




随着大语言模型(LLM)应用的爆发式增长,如何为其提供高效、可靠且可扩展的“长期记忆”已成为关键挑战。向量数据库通过存储和检索高维向量,成为解决LLM幻觉问题和降低推理成本的核心组件。然而,现有向量数据库系统往往在实时性、持久化能力、海量数据可扩展性以及混合查询效率之间存在矛盾。本文为您解读数据库领域顶级会议VLDB 2025的文章《GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications》,该系统在单一设计架构下,同时实现了高性能、高可用、高可扩展、零延迟数据新鲜度以及高效的混合查询能力。

一. 背景
向量数据库是增强LLM能力的关键基础设施,广泛应用于检索增强生成(RAG)与语义记忆(Semantic Memory)等场景。一个理想的系统需能高效管理数十亿向量,并同步支撑实时更新、混合查询与超大规模扩展。然而,现有方案难以兼顾:Milvus等专为规模设计,却牺牲了实时性与混合查询效率;基于ElasticSearch的方案受限于分段架构的延迟与合并开销;PGVector等则在I/O效率与分布式扩展上存在瓶颈。总体而言,现有系统在性能、功能与规模间存在难以调和的割裂。
为突破这一局限,本文提出GaussDB-Vector,一个统一的高性能持久化实时向量数据库。其核心直指三大挑战:挑战1: 如何设计存储与索引架构,以同时实现低延迟、高吞吐的向量检索与高效的实时增删改操作?挑战2: 如何设计高效的混合查询机制,以支持不同选择率下的属性过滤与向量相似度搜索的无缝结合?挑战3: 如何构建可扩展的分布式架构,以支持万亿级别向量的管理与检索,并保证高可用性?
针对这些挑战,GaussDB-Vector带来了系统性创新。应对挑战1,系统采用双架构设计,协调节点(CN)与数据节点(DN)的两层式分布式架构,并通过分布式优化,实现了基于向量距离的数据分片、周期性的数据分布偏移(Drift)检测与重分布,并利用基于基数估计的智能查询路由。