




主要是技术性运维总结,主打通俗易懂和快速上手,同时也是对PG数据库运维的阶段性总结,希望对PGer有所帮助。
历史的运维经验:pg数据库运维经验2024。注意,本篇不会包含历史的运维经验的内容。
CPU
SQL性能问题是PG异常处理根因中最多的,这包含SQL本身性能不好,索引一般、突发并发高、执行计划突变。对于postgres这种没有完善的绑定执行计划的方案的库来说,有一个DBA团队帮助设计数据模型、数据访问方式、索引、调整执行计划等显得尤为重要,实际上可以极大缓解CPU突然打满的问题。
执行计划
执行计划突变是cost-base优化器的老毛病,postgres也不会例外。
DISTINCT不准确
由于默认采样数最大是3w行,也就是说这种采样算法只要超过3w,即表比较大的时候,预估distinct很可能偏小。注意这里的数据不能有太多唯一值。
测试一张表不同采样数的差异:
表有reltuples=8亿,relpages=2kw,size=175GB,真实的某字段distinct 1亿
| target statistics | pages采样比例(1) | tuples采样比例(1) | n_distinct | 执行时间 |
|---|---|---|---|---|
| 50 | 0.00075 | 0.00001875 | 6w | 2秒 |
| 100 | 0.0015 | 0.0000375 | 11w | 5秒 |
| 1000 | 0.015 | 0.000375 | 103w | 58秒 |
| 3000 | 0.045 | 0.001125 | 268w | 3分01秒 |
| 10000 | 0.15 | 0.00375 | 675w | 7分21秒 |
(target statistics 最大值10000)
可以粗糙的总结:n_distinct和analyze的执行时间随采样数量成倍增长。
n_distinct随采样数量增长,pages和tuples却一直都很准确。
generic plan的干扰
pg的执行计划要考虑generic plan。generic plan与传参是无关的,它用一些默认值计算cost,并与前五次计划的代价进行对比,谁小用谁。
一、generic plan预估不准的问题分类
因为有5次机制对比,所以generic plan的问题可以分为2种:
- 前5次SQL的执行没有普遍性。跟前5次执行计划相关性大,依赖数据倾斜和前5次参数是否具有普遍性。
- generic plan本身有问题。generic plan因为数据倾斜或数据均衡但无法准确计算选择率,导致generic plan本身执行效率低下
二、解决方案参考
generic plan问题在分区表上可能会出现,分区键是连续的,扫描所有分区建选择率应该为1,但generic plan为0.05,很可能导致走“全索引”扫描这种场景。
所以在优化的时候需要考虑更多:
- 不要建太多索引迷惑优化器
- 排除generic plan的干扰。用
EXECUTE真实跑6次 - 会话级别
set plan_cache_mode='force_generic_plan'; orset plan_cache_mode='force_custom_plan';对比执行计划;或者在pg16+用explain (GENERIC_PLAN)对比执行计划
语法参考:
--prepare/excute
PREPARE sql1(text) AS
SELECT COUNT(*) FROM LZL where a=$1;
EXECUTE sql1('zzz'); --跑6次再说
EXPLAIN EXECUTE sql1('zzz');
select * from pg_prepared_statements --查看prepare语句信息,只能看当前会话
--对比执行计划,设置会话参数后执行EXPLAIN EXECUTE
set plan_cache_mode='force_generic_plan'
set plan_cache_mode='force_custom_plan'
--直接查看genetic plan,16+
explain (GENERIC_PLAN) xx
行锁导致的LWLock:Lockmanager
LWLock Lockmanager问题一般发生在分区表上,高并发没有分区键的SQL容易发生。而今年又发现一个新的场景:行锁导致的LWLock:Lockmanager
这不算一个很大的问题,因为更新同一行会阻塞是众所周知的。只是没有测试前我也没有想到更新同一行也会产生LWLock:Lockmanager。不算特别有价值的案例,在观察等待事件有LWLock:Lockmanager时考虑行锁即可。
idle连接数
PostgreSQL的性能基本随着大版本提升而稳定提升。其中PG14对快照的获取和维护所有backend的事务信息都做了大幅优化,使得14对多idle connection的提升明显:
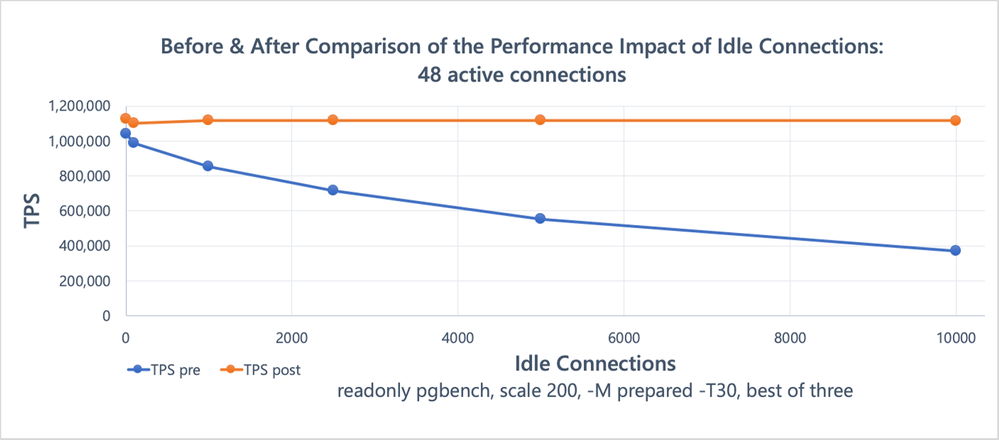
但,这不代表14以后就不需要关注idle连接数了,它仍然会消耗backend事务维护成本、上下文切换、使内存碎片化等问题,导致数据库的idle连接数越多性能越差。
一般业务连接本身是有轮询和保活的,保持一定的idle是为了不让每个请求都新建连接,那样消耗就大了去了。一般小库是不太需要关注连接数(只要别太离谱),因为CPU买的不多,系统也没那么重要,而且扩容比较容易。但是大库又不一样了。CPU数就是主机资源上限,再加也加不上去了。大库本身idle connection就很多,再增加空闲连接不一定会增加系统的吞吐量,特别是CPU已经不太够时,增加idle连接会起反向效果。
以PG15压测经验来看,以5k idle为基线,上1w个idle时,idle的维护会多使用2-5个vCPU,上2w个idle时,多使用5-10个vCPU。大致情况是这样。
idle in transaction
去年狠狠把长事务批判了一遍,因为长事务对PG的影响要比其他库(oracle、mysql等)要大。但这问题不大,做好告警和运维,长事务问题是可解决的。
在监控会话状态时,一般都要查看会话状态,比如active代表正在运行,代表在跑SQL,idle in transaction代表事务在空闲状态,代表事务没有在跑SQL也没有提交。所有的pg_stat_activity.state如下,pg15:
Current overall state of this backend. Possible values are:
active: The backend is executing a query.idle: The backend is waiting for a new client command.idle in transaction: The backend is in a transaction, but is not currently executing a query.idle in transaction (aborted): This state is similar toidle in transaction, except one of the statements in the transaction caused an error.fastpath function call: The backend is executing a fast-path function.disabled: This state is reported if track_activities is disabled in this backend.
