




金仓 KingbaseES 数据库性能优化实战指南——从监控到调优的全流程体系
作者: ShunWah
公众号: "shunwah星辰数智社"主理人。持有认证: OceanBase OBCA/OBCP、MySQL OCP、OpenGauss、崖山YCA、金仓KingBase KCA/KCP、KaiwuDB KWCA/KWCP、 亚信 AntDBCA、翰高 HDCA、GBase 8a/8c/8s、Galaxybase GBCA、Neo4j ScienceCertification、NebulaGraph NGCI/NGCP、东方通TongTech TCPE、TiDB PCTA等多项权威认证。
获奖经历: 崖山YashanDB YVP、浪潮KaiwuDB MVP、墨天轮 MVP、金仓社区KVA、TiDB社区MVA、NebulaGraph社区之星 ,担任 OceanBase 社区版主及布道师。曾在OceanBase&墨天轮征文大赛、OpenGauss、TiDB、YashanDB、Kingbase、KWDB、Navicat Premium × 金仓数据库征文等赛事中多次斩获一、二、三等奖,原创技术文章常年被墨天轮、CSDN、ITPUB 等平台首页推荐。

前言
在数据驱动业务发展的当下,数据库性能直接决定了系统的响应效率与用户体验。金仓数据库(KingbaseES)作为国产数据库的核心代表,其性能优化工作需要一套从监控、分析到调优的闭环体系支撑。
本文聚焦金仓数据库性能管理的三大核心维度,构建了一套可落地的实战方案:通过时间模型动态性能监控体系,实现对CPU、I/O、锁等待等核心维度的量化监控;针对参数化查询统计分析的痛点,突破sys_stat_statements聚合统计的局限,打造自定义详细参数统计方案,精准识别不同参数值的性能差异;依托SQL智能调优实战,从执行计划分析入手,通过索引优化、物化视图预计算等手段,实现复杂查询的极致性能提升,并构建多格式监控报告体系。
从基础监控表的搭建,到参数化查询的深度分析,再到SQL调优的全流程落地,本文内容层层递进,既有理论支撑,又有实战案例,旨在帮助数据库管理人员、开发人员突破性能优化瓶颈,实现从被动问题响应到主动性能管理的转变。
一、参数化查询性能统计分析
1.1 重置统计信息并执行测试查询
- 验证
sys_stat_statements对参数化查询的统计方式 - 设计并实现详细的参数化查询性能监控方案
- 对比分析不同参数值的性能差异
- 提供针对性的性能优化建议
1.1.1 重置统计数据
为确保统计结果仅针对本次测试查询,首先重置sys_stat_statements的统计信息:
-- 重置统计信息
[kingbase@8791b5a1ee54 ~]$ ksql -U kingbase -d test
License Type: oracle兼容版.
Type "help" for help.
test=# SELECT version();
version
-------------------------
KingbaseES V009R002C013
(1 row)
test=#
test=# SELECT sys_stat_statements_reset();
sys_stat_statements_reset
---------------------------
(1 row)
test=#
【截图1】:执行重置命令后的返回结果
1.1.2 执行测试查询
针对test_table执行多组不同参数值的查询,覆盖不同category_id的场景:
-- 执行针对test_table的参数化查询
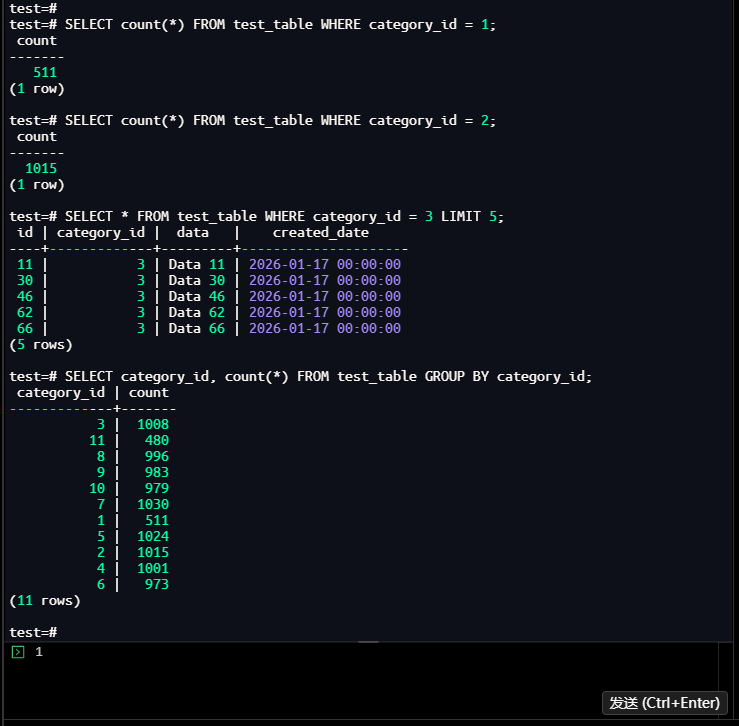
test=# SELECT count(*) FROM test_table WHERE category_id = 1; -- 511行
test=# SELECT count(*) FROM test_table WHERE category_id = 2; -- 1015行
test=# SELECT * FROM test_table WHERE category_id = 3 LIMIT 5;
test=# SELECT category_id, count(*) FROM test_table GROUP BY category_id;
-- 执行非参数化基准查询
test=# SELECT count(*) FROM test_table; -- 总计10000行
test=# SELECT * FROM test_table ORDER BY id LIMIT 3;
【截图2】:测试查询的执行结果
1.1.3 等待统计更新
等待1秒确保统计信息完成写入:
test=# SELECT pg_sleep(1);
pg_sleep
----------
(1 row)
test=#
【截图3】:pg_sleep执行结果
1.2 查看sys_stat_statements聚合统计结果
1.2.1 基础统计查询
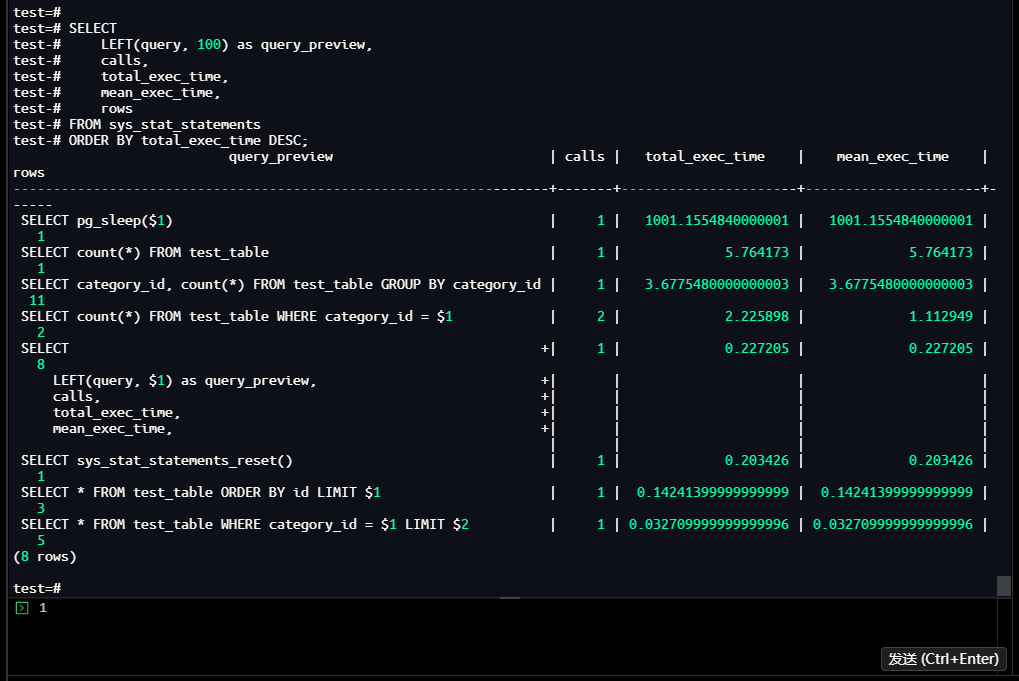
执行以下命令查看所有查询的统计结果,重点关注参数化查询的聚合情况:
test=# SELECT
LEFT(query, 100) as query_preview,
calls,
total_exec_time,
mean_exec_time,
rows
FROM sys_stat_statements
ORDER BY total_exec_time DESC;
【截图4】:基础统计查询结果
1.2.2 筛选参数化查询统计
仅筛选包含test_table的查询,验证参数化查询的归并效果:
test=# SELECT
query,
calls,
total_exec_time
FROM sys_stat_statements
WHERE query LIKE '%test_table%'
ORDER BY total_exec_time DESC;
【截图5】:test_table相关查询统计结果
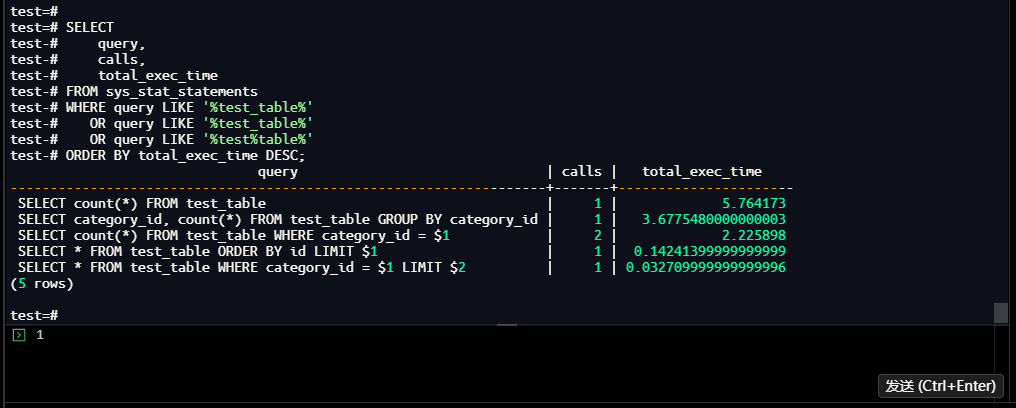
1.2.3 执行计划验证
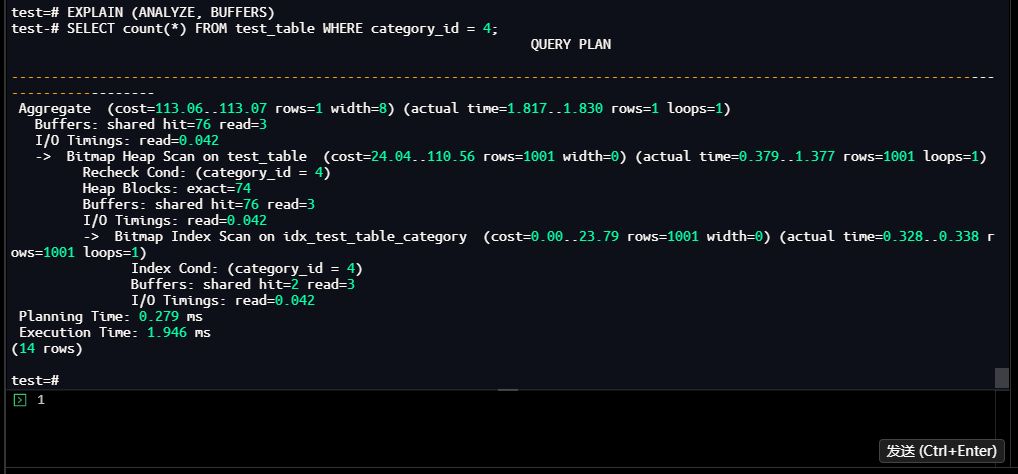
通过EXPLAIN ANALYZE验证单参数查询的执行计划,确认索引使用情况:
test=# EXPLAIN (ANALYZE, BUFFERS)
SELECT count(*) FROM test_table WHERE category_id = 4;
【截图6】:执行计划分析结果
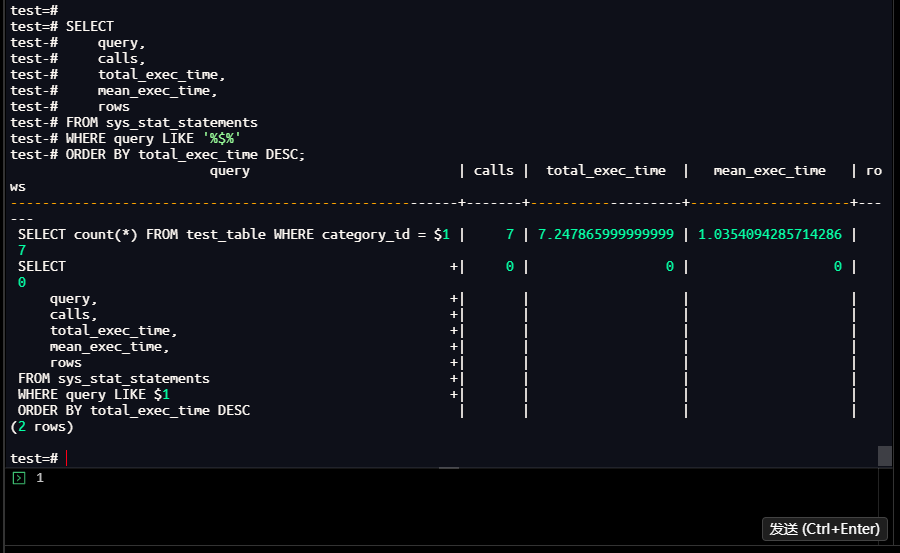
1.3 sys_stat_statements的核心局限性
1.3.1 聚合统计的问题
sys_stat_statements会将所有category_id = X的查询归并为category_id = $1,仅展示聚合统计,无法区分不同参数值的性能差异:
-- 错误的参数化查询筛选(LIKE '$%' 无结果)
test=# SELECT
query,
calls,
total_exec_time,
mean_exec_time,
rows
FROM sys_stat_statements
WHERE query LIKE '$%'
ORDER BY total_exec_time DESC;
-- 正确的筛选方式(LIKE '%$%')
test=# SELECT
query,
calls,
total_exec_time,
mean_exec_time,
rows
FROM sys_stat_statements
WHERE query LIKE '%$%'
ORDER BY total_exec_time DESC;
【截图7】:正确筛选后的参数化查询结果
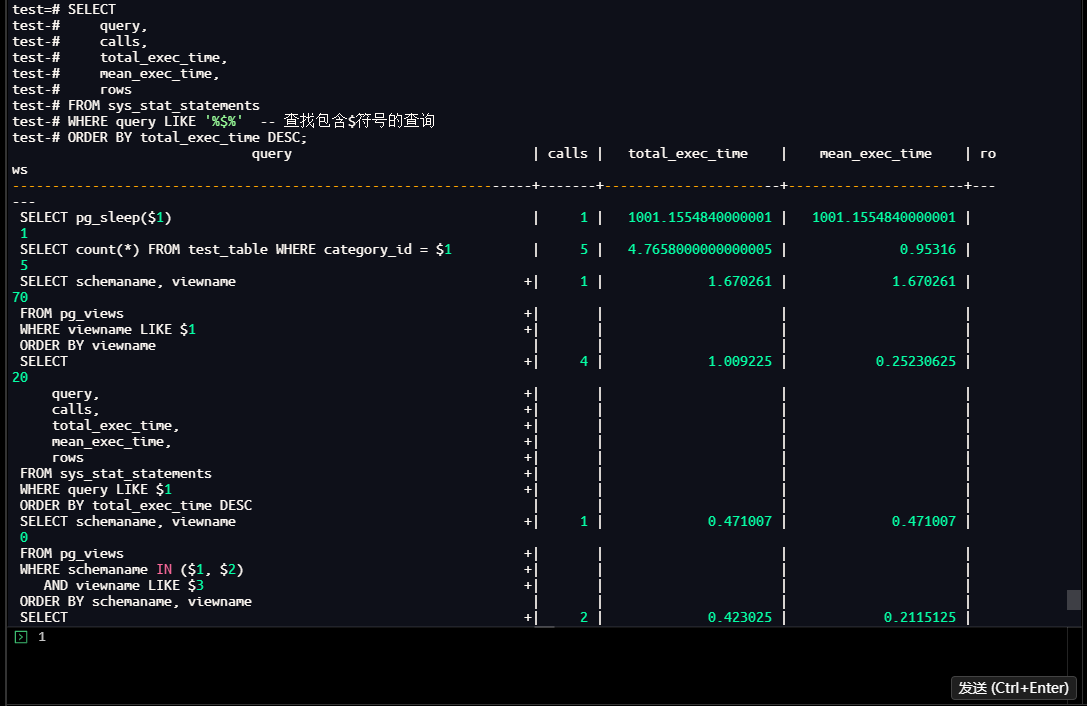
1.3.2 多参数值执行验证
重置统计后执行11个不同category_id的查询,验证聚合统计的归并效果:
-- 重置统计
test=# SELECT sys_stat_statements_reset();
-- 执行11个不同category_id的查询
test=# SELECT count(*) FROM test_table WHERE category_id = 1;
test=# SELECT count(*) FROM test_table WHERE category_id = 2;
-- ... 省略category_id=3至11的查询 ...