应对挑战2,系统通过高效向量索引,采用优化的Vamana图索引与双层IVF索引,并创新设计了自适应的存储结构与热节点缓冲策略。应对挑战3,系统通过混合索引设计,构建了基于平衡树的索引结构,将向量子索引嵌入树节点中,使查询能根据标量选择率自适应选择最优检索路径,实现了高效且稳定的混合搜索。
二. 方法介绍
2.1 总体框架
如图1所示,GaussDB-Vector 的整体框架由编程接口层、CN层、DN层及底层硬件支撑四部分构成。编程接口层提供 SQL、Python 等多语言交互方式,满足不同开发场景的接入需求。CN层承担优化器、数据与查询路由功能,并配合集群管理、全局事务管理模块,实现负载均衡与分布式协调。DN层是核心功能载体:一方面支持 FloatVector 等多类型向量,提供 IndexScan 等向量操作接口;另一方面通过聚类、量化等算子完成向量计算,结合存储管理模块实现数据的高效存储与分片,同时借助计算加速器与 IO 加速器提升性能。底层则依托 Ascend、Kunpeng 硬件及 RAM、NVMe 等存储介质,为整体架构提供算力与存储支撑。该架构共同构成了一个支持海量向量实时检索与管理的完整系统解决方案。
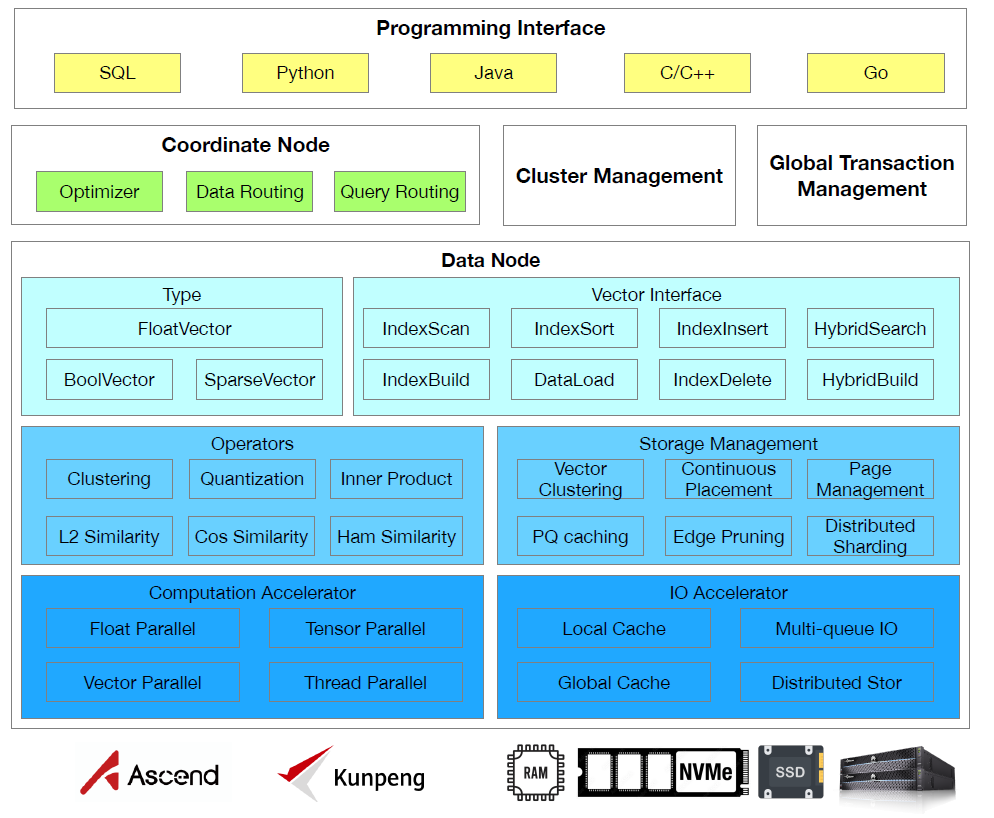
图1 GaussDB-Vector框架图
2.1 向量索引
2.1.1 基于IVF的索引
GaussDB-Vector实现了一种双层聚类的IVF索引结构。该索引在逻辑上组织为三层树,通过两层聚类页管理数据分布。当启用乘积量化(PQ)时,向量以压缩编码形式存储,显著减少了存储空间和距离计算成本。其Top-K查询采用一种基于距离阈值的二分筛选排序策略,通过迭代剔除远离查询向量的候选者,大幅优化排序复杂度,并能有效处理由异步删除或过滤产生的无效条目。
2.1.2 基于图的索引
