




关于碎片的形成
- 一般来说,关系型为主的多模数据库或者纯关系型数据库,对于执行delete的操作都不会释放数据空间。从而产生碎片。
- 最好的方式就是,有一定的规划,比如分区之类。通过分区的转移来移除数据。这样不产生碎片。
一旦产生碎片。怎么办?
- 最低级的操作就是把表进行逻辑导出,然后再进行逻辑导入。如果表大的话,这种几乎不可行。
- 还有就是新建一个表,然后两个表换名字,慢慢搬迁需要的数据。
- 还有一个方案就是做碎片整理。
- 有人说利用数据库主从切换的方式整理(我个人是不同意的,小题大做)
碎片整理实质
- 把数据物理位置移动的更加紧凑,然后释放空的数据块。从而达到缩小数据占用空间的目的。
- 取决于表的大小、碎片的程度,以及数据库的处理能力(在线还是停机),当然也和磁盘的IO吞吐能力有很大关系。
说说我的实际经验:
- 最后一次实操那是2012年了。距今都13年多了。那时候次我有一个表大概40-50T了。由于使用不当,有了大约800G-1T的碎片。
- 对,你没有看错,我的碎片都比现如今很多企业的大数据都要大。
- 那次我做了碎片整理,可以在线做,不影响读写。我特意在做之前记录了时间,最后看整个过程用了多久。最后看是55个小时。
- 我另外一个同事也遇到了同样的问题(因为都是一样的软件一样的系统,在各个项目中的问题都是一样),而他整个过程用了550个小时。
- 要知道一个月一共720个小时。我们的区别是我们的数据库是一样的,业务读写压力也是差不多的。唯一区别是我们的存储IO能力。在那个时候我们没有SSD,我要求项目的配置必须是15K转速的磁盘,而且做RAID10。我是比较强硬的。而另外项目就是去迁就了,而且还是RAID5。最后我们的存储能力就差很多。建立一个10G的数据文件,我是大约30秒,他是5分半。这点上我们两个项目的能力差了11倍。所以最终那次碎片整理他用了我10倍的时间。
本来有这样的经验所碎片回收应该没有问题
- 但是总有盲点
- 上周遇到一个问题还是让我觉得经验还是不足。

- 这个出错,我去查了一下。
- Shrink operations can be performed only on segments in locally managed tablespaces with automatic segment space management (ASSM). Within an ASSM tablespace, all segment types are eligible for online segment shrink except these:
■ IOT mapping tables
■ Tables with rowid based materialized views
■ Tables with function-based indexes
■ SECUREFILE LOBs
■ Compressed tables - 从上面看唯一有可能的就是我们有函数索引。一般来说给时间字段建立to_char这样的就是。于是我想看看到底是哪个列。
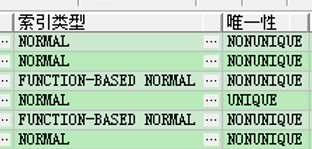
- 查询先来果然有两个函数索引。一般来说不到万不得已,我不会允许建立函数索引的。需要看看具体的列。
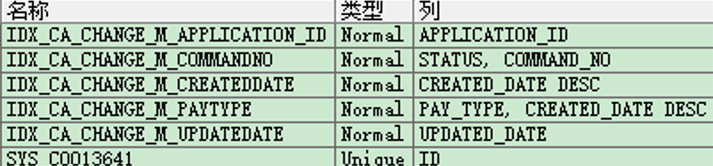
- 有两个 以时间字段的索引 带有desc。其中一个还是我让这样建立的。因为业务需要看最新的数据。而这样就能避免排序了。
- 问题就在这里,默认建立时间是升序的,不算函数索引。我显示声明了一下降序,就算函数索引。这让我不理解了。因为在此之前的认知中只有带上函数的才算。
- 但是事实就是如此。
最终先增加数据文件的方式维持现在
- 这件事让我如今再有把握的事情,我都会当自己和入门级一样去多问问。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