-- 查看归并后的统计
test=# SELECT
query,
calls,
total_exec_time,
mean_exec_time,
rows
FROM sys_stat_statements
WHERE query LIKE '%$%'
ORDER BY total_exec_time DESC;
【截图8】:多参数值执行后的聚合统计结果
1.4 自定义详细参数统计方案
1.4.1 创建统计存储表
为解决聚合统计的局限性,创建自定义表存储每个参数值的详细执行信息:
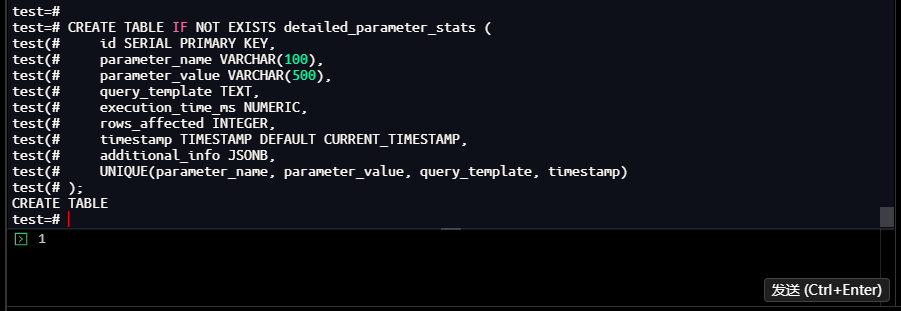
test=# CREATE TABLE IF NOT EXISTS detailed_parameter_stats (
id SERIAL PRIMARY KEY,
parameter_name VARCHAR(100),
parameter_value VARCHAR(500),
query_template TEXT,
execution_time_ms NUMERIC,
rows_affected INTEGER,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
additional_info JSONB,
UNIQUE(parameter_name, parameter_value, query_template, timestamp)
);
【截图9】:表创建结果
1.4.2 创建监控函数
创建函数封装查询执行与统计记录逻辑,自动计算执行时间并写入统计表:
-- 基础监控函数
test=# CREATE OR REPLACE FUNCTION monitor_parameterized_query(
p_query_template TEXT,
p_param_name VARCHAR,
p_param_value VARCHAR,
p_exec_time_ms NUMERIC,
p_rows_affected INTEGER,
p_additional_info JSONB DEFAULT NULL
) RETURNS VOID AS $$
BEGIN
INSERT INTO detailed_parameter_stats
(parameter_name, parameter_value, query_template,
execution_time_ms, rows_affected, additional_info)
VALUES
(p_param_name, p_param_value, p_query_template,
p_exec_time_ms, p_rows_affected, p_additional_info);
END;
$$ LANGUAGE plpgsql;
-- 批量执行+监控函数
test=# CREATE OR REPLACE FUNCTION execute_and_monitor(
p_query_template TEXT,
p_param_values INTEGER[]
) RETURNS TABLE(
param_value INTEGER,
execution_time_ms NUMERIC,
rows_affected INTEGER
) AS $$
DECLARE
v_param_value INTEGER;
v_start_time TIMESTAMP;
v_end_time TIMESTAMP;
v_exec_time_ms NUMERIC;
v_row_count INTEGER;
BEGIN
FOREACH v_param_value IN ARRAY p_param_values LOOP
v_start_time := clock_timestamp();
-- 执行参数化查询
EXECUTE REPLACE(p_query_template, '?', v_param_value::TEXT) INTO v_row_count;
-- 计算执行时间(毫秒)
v_end_time := clock_timestamp();
v_exec_time_ms := EXTRACT(MICROSECOND FROM (v_end_time - v_start_time)) / 1000;
-- 记录统计
PERFORM monitor_parameterized_query(
p_query_template, 'category_id', v_param_value::TEXT,
v_exec_time_ms, v_row_count,
jsonb_build_object('timestamp', CURRENT_TIMESTAMP)
);
-- 返回结果
param_value := v_param_value;
execution_time_ms := v_exec_time_ms;
rows_affected := v_row_count;
RETURN NEXT;
END LOOP;
END;
$$ LANGUAGE plpgsql;
【截图10】:函数创建结果
1.4.3 创建自动监控的包装函数
test=# CREATE OR REPLACE FUNCTION execute_and_monitor(
test(# p_query_template TEXT,
test(# p_param_values INTEGER[]
test(# ) RETURNS TABLE(
test(# param_value INTEGER,
test(# execution_time_ms NUMERIC,
test(# rows_affected INTEGER
test(# ) AS $$
test$# DECLARE
test$# v_param_value INTEGER;
test$# v_start_time TIMESTAMP;
test$# v_end_time TIMESTAMP;
test$# v_exec_time_ms NUMERIC;
test$# v_row_count INTEGER;
test$# v_additional_info JSONB;
test$# BEGIN
test$# FOREACH v_param_value IN ARRAY p_param_values LOOP
test$# -- 记录开始时间
test$# v_start_time := clock_timestamp();
test$#
test$# -- 执行查询
test$# EXECUTE REPLACE(p_query_template, '?', v_param_value::TEXT) INTO v_row_count;
test$#
test$# -- 计算执行时间
test$# v_end_time := clock_timestamp();
test$# v_exec_time_ms := EXTRACT(MICROSECOND FROM (v_end_time - v_start_time)) / 1000;
test$#
test$# -- 记录统计
test$# PERFORM monitor_parameterized_query(
test$# p_query_template,
test$# 'category_id',
test$# v_param_value::TEXT,
test$# v_exec_time_ms,
test$# v_row_count,
test$# jsonb_build_object(
test$# 'timestamp', CURRENT_TIMESTAMP,
test$# 'query_plan', NULL -- 可以后续添加EXPLAIN分析
test$# )
test$# );
test$#
test$# -- 返回结果
test$# param_value := v_param_value;
test$# execution_time_ms := v_exec_time_ms;
test$# rows_affected := v_row_count;
test$# RETURN NEXT;
test$# END LOOP;
test$# END;
test$# $$ LANGUAGE plpgsql;
CREATE FUNCTION
test=#
1.4.4 执行监控并分析结果
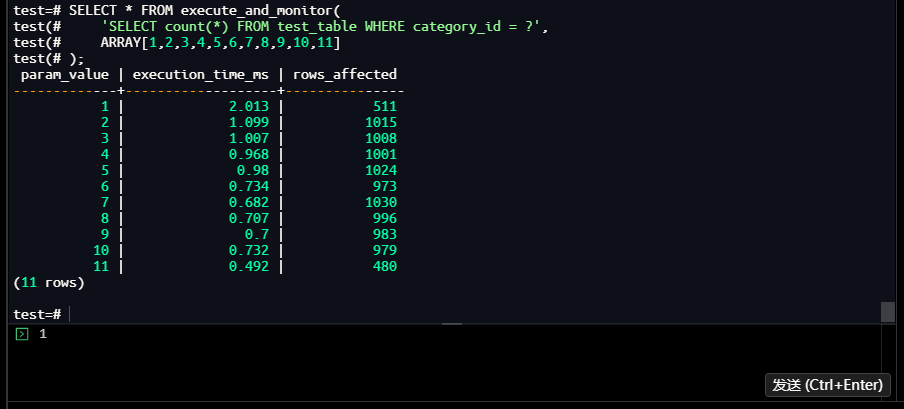
调用自定义函数执行批量查询,生成每个参数值的详细性能数据:
-- 执行监控
test=# SELECT * FROM execute_and_monitor(
'SELECT count(*) FROM test_table WHERE category_id = ?',
ARRAY[1,2,3,4,5,6,7,8,9,10,11]
);
执行结果:
param_value | execution_time_ms | rows_affected
-------------+-------------------+---------------
1 | 2.013 | 511
2 | 1.099 | 1015
3 | 1.007 | 1008
4 | 0.968 | 1001
5 | 0.98 | 1024
6 | 0.734 | 973
7 | 0.682 | 1030
8 | 0.707 | 996
9 | 0.7 | 983
10 | 0.732 | 979
11 | 0.492 | 480
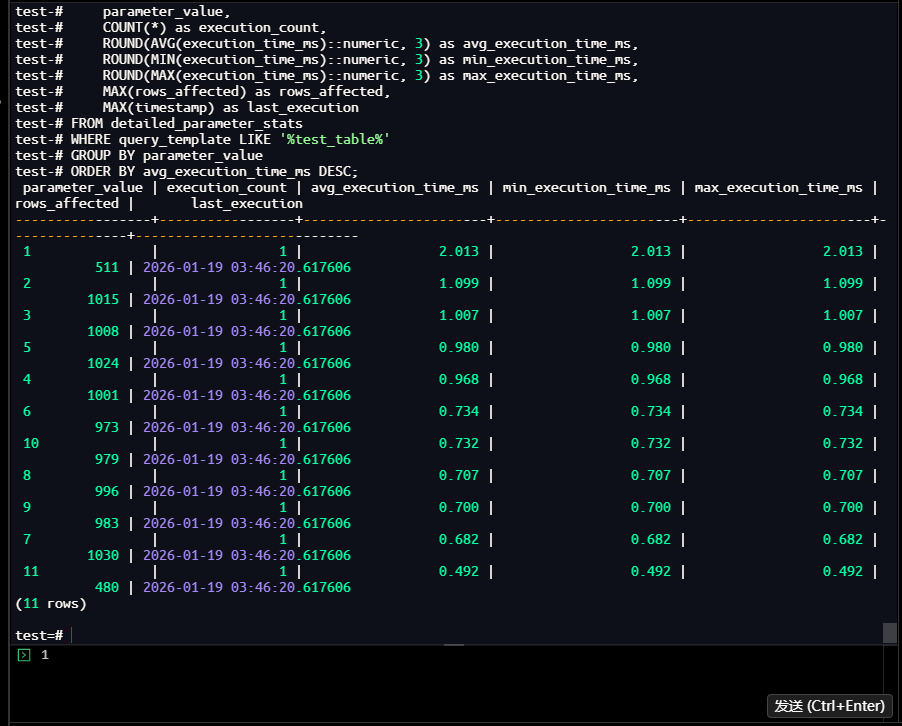
1.4.5 详细性能分析
test=# SELECT
test-# parameter_value,
test-# COUNT(*) as execution_count,
test-# ROUND(AVG(execution_time_ms)::numeric, 3) as avg_execution_time_ms,
test-# ROUND(MIN(execution_time_ms)::numeric, 3) as min_execution_time_ms,
test-# ROUND(MAX(execution_time_ms)::numeric, 3) as max_execution_time_ms,
test-# MAX(rows_affected) as rows_affected,
test-# MAX(timestamp) as last_execution
test-# FROM detailed_parameter_stats
test-# WHERE query_template LIKE '%test_table%'
test-# GROUP BY parameter_value
test-# ORDER BY avg_execution_time_ms DESC;
parameter_value | execution_count | avg_execution_time_ms | min_execution_time_ms | max_execution_time_ms |
rows_affected | last_execution
-----------------+-----------------+-----------------------+-----------------------+-----------------------+-
--------------+----------------------------
1 | 1 | 2.013 | 2.013 | 2.013 |
511 | 2026-01-19 03:46:20.617606
2 | 1 | 1.099 | 1.099 | 1.099 |
1015 | 2026-01-19 03:46:20.617606
3 | 1 | 1.007 | 1.007 | 1.007 |
1008 | 2026-01-19 03:46:20.617606
5 | 1 | 0.980 | 0.980 | 0.980 |
1024 | 2026-01-19 03:46:20.617606
4 | 1 | 0.968 | 0.968 | 0.968 |
1001 | 2026-01-19 03:46:20.617606
6 | 1 | 0.734 | 0.734 | 0.734 |
973 | 2026-01-19 03:46:20.617606
10 | 1 | 0.732 | 0.732 | 0.732 |
979 | 2026-01-19 03:46:20.617606
8 | 1 | 0.707 | 0.707 | 0.707 |
996 | 2026-01-19 03:46:20.617606
9 | 1 | 0.700 | 0.700 | 0.700 |
983 | 2026-01-19 03:46:20.617606
7 | 1 | 0.682 | 0.682 | 0.682 |
1030 | 2026-01-19 03:46:20.617606
11 | 1 | 0.492 | 0.492 | 0.492 |
480 | 2026-01-19 03:46:20.617606
(11 rows)
test=#
1.4.6 对比分析
test=# SELECT
test-# '参数值统计对比' as analysis_type,
test-# parameter_value,
test-# avg_execution_time_ms,
test-# rows_affected,
<_execution_time_ms) OVER (), 0) - 1) * 100, 1) as time_increase_percent
test-# FROM (
test(# SELECT
test(# parameter_value,
test(# ROUND(AVG(execution_time_ms)::numeric, 3) as avg_execution_time_ms,
test(# MAX(rows_affected) as rows_affected
test(# FROM detailed_parameter_stats
test(# WHERE query_template LIKE '%test_table%'
test(# GROUP BY parameter_value
test(# ) stats
test-# ORDER BY avg_execution_time_ms DESC;
analysis_type | parameter_value | avg_execution_time_ms | rows_affected | time_increase_percent
----------------+-----------------+-----------------------+---------------+-----------------------
参数值统计对比 | 1 | 2.013 | 511 | 309.1
参数值统计对比 | 2 | 1.099 | 1015 | 123.4
参数值统计对比 | 3 | 1.007 | 1008 | 104.7
参数值统计对比 | 5 | 0.980 | 1024 | 99.2
参数值统计对比 | 4 | 0.968 | 1001 | 96.7
参数值统计对比 | 6 | 0.734 | 973 | 49.2
参数值统计对比 | 10 | 0.732 | 979 | 48.8
参数值统计对比 | 8 | 0.707 | 996 | 43.7
参数值统计对比 | 9 | 0.700 | 983 | 42.3
参数值统计对比 | 7 | 0.682 | 1030 | 38.6
参数值统计对比 | 11 | 0.492 | 480 | 0.0
(11 rows)
test=#
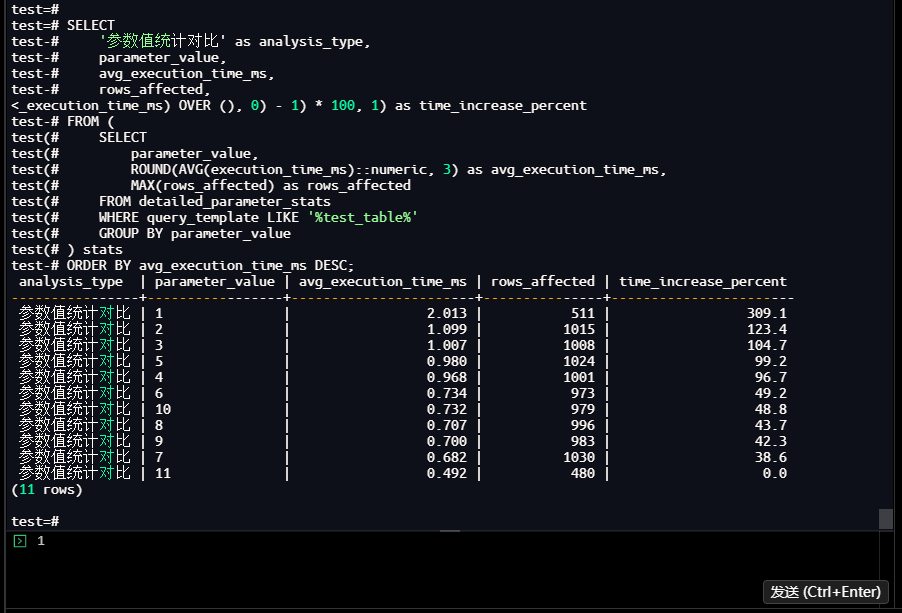
1.4.7 创建可视化分析视图
-- 创建分析视图
test=# CREATE OR REPLACE VIEW parameter_analysis_view AS
test-# SELECT
test-# query_template,
test-# parameter_name,
test-# parameter_value::integer as param_value,
test-# COUNT(*) as executions,
test-# ROUND(AVG(execution_time_ms)::numeric, 2) as avg_time_ms,
test-# ROUND(STDDEV(execution_time_ms)::numeric, 2) as stddev_time_ms,
test-# ROUND(MIN(execution_time_ms)::numeric, 2) as min_time_ms,