常见的state只有active,idle,idle in transaction,idle in transaction (aborted)。idle in transaction有一个误区是,它只代表当前时间没有运行sql,没有提交事务,不代表这个事务空闲了很久。不能通过事务xact_start +idle in transaction判断事务多久没跑,而应该通过state_change +idle in transaction来判断。
内存
内存问题非常棘手,而且今年处理了非常多,也找到了一些很好的解决方案。不过内存体系知识还是比较大,只能尽我所能尽量简化这部分知识,直达现象、结果和解决方案。
内存问题和大页
pg内存问题分类:
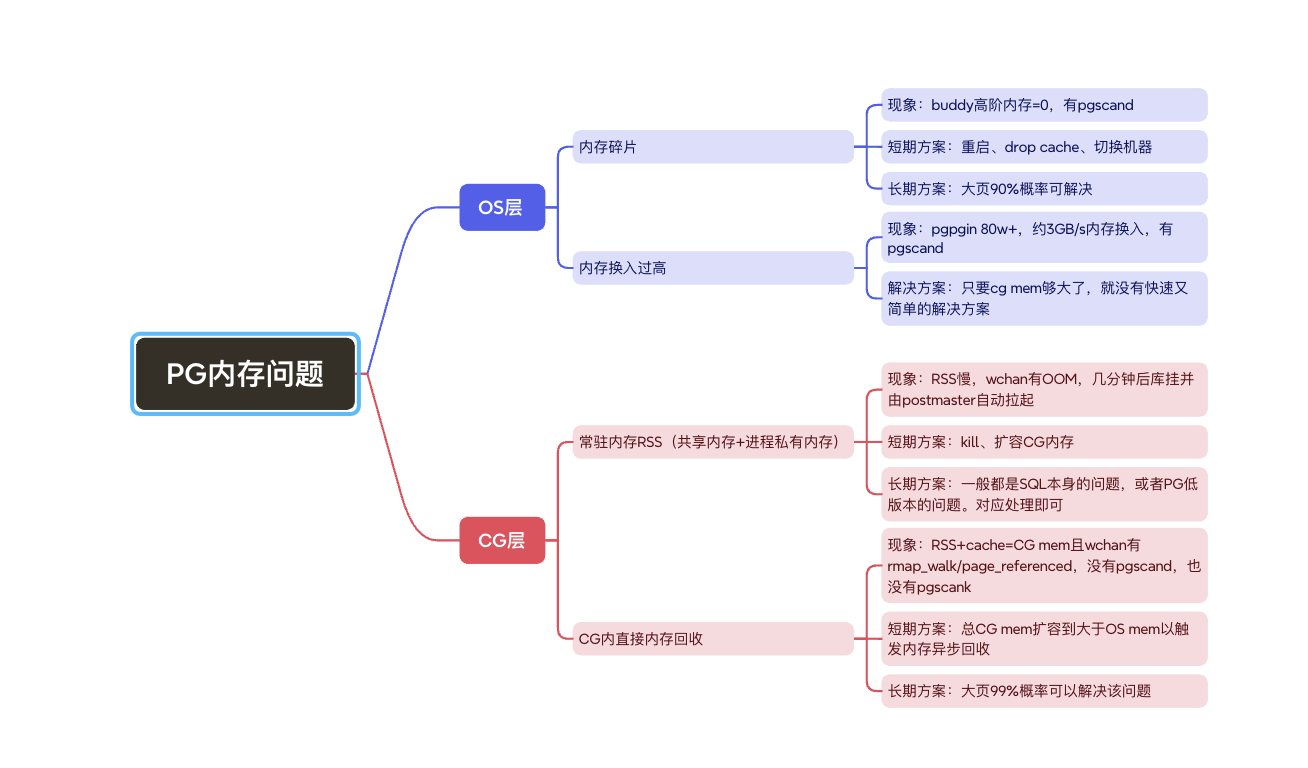
pg内存问题相关wchan:
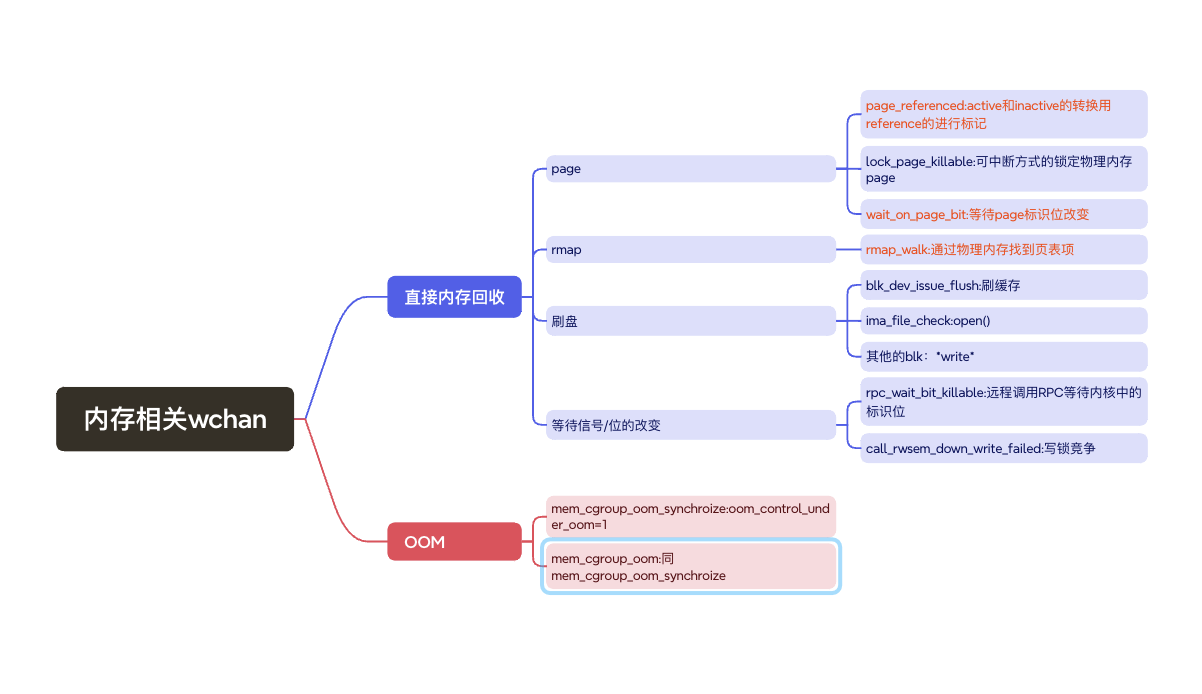
大页对内存碎片、CG内直接内存回收都非常好的效果。
大页实际效果看压测:https://docs.paic.com.cn/#/post/84479375
大页八股文理论效果:
-
减少TLB的压力
-
减少pagetable在主内存上的大小
-
大页在物理上是连续的。连续的物理内存访问比不连续的物理内存访问更优
-
当使用大页时,page是直接映射的,不会使用多级的pte条目
不过使用大页会带来管理上的挑战:
- 需要提前分配大页
- 需要提前计算大页大小,以避免内存浪费
内存知识比较多,其他的参考Linux内存进阶。总之要记住如下几点:
-
优先排除os层问题再解决pg实例层问题
-
大页有神奇的效果,但极少数情况仍没有效果
-
很多小伙伴不会关注pgpgin/pgpgout/pgfree,甚至不会关心pgscank/pgscand,只会看cpu、内存用了多少。这对运维pg库来说是不够的。
-
没有良好的运维体系pg的内存会很不稳定
值得注意的cgroup知识
cgroup的知识也不少,参考之前的文章吧,这里做个简单总结。
cgroup v1有自身的缺陷:
- 没有统计cg pagetable
- 没有统计cg slab
- 没有统计cg hugepage(hugepage是没有charge,还不是没有算进去)
- 没有统计cg异步、同步回收pages
- cg rss与process rss统计口径不统一
- shmem统计口径比较乱
未解之谜
大页确实解决了很多问题,但不能解决所有内存问题。不能解决的这部分问题待研究,希望26年可以弄明白。
关注OS
关注OS的一切
学习开源库需要了解操作系统
(这句话已忘记出处)
想要运维好Postgres,了解OS的原理是十分重要的。Postres数据库就是构建在OS(特别是linux)之上,linux提供什么它用什么,postgres是linux的生态。所以想要深入理解运行原理,得先了解操作系统原理。
优先排除os层问题再解决pg实例层问题
(这句话是我说的)
一、CPU
因为postgres还用不了NUMA,无论是主机资源全给,还是CGROUP(or pod)管理cpu,都不太需要深入到操作系统层CPU原理。CPU问题看看SQL或者PG的堆栈基本够了。
二、内存