系统采用Vamana (DiskANN) 图算法作为基础,并为其磁盘存储设计了三种自适应存储布局。根据数据维度和规模,可选择将节点数据打包存储、分离PQ码或完全压缩节点与边,以优化I/O效率。为提升构建与更新效率,系统提出了两阶段邻居剪枝方法,将单次向量插入的复杂度降至 O(m2)。同时,通过惰性删除与定期的Vacuum操作来回收“死亡”节点空间并维护图的连通性。
2.2 标量-向量混合查询
2.2.1 混合索引结构
系统设计了平衡树与向量子索引融合的混合索引结构。在标量列(如ID)的平衡树内部节点中,直接嵌入覆盖该节点值范围的向量子索引(IVF或图索引),从而在索引层面将标量过滤与向量搜索能力紧密结合。
2.2.2 混合搜索
执行混合查询时,系统根据标量过滤条件的选择率自适应选择检索路径:高选择率时,直接搜索相应内部节点的向量子索引;低选择率时,则快速定位到少数叶子节点并对其中少量向量进行精确计算。确保混合查询在不同选择率下均能保持高效稳定。
2.2.3 混合数据更新
在混合索引上的数据更新需同步维护标量树与向量子索引。删除操作仅进行标记。插入操作则可能引发标量树的节点分裂或旋转,进而触发相关向量子索引的调整或重建。为此,系统进行了针对性设计:仅在数据量大的内部节点上构建复杂的图索引,而在数据量少的节点上使用轻量索引,以平衡查询性能与更新开销。
2.3 分布式向量搜索
2.3.1 数据分片
系统采用基于向量距离的聚类分片策略,将数据分布到不同节点。如图2左上角所示,新向量被插入到最近簇中心所在的节点。后台运行周期性的数据分布偏移检测,在数据分布发生显著变化时自动触发重分布,以维持集群负载均衡。
2.3.2 查询路由
如图2右上角所示,针对分布式Top-K查询,协调节点利用基数估计模型预测各数据节点对结果的贡献度,并仅将查询路由至最相关的节点子集。该方法在保证高召回率的同时,大幅减少了跨节点通信与计算开销。
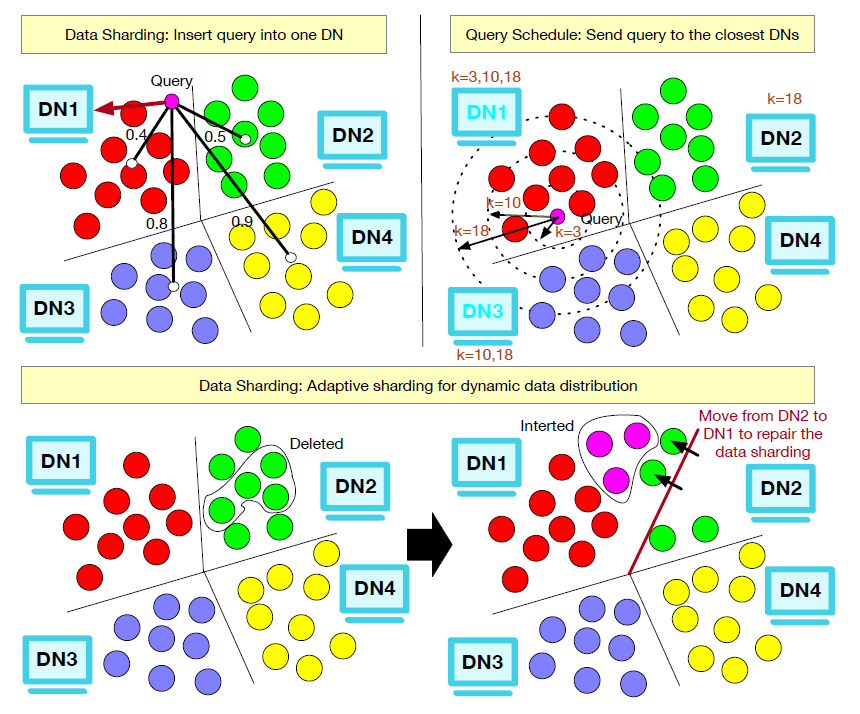
图2 GaussDB-Vector 分布式数据分片与查询路由示意图
2.4 硬件加速