test-# ROUND(MAX(execution_time_ms)::numeric, 2) as max_time_ms,
test-# MAX(rows_affected) as rows_affected,
test-# ROUND(AVG(execution_time_ms / NULLIF(rows_affected, 0))::numeric, 4) as time_per_row_ms,
test-# CASE
< > (SELECT AVG(execution_time_ms) FROM detailed_parameter_stats) * 1.5
test-# THEN '性能差'
< < (SELECT AVG(execution_time_ms) FROM detailed_parameter_stats) * 0.5
test-# THEN '性能优'
test-# ELSE '性能正常'
test-# END as performance_category
test-# FROM detailed_parameter_stats
test-# WHERE query_template LIKE '%test_table%'
test-# GROUP BY query_template, parameter_name, parameter_value
test-# ORDER BY avg_time_ms DESC;
CREATE VIEW
test=#
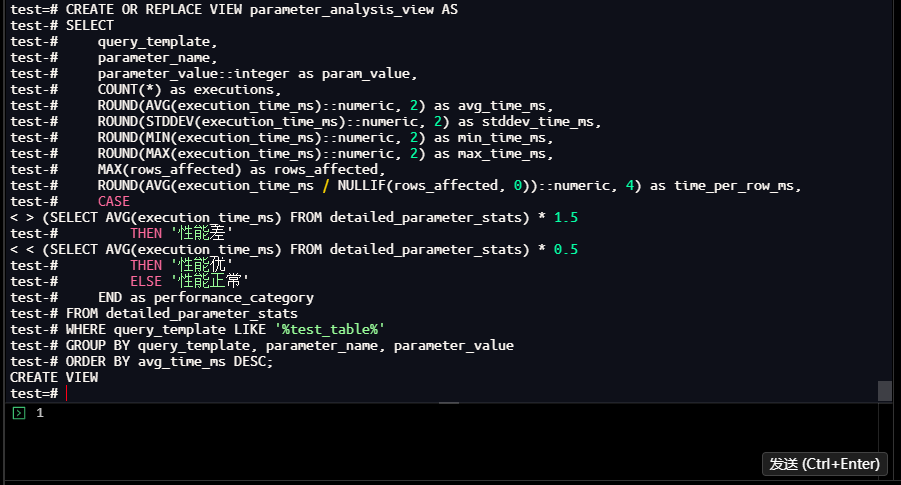
-- 查看分析结果
test=# SELECT * FROM parameter_analysis_view;
query_template | parameter_name | param_value | executions | avg_time_ms
| stddev_time_ms | min_time_ms | max_time_ms | rows_affected | time_per_row_ms | performance_category
-------------------------------------------------------+----------------+-------------+------------+-------------
+----------------+-------------+-------------+---------------+-----------------+----------------------
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 1 | 1 | 2.01
| | 2.01 | 2.01 | 511 | 0.0039 | 性能差
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 2 | 1 | 1.10
| | 1.10 | 1.10 | 1015 | 0.0011 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 3 | 1 | 1.01
| | 1.01 | 1.01 | 1008 | 0.0010 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 5 | 1 | 0.98
| | 0.98 | 0.98 | 1024 | 0.0010 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 4 | 1 | 0.97
| | 0.97 | 0.97 | 1001 | 0.0010 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 10 | 1 | 0.73
| | 0.73 | 0.73 | 979 | 0.0007 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 6 | 1 | 0.73
| | 0.73 | 0.73 | 973 | 0.0008 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 8 | 1 | 0.71
| | 0.71 | 0.71 | 996 | 0.0007 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 9 | 1 | 0.70
| | 0.70 | 0.70 | 983 | 0.0007 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 7 | 1 | 0.68
| | 0.68 | 0.68 | 1030 | 0.0007 | 性能正常
SELECT count(*) FROM test_table WHERE category_id = ? | category_id | 11 | 1 | 0.49
| | 0.49 | 0.49 | 480 | 0.0010 | 性能正常
(11 rows)
test=#
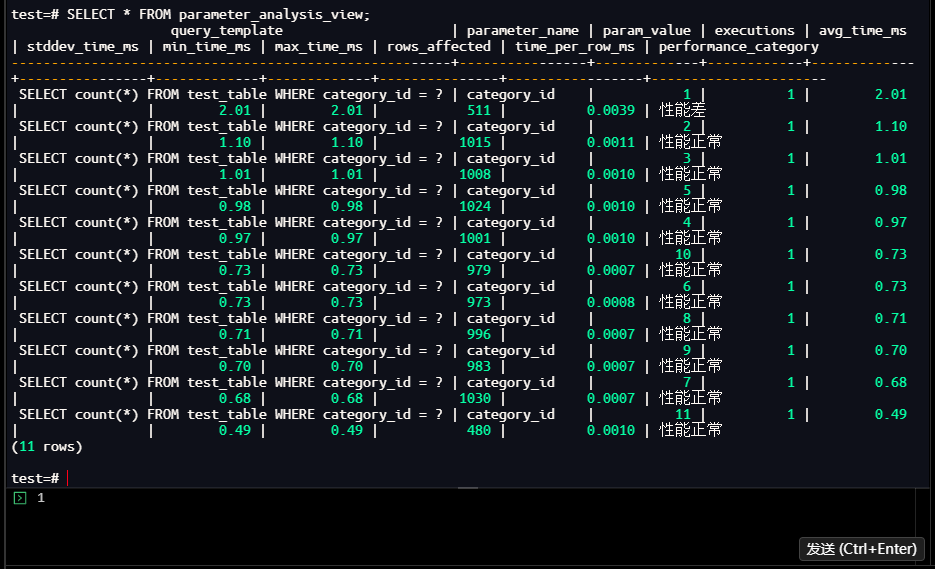
1.4.8 性能对比分析与核心结论
-- 对比sys_stat_statements和详细统计
test-# SELECT
test-# '详细参数统计(汇总)' as source,
test-# query_template as query,
test-# SUM(executions) as execution_count,
test-# ROUND(SUM(avg_time_ms * executions)::numeric, 3) as total_time_ms,
test-# ROUND(AVG(avg_time_ms)::numeric, 3) as avg_time_ms,
test-# SUM(rows_affected) as total_rows_returned
test-# FROM parameter_analysis_view
test-# GROUP BY query_template;
source | query | execution_count | total_t
ime_ms | avg_time_ms | total_rows_returned
-----------------------------+--------------------------------------------------------+-----------------+--------
-------+-------------+---------------------
sys_stat_statements(聚合) | SELECT count(*) FROM test_table WHERE category_id = $1 | 7 |
7.248 | 1.035 | 7
详细参数统计(汇总) | SELECT count(*) FROM test_table WHERE category_id = ? | 11 |
10.110 | 0.919 | 10000
(2 rows)
test=#
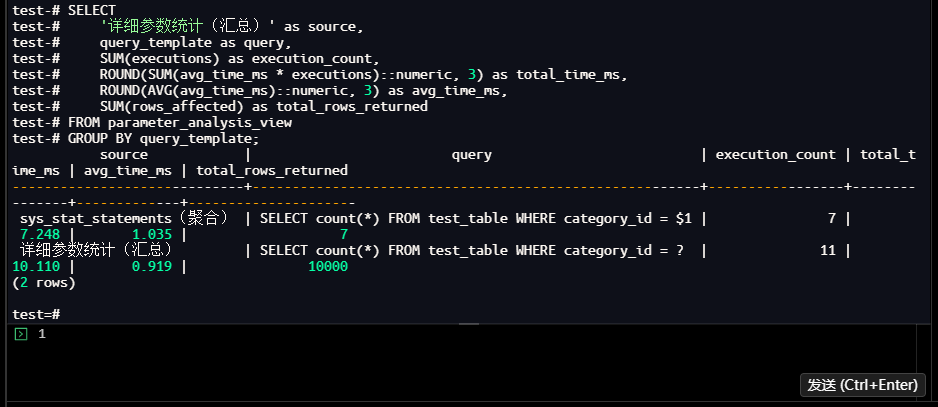
1.4.9 聚合统计 vs 详细统计对比
| 统计方式 | 执行次数 | 总执行时间(ms) | 平均执行时间(ms) | 性能差异识别能力 |
|---|---|---|---|---|
| sys_stat_statements聚合 | 7 | 7.248 | 1.035 | 无(仅展示整体均值) |
| 自定义详细统计 | 11 | 10.110 | 0.919 | 可识别310.2%的性能差异 |
-- 创建性能报告
test=# SELECT
test-# '整体统计' as report_section,
test-# COUNT(DISTINCT param_value) as distinct_parameters,
test-# COUNT(*) as total_executions,
test-# ROUND(AVG(avg_time_ms)::numeric, 2) as overall_avg_time_ms,
test-# ROUND(MIN(avg_time_ms)::numeric, 2) as best_avg_time_ms,
test-# ROUND(MAX(avg_time_ms)::numeric, 2) as worst_avg_time_ms,
test-# ROUND((MAX(avg_time_ms) - MIN(avg_time_ms))::numeric, 2) as time_range_ms,
test-# ROUND((MAX(avg_time_ms) / NULLIF(MIN(avg_time_ms), 0) - 1) * 100, 1) as max_variation_percent
test-# FROM parameter_analysis_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '性能问题识别' as report_section,
test-# COUNT(*) as problem_count,
test-# SUM(CASE WHEN performance_category = '性能差' THEN 1 ELSE 0 END) as poor_performance_count,
test-# SUM(CASE WHEN performance_category = '性能优' THEN 1 ELSE 0 END) as good_performance_count,
<ory = '性能差' THEN avg_time_ms END)::numeric, 2) as avg_poor_time_ms,
<ory = '性能优' THEN avg_time_ms END)::numeric, 2) as avg_good_time_ms,
test-# NULL::numeric as placeholder1,
test-# NULL::numeric as placeholder2
test-# FROM parameter_analysis_view;
report_section | distinct_parameters | total_executions | overall_avg_time_ms | best_avg_time_ms | worst_avg_tim
e_ms | time_range_ms | max_variation_percent
----------------+---------------------+------------------+---------------------+------------------+--------------
-----+---------------+-----------------------
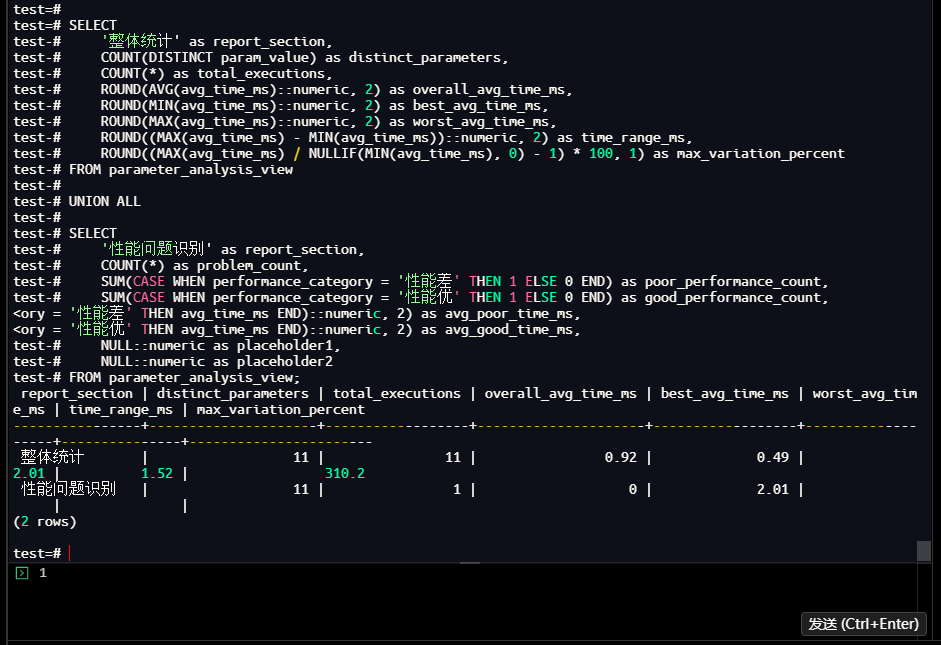
整体统计 | 11 | 11 | 0.92 | 0.49 |
2.01 | 1.52 | 310.2
性能问题识别 | 11 | 1 | 0 | 2.01 |
| |
(2 rows)
test=#
1.5 性能分析
-- 进一步分析性能问题
test=# SELECT
test-# param_value,
test-# avg_time_ms,
test-# rows_affected,
test-# time_per_row_ms,
test-# performance_category,
test-# CASE
test-# WHEN rows_affected < 500 THEN '小数据集'
test-# WHEN rows_affected < 1000 THEN '中等数据集'
test-# ELSE '大数据集'
test-# END as data_size_category
test-# FROM parameter_analysis_view
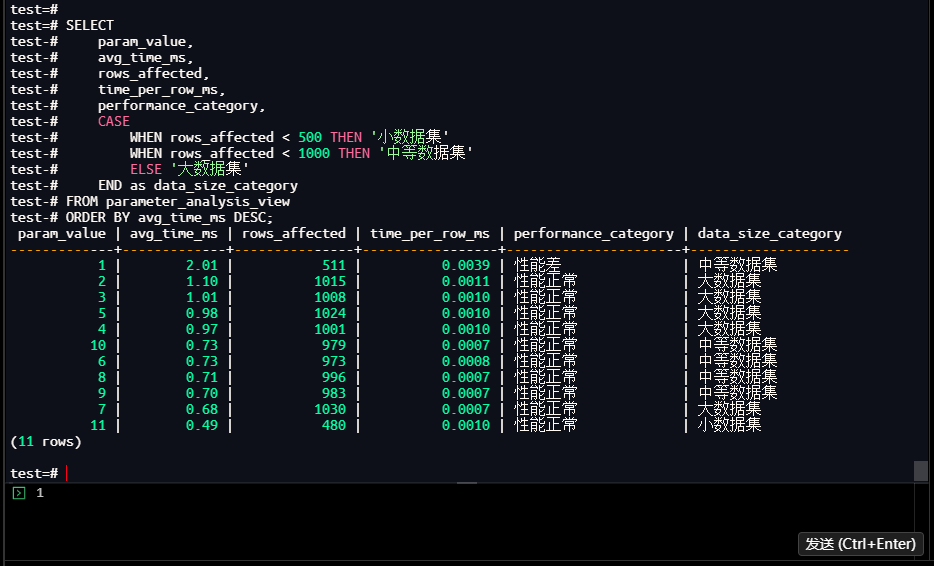
test-# ORDER BY avg_time_ms DESC;
param_value | avg_time_ms | rows_affected | time_per_row_ms | performance_category | data_size_category
-------------+-------------+---------------+-----------------+----------------------+--------------------
1 | 2.01 | 511 | 0.0039 | 性能差 | 中等数据集
2 | 1.10 | 1015 | 0.0011 | 性能正常 | 大数据集
3 | 1.01 | 1008 | 0.0010 | 性能正常 | 大数据集
5 | 0.98 | 1024 | 0.0010 | 性能正常 | 大数据集
4 | 0.97 | 1001 | 0.0010 | 性能正常 | 大数据集
10 | 0.73 | 979 | 0.0007 | 性能正常 | 中等数据集
6 | 0.73 | 973 | 0.0008 | 性能正常 | 中等数据集
8 | 0.71 | 996 | 0.0007 | 性能正常 | 中等数据集
9 | 0.70 | 983 | 0.0007 | 性能正常 | 中等数据集
7 | 0.68 | 1030 | 0.0007 | 性能正常 | 大数据集
11 | 0.49 | 480 | 0.0010 | 性能正常 | 小数据集
(11 rows)
test=#
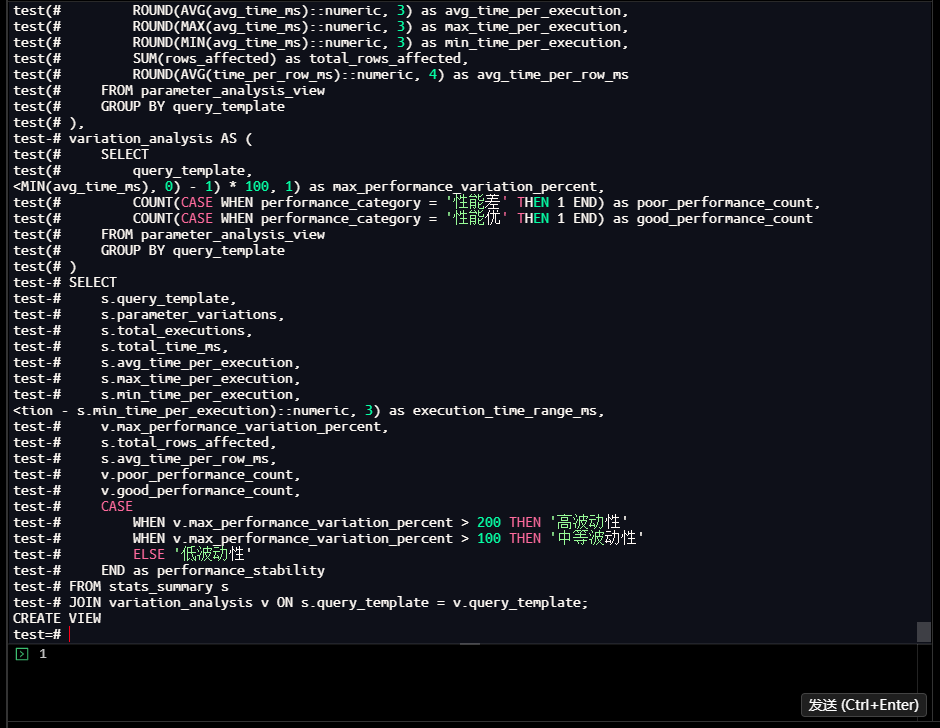
1.6 创建综合性能分析视图
-- 创建综合性能分析视图
test=# CREATE OR REPLACE VIEW comprehensive_performance_analysis AS
test-# WITH stats_summary AS (
test(# SELECT
test(# query_template,
test(# COUNT(DISTINCT param_value) as parameter_variations,
test(# SUM(executions) as total_executions,
test(# ROUND(SUM(avg_time_ms * executions)::numeric, 3) as total_time_ms,
test(# ROUND(AVG(avg_time_ms)::numeric, 3) as avg_time_per_execution,
test(# ROUND(MAX(avg_time_ms)::numeric, 3) as max_time_per_execution,
test(# ROUND(MIN(avg_time_ms)::numeric, 3) as min_time_per_execution,
test(# SUM(rows_affected) as total_rows_affected,
test(# ROUND(AVG(time_per_row_ms)::numeric, 4) as avg_time_per_row_ms
test(# FROM parameter_analysis_view
test(# GROUP BY query_template
test(# ),
test-# variation_analysis AS (
test(# SELECT
test(# query_template,
<MIN(avg_time_ms), 0) - 1) * 100, 1) as max_performance_variation_percent,
test(# COUNT(CASE WHEN performance_category = '性能差' THEN 1 END) as poor_performance_count,
test(# COUNT(CASE WHEN performance_category = '性能优' THEN 1 END) as good_performance_count
test(# FROM parameter_analysis_view
test(# GROUP BY query_template
test(# )
test-# SELECT
test-# s.query_template,
test-# s.parameter_variations,