内存参考内存章节。内存问题是需要深入到OS层的。
三、进程
从操作系统查看PG进程的状态非常重要,包括但不限于要查看D、wchan、RSS、SYSCALL
四、主机状态和日志
监控主机状态、包括主机层CPU、内存、IO、网络、日志。非常重要。
难以想象“an I/O error occured while sending to the backend”这种网络IO的模糊告警跟底层存储是相关的。除了查看/var/log/message,pg层看不出来有什么。当然这个报错有可能不是这个原因,请勿曲解。
五、其他
未归类
物理读
postgres本身不直接暴露“真正的物理磁盘读”(Physical Disk Read)指标。pg_stat中的各种reads(比如pg_stat_database.blks_read )都是从os cache中读。
那怎么监控物理读?
reads或者buffer allocation指标都是辅助策略,最好的办法还是监控OS。
os是postgres的生态,绝对不要单看数据库。数据库层监控不到物理读不值得PGer shame,有方案就没问题。
监控iostat以及各种五花八门的磁盘监控指标。对于云环境来说,os层的监控体系已经十分成熟了,不要浪费基于云的可观测性。
autovacuum
监控autovacuum process的SQL参考sql autovacuum_queue_and_progress
大库的autovacuum freeze
只要把参数、监控、告警配好,autovacuum freeze在绝大部分库中,都是不太需要关注的。
但是,在一些事务并发超高、数据特别大的库,仍然不可以忽略。因为autovacuum prevent wraparound可能随时都在跑,此时至少要关注如下两点:
- 年龄告警,及时处理并尽量避免下一次告警。不要出现快死到临头了才来着急挽救(加速方案需要看版本,比如
INDEX_CLEANUP OFF,BUFFER_USAGE_LIMIT的调整) - 对内存(特别是cache)的冲击。如果autovacuum跑个不停,库又特别大,对cache也有一定冲击,对内存是有影响的
原理和参数参考howstos这个图:

大表跑不动
大表指上百GB的表,一般有许多索引和死元组才会“跑不动”。
跑不动的主要原因是:(auto)vacuum会根据死元组,一条条的去索引上清理死索引元组。一般大表的(auto)vacuum就慢在这里,一般可以看到这个大表的死元组也比较多。更恐怖的是,这可能导致(auto)vacuum的运行速度慢于死元组生成速度,也就是(auto)vacuum永远跑不完,无限膨胀。
对于大表跑不完的场景经验:
- 同一表,死元组数基本与执行时间成正比
- 从autovacuum日志中的user time,elapsed time可以观察使用cpu时间和执行时间,即可大致推测delay sleep时间
- 关闭autovacuum cost-based delay,可以减少3倍执行时间(与索引大小相关,属于来源:200GB表,280GB索引)
- 调整某表的autovacuum cost-based delay含义是让autovacuum跑这个表更少的休息,会在更短的时间内消耗更多CPU以及扫描表时的io
如何加速?