系统通过全栈硬件协同提升性能:利用CPU SIMD指令集与多线程并行加速向量计算;将批量距离计算转化为矩阵运算,卸载到NPU/GPU上执行;并通过多级缓存与多队列I/O技术优化数据访问效率。
三.实验
3.1实验设置
集群:实验在由 40 台服务器组成的集群上进行。每台服务器配备 72 核 Intel 3.00GHz CPU、64GB 内存和 2TB 磁盘,节点间通过万兆以太网连接。部分节点额外搭载了八块昇腾 920B NPU,用于硬件加速测试。
数据集: 论文使用了三个具有不同维度的真实世界数据集:SIFT(128维图像特征)、GIST(960维图像特征)、HUAWEINet(1024维文档嵌入),以及一个用于测试可扩展性的合成数据集 SIFT-10B。
Baseline:论文选取了三个广泛使用的向量检索系统作为基线:专为向量设计的 Milvus、支持向量搜索的全文搜索引擎 ElasticSearch、以及基于 PostgreSQL 的向量扩展 PGVector。为保证对比公平,所有基线均采用其性能最佳的 HNSW 索引,并在单机模式下测试。
评估方法:实验主要从效率和效果两方面评估。效率指标包括查询延迟(平均及尾部延迟)、系统吞吐量(QPS) 和插入延迟;效果核心指标为召回率(Recall)。
3.2 核心实验结果
低延迟、高吞吐、高召回:如图3,4,5所示,GaussDB-Vector在查询延迟与QPS上均显著优于所有基线系统(Milvus、ElasticSearch、PGVector)。例如,在SIFT数据集上达到95%召回率时,GaussDB-Vector的查询延迟比最快的基线降低超过50%,同时吞吐量提升1倍以上。
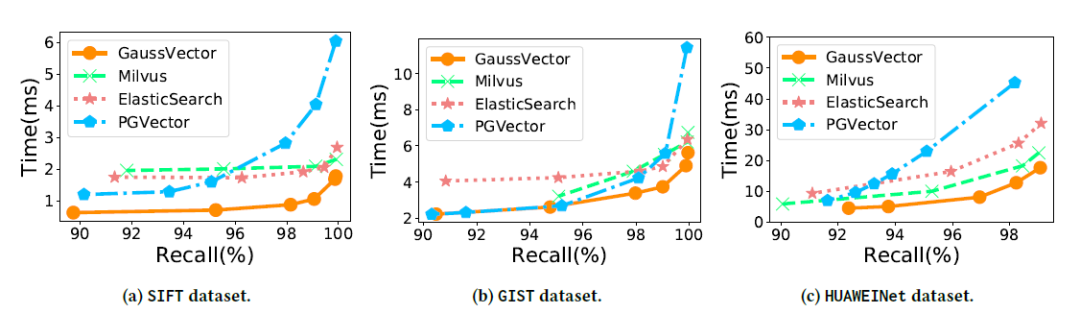
图3 单连接下ANN搜索的平均延迟
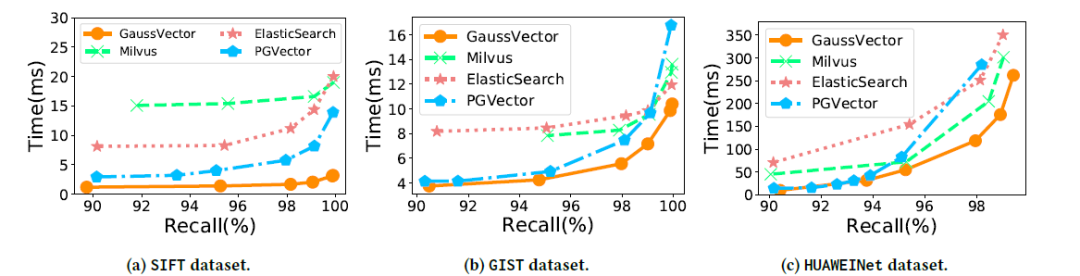
图4 具有多重连接的 ANN搜索的平均延迟
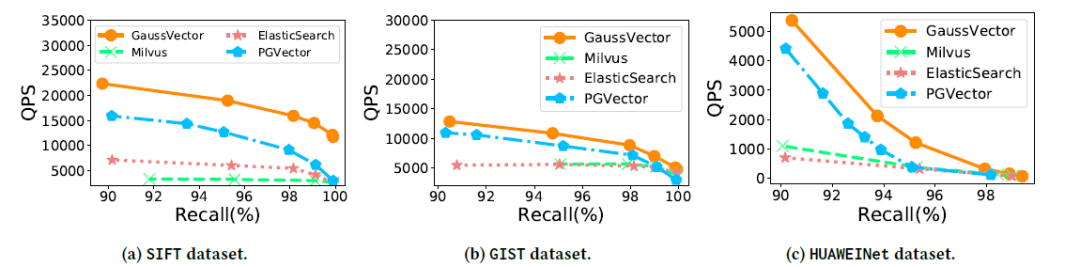