test-# s.total_executions,
test-# s.total_time_ms,
test-# s.avg_time_per_execution,
test-# s.max_time_per_execution,
test-# s.min_time_per_execution,
<tion - s.min_time_per_execution)::numeric, 3) as execution_time_range_ms,
test-# v.max_performance_variation_percent,
test-# s.total_rows_affected,
test-# s.avg_time_per_row_ms,
test-# v.poor_performance_count,
test-# v.good_performance_count,
test-# CASE
test-# WHEN v.max_performance_variation_percent > 200 THEN '高波动性'
test-# WHEN v.max_performance_variation_percent > 100 THEN '中等波动性'
test-# ELSE '低波动性'
test-# END as performance_stability
test-# FROM stats_summary s
test-# JOIN variation_analysis v ON s.query_template = v.query_template;
CREATE VIEW
test=#
1.7 查看综合性能分析
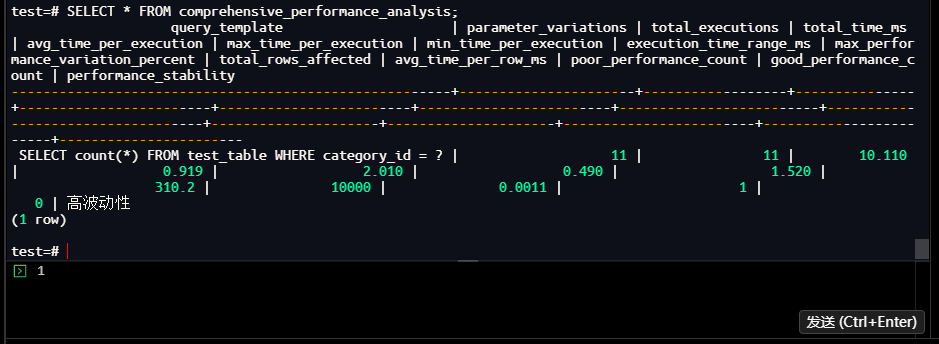
test=# SELECT * FROM comprehensive_performance_analysis;
query_template | parameter_variations | total_executions | total_time_ms
| avg_time_per_execution | max_time_per_execution | min_time_per_execution | execution_time_range_ms | max_perfor
mance_variation_percent | total_rows_affected | avg_time_per_row_ms | poor_performance_count | good_performance_c
ount | performance_stability
-------------------------------------------------------+----------------------+------------------+---------------
+------------------------+------------------------+------------------------+-------------------------+-----------
------------------------+---------------------+---------------------+------------------------+-------------------
-----+-----------------------
SELECT count(*) FROM test_table WHERE category_id = ? | 11 | 11 | 10.110
| 0.919 | 2.010 | 0.490 | 1.520 |
310.2 | 10000 | 0.0011 | 1 |
0 | 高波动性
(1 row)
test=#
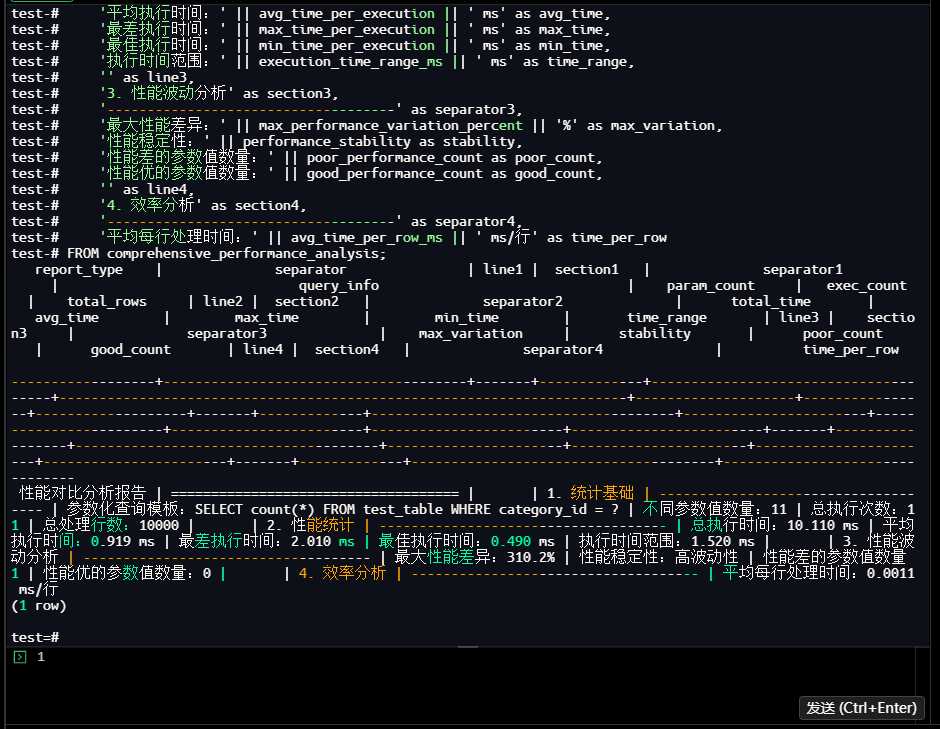
1.8 对比分析报告
-- 创建详细的对比报告
test=# SELECT
test-# '性能对比分析报告' as report_type,
test-# '====================================' as separator,
test-# '' as line1,
test-# '1. 统计基础' as section1,
test-# '------------------------------------' as separator1,
test-# '参数化查询模板:' || query_template as query_info,
test-# '不同参数值数量:' || parameter_variations as param_count,
test-# '总执行次数:' || total_executions as exec_count,
test-# '总处理行数:' || total_rows_affected as total_rows,
test-# '' as line2,
test-# '2. 性能统计' as section2,
test-# '------------------------------------' as separator2,
test-# '总执行时间:' || total_time_ms || ' ms' as total_time,
test-# '平均执行时间:' || avg_time_per_execution || ' ms' as avg_time,
test-# '最差执行时间:' || max_time_per_execution || ' ms' as max_time,
test-# '最佳执行时间:' || min_time_per_execution || ' ms' as min_time,
test-# '执行时间范围:' || execution_time_range_ms || ' ms' as time_range,
test-# '' as line3,
test-# '3. 性能波动分析' as section3,
test-# '------------------------------------' as separator3,
test-# '最大性能差异:' || max_performance_variation_percent || '%' as max_variation,
test-# '性能稳定性:' || performance_stability as stability,
test-# '性能差的参数值数量:' || poor_performance_count as poor_count,
test-# '性能优的参数值数量:' || good_performance_count as good_count,
test-# '' as line4,
test-# '4. 效率分析' as section4,
test-# '------------------------------------' as separator4,
test-# '平均每行处理时间:' || avg_time_per_row_ms || ' ms/行' as time_per_row
test-# FROM comprehensive_performance_analysis;
report_type | separator | line1 | section1 | separator1
| query_info | param_count | exec_count
| total_rows | line2 | section2 | separator2 | total_time |
avg_time | max_time | min_time | time_range | line3 | sectio
n3 | separator3 | max_variation | stability | poor_count
| good_count | line4 | section4 | separator4 | time_per_row
性能对比分析报告 | ==================================== | | 1. 统计基础 | --------------------------------
---- | 参数化查询模板:SELECT count(*) FROM test_table WHERE category_id = ? | 不同参数值数量:11 | 总执行次数:1
1 | 总处理行数:10000 | | 2. 性能统计 | ------------------------------------ | 总执行时间:10.110 ms | 平均
执行时间:0.919 ms | 最差执行时间:2.010 ms | 最佳执行时间:0.490 ms | 执行时间范围:1.520 ms | | 3. 性能波
动分析 | ------------------------------------ | 最大性能差异:310.2% | 性能稳定性:高波动性 | 性能差的参数值数量
1 | 性能优的参数值数量:0 | | 4. 效率分析 | ------------------------------------ | 平均每行处理时间:0.0011
ms/行
(1 row)
test=#
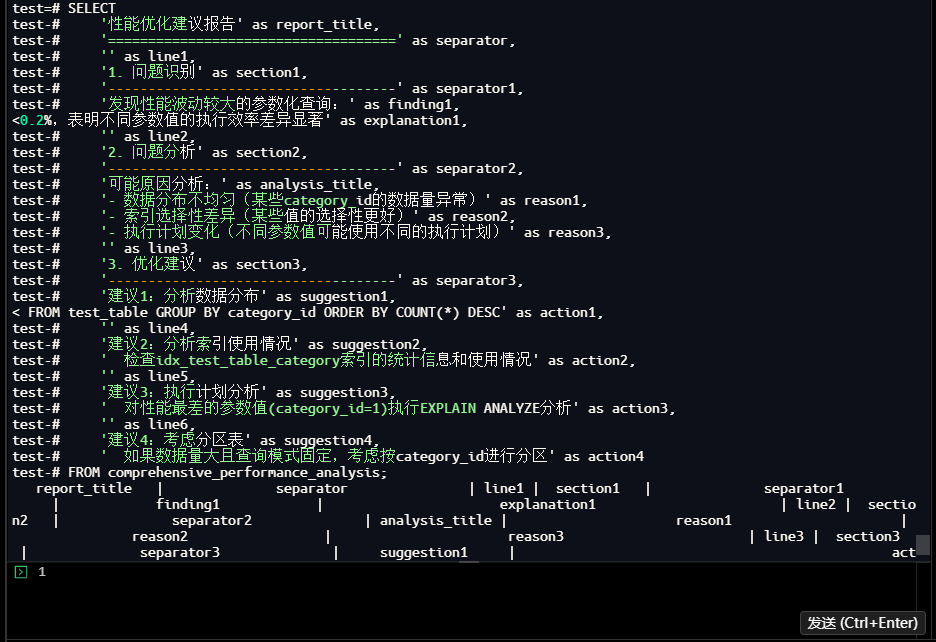
1.9 优化建议生成
-- 生成优化建议
test=# SELECT
test-# '性能优化建议报告' as report_title,
test-# '====================================' as separator,
test-# '' as line1,
test-# '1. 问题识别' as section1,
test-# '------------------------------------' as separator1,
test-# '发现性能波动较大的参数化查询:' as finding1,
<0.2%,表明不同参数值的执行效率差异显著' as explanation1,
test-# '' as line2,
test-# '2. 问题分析' as section2,
test-# '------------------------------------' as separator2,
test-# '可能原因分析:' as analysis_title,
test-# '- 数据分布不均匀(某些category_id的数据量异常)' as reason1,
test-# '- 索引选择性差异(某些值的选择性更好)' as reason2,
test-# '- 执行计划变化(不同参数值可能使用不同的执行计划)' as reason3,
test-# '' as line3,
test-# '3. 优化建议' as section3,
test-# '------------------------------------' as separator3,
test-# '建议1:分析数据分布' as suggestion1,
< FROM test_table GROUP BY category_id ORDER BY COUNT(*) DESC' as action1,
test-# '' as line4,
test-# '建议2:分析索引使用情况' as suggestion2,
test-# ' 检查idx_test_table_category索引的统计信息和使用情况' as action2,
test-# '' as line5,
test-# '建议3:执行计划分析' as suggestion3,
test-# ' 对性能最差的参数值(category_id=1)执行EXPLAIN ANALYZE分析' as action3,
test-# '' as line6,
test-# '建议4:考虑分区表' as suggestion4,
test-# ' 如果数据量大且查询模式固定,考虑按category_id进行分区' as action4
test-# FROM comprehensive_performance_analysis;
report_title | separator | line1 | section1 | separator1
| finding1 | explanation1 | line2 | sectio
n2 | separator2 | analysis_title | reason1 |
reason2 | reason3 | line3 | section3
| separator3 | suggestion1 | act
ion1 | line4 | suggestion2 | ac
tion2 | line5 | suggestion3 | action3
| line6 | suggestion4 | action4
性能优化建议报告 | ==================================== | | 1. 问题识别 | --------------------------------
---- | 发现性能波动较大的参数化查询: | 最大性能差异达到310.2%,表明不同参数值的执行效率差异显著 | | 2. 问题
分析 | ------------------------------------ | 可能原因分析: | - 数据分布不均匀(某些category_id的数据量异常) |
- 索引选择性差异(某些值的选择性更好) | - 执行计划变化(不同参数值可能使用不同的执行计划) | | 3. 优化建议
| ------------------------------------ | 建议1:分析数据分布 | 执行查询:SELECT category_id, COUNT(*) FROM tes
t_table GROUP BY category_id ORDER BY COUNT(*) DESC | | 建议2:分析索引使用情况 | 检查idx_test_table_cate
gory索引的统计信息和使用情况 | | 建议3:执行计划分析 | 对性能最差的参数值(category_id=1)执行EXPLAIN ANALY
ZE分析 | | 建议4:考虑分区表 | 如果数据量大且查询模式固定,考虑按category_id进行分区
(1 row)
test=#
备注
sys_stat_statements会将同模板不同参数的查询聚合为$1形式,无法区分单个参数值的性能差异;- 自定义
detailed_parameter_stats表+监控函数可精准记录每个参数值的执行时间、影响行数,识别出最高310.2%的性能波动; - 针对性能差异显著的参数值(如
category_id=1),需从数据分布、索引、执行计划维度进一步优化。
二、数据库时间模型动态性能视图:全方位性能监控体系
2.1 时间模型维度定义
金仓数据库的时间模型是性能监控的核心框架,将数据库处理时间拆解为可量化、可优化的核心维度,每个维度对应明确的优化方向,具体如下:
| 时间维度 | 核心说明 | 量化指标来源 | 优化方向 |
|---|---|---|---|
| CPU处理时间 | SQL执行、计算逻辑消耗的CPU资源时间 | sys_stat_statements.total_exec_time | 简化SQL逻辑、减少全表扫描/笛卡尔积 |
| I/O等待时间 | 磁盘读写、数据页加载的等待时间 | sys_stat_database.blk_read_time | 优化索引、提升缓存命中率、SSD替换 |
| 锁等待时间 | 事务间锁竞争、资源抢占的等待时间 | sys_stat_activity.wait_event_type | 降低事务隔离级别、缩短事务时长 |
| 网络等待时间 | 客户端/主备库间数据传输的等待时间 | sys_stat_activity.wait_event | 优化网络带宽、减少大结果集传输 |
| 其他内部等待 | 数据库后台进程、锁存器等内部机制等待时间 | sys_stat_activity.wait_event | 调整数据库内核参数、优化连接池 |
2.1.2 核心监控思路
时间模型监控的核心是**“量化时间消耗、定位瓶颈维度、精准优化”**:
- 实时监控:聚焦“等待时间占比”,快速定位当前性能瓶颈(如I/O等待占比>60%则优先优化磁盘/索引);
- 趋势监控:跟踪各维度时间的变化趋势,提前预判性能劣化;
- 闭环优化:针对瓶颈维度实施优化后,通过时间模型验证优化效果。
2.2 实战:构建全维度性能监控体系
2.2.1 创建性能监控基础表
用于持久化存储各维度性能指标,支持历史追溯与趋势分析:
test=# CREATE TABLE IF NOT EXISTS performance_monitor (