- repack。repack属于釜底抽薪型,可以快速重建表,在应急时可以使用。但repack毕竟是cli工具,每次去跑比较麻烦。
- 调整autovacuum的 cost-based delay参数。可1.调大cost limit
alter table t1 SET (autovacuum_vacuum_cost_limit=1000);,或者2.直接关闭delay睡眠时间alter table t1 SET (autovacuum_vacuum_cost_delay=0);。建议仅对autovacuum跑不过来的表调整。 - 删除不必要的索引。扫描索引并更新索引条目的时间是最久的,删除不必要的索引当然有效
- 分区表。推荐分区大小不大于10GB;改造为分区表是最好的方案
- 删除updated_time字段索引以利用HOT,以减少膨胀率
checkpoint和bgwriter
checkpointer不仅要打检查点,跟实例恢复的时间相关,它还会做刷脏。而bgwriter只是做刷脏。从pg 17开始一些指标转移到pg_stat_checkpointer ,这里以pg 17-为例,基本只看pg_stat_bgwriter
一、checkpoint间隔
- 指标
checkpoints_timed:对应checkpoint_timeout参数 - 指标
checkpoints_req:对应max_wal_size参数。
推荐以checkpoint_timeout为基本的checkpoint间隔,如果出现checkpoints_req,应该将max_wal_size调大,并配合调整刷脏参数。有FPI时也应该检查这两个指标表现。
二、刷脏指标
- 指标
buffers_checkpoint:checkpointer刷脏数 - 指标
buffers_clean:bgwriter刷脏数 - 指标
buffers_backend:backend刷脏数,这应该尽量少的出现,出现说明bgwriter刷脏不够激进 - 指标
buffers_backend_fsync:意义不明
刷脏调参目标以刷脏优先级为目标,刷脏优先级为:bgwriter刷脏 > checkpointer刷脏 > backend刷脏
checkpointer虽然可以顺手刷脏,但是checkpointer不好控制刷脏速度,即可能出现checkpointer会引起IO突刺的情况。所以bgwriter的刷脏优先级应高于checkpointer。backend刷脏自不必多说,这是backend触发的刷脏,应尽量减少这种情况。
三、bgwriter刷脏参数
bgwriter是通过“写多少停一下然后继续写的方式”来控制刷脏速度的。
- 参数
bgwriter_delay:停多久 - 参数
bgwriter_lru_maxpages:一次最多写多少 - 参数
bgwriter_lru_multiplier:一次写多少=(近期buffer allocate* lru_multiplier),但不大于lru_maxpages - 参数
bgwriter_flush_after:刷多少后做fsync - 指标
pg_buffers_alloc:可以代表共享内存buffer的分配量。(allocate是产生了实质的换入的,可以一定程度上代表内存换入pgpgin)。 - 指标
maxwritten_clean:到达bgwriter_lru_maxpages的次数
默认的bgwriter刷脏逻辑:一次刷(新buffers数*2,但不大于100个dirty buffers),delay 200ms,每刷64个buffers后 fsync。
平时的一周期刷脏量跟近期的buffer allocation多少和bgwriter_lru_multiplier参数相关,而在高峰期时buffer allocation一般是比较高的,所以高峰期一般会触达bgwriter_lru_maxpages上限。所以可以这样理解:bgwriter_lru_maxpages用于限制高峰期刷脏上限;bgwriter_lru_multiplier用于控制低峰期不要频繁刷脏。
四、刷脏参数参考
默认最大bgwriter刷脏=100*5*8k=3.9M/s。默认bgwriter刷脏参数肯定是偏小的,如果需要调大的话应该结合shared_buffer的大小和负载来进行调整。
说了半天理论,实际可以参考如下调整:
#读写比2:8,负载较高
shared_buffers=40GB
checkpoint_timeout=20min;
max_wal_size=80GB
bgwriter_delay=20ms
bgwriter_lru_maxpages=1000
bgwriter_lru_multiplier=4
看情况再进行下一步调整。
至于效果,从实际的经验来看,不要期待单独调整bgwriter可以有好的效果。甚至bgwriter调整的过于激进可能会有反向效果。
所以,你的库没有明确定位到是checkpoint刷脏突刺或者其他刷脏的问题,那就不要动这个。仅推荐核心大库、并发高的库,在调整其他东西的时候(比如迁移时、调shared buffer时等)一并调整刷脏,当成附属调优策略。
五、刷脏参数总结
bgwriter刷脏可以总结为“三难”:
“难懂、难调、难有效果”
DB4AI
AI任务调度信息写入数据库
AI的应用已经在开发层面已经应用得非常广泛,其中一个场景是调用AI的任务会写进数据库,任务调用可能是瞬间极高的,而写入数据库的请求可能是没有并发控制的,所以会导致数据库的cpu或者其他资源使用率飙升。
这是一个AI时代背景下的一个新的数据库故障场景,careful。
vector hnsw
参考资料:https://postgresql.us/events/pgconfnyc2024/sessions/session/1862/slides/172/pgvector_best_practices_pgconfnyc2024.pdf
HNSW索引构建加速
HNSW索引在构建的时候可以非常慢,百万行数据可以慢到以小时计。
影响HNSW索引构建速度的,除了套餐的内存(和cpu)以外,还有索引构建参数,例如:
maintenance_work_mem=3g max_parallel_maintenance_workers=2 m=12 ef_construction=100
创建HNSW可能非常折磨人,我们可以有以下手段加速创建索引:
- 在数据写入前建索引,其实是一个选择。虽然initial整体时间更慢,但是开发可接受慢一点,但接收不了建1个小时的索引
- 在数据写入后建索引优化
-
SET maintenance_work_mem = '8GB'
-
SET max_parallel_maintenance_workers = 8
after建索引需要注意内存问题,跟套餐内存,空闲内存强相关
-
注意
