
• 小 I/O
• 对 IOPS 非常敏感
一旦存储繁忙,LGWR 写入速度下降,log file sync 就会出现。
判断方法
方法一:观察操作系统磁盘负载
• AIX:topas
• Linux:iostat, sar
方法二:对比等待事件时间
• log file parallel write
• log file sync
如果两者时间 接近,说明问题在存储。
查看等待分布示例
SELECT event, wait_time_milli, wait_count
FROM v$event_histogram
WHERE event = 'log file parallel write';
示例输出:
WAIT_TIME_MILLI WAIT_COUNT
1 22677
2 424
4 141
8 340
16 1401
32 812
64 391
128 21
256 6
解决方案
1. redo log 迁移到独立、空闲、性能更高的磁盘
2. 视情况迁移 UNDO 表空间,释放 I/O 压力
3. redo log 有多 member 时,可减少 member 数量
原因三:短时间业务量过大(redo 激增)
常见于:
• 批量 DML
• 夜间批处理
• 数据迁移
分析建议
• 分析 redo / archive 生成趋势
• 判断是否业务突增而非系统异常
• 观察业务量是否平稳
原因四:CPU 资源紧张,LGWR 抢不到时间片
现象特征
• log file sync 很高
• log file parallel write 每次仅 1~2ms
说明:
LGWR 写得并不慢,而是 拿不到 CPU
解决方案
1. 增加 CPU / 优化高 CPU SQL(效果最好,成本最高)
2. OS 层面提高 LGWR 优先级(renice)
3. 绑定 LGWR 到指定 CPU
4. 设置隐含参数:
_high_priority_processes
原因五:redo buffer 太小
• redo buffer 太小 → 写入过于频繁
• redo buffer 太大 → 单次写入量过大
建议
• 适当调大
• 调整后持续观察
• 不建议一味追求“大”
原因六:redo log 文件太小 / 组数不足
建议配置
• redo 文件大小:
• 至少 500MB
• 繁忙系统建议 1G / 2G
• redo log 组数:
• 至少 3 组
• 繁忙系统建议 5 组以上
四、RAC 场景下的特殊原因
原因七:RAC 节点之间 SCN 同步(Commit SCN)
原理说明
RAC 中为了保证一致性读,需要同步 commit SCN。
• Lamport SCN
• Immediate Commit Propagation(BOC)
BOC 提交流程
流程简述:
1. User Session commit
2. LGWR 写 redo
3. LGWR 将 commit SCN 广播给远端 LMS
4. 远端 LMS 同步 SCN
5. 全部确认后,commit 才返回成功
解决思路
1. 检查 LMS 进程数量
2. 检查 CPU 是否足够
3. 检查私网通信
4. 必要时关闭 BOC:
_immediate_commit_propagation = false
原因八:RAC 节点之间 CR 块传递
原理
• current block 修改后
• redo 必须写入完成
• 才能通过 LMS 传给其他节点
解决方案
1. 减少跨节点访问
2. 设置:
_cr_server_log_flush = false
原因九:控制文件争用
LGWR 写 redo 时需要更新控制文件。
• RMAN 高频操作
• 并发控制文件更新
• 导致 enq: CF–contention
当 LGWR 拿不到 CF 锁时,前台会话可能出现 log file sync。
五、OLTP 系统的一个关键参数建议
对于交易型(OLTP)系统:
ALTER SYSTEM SET “_use_adaptive_log_file_sync” = FALSE SCOPE=SPFILE SID=’*’;
含义:
• 固定使用 post/wait 机制
• 避免 adaptive 模式下产生过多 log file sync
六、总结
log file sync 不是一个简单的“磁盘慢”问题,而是:
事务提交、redo 写入、CPU 调度、RAC 同步等多因素共同作用的结果。
排查建议:
1. 先看 commit 频率
2. 再看 log file parallel write
3. 同时结合 CPU、存储、RAC 架构
4. 避免“只调参数、不看业务”的误区
它本质上,是 Oracle 作为一台高度同步系统的真实体现。