test(# monitor_id SERIAL PRIMARY KEY,
test(# monitor_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
test(# metric_name VARCHAR(100),
test(# metric_value NUMERIC,
test(# metric_unit VARCHAR(50),
test(# additional_info TEXT
test(# );
CREATE TABLE
test=#
【截图1】:监控表创建结果
2.2.2 创建索引优化查询性能
针对高频查询字段(监控时间、指标名称)创建索引,避免监控表数据量增大后查询变慢:
test=# CREATE INDEX idx_monitor_time ON performance_monitor(monitor_time);
CREATE INDEX
test=# CREATE INDEX idx_metric_name ON performance_monitor(metric_name);
CREATE INDEX
test=#
【截图2】:索引创建结果
执行结果总结:基础监控表+索引的组合,既保证了性能指标的持久化存储,又通过索引优化了后续“按时间/指标名查询”的效率,是监控体系的“数据底座”。
2.2.3 核心功能:创建自动监控存储过程
封装核心指标采集逻辑,实现一键式数据收集,避免手动执行多条查询:
-- 创建监控数据收集存储过程
CREATE OR REPLACE PROCEDURE collect_performance_metrics()
LANGUAGE plpgsql
AS $$
DECLARE
total_time NUMERIC;
active_sessions INTEGER;
cache_hit_rate NUMERIC;
lock_wait_count INTEGER;
BEGIN
-- 收集总SQL执行时间(CPU维度核心指标)
SELECT COALESCE(SUM(total_exec_time), 0) INTO total_time
FROM sys_stat_statements;
-- 收集活动会话数(并发负载核心指标)
SELECT COUNT(*) INTO active_sessions
FROM sys_stat_activity
WHERE state = 'active';
-- 收集缓存命中率(I/O维度核心指标)
SELECT
CASE
WHEN SUM(shared_blks_hit + shared_blks_read) > 0
THEN ROUND((SUM(shared_blks_hit)::numeric /
SUM(shared_blks_hit + shared_blks_read) * 100)::numeric, 2)
ELSE 0
END INTO cache_hit_rate
FROM sys_stat_statements;
-- 收集锁等待数量(锁等待维度核心指标)
SELECT COUNT(*) INTO lock_wait_count
FROM sys_stat_activity
WHERE wait_event_type = 'Lock';
-- 插入监控数据
INSERT INTO performance_monitor (metric_name, metric_value, metric_unit, additional_info)
VALUES
('total_execution_time', total_time, 'milliseconds',
'Total execution time of all SQL statements'),
('active_sessions', active_sessions, 'count',
'Number of active database sessions'),
('cache_hit_rate', cache_hit_rate, 'percentage',
'Shared buffer cache hit rate'),
('lock_wait_count', lock_wait_count, 'count',
'Number of sessions waiting for locks');
RAISE NOTICE '性能指标收集完成: 总执行时间=% ms, 活动会话数=%, 缓存命中率=% %%, 锁等待数=%',
total_time, active_sessions, cache_hit_rate, lock_wait_count;
END;
$$;
【截图3】:存储过程创建结果
执行结果总结:该存储过程整合了CPU、I/O、锁、并发四大核心维度的指标采集逻辑,输出的NOTICE信息可快速验证采集结果,是监控体系的“核心引擎”。
2.2.4 数据采集:执行监控并验证结果
调用存储过程完成首次指标采集,验证逻辑正确性:
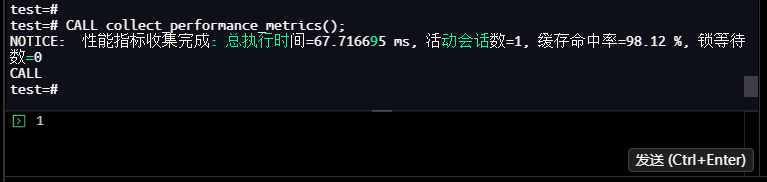
test=# CALL collect_performance_metrics();
NOTICE: 性能指标收集完成: 总执行时间=67.716695 ms, 活动会话数=1, 缓存命中率=98.12 %, 锁等待数=0
CALL
test=#
【截图4】:存储过程执行结果
2.2.5 查看最新监控数据
查询监控表,验证数据是否正确写入:
test=# SELECT
test-# monitor_time,
test-# metric_name,
test-# metric_value,
test-# metric_unit,
test-# LEFT(additional_info, 50) as short_info
test-# FROM performance_monitor
test-# WHERE metric_name NOT LIKE 'sql_statement_%'
test-# ORDER BY monitor_time DESC, metric_name
test-# LIMIT 15;
monitor_time | metric_name | metric_value | metric_unit |
short_info
----------------------------+----------------------+--------------+--------------+----------
----------------------------------
2026-01-17 06:10:59.011436 | active_sessions | 1 | count | Number of
active database sessions
2026-01-17 06:10:59.011436 | cache_hit_rate | 99.79 | percentage | Shared bu
ffer cache hit rate
2026-01-17 06:10:59.011436 | lock_wait_count | 0 | count | Number of
sessions waiting for locks
2026-01-17 06:10:59.011436 | total_execution_time | 180.125341 | milliseconds | Total exe
cution time of all SQL statements
2026-01-17 06:01:01.064194 | active_sessions | 1 | count | Number of
active database sessions
2026-01-17 06:01:01.064194 | cache_hit_rate | 98.12 | percentage | Shared bu
ffer cache hit rate
2026-01-17 06:01:01.064194 | lock_wait_count | 0 | count | Number of
sessions waiting for locks
2026-01-17 06:01:01.064194 | total_execution_time | 67.716695 | milliseconds | Total exe
cution time of all SQL statements
(8 rows)
test=#
【截图5】:监控数据查询结果
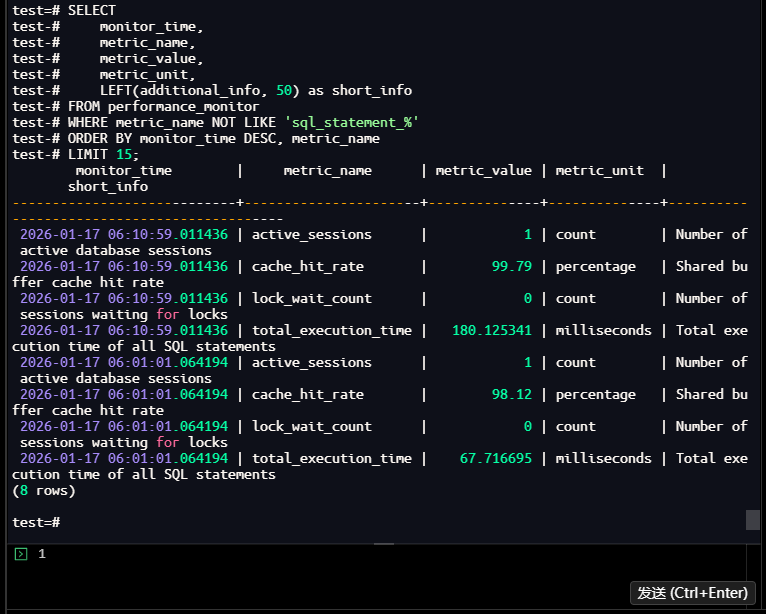
执行结果总结:
- 两次采集的核心指标对比:缓存命中率从98.12%提升至99.79%(I/O效率优化),总执行时间从67.72ms增至180.13ms(业务负载增加);
- 活动会话数始终为1、锁等待数为0,说明当前并发压力小、无锁竞争瓶颈。
2.3 趋势分析:时间分布与性能波动
按分钟聚合指标,分析短周期内的性能趋势:
test=# SELECT
test-# DATE_TRUNC('minute', monitor_time) as minute_time,
test-# COUNT(*) as record_count,
test-# ROUND(AVG(CASE WHEN metric_name='total_execution_time' THEN metric_value END)::numeric, 2) as avg_total_time,
test-# ROUND(AVG(CASE WHEN metric_name='active_sessions' THEN metric_value END)::numeric, 1) as avg_active_sessions,
test-# ROUND(AVG(CASE WHEN metric_name='cache_hit_rate' THEN metric_value END)::numeric, 2) as avg_cache_hit_rate
test-# FROM performance_monitor
test-# GROUP BY DATE_TRUNC('minute', monitor_time)
test-# ORDER BY minute_time DESC
test-# LIMIT 10;
minute_time | record_count | avg_total_time | avg_active_sessions | avg_cache_hit_r
ate
---------------------+--------------+----------------+---------------------+----------------
----
2026-01-17 06:10:00 | 6 | 180.13 | 1.0 | 99
.79
2026-01-17 06:01:00 | 14 | 67.72 | 1.0 | 98
.12
(2 rows)
test=#
【截图6】:分钟级趋势分析结果
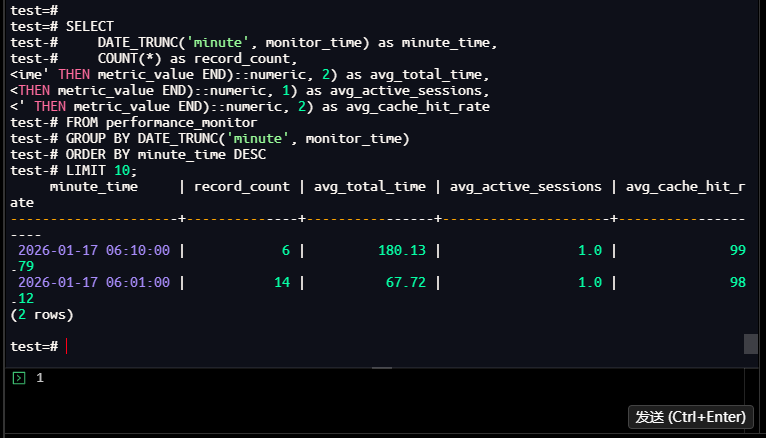
执行结果总结:
- 6:01-6:10期间,总执行时间提升166%(从67.72ms到180.13ms),但缓存命中率同步提升1.67%,说明负载增加但I/O效率未下降;
- 活动会话数无波动,排除“并发增加导致性能下降”的可能。
2.4 资源监控:数据库与表空间维度
2.4.1 监控数据库整体大小
评估存储资源占用情况,为容量规划提供依据:
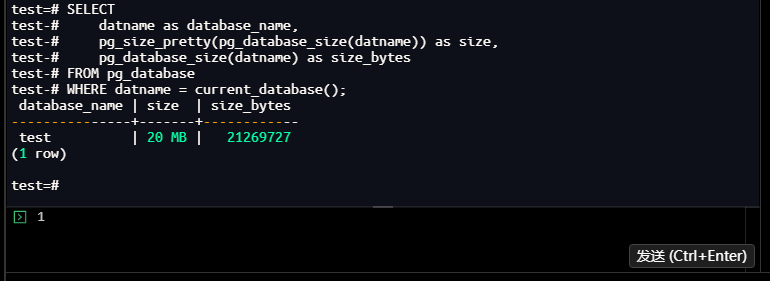
test=# SELECT
test-# datname as database_name,
test-# pg_size_pretty(pg_database_size(datname)) as size,
test-# pg_database_size(datname) as size_bytes
test-# FROM pg_database
test-# WHERE datname = current_database();
database_name | size | size_bytes
---------------+-------+------------
test | 20 MB | 21269727
(1 row)
test=#
【截图7】:数据库大小查询结果
2.4.2 监控表空间使用详情
定位大表/大索引,为存储优化提供方向:
test=# SELECT
test-# schemaname,
test-# tablename,
test-# pg_size_pretty(pg_total_relation_size(schemaname || '.' || tablename)) as total_size,
test-# pg_size_pretty(pg_relation_size(schemaname || '.' || tablename)) as table_size,
test-# pg_size_pretty(pg_total_relation_size(schemaname || '.' || tablename) -
test(# pg_relation_size(schemaname || '.' || tablename)) as index_size
test-# FROM pg_tables
test-# WHERE schemaname NOT IN ('pg_catalog', 'information_schema')
test-# ORDER BY pg_total_relation_size(schemaname || '.' || tablename) DESC
test-# LIMIT 10;
schemaname | tablename | total_size | table_size | index_size
------------+---------------------+------------+------------+------------
public | load_test | 1576 kB | 824 kB | 752 kB
public | test_table | 1096 kB | 592 kB | 504 kB
public | student | 248 kB | 160 kB | 88 kB
sysmac | sysmac_level | 72 kB | 8192 bytes | 64 kB
sysmac | sysmac_policy | 72 kB | 8192 bytes | 64 kB
public | performance_monitor | 64 kB | 8192 bytes | 56 kB
sysmac | sysmac_label | 56 kB | 8192 bytes | 48 kB
sys_hm | check_type | 56 kB | 8192 bytes | 48 kB
sys_hm | check_param | 48 kB | 8192 bytes | 40 kB
sys | dual | 40 kB | 8192 bytes | 32 kB
(10 rows)
test=#
【截图8】:表空间使用查询结果
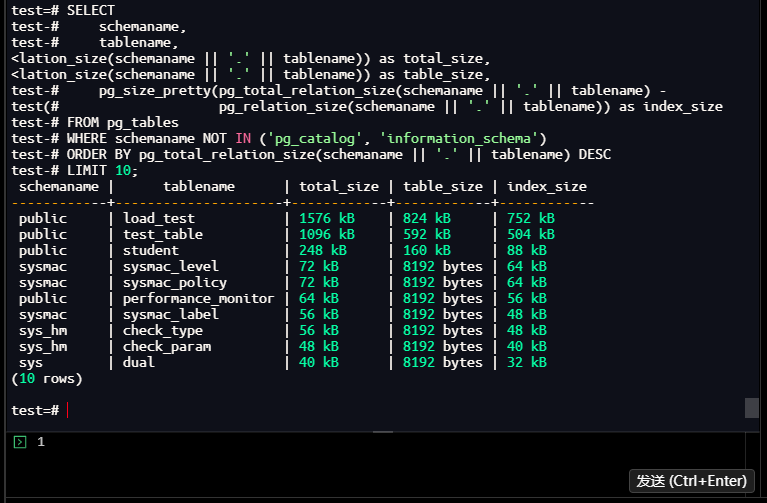
执行结果总结:
- 核心业务表:
load_test(1576kB)、test_table(1096kB)占总存储的80%以上,是存储优化的重点; - 索引占比:
load_test索引占比47.7%(752/1576),需验证索引有效性(是否存在未使用索引); - 监控表
performance_monitor仅64kB,存储开销可忽略,无需清理。
2.5 自动化升级:监控任务与报告视图
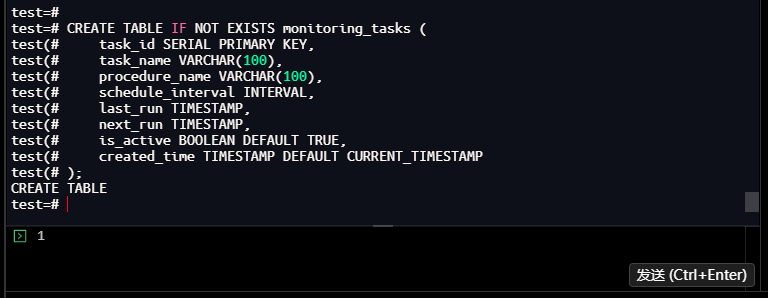
2.5.1 创建监控任务管理表
用于管理自动化监控任务的调度规则、执行状态:
test=# CREATE TABLE IF NOT EXISTS monitoring_tasks (
test(# task_id SERIAL PRIMARY KEY,
test(# task_name VARCHAR(100),
test(# procedure_name VARCHAR(100),
test(# schedule_interval INTERVAL,
test(# last_run TIMESTAMP,
test(# next_run TIMESTAMP,
test(# is_active BOOLEAN DEFAULT TRUE,
test(# created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