maintenance_work_mem是可以起到保护OS mem的作用,如果maintenance_work_mem超过了OS mem可分配内存,且表很大,则直接报错中断连接(快速报错)ERROR: 53200: could not resize shared memory segment "/PostgreSQL.1390017142" to 6439348672 bytes: Cannot allocate memory LOCATION: dsm_impl_posix, dsm_impl.c:314 -
注意创建过程中使用的内存超过
maintenance_work_mem会有info提示(达到一定时间)NOTICE: 00000: hnsw graph no longer fits into maintenance_work_mem after 886990 tuples DETAIL: Building will take significantly more time. HINT: Increase maintenance_work_mem to speed up builds. LOCATION: InsertTuple, hnswbuild.c:525
HNSW索引查询速度
查询的召回率和性能之间需要做平衡,通过调整ef_search参数实现。
查询时除了ef_search参数影响较大外,还有一个影响查询返回速度的因素:HNSW索引是否缓存在内中。
索引不在内存中:
explain (analyze,buffers) SELECT image_id, applyNo, feature_vector <-> (select vectorsit
FROM image_features_test2
ORDER BY distance
LIMIT 10;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=11852.80..11865.74 rows=10 width=35) (actual time=82193.073..82193.185 rows=10 loops=1)
Buffers: shared hit=1796 read=9309
I/O Timings: shared/local read=82108.559
InitPlan 1 (returns $0)
-> Limit (cost=0.00..0.02 rows=1 width=32) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on test_0 (cost=0.00..23.60 rows=1360 width=32) (actual time=0.007..0.008 rows=1 loops=1)
Buffers: shared hit=1
-> Index Scan using idx_feature_hnsw on image_features_test2 (cost=11852.78..1292546.60 rows=989705 width=35) (actual time=82193.071..82193.179 rows=10 loops=1)
Order By: (feature_vector <-> $0)
Buffers: shared hit=1796 read=9309
I/O Timings: shared/local read=82108.559
Planning:
Buffers: shared hit=1
Planning Time: 0.130 ms
Execution Time: 82193.279 ms
索引在内存中:
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=11852.80..11865.74 rows=10 width=35) (actual time=20.240..20.350 rows=10 loops=1)
Buffers: shared hit=11105
InitPlan 1 (returns $0)
-> Limit (cost=0.00..0.02 rows=1 width=32) (actual time=0.007..0.008 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on test_0 (cost=0.00..23.60 rows=1360 width=32) (actual time=0.007..0.007 rows=1 loops=1)
Buffers: shared hit=1
-> Index Scan using idx_feature_hnsw on image_features_test2 (cost=11852.78..1292546.60 rows=989705 width=35) (actual time=20.239..20.344 rows=10 loops=1)
Order By: (feature_vector <-> $0)
Buffers: shared hit=11105
Planning:
Buffers: shared hit=1
Planning Time: 0.093 ms
Execution Time: 20.392 ms
同一个索引,同一个执行计划,索引是否在内存中的性能差距是82193.279/20.392=4000倍!
这个差距是不可忽略的,关注HNSW索引性能时,一定要观测HNSW索引是否在内存中。SQL参考如下:
--buffercache查看hnsw是否在shared buffer中缓存
SELECT c.relname, pg_size_pretty(count(*) * 8192) as buffered, round(100.0 * count(*) / (SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer, 1) AS buffer_percent, round(100.0 * count(*) * 8192 / pg_table_size(c.oid), 1) AS percent_of_relation FROM pg_class c INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database()) GROUP BY c.oid, c.relname ORDER BY 3 DESC LIMIT 10;
relname | buffered | buffer_percent | percent_of_relation
---------------------------------+------------+----------------+---------------------