图5 具有多重连接的 ANN 搜索的 QPS
性能稳定,不受选择率影响:如图6所示,在测试混合查询时,GaussDB-Vector的性能在不同标量选择率下均保持稳定且最优。而基线系统表现各异。
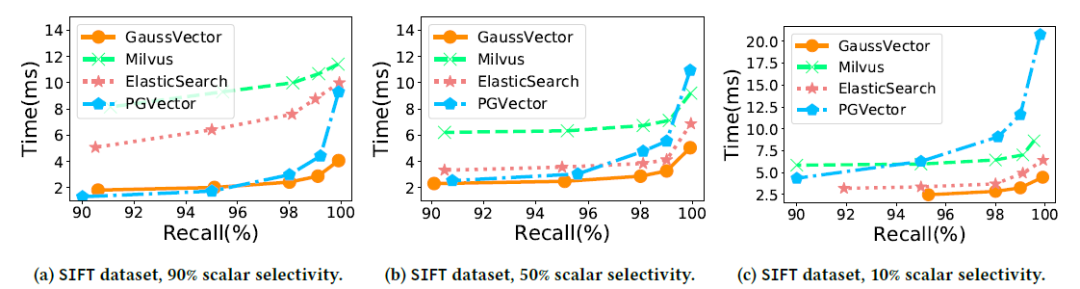
图6 标量-向量查询的搜索延迟
兼顾实时性与高吞吐:如图7所示,在插入性能方面,GaussDB-Vector在保证数据提交后立即可见(即实时性)的前提下,其插入吞吐量与延迟依然大幅优于同为实时系统的PGVector,并显著好于采用批处理缓存模式的Milvus与ElasticSearch的尾部延迟。
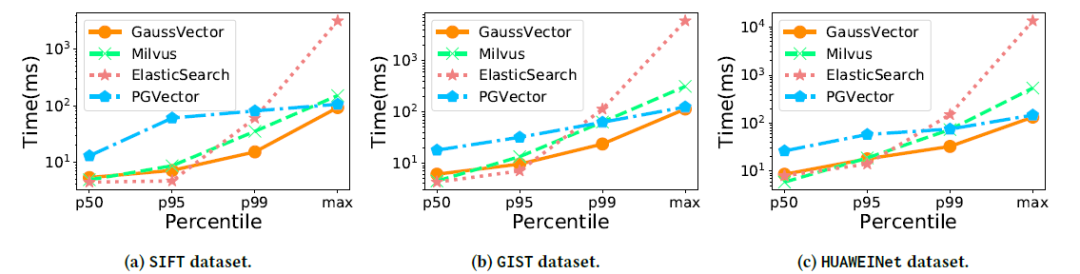
图7 插入延迟
超大规模可扩展性验证:如图8所示,在包含100亿向量的SIFT-10B数据集上,仅使用10台普通服务器的GaussDB-Vector集群仍能维持亚秒级查询延迟与高吞吐量,且其查询性能随集群规模扩大呈现近线性扩展趋势。
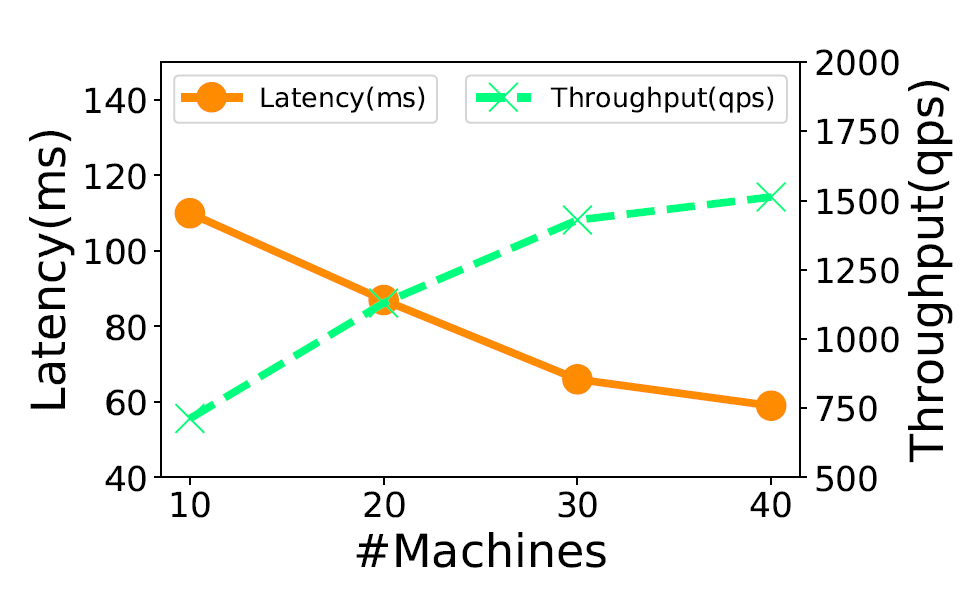
图8 GaussDB-Vector机器数量对延迟与吞吐量的影响趋势
四.总结
论文提出面向 LLM 应用的大规模持久化实时向量数据库 GaussDB-Vector,核心采用 IVF 与图基双重向量索引适配多场景需求:IVF 索引通过两层聚类平衡负载,结合乘积量化压缩向量并支持增量更新与异步删除;图基索引基于 Vamana 优化采用自适应页面结构,通过两阶段邻居剪枝降低插入复杂度,搭配热节点缓存减少 I/O 开销。同时,数据库融合标量 - 向量混合索引、动态数据分片、智能查询路由及 SIMD/GPU/NPU 硬件加速等策略,构建全链路优化体系。实验验证,该数据库在查询延迟、召回率、吞吐量等关键指标上显著优于 Milvus、ElasticSearch 等主流基线,综合性能优势突出。
-End-
 |

图文|魏任鸿
校稿|李政
编辑|刘苧锐
审核|李瑞远
审核|杨广超