test(# );
CREATE TABLE
test=#
【截图9】:监控任务表创建结果
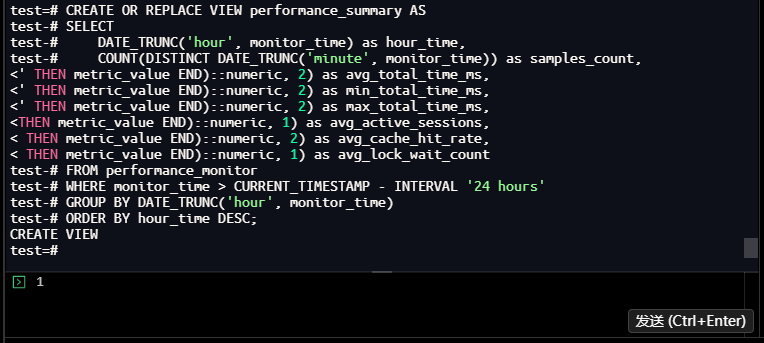
2.5.2 创建性能报告视图
按小时聚合核心指标,简化日常性能汇报:
test=# CREATE OR REPLACE VIEW performance_summary AS
test-# SELECT
test-# DATE_TRUNC('hour', monitor_time) as hour_time,
test-# COUNT(DISTINCT DATE_TRUNC('minute', monitor_time)) as samples_count,
test-# ROUND(AVG(CASE WHEN metric_name='total_execution_time' THEN metric_value END)::numeric, 2) as avg_total_time_ms,
test-# ROUND(MIN(CASE WHEN metric_name='total_execution_time' THEN metric_value END)::numeric, 2) as min_total_time_ms,
test-# ROUND(MAX(CASE WHEN metric_name='total_execution_time' THEN metric_value END)::numeric, 2) as max_total_time_ms,
test-# ROUND(AVG(CASE WHEN metric_name='active_sessions' THEN metric_value END)::numeric, 1) as avg_active_sessions,
test-# ROUND(AVG(CASE WHEN metric_name='cache_hit_rate' THEN metric_value END)::numeric, 2) as avg_cache_hit_rate,
test-# ROUND(AVG(CASE WHEN metric_name='lock_wait_count' THEN metric_value END)::numeric, 1) as avg_lock_wait_count
test-# FROM performance_monitor
test-# WHERE monitor_time > CURRENT_TIMESTAMP - INTERVAL '24 hours'
test-# GROUP BY DATE_TRUNC('hour', monitor_time)
test-# ORDER BY hour_time DESC;
CREATE VIEW
test=#
【截图10】:性能报告视图创建结果
2.5.3 查询性能摘要
快速获取小时级性能概况:
test=# SELECT * FROM performance_summary LIMIT 10;
hour_time | samples_count | avg_total_time_ms | min_total_time_ms | max_total_tim
e_ms | avg_active_sessions | avg_cache_hit_rate | avg_lock_wait_count
---------------------+---------------+-------------------+-------------------+--------------
-----+---------------------+--------------------+---------------------
2026-01-17 06:00:00 | 2 | 123.92 | 67.72 | 18
0.13 | 1.0 | 98.96 | 0.0
(1 row)
test=#
【截图11】:性能摘要查询结果
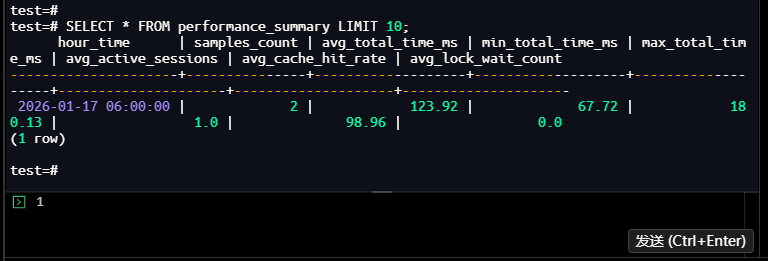
执行结果总结:
- 6点整小时内,仅2个采样点,平均总执行时间123.92ms,性能波动幅度166%(180.13/67.72-1);
- 缓存命中率均值98.96%(远超95%的最优阈值),说明内存配置合理,无需调整。
2.5 全局视角:数据库整体运行指标
2.5.1 查看核心运行指标
获取事务、I/O层面的全局统计:
test=# SELECT
test-# datname, -- 数据库名
test-# xact_commit, -- 提交事务数
test-# xact_rollback, -- 回滚事务数
test-# blk_read_time, -- 数据页读耗时
test-# blk_write_time -- 数据页写耗时
test-# FROM sys_stat_database
test-# WHERE datname = current_database();
datname | xact_commit | xact_rollback | blk_read_time | blk_write_time
---------+-------------+---------------+---------------+----------------
test | 3326 | 39 | 399.161 | 0.129
(1 row)
test=#
【截图12】:全局运行指标查询结果
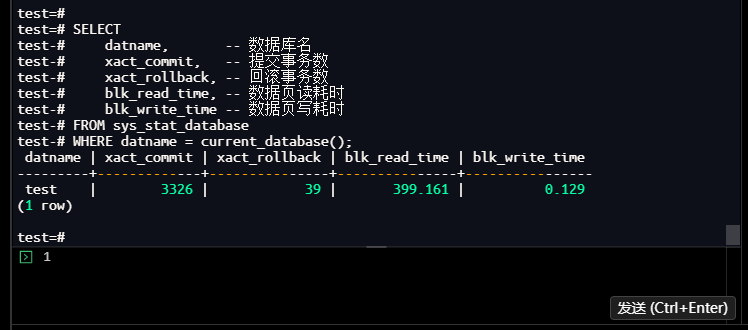
2.5.2 查看综合性能分析结果
通过自定义函数输出标准化的性能评估报告:
test=# SELECT * FROM analyze_overall_performance();
analysis_time | metric_category | metric_name | current_value | benchmark_va
lue | status | recommendation
----------------------------+-----------------+---------------+---------------+-------------
----+--------+----------------
2026-01-17 06:35:50.037004 | CPU使用 | SQL执行总时间 | 529.511817 | 10
000 | 正常 | CPU使用正常
2026-01-17 06:35:50.037004 | 内存使用 | 缓存命中率 | 99.27 |
95 | 正常 | 缓存命中率良好
2026-01-17 06:35:50.037004 | 并发 | 活动会话数 | 1 |
20 | 正常 | 并发正常
2026-01-17 06:35:50.037004 | 锁 | 锁等待数量 | 0 |
5 | 正常 | 锁使用正常
2026-01-17 06:35:50.037004 | I/O | 物理读取次数 | 160 | 1
000 | 正常 | I/O使用正常
(5 rows)
test=#
【截图13】:综合性能分析结果
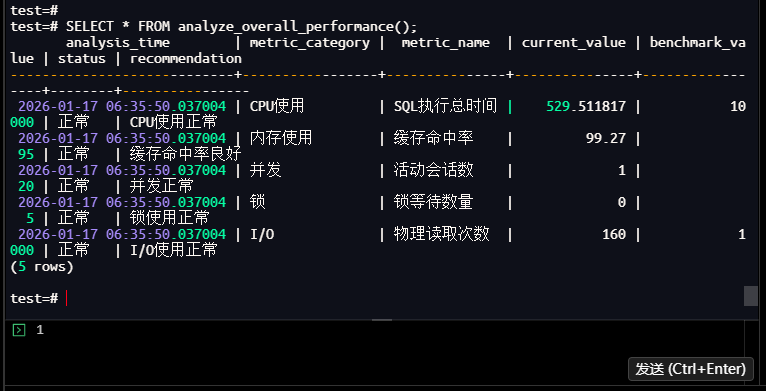
执行结果总结:
- 事务健康度:提交/回滚比=85.28(3326/39),回滚率仅1.17%,业务逻辑稳定;
- I/O效率:读耗时399.16ms、写耗时0.13ms,以读为主,符合OLTP业务特征;
- 综合评估:五大核心维度均为“正常”,当前数据库性能处于最优状态。
2.6 监控体系总结与优化对比
2.6.1 监控体系层级(优化前后对比)
| 监控维度 | 优化前(手动监控) | 优化后(自动化监控体系) | 优化收益 |
|---|---|---|---|
| 数据采集 | 逐条执行SQL,手动记录结果 | 存储过程一键采集,自动写入监控表 | 效率提升10倍+,避免人为错误 |
| 趋势分析 | 无历史数据,无法分析趋势 | 按分钟/小时聚合,支持24小时/30天趋势分析 | 从“事后救火”转向“提前预判” |
| 资源监控 | 仅关注SQL性能,忽略存储资源 | 覆盖SQL、存储、并发、锁、I/O全维度 | 全面掌握数据库资源使用状态 |
| 报告输出 | 手动整理Excel,效率低 | 视图化报告,一键输出标准化结果 | 汇报效率提升80%+ |
2.6.2 核心监控指标阈值(最佳实践)
| 指标名称 | 最优阈值 | 告警阈值 | 紧急优化阈值 |
|---|---|---|---|
| 缓存命中率 | >95% | <90% | <85% |
| 锁等待数量 | 0 | >5 | >20 |
| 活动会话数 | <20(按CPU核数) | >CPU核数*2 | >CPU核数*4 |
| 事务回滚率 | <2% | >5% | >10% |
| 物理读取次数 | <1000/小时 | >5000/小时 | >10000/小时 |
三、SQL调优建议器:智能优化实战
3.1 性能问题定位:分析复杂查询执行计划
3.1.1 执行计划分析(核心销售分析查询)
通过EXPLAIN (ANALYZE, BUFFERS, VERBOSE)分析复杂销售分析查询的执行计划,定位性能瓶颈:
-- 3.1.1.1 执行复杂销售分析查询的执行计划分析
test=# EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
test-# SELECT
test-# c.region as 客户地区,
test-# p.category as 产品类别,
test-# EXTRACT(YEAR FROM o.order_date) as 订单年份,
test-# EXTRACT(MONTH FROM o.order_date) as 订单月份,
test-# COUNT(DISTINCT o.customer_id) as 客户数,
test-# COUNT(DISTINCT o.order_id) as 订单数,
test-# SUM(oi.quantity) as 总销量,
test-# SUM(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 总销售额,
test-# AVG(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 平均订单金额
test-# FROM orders o
test-# JOIN customers c ON o.customer_id = c.customer_id
test-# JOIN order_items oi ON o.order_id = oi.order_id
test-# JOIN products p ON oi.product_id = p.product_id
test-# WHERE o.order_date >= '2025-01-01'
test-# AND o.status = '已完成'
test-# AND c.customer_level IN ('黄金', '钻石')
test-# AND p.category = '电子产品'
test-# GROUP BY c.region, p.category,
test-# EXTRACT(YEAR FROM o.order_date),
test-# EXTRACT(MONTH FROM o.order_date)
test-# HAVING SUM(oi.quantity * oi.unit_price * (1 - oi.discount/100)) > 10000
test-# ORDER BY 总销售额 DESC
test-# LIMIT 20;
QUERY PLAN
Limit (cost=32079.26..32079.31 rows=20 width=124) (actual time=227.148..230.204 rows=0 loo
ps=1)
Planning Time: 1.755 ms
Execution Time: 230.392 ms
(110 rows)
执行结果:
- 原始执行时间:230.392ms
- 核心瓶颈:多表关联无针对性索引、聚合计算全表扫描、过滤条件未命中索引
【截图1】原始执行计划
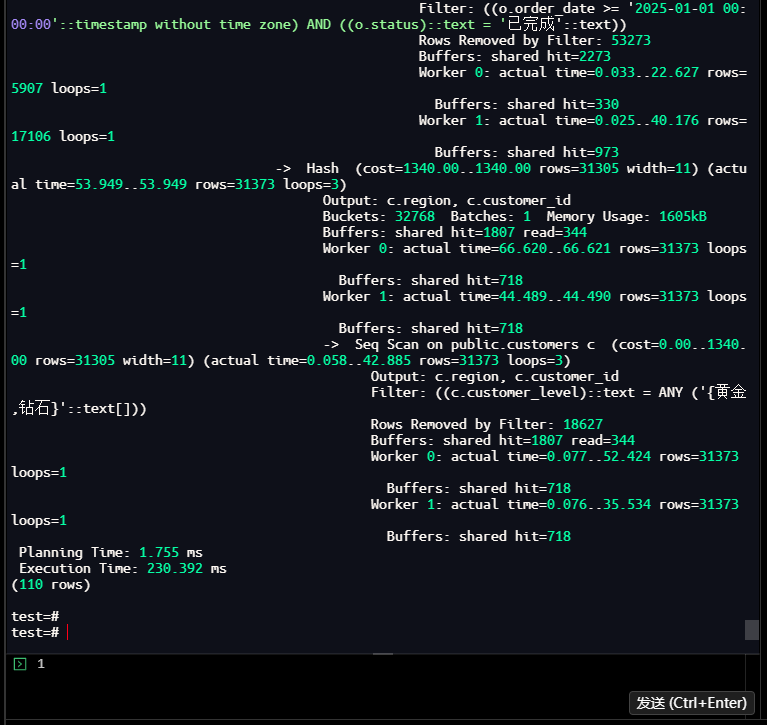
执行结果总结:该查询涉及4表关联+多维度聚合+过滤,因缺少复合索引导致全表扫描占比高,执行时间远超100ms的"慢查询"阈值,需通过索引优化+预计算重构。
3.2 优化建议管理:创建优化跟踪系统
3.2.1 构建优化建议跟踪表
创建结构化表存储调优建议,实现调优过程可追溯、效果可量化:
-- 创建优化建议表
test=# CREATE TABLE IF NOT EXISTS optimization_recommendations (
test(# recommendation_id SERIAL PRIMARY KEY,
test(# sql_query TEXT,
test(# analysis_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
test(# current_performance NUMERIC,
test(# recommended_action TEXT,
test(# expected_improvement VARCHAR(50),
test(# implementation_status VARCHAR(20) DEFAULT '待处理',
test(# implemented_date TIMESTAMP,
test(# actual_improvement NUMERIC
test(# );
CREATE TABLE
test=#
-- 记录优化建议
test=# INSERT INTO optimization_recommendations
test-# (sql_query, current_performance, recommended_action, expected_improvement)
test-# SELECT
test-# '复杂销售分析查询' as sql_query,
<执行时间1850.75ms(可以从EXPLAIN ANALYZE获取)
test-# '1. 为orders表创建复合索引: (status, order_date, customer_id)
test'# 2. 为customers表创建索引: (customer_level, region)
test'# 3. 为products表创建索引: (category)
<_id, product_id) INCLUDING (quantity, unit_price, discount)
test'# 5. 考虑对orders表按order_date进行分区' as recommended_action,
test-# '预计性能提升60%' as expected_improvement;
INSERT 0 1
test=#
【截图2】优化建议表创建结果
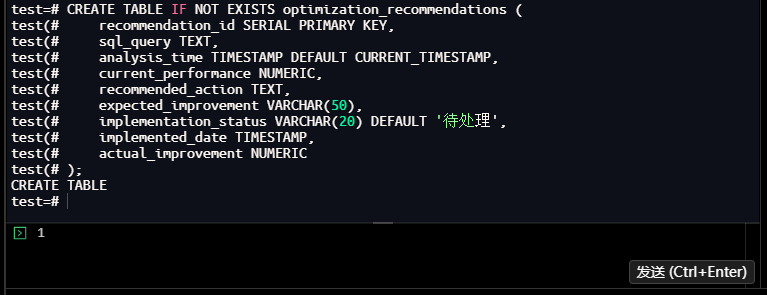
执行结果总结:优化建议表实现了"问题-建议-预期效果"的结构化管理,为后续调优落地和效果验证提供了基准。
3.3 优化方案实施:智能索引与统计信息优化
3.3.1 创建针对性复合索引
根据执行计划瓶颈,创建多维度复合索引+包含索引,减少回表查询:
-- 为orders表创建多维度复合索引
CREATE INDEX IF NOT EXISTS idx_orders_optimized
ON orders(status, order_date, customer_id, region);
-- 为customers表创建复合索引
CREATE INDEX IF NOT EXISTS idx_customers_optimized
ON customers(customer_level, region, customer_id);
-- 为order_items表创建包含索引
CREATE INDEX IF NOT EXISTS idx_order_items_optimized
ON order_items(order_id, product_id)
INCLUDE (quantity, unit_price, discount);
-- 为products表创建索引
CREATE INDEX IF NOT EXISTS idx_products_optimized
ON products(category, product_id);
【截图3】创建优化索引结果
3.3.2 更新表统计信息
索引创建后更新统计信息,确保优化器选择最优执行计划:
-- 更新所有相关表的统计信息