idx_feature_hnsw_1 | 2117 MB | 91.9 | 44.5
idx_feature_hnsw | 78 MB | 3.4 | 2.0
pg_inherits_parent_index | 8192 bytes | 0.0 | 100.0
业务发版
ddl的技巧
online ddl工具pg-osc、pg_migrate都不支持分区表,而且工具还有一些其他问题,真实使用比较困难。所以DDL的技巧还算比较有用,可以降低锁级别、提前识别阻塞等以减少DDL阻塞和重写带来的风险。
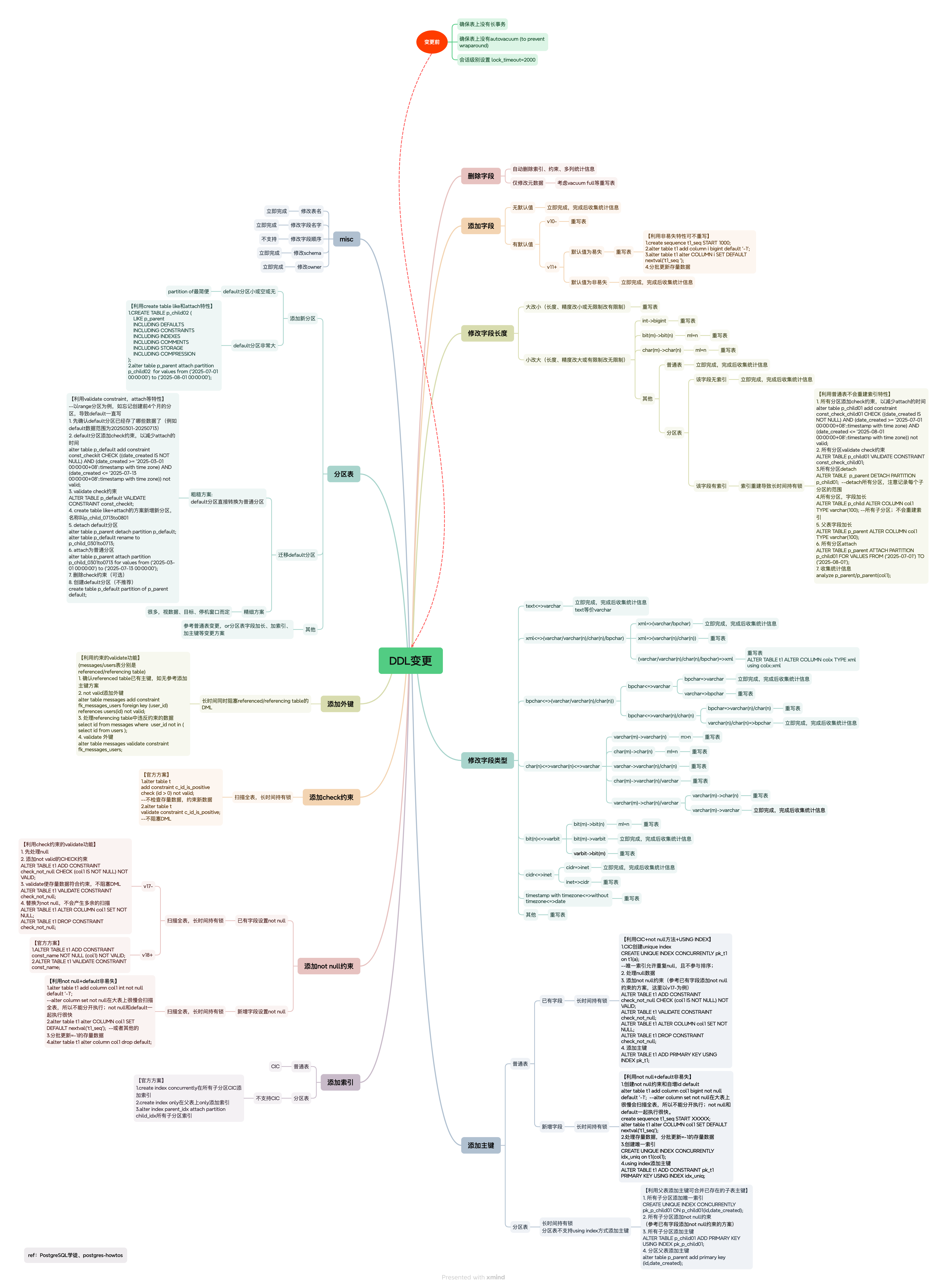
理解这个图的关键点:
变更前的注意事项:
-
确保表上没有长事务——长事务会长期持有表上的锁,长事务在pg中是危害这是共识,应先处理长事务
-
确保表上没有autovacuum (to prevent wraparound)——autovacuum一般不会阻塞SQL,但做
to prevent wraparound的除外Autovacuum workers generally don’t block other commands. If a process attempts to acquire a lock that conflicts with the
SHARE UPDATE EXCLUSIVElock held by autovacuum, lock acquisition will interrupt the autovacuum. However, if the autovacuum is running to prevent transaction ID wraparound (i.e., the autovacuum query name in thepg_stat_activityview ends with(to prevent wraparound)), the autovacuum is not automatically interrupted. -
lock_timeout=2000——即拿不到锁超过2s就不拿了,以免引发大面积阻塞
字段小改大的特例:
- 字段小改大一般不会重写表,但有几个例外。特别要注意int->bigint(常见主键字段), char(n)->char(m))
- 分区表索引。分区表字段小改大不会重写表,但会重建索引,而分区表重建索引一般都非常慢,很可能造成长期8级锁阻塞。这个特性是普通表没有的。
修改字段类型:
- 基本都会重写表,除了一些类型等价,或者属于另一种小改大的
DDL降低锁级别的注意点:
- 索引用CIC,分区不支持就子表CIC(记得attach index)
- CIC执行分了好几个阶段。其中2、3阶段会获取share锁,阻塞dml(官方文档只说了SHARE UPDATE EXCL.(不等DML),CIC不是单纯的显式锁)
- 添加主键用using index,分区不支持就利用“子表加主键+父表添加主键可合并已存在的子表主键的特性”
- 约束用validate constraint
- 17以前不支持not null validate,可以用check(col1 IS NOT NULL)。这个check转not null也不会产生多余的扫描
- 加字段有default易失会重写,可以用非易失不重写特性先加字段,不会重写。存量数据看情况update
- 分区表attach时可以利用check约束减少停机时间,而添加check约束又可以用到validate constraint
- create table like+attach比partition of的锁低很多(但我还是喜欢parition of)
变更后的注意事项:
- 记得收集统计信息(很多场景需要)
并发创建索引
在生产运维时,可能会碰到需要创建索引,但表又特别大,创建时间很长的情况。并发创建索引可以缩短建索引的时间。
普通表并发建索引:
并行参数:max_parallel_maintenance_workers
前提:
- worker是够的,需要检查
max_parallel_workers,max_worker_processes - 调整
maintenance_work_mem上GB
注意事项:
- 对 B-tree or BRIN有效
maintenance_work_memlimit to entire utility command。跟parallel query不同,parallel query的资源限制是 per worker process
从测试结果来看,并发建索引在8个并发以后收益不明显(这个结论在不同环境可能不保真)。
分区表并发建索引:
推荐分区子表手搓并发,即一次在多个分区上创建,而不是使用原生并发,这可以减少多进程交互代价。
cached plan must not change resource
业务前晚新增字段后,早上业务连接报错:“cached plan must not change result type in PostgreSQL”
复现:
create table a(b varchar(10));
PREPARE p1 (varchar) AS SELECT * FROM a WHERE b=$1;
ALTER TABLE a ALTER COLUMN b TYPE varchar(20);
EXECUTE p1 ('abcd');
ERROR: 0A000: cached plan must not change result type
LOCATION: RevalidateCachedQuery, plancache.c:718
测试环境的解决办法:
DEALLOCATE ALL主动丢弃prepared statement
或者,
DISCARD ALL主动丢弃整个会话状态
DEALLOCATE ALL; --DISCARD ALL
PREPARE p1 (varchar) AS SELECT * FROM a WHERE b=$1;
EXECUTE p1 ('abcd');
生产环境的解决办法:
由于是业务层报错,JDBC可识别DEALLOCATE ALL,DISCARD ALL,但是业务可能没有做过。当下生产可执行如下方案:
解决办法(四选一):
-
由于hikari等连接池的轮询启用连接和轮询timeout机制,可kill idle会话,报错会逐渐减少
-
同样是由于连接池的轮询启用连接和轮询timeout机制,可什么都不做,等连接池逐渐建立和启用新的连接
-
如果业务压力足够大,可考虑kill所有业务连接
-
轮询重启业务
不推荐:
- DDL后重启应用。有效,但不要建议“所有DDL后都应该重启应用”这样的方案
autosave=conservative。有效,但会启用子事务。savepoint is set for each query, however the rollback is done only for rare cases like ‘cached statement cannot change return type’ or ‘statement XXX is not valid’ so JDBC driver rolls back and retries
jdbc配置建议:
- 配置jdbc事务回滚后自动重试:https://developer.aliyun.com/article/741750
- 其他jdbc配置参考:https://jdbc.postgresql.org/documentation/server-prepare/#corner-cases,注意有些建议是不能上生产的。
物理复制
查询冲突
查询冲突是一个非常坑的特性,它直接影响了PG从库的查询是不那么好用的。查询冲突会导致从库延迟增加,而从库的拉数SQL本身要跑一段时间是符合逻辑的,这就导致PG管理者不得不在延迟管理和长SQL管理中做出平衡。而这个特性在其他关系型数据库中是不存在的。
查询冲突要注意的隐蔽特性:
- 静态表同样会产生查询冲突(见-从静态表查询冲突到其原理),也就是说冲突是快照冲突,与查询的表本身的锁几乎没有关系,快照冲突是跨表的。
- 长查影响短查。长查把从库延迟推到
max_standby_streaming_delay后,此时的短查也会被掐断。 - 不停的短查也会引起查询冲突。例如上个短查还没有结束,下一个短查又开始了,这两个短查逻辑可能是类似的,此时startup进程还没有来得应用日志。这在跑批中比较常见。这两个短查都持有那个需要应用的xid,可以检查
pg_stat_activity.backend_xmin是否小于startup正在应用的xid
查询从库推荐的实践:
- 通过RTO SLO来调整
max_standby_streaming_delay是一个不错的选择。当吵架到没有结果时,使用SLO来进行IT管理会救命。 - 短平快的业务查询与抽数、报表等长查询应该分到不同的从库,减少相互影响
- 从库查询SQL也是需要优化的
- 从库的日志应用延迟是需要监控的
逻辑复制
逻辑复制的坑可以说非常多了。24年有很多非常坑的案例,25年也遇到一些案例,但不算特别坑,而且主要是一些低版本pg上出现的,总体来看高版本的pg逻辑复制倾向稳定。
低版本PG+DDL/DCL语句解析较慢
PG13及之前的版本,对某些DDL、DCL语句解析较慢,可能会影响walsender延迟。这些DDL、DCL包括:
- 批量授权(含grant all tables)+ 安装了pathman extension(无论是否使用)
- 批量DDL/TRUNCATE/DCL/DROP PUBLICATION
低版本PG+多链路重复解析+flink
flink只能一个表一条链路,加上pg的walsender是重复解析的,一个pg库上几十条flink链路的walsender都是常见情况,而且改造困难。
而在pg11及以前,在walsender主循环中有PostmasterIsAlive()函数,导致主循环性能较差。从pg12开始WalSndLoop函数没有在主循环中频繁轮询PostmasterIsAlive(),而是将状态检查放到WalSndWait中,通过事件机制被动等待通知。这极大的缓解了CPU的争用。
如果库中有多个flink链路,而且pg版本较低,建议升级版本,可以缓解一定的walsender资源争用问题。这些可以缓解的资源问题包括:
- 可能会解决walsender启动时资源争用导致数据库长时间起不来的问题
- 可能会解决上游大量数据变动(含DDL重写)导致runtime walsender解析日志的cpu打满问题
低版本PG无法自动同步新分区
PG声明式分区在低版本需要注意仅能通过子表发布。pg版本>=13才支持按照父表配置发布,低于这个版本只能按分区子表的名称配置同步:
Allow partitioned tables to be logically replicated via publications (Amit Langote) § §
Previously, partitions had to be replicated individually. Now a partitioned table can be published explicitly, causing all its partitions to be published automatically. Addition/removal of a partition causes it to be likewise added to or removed from the publication. The
CREATE PUBLICATIONoptionpublish_via_partition_rootcontrols whether changes to partitions are published as their own changes or their parent’s.
也就是说,这个分区表如果是同步上游,每新增分区时,都要适配同步工具做发布,不然无法同步新分区数据。
迁移和升级
迁移信创和glibc升级
无论是信创迁移还是LINUX OS版本升级,都可能涉及glibc的升级,而glibc升级可能会非常坑。pg的排序在17以前都是完全依赖操作系统的。
pg没有办法检测glibc升级带来的兼容性问题。GNU C library每个小版本都会对locale做出改动,现实中最容易出问题的版本是glibc 2.28,因为2.28升级了大版本unicode 9.0.0(has been updated to a new upstream version from ISO which is in sync with Unicode 9.0.0)。
排序规则分了很多种,而很多环境用的是语义排序(例如en_US.utf8),语义排序也是最吃版本的。排序规则变化最常见的是引起查询索引时数据库奔溃,也还有其他不常见问题比如重复主键、分区表数据存入错误分区、merge join结果返回不一致等等。
好在pg17提供了非常安全的locale提供方式:builtin,不再依赖OS提供的glibc、ICU等provider。启用命令例如:
initdb --locale-provider=builtin --bultin-locale=C.UTF-8 dbname1
但是,
builtin虽然是个好东西但是来得太迟了。大量已投入使用的数据库实例,想转builtin的字符集可不是一件容易的事。而且,信创迁移或者OS升级可能不会将数据库升级作为强制动作。
信创迁移时,信创主机的glibc版本一般都比老的英特尔服务器glibc版本高,很可能跨了2.28这个版本。加上任务急、kpi推动、人力不足和大库,物理迁移是在所难免。所以信创物理迁移得关注glibc版本和collation导致的许多异常。
物理迁移后可以做什么?