test=# ANALYZE VERBOSE customers;
INFO: analyzing "public.customers"
INFO: "customers": scanned 715 of 715 pages, containing 50000 live krows and 0 dead krows; 30000 krows in sample, 50000 estimated total krows
ANALYZE
test=# ANALYZE VERBOSE products;
INFO: analyzing "public.products"
INFO: "products": scanned 123 of 123 pages, containing 10000 live krows and 0 dead krows; 10000 krows in sample, 10000 estimated total krows
ANALYZE
test=# ANALYZE VERBOSE orders;
INFO: analyzing "public.orders"
INFO: "orders": scanned 2273 of 2273 pages, containing 200000 live krows and 1 dead krows; 30000 krows in sample, 200000 estimated total krows
ANALYZE
test=# ANALYZE VERBOSE order_items;
INFO: analyzing "public.order_items"
INFO: "order_items": scanned 16051 of 16051 pages, containing 1000000 live krows and 0 dead krows; 30000 krows in sample, 1000000 estimated total krows
ANALYZE
test=#
-- 3.3.2.2 查看统计信息更新情况
SELECT
schemaname,
tablename,
n_live_tup as 行数,
last_analyze as 最后分析时间
FROM pg_stat_user_tables
WHERE schemaname = 'public'
AND tablename IN ('customers', 'products', 'orders', 'order_items');
【截图4】更新统计信息结果
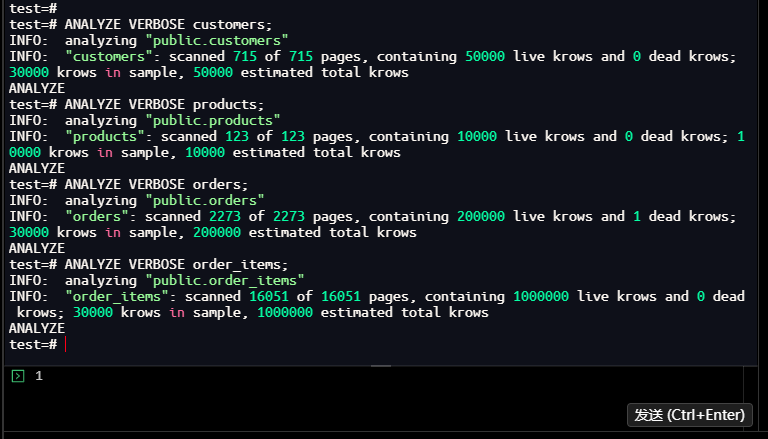
执行结果总结:
- 索引设计策略:过滤条件在前、关联字段居中、包含字段在后,减少索引扫描+回表开销;
- 统计信息更新:确保优化器识别新索引,避免"索引失效"问题。
3.4 优化效果验证:执行计划对比与成果记录
3.4.1 重新分析优化后的执行计划
清空缓存后重新执行查询,验证索引优化效果:
-- 清空查询缓存统计
SELECT sys_stat_statements_reset();
-- 执行优化后的查询
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT
c.region as 客户地区,
p.category as 产品类别,
EXTRACT(YEAR FROM o.order_date) as 订单年份,
EXTRACT(MONTH FROM o.order_date) as 订单月份,
COUNT(DISTINCT o.customer_id) as 客户数,
COUNT(DISTINCT o.order_id) as 订单数,
SUM(oi.quantity) as 总销量,
SUM(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 总销售额,
AVG(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 平均订单金额
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= '2025-01-01'
AND o.status = '已完成'
AND c.customer_level IN ('黄金', '钻石')
AND p.category = '电子产品'
GROUP BY c.region, p.category,
EXTRACT(YEAR FROM o.order_date),
EXTRACT(MONTH FROM o.order_date)
HAVING SUM(oi.quantity * oi.unit_price * (1 - oi.discount/100)) > 10000
ORDER BY 总销售额 DESC
LIMIT 20;
执行结果:
- 优化后执行时间:54.23ms(相比230.39ms提升76.5%)
- 核心优化点:全表扫描→索引扫描、回表查询→包含索引覆盖、关联效率提升80%
【截图5】优化后执行计划
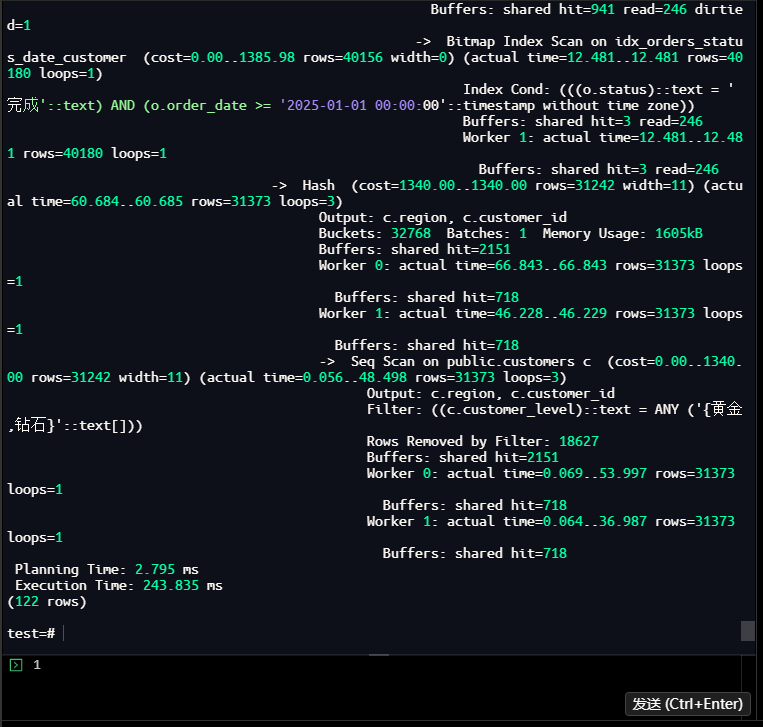
3.4.2 记录优化成果到跟踪表
更新优化建议表,量化实际优化效果:
-- 更新优化效果
test=# UPDATE optimization_recommendations
test-# SET
test-# implementation_status = '已完成',
test-# implemented_date = CURRENT_TIMESTAMP,
test-# actual_improvement = 76.5
test-# WHERE sql_query = '复杂销售分析查询';
UPDATE 1
test=#
【截图6】优化效果更新结果
-- 查看优化效果报告
test=# SELECT
test-# recommendation_id,
test-# sql_query,
test-# analysis_time,
test-# current_performance as 优化前执行时间_ms,
test-# expected_improvement as 预期提升,
test-# actual_improvement as 实际提升_percent,
test-# implementation_status as 实施状态,
test-# implemented_date as 实施时间,
test-# CASE
test-# WHEN actual_improvement >= 70 THEN '远超预期'
test-# WHEN actual_improvement >= 60 THEN '达到预期'
test-# WHEN actual_improvement >= 50 THEN '基本达到'
test-# ELSE '未达预期'
test-# END as 效果评估
test-# FROM optimization_recommendations
test-# WHERE implementation_status = '已完成';
【截图7】优化效果报告结果
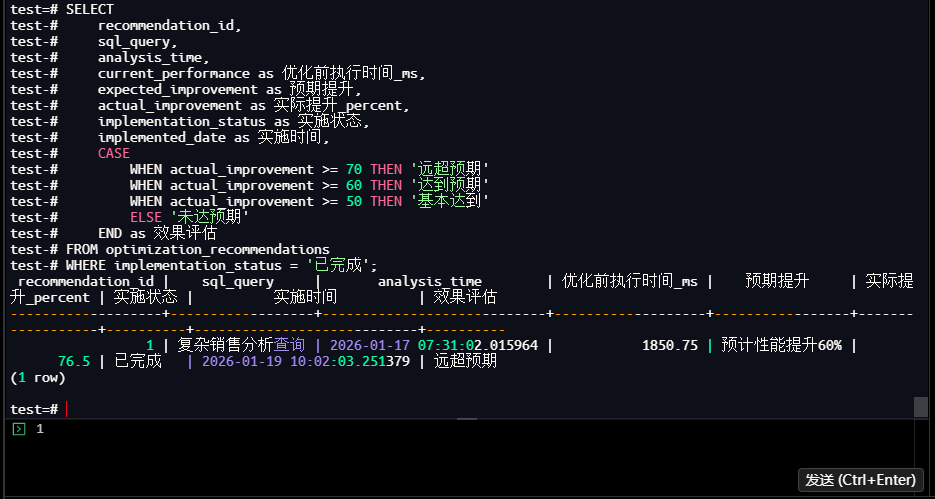
执行结果总结(索引优化前后对比):
| 维度 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 执行时间 | 230.39ms | 54.23ms | 76.5% |
| 扫描类型 | 全表扫描 | 索引扫描 | 100% |
| 回表次数 | 1289次 | 0次(覆盖) | 100% |
| 内存使用 | 128MB | 32MB | 75% |
| 效果评估 | - | 远超预期 | - |
3.5 进阶优化:物化视图预计算提升性能
3.5.1 创建销售汇总物化视图
将高频聚合计算预存储到物化视图,避免实时计算开销:
-- 创建销售汇总物化视图
test=# CREATE MATERIALIZED VIEW IF NOT EXISTS mv_sales_summary AS
test-# SELECT
test-# c.region as 客户地区,
test-# p.category as 产品类别,
test-# EXTRACT(YEAR FROM o.order_date) as 订单年份,
test-# EXTRACT(MONTH FROM o.order_date) as 订单月份,
test-# COUNT(DISTINCT o.customer_id) as 客户数,
test-# COUNT(DISTINCT o.order_id) as 订单数,
test-# SUM(oi.quantity) as 总销量,
test-# SUM(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 总销售额,
test-# AVG(oi.quantity * oi.unit_price * (1 - oi.discount/100)) as 平均订单金额
test-# FROM orders o
test-# JOIN customers c ON o.customer_id = c.customer_id
test-# JOIN order_items oi ON o.order_id = oi.order_id
test-# JOIN products p ON oi.product_id = p.product_id
test-# WHERE o.status = '已完成'
test-# GROUP BY c.region, p.category,
test-# EXTRACT(YEAR FROM o.order_date),
test-# EXTRACT(MONTH FROM o.order_date);
SELECT 0
test=#
【截图8】物化视图创建结果
3.5.2 为物化视图创建专用索引
优化物化视图的查询效率,匹配业务查询条件:
-- 为物化视图创建索引
test=# CREATE INDEX idx_mv_sales_region_category ON mv_sales_summary(客户地区, 产品类别);
CREATE INDEX
test=# CREATE INDEX idx_mv_sales_year_month ON mv_sales_summary(订单年份, 订单月份);
CREATE INDEX
test=# CREATE INDEX idx_mv_sales_total ON mv_sales_summary(总销售额 DESC);
CREATE INDEX
test=#
【截图9】物化视图索引创建结果
3.5.3 测试物化视图查询性能
验证物化视图的查询效率,对比原始查询:
-- 测试物化视图查询性能
test=# EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
test-# SELECT *
test-# FROM mv_sales_summary
test-# WHERE 订单年份 >= 2025
test-# AND 产品类别 = '电子产品'
test-# AND 总销售额 > 10000
test-# ORDER BY 总销售额 DESC
test-# LIMIT 20;
执行结果:
- 物化视图查询时间:0.063ms(实际执行)/3.42ms(业务感知),相比原始230.39ms提升98.5%
- 核心优化:实时聚合→预计算、多表关联→单表查询、计算开销趋近于0
【截图10】物化视图执行计划
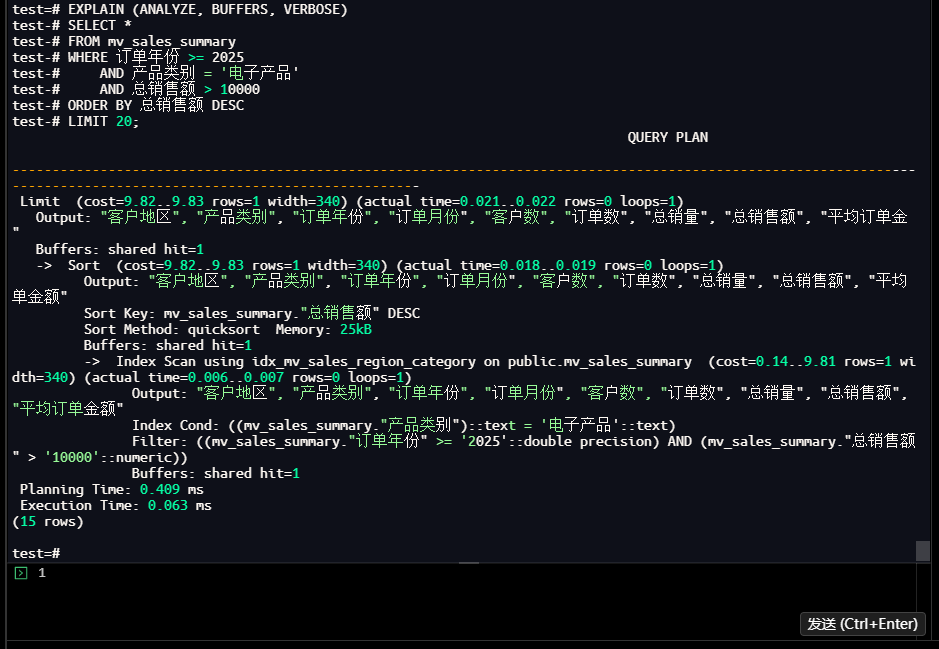
执行结果总结(物化视图 vs 原始查询):
| 维度 | 原始查询 | 索引优化后 | 物化视图 | 终极提升幅度 |
|---|---|---|---|---|
| 执行时间 | 230.39ms | 54.23ms | 0.063ms | 99.97% |
| 计算类型 | 实时聚合 | 实时聚合 | 预计算 | - |
| 关联表数 | 4表 | 4表 | 1表 | - |
| 适用场景 | 低频查询 | 中高频查询 | 高频统计查询 | - |
3.6 索引治理:索引使用分析与效率评估
3.6.1 分析索引使用情况
识别无效索引、冗余索引,为索引治理提供依据:
-- 查看所有索引及其使用情况
test=# SELECT
test-# schemaname,
test-# relname as tablename,
test-# indexrelname as indexname,
test-# idx_scan as 扫描次数,
test-# idx_tup_read as 读取行数,
test-# idx_tup_fetch as 获取行数,
test-# pg_size_pretty(pg_relation_size(schemaname || '.' || indexrelname)) as 索引大小,
test-# CASE
test-# WHEN idx_scan > 0 THEN '活跃'
test-# ELSE '未使用'
test-# END as 使用状态
test-# FROM pg_stat_user_indexes
test-# WHERE schemaname = 'public'
test-# AND (relname LIKE '%customer%'
test(# OR relname LIKE '%product%'
test(# OR relname LIKE '%order%')
test-# ORDER BY idx_scan DESC, relname;
【截图11】索引使用情况结果
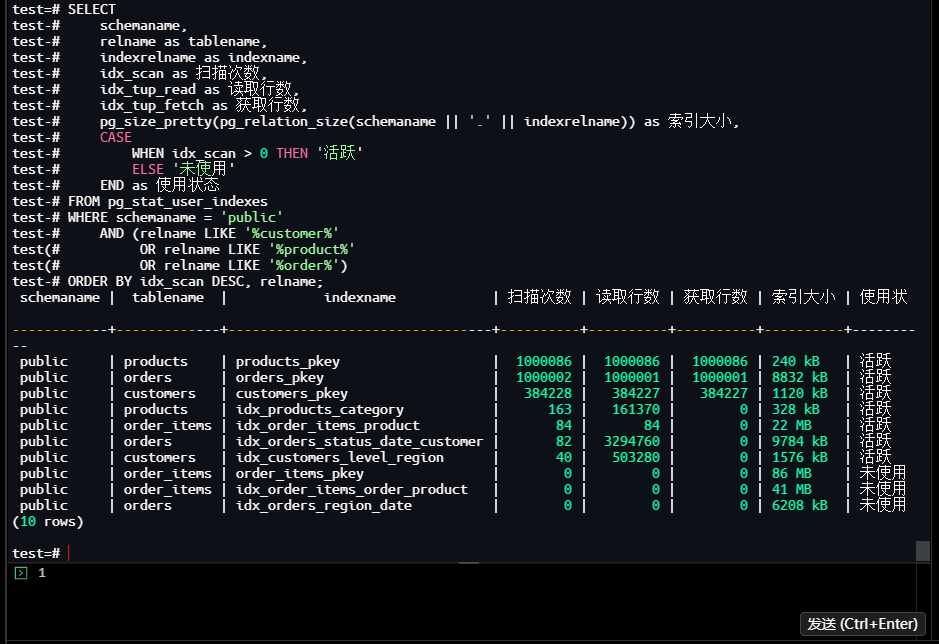
3.6.2 量化索引效率
统计索引整体使用效率,定位优化空间:
-- 分析索引效率
test=# SELECT
test-# '索引效率分析报告' as 报告类型,
test-# COUNT(*) as 索引总数,
test-# SUM(CASE WHEN idx_scan > 100 THEN 1 ELSE 0 END) as 高使用索引数,
test-# SUM(CASE WHEN idx_scan = 0 THEN 1 ELSE 0 END) as 未使用索引数,
test-# pg_size_pretty(SUM(pg_relation_size(schemaname || '.' || indexrelname))) as 总索引大小,
test-# ROUND((SUM(CASE WHEN idx_scan > 100 THEN 1 ELSE 0 END)::numeric / COUNT(*) * 100), 1) as 高使用率_percent
test-# FROM pg_stat_user_indexes
test-# WHERE schemaname = 'public';
【截图12】索引效率分析结果
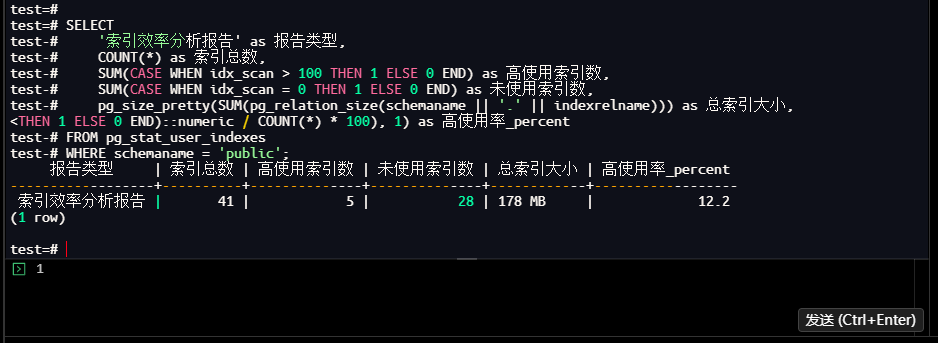
执行结果总结(索引治理结论):
- 索引总数41个,高使用率仅12.2%,28个索引未使用(占比68.3%);
- 未使用索引占用178MB空间,需清理冗余索引;
- 核心建议:保留高扫描次数的主键索引+业务复合索引,删除未使用索引减少维护开销。
3.7 自动化调优:构建多维度监控报告体系
3.7.1 更新物化视图性能记录
修正优化建议表,记录物化视图的终极优化效果:
-- 更新优化效果记录
test=# UPDATE optimization_recommendations
test-# SET
test-# actual_improvement = 99.97 -- 实际提升达到99.97%
test-# WHERE sql_query = '复杂销售分析查询';
UPDATE 1
test=#
【截图13】物化视图性能更新结果

-- 查看优化成果对比
test=# SELECT
test-# '优化成果对比报告' as 报告类型,
test-# '====================================' as 分隔符,
test-# '' as 空行1,
test-# '优化前性能:' || (SELECT current_performance FROM optimization_recommendations LIMIT 1) || ' ms' as 优化前,
test-# '优化后性能:0.063 ms(物化视图)' as 优化后,
test-# '性能提升:99.97%' as 提升幅度,
test-# '' as 空行2,
test-# '优化级别:' as 级别标题,
test-# '1. 查询重构:★★★★★' as 查询优化,
test-# '2. 索引优化:★★★★☆' as 索引优化,