一、官方必修方案
1.check索引,重建明显有问题的索引
2.REFRESH DATABASE COLLATION VERSION
3.检查依赖对象
4.REFRESH COLLATION VERSION
二、非官方邪修方案
我这没有做出完整的方案,只是一点思路。
1.处理分区表写入错误分区的问题
分区键是int/bigint/float,跟collation没有关系,可以不用管了
分区键是时间分区,如果是timestamp不用管了,如果是varchar等等字符类型,就看情况了
分区键是字符类型,参考“a”和“-”的排序(pgconf Collation Challenges Sorting It Out)。但要注意以下几点
- 如果要查数据的话,不要从父表查,可能会崩或者查不出来
- 没有简单的检测方案
2.处理主键/唯一键冲突
3.处理fdw排序范围异常的问题
4.未知问题
丝滑大版本升级
https://gitlab.com/postgres-ai/postgresql-consulting/postgres-howtos/-/blob/main/0077_zero_downtime_major_upgrade.md?ref_type=heads
https://www.postgresql.eu/events/pgconfeu2023/sessions/session/4791/slides/439/2023.pgconf.eu%20Zero%20Downtime%20PostgreSQL%20Upgrades.pdf
一般的大版本升级方案:
- pg_upgrade原地升级。不推荐,可能原地爆炸。
- pgdump:适合小库,窗口期较长的库
- 逻辑同步+switchover(发布订阅/pg_logical/dts等):适合小库,窗口期较短的库
- 物理正向同步+逻辑反向同步:适合大库,窗口期不太长的库
- 物理复制全量+逻辑同步增量+switchover:适合大库,窗口期极短的库
用逻辑同步同步全量数据可能是非常慢的,而用新从库原地升级本身带有不确定性,有一定的升级时间,而且也要解决反向逻辑同步的问题。“丝滑大版本升级”其实就是“物理复制全量+逻辑同步增量+switchover”。
丝滑大版本升级的主要技术:主库创建slot会返回LSN,新从库recovery_target_lsn 恢复到这个LSN,然后开启逻辑同步。
方案的大致流程:
- 预检查。多db(多db要考虑应用一个slot lsn)、插件、pathman、trigger、外键、unlogged表、crontab等等
- 物理同步。新老版本软件、对比和备份conf文件、pg_basebackup搭建低版本新库
- 逻辑同步准备一。主键和复制标识、创建发布;禁止业务发布DDL/DCL
- 新库恢复到target LSN。停新库;老库创建slot并记录LSN;新库以target LSN启动
- 新库大版本升级。升级、处理各种问题、环境变量切换
- 逻辑同步准备二。禁用trigger、外键、任务、插件等
- 逻辑同步。创建指定slot的copy_data=false订阅
- 逻辑同步后。索引损坏检查、检查日志报错并修复、重建同城远程
- switchover。停业务;提升序列、启用外键、trigger、任务等
- switchover。搭建反向链路(老库订阅)
- switchover。业务切换
丝滑大版本升级的方案对于业务很丝滑,对于DBA很复杂。这个方案包含了逻辑迁移和物理迁移的所有缺点,做起来是比较痛苦的,以上步骤已经简化过了。该方案消耗DBA人力,对于非常重要的库可以考虑这个方案。
分区表的管理
Postgres分区表非常灵活,没有自增interval分区功能,而且版本多变,导致分区表运维管理问题几乎是年年发生。我相信有不少PG DBA对于新分区的各种问题还提心吊胆的。
我自己观察下来分区表的管理和使用主要有如下问题:
- 未使用声明式分区表。老版本仍然使用pathman分区或继承表分区,或者即便升级后仍然使用pathman分区或继承表分区。PG10开始支持声明式分区,由于早期版本有功能不足,建议至少PG12以后就仅使用声明式分区表,以减少环境的复杂性。
- 开发自建子表索引/主键。不通过父表默认继承而是通过SQL直接在子表建索引/主键,会导致下一次开发写SQL时可能就忘记了。这不仅会导致父子不一致,也会导致子子不一致,最终导致分区表结构面目全非。
- 新分区无管理策略。忘记建新分区或者用default分区。一般开发会建个几年的分区,下一次可能开发都换了一批了,没人会去管这个新分区建设。这会定时炸弹随时爆炸,或者数据写入default分区失去分区意义。
- 缺乏DBA的管理。是的,DBA!PG的分区表知识实在是多(参考PostgreSQL分区表),怎么基于自己的环境做管理策略和落地,需要专业DBA的主动推动。这可能是最重要的。
自己思考的分区表管理目标(copy的这个案例-20260101分区数据更新失败):
- 以主表结构为标准结构,即主表面向开发,它上面应该有主键、索引、复制标识(pg版本不支持除外)
- 主表与子表保持一致,使用partition of创建新分区(是的,我不推荐attach)
- 子表与子表保持一致
- 提前创建新分区,分区数据量不宜过多
- default分区不建议创建,如果创建必须监控其写入情况
- 频繁访问的表的SQL必须包含分区键,使用分区裁剪,不然改造为普通表
可观测性
从官方文档中基本都能看到数据库、表、索引、SQL、刷脏等等指标释义,还是比较清楚的。
其中有几个指标可能要特别注意一下,不仅解释的不是很清楚,而且常用且有理解成本。
buffers_alloc、blks_read
pg_stat_bgwriter.buffers_alloc: Number of buffers allocated,共享内存置换量pg_stat_database.blks_read:os cache读
(buffers_alloc在不同PG版本可能在不同视图中,但含义不变)
pg_stat_bgwriter.buffers_alloc是共享内存的buffer分配量,源码中叫buffer allocation。可以代表共享内存的置换量,新起的库一般这个值比较高。观察共享内存繁忙程度时,buffer allocate可能要比命中率好,命中率高可能就是小表频繁访问拉高了,allocate是产生了实质的置换的。
buffers_alloc是从cache读数后加载到新的共享内存buffer,其实也能一定程度代表os cache read吧?但是实际观察下来,buffers_alloc与blks_read含义如此相似但数值可能差异较大。为什么?没搞懂,待研究。
源码:numBufferAllocs
tup_fetched、tup_returned
这俩是pg_stat_database 中的指标:
tup_fetched:索引扫描最终获取的行数,去掉了过滤条件、死亡元组、不可见行后的行。偏向于结果。tup_returned:索引扫描回表的行数,不管是否满足过滤条件、死亡元组、不可见行后的行。偏向于处理过程
所以,tup_returned 一般比tup_fetched 高不少。而异常高,也代表可能有优化空间,因为毕竟访问了这么多数据,实际上没有返回给客户端多少。
idx_tup_fetch 、idx_tup_read
这俩是pg_stat_all_indexes 中的指标:
idx_tup_read:从索引计数的访问索引条目数,包含bitmap scanidx_tup_fetch:从表计数的索引扫描最终返回的行数,不包含bitmap scan
疯了
可以记住一个点:xx_tup_fetch是指经过索引回表访问后返回的最终行数,偏向于结果。
参考内容
Best practices for using pgvector
https://liuzhilong.blog.csdn.net/article/details/130783036
https://techcommunity.microsoft.com/blog/adforpostgresql/improving-postgres-connection-scalability-snapshots/1806462
https://www.postgresql.org/docs/17/sql-prepare.html
https://www.postgresql.org/docs/17/sql-deallocate.html
https://www.postgresql.org/docs/release/13.0/
https://jdbc.postgresql.org/documentation/use/
https://jdbc.postgresql.org/documentation/server-prepare/#server-prepared-statements
https://www.postgresql.eu/events/pgconfeu2023/sessions/session/4791/slides/439/2023.pgconf.eu%20Zero%20Downtime%20PostgreSQL%20Upgrades.pdf
感谢25年跟高大师的battle