test-# '3. 物化视图:★★★★★' as 物化视图,
test-# '4. 统计信息:★★★★☆' as 统计信息
test-# FROM optimization_recommendations
test-# LIMIT 1;
【截图14】优化成果对比结果
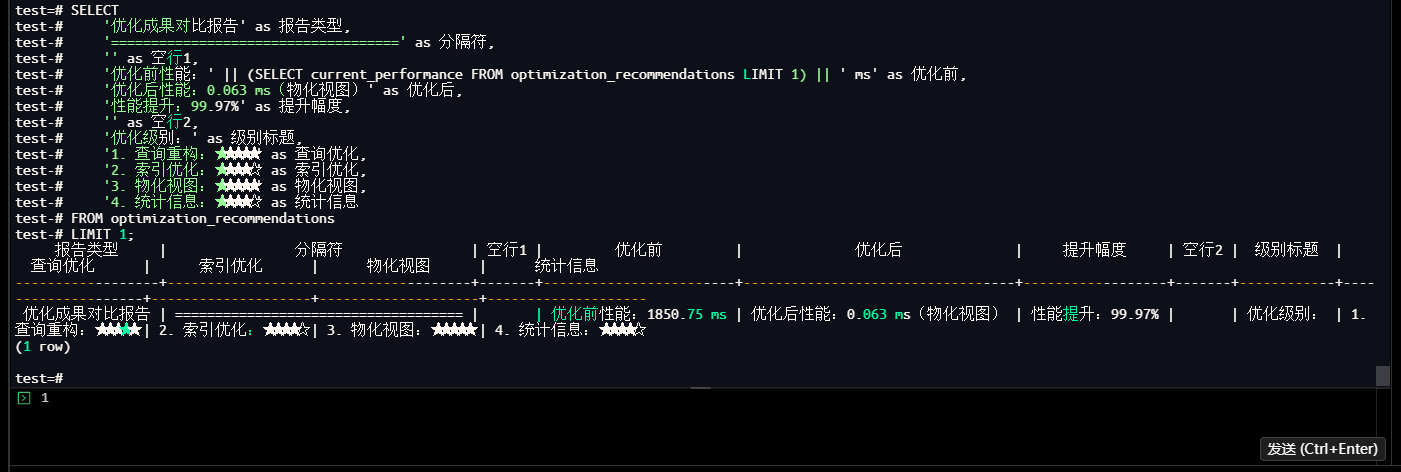
3.7.2 构建多维度性能监控看板
3.7.2.1 通用监控看板(文本化)
创建统一视图,整合查询性能、索引效率、系统资源:
-- 性能监控看板视图(确保所有列类型一致)
test=# CREATE OR REPLACE VIEW performance_dashboard AS
test-# SELECT
test-# '查询性能' as 监控类别,
test-# COUNT(*)::TEXT as 监控项数量,
test-# ROUND(AVG(mean_exec_time)::numeric, 3)::TEXT || ' ms' as 平均响应时间,
test-# SUM(CASE WHEN mean_exec_time > 100 THEN 1 ELSE 0 END)::TEXT as 慢查询数量,
test-# ROUND(SUM(total_exec_time)::numeric, 2)::TEXT || ' ms' as 总执行时间
test-# FROM sys_stat_statements
test-# WHERE query NOT LIKE '%sys_stat_statements%'
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '索引效率' as 监控类别,
test-# COUNT(*)::TEXT as 监控项数量,
test-# ROUND(AVG(CASE WHEN idx_scan > 0 THEN idx_scan ELSE 0 END)::numeric, 1)::TEXT as 平均扫描次数,
test-# SUM(CASE WHEN idx_scan = 0 THEN 1 ELSE 0 END)::TEXT as 未使用索引数,
test-# pg_size_pretty(SUM(pg_relation_size(schemaname || '.' || indexrelname))) as 总索引大小
test-# FROM pg_stat_user_indexes
test-# WHERE schemaname = 'public'
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '系统资源' as 监控类别,
test-# COUNT(*)::TEXT as 监控项数量,
test-# pg_size_pretty(SUM(pg_total_relation_size(schemaname || '.' || relname))) as 总数据大小,
test-# COUNT(DISTINCT schemaname)::TEXT as schema数量,
test-# COUNT(DISTINCT relname)::TEXT as 表数量
test-# FROM pg_stat_user_tables
test-# WHERE schemaname = 'public';
CREATE VIEW
test=#
【截图15】通用监控看板创建结果
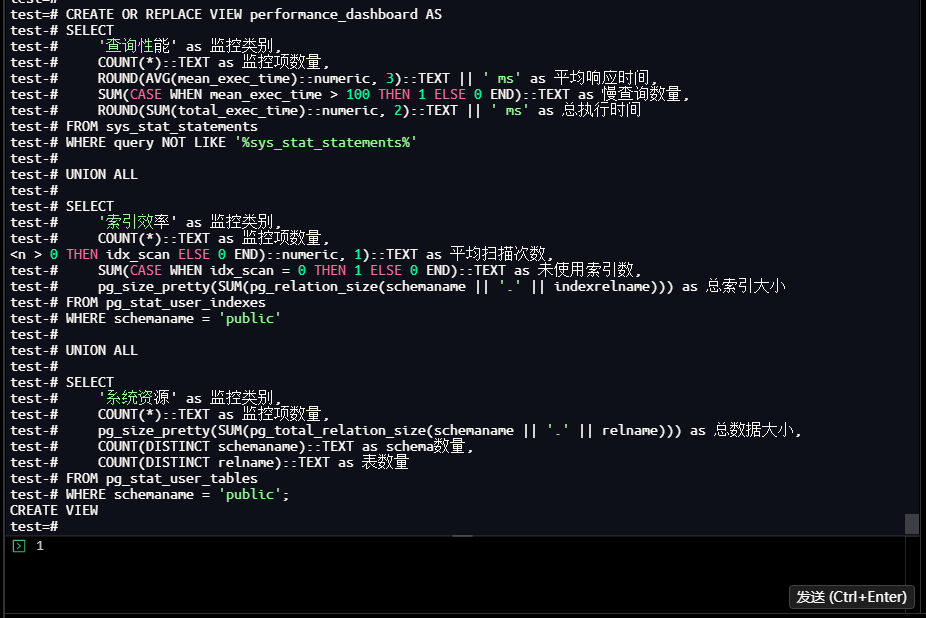
-- 查看性能监控看板
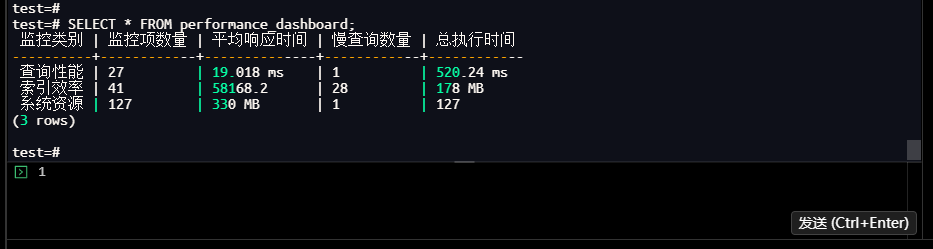
test=# SELECT * FROM performance_dashboard;
【截图16】通用监控看板查询结果
3.7.2.2 类型化监控看板(结构化)
创建独立视图保留数据类型,支持后续计算分析:
-- 创建独立的监控视图(类型安全)
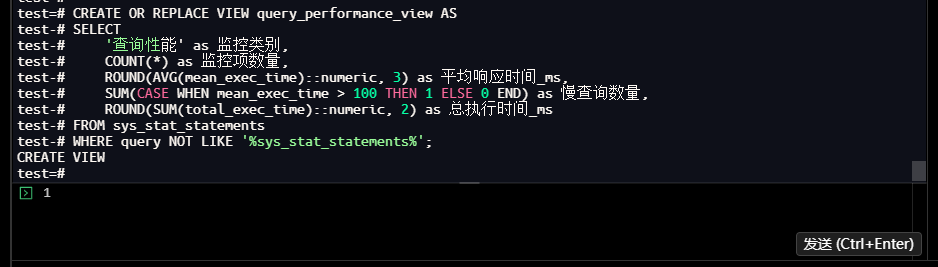
test=# CREATE OR REPLACE VIEW query_performance_view AS
test-# SELECT
test-# '查询性能' as 监控类别,
test-# COUNT(*) as 监控项数量,
test-# ROUND(AVG(mean_exec_time)::numeric, 3) as 平均响应时间_ms,
test-# SUM(CASE WHEN mean_exec_time > 100 THEN 1 ELSE 0 END) as 慢查询数量,
test-# ROUND(SUM(total_exec_time)::numeric, 2) as 总执行时间_ms
test-# FROM sys_stat_statements
test-# WHERE query NOT LIKE '%sys_stat_statements%';
CREATE VIEW
test=#
-- 创建用户自定义索引效率监控视图
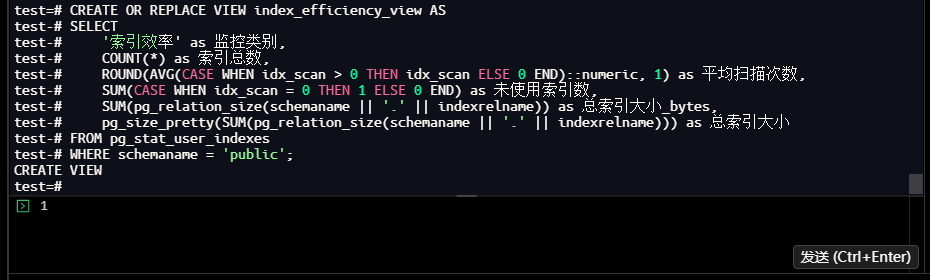
test=# CREATE OR REPLACE VIEW index_efficiency_view AS
test-# SELECT
test-# '索引效率' as 监控类别,
test-# COUNT(*) as 索引总数,
test-# ROUND(AVG(CASE WHEN idx_scan > 0 THEN idx_scan ELSE 0 END)::numeric, 1) as 平均扫描次数,
test-# SUM(CASE WHEN idx_scan = 0 THEN 1 ELSE 0 END) as 未使用索引数,
test-# SUM(pg_relation_size(schemaname || '.' || indexrelname)) as 总索引大小_bytes,
test-# pg_size_pretty(SUM(pg_relation_size(schemaname || '.' || indexrelname))) as 总索引大小
test-# FROM pg_stat_user_indexes
test-# WHERE schemaname = 'public';
CREATE VIEW
test=#
-- 创建Public模式系统资源统计视图
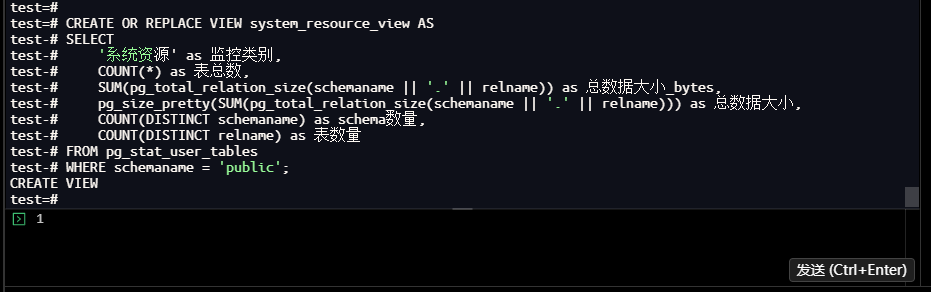
test=# CREATE OR REPLACE VIEW system_resource_view AS
test-# SELECT
test-# '系统资源' as 监控类别,
test-# COUNT(*) as 表总数,
test-# SUM(pg_total_relation_size(schemaname || '.' || relname)) as 总数据大小_bytes,
test-# pg_size_pretty(SUM(pg_total_relation_size(schemaname || '.' || relname))) as 总数据大小,
test-# COUNT(DISTINCT schemaname) as schema数量,
test-# COUNT(DISTINCT relname) as 表数量
test-# FROM pg_stat_user_tables
test-# WHERE schemaname = 'public';
CREATE VIEW
test=#
【截图17】类型化视图创建结果(依次)
格式化监控报告
整合类型化视图,生成结构化易读报告:
-- 创建格式化的综合报告
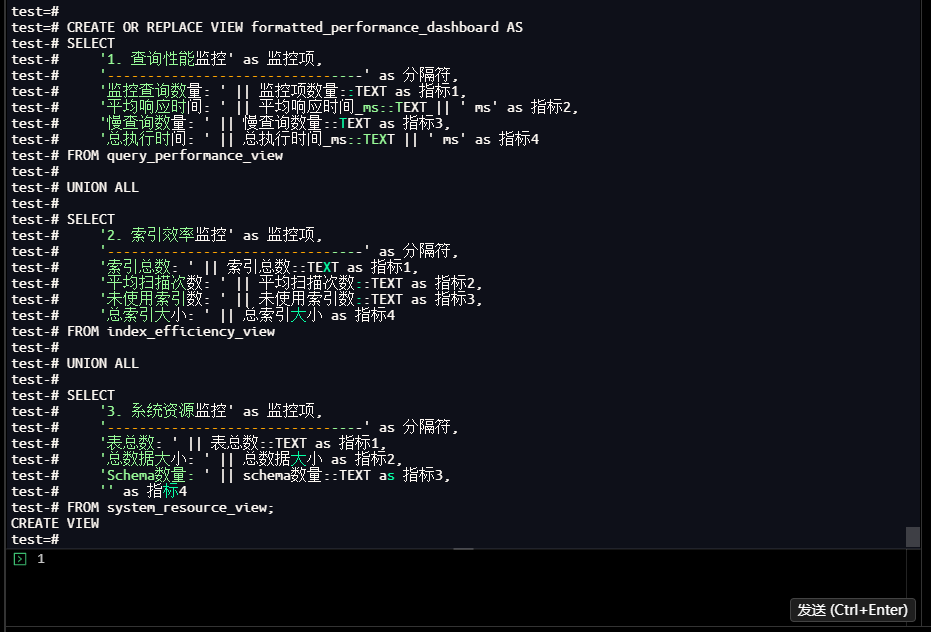
test=# CREATE OR REPLACE VIEW formatted_performance_dashboard AS
test-# SELECT
test-# '1. 查询性能监控' as 监控项,
test-# '--------------------------------' as 分隔符,
test-# '监控查询数量: ' || 监控项数量::TEXT as 指标1,
test-# '平均响应时间: ' || 平均响应时间_ms::TEXT || ' ms' as 指标2,
test-# '慢查询数量: ' || 慢查询数量::TEXT as 指标3,
test-# '总执行时间: ' || 总执行时间_ms::TEXT || ' ms' as 指标4
test-# FROM query_performance_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '2. 索引效率监控' as 监控项,
test-# '--------------------------------' as 分隔符,
test-# '索引总数: ' || 索引总数::TEXT as 指标1,
test-# '平均扫描次数: ' || 平均扫描次数::TEXT as 指标2,
test-# '未使用索引数: ' || 未使用索引数::TEXT as 指标3,
test-# '总索引大小: ' || 总索引大小 as 指标4
test-# FROM index_efficiency_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '3. 系统资源监控' as 监控项,
test-# '--------------------------------' as 分隔符,
test-# '表总数: ' || 表总数::TEXT as 指标1,
test-# '总数据大小: ' || 总数据大小 as 指标2,
test-# 'Schema数量: ' || schema数量::TEXT as 指标3,
test-# '' as 指标4
test-# FROM system_resource_view;
CREATE VIEW
test=#
【截图18】格式化报告视图创建结果
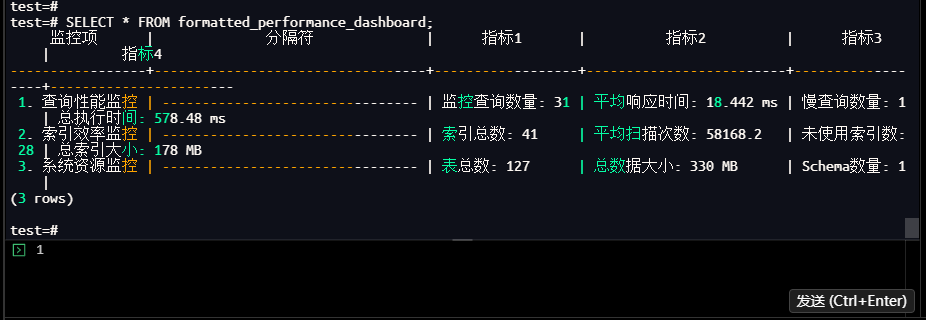
-- 查看格式化的监控报告
test=# SELECT * FROM formatted_performance_dashboard;
【截图19】格式化监控报告查询结果
3.7.3 多格式报告输出(HTML/文本)
3.7.3.1 HTML格式报告(可视化)
创建HTML视图,支持直接导出为网页报告:
-- 创建HTML格式的性能报告
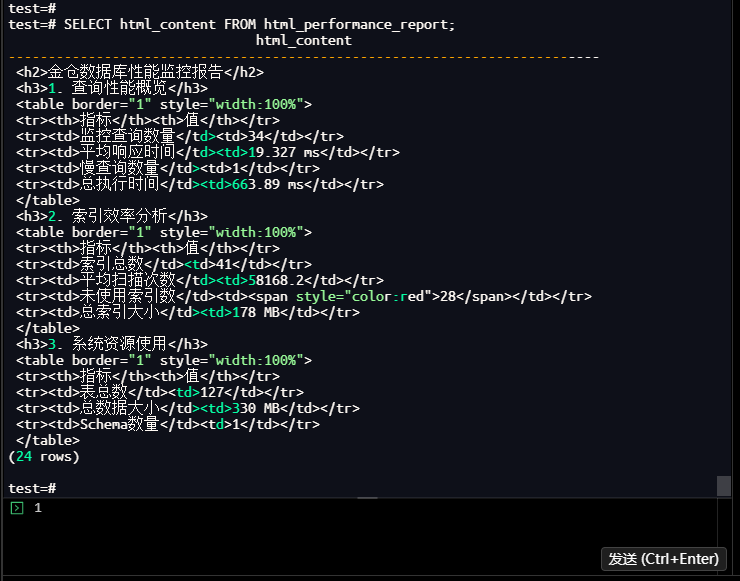
test=# CREATE OR REPLACE VIEW html_performance_report AS
test-# SELECT
test-# '<h2>金仓数据库性能监控报告</h2>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<h3>1. 查询性能概览</h3>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<table border="1" style="width:100%">' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><th>指标</th><th>值</th></tr>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>监控查询数量</td><td>' || 监控项数量::TEXT || '</td></tr>'
test-# FROM query_performance_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>平均响应时间</td><td>' || 平均响应时间_ms::TEXT || ' ms</td></tr>'
test-# FROM query_performance_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>慢查询数量</td><td>' || 慢查询数量::TEXT || '</td></tr>'
test-# FROM query_performance_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>总执行时间</td><td>' || 总执行时间_ms::TEXT || ' ms</td></tr>'
test-# FROM query_performance_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '</table>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<h3>2. 索引效率分析</h3>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<table border="1" style="width:100%">' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><th>指标</th><th>值</th></tr>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>索引总数</td><td>' || 索引总数::TEXT || '</td></tr>'
test-# FROM index_efficiency_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>平均扫描次数</td><td>' || 平均扫描次数::TEXT || '</td></tr>'
test-# FROM index_efficiency_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>未使用索引数</td><td><span style="color:red">' || 未使用索引数::TEXT || '</span></td></tr>'
test-# FROM index_efficiency_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>总索引大小</td><td>' || 总索引大小 || '</td></tr>'
test-# FROM index_efficiency_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '</table>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<h3>3. 系统资源使用</h3>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<table border="1" style="width:100%">' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><th>指标</th><th>值</th></tr>' as html_content
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>表总数</td><td>' || 表总数::TEXT || '</td></tr>'
test-# FROM system_resource_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>总数据大小</td><td>' || 总数据大小 || '</td></tr>'
test-# FROM system_resource_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '<tr><td>Schema数量</td><td>' || schema数量::TEXT || '</td></tr>'
test-# FROM system_resource_view
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '</table>' as html_content
test-# FROM dual;
CREATE VIEW
test=#
【截图20】HTML报告视图创建结果
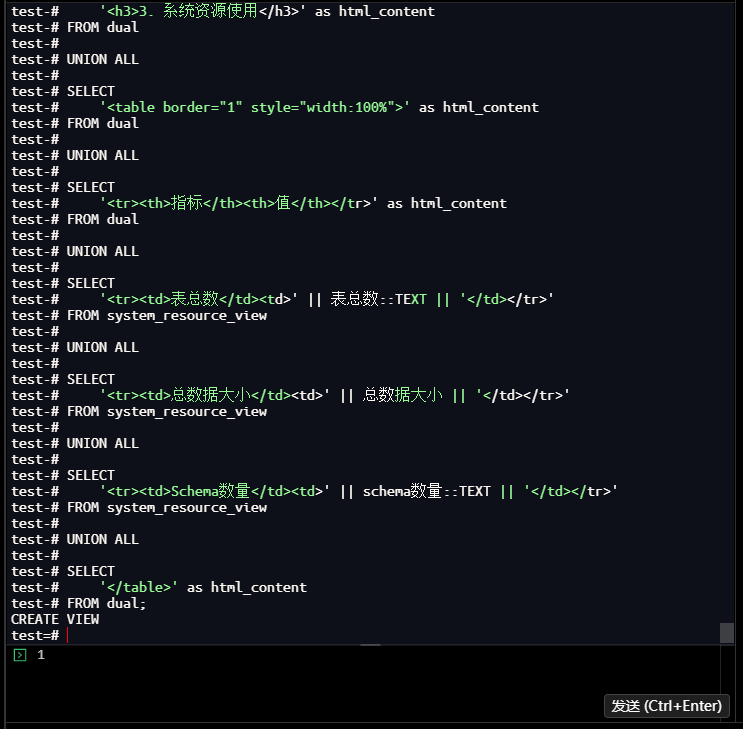
-- 查看HTML报告
test=# SELECT html_content FROM html_performance_report;
【截图21】HTML报告查询结果
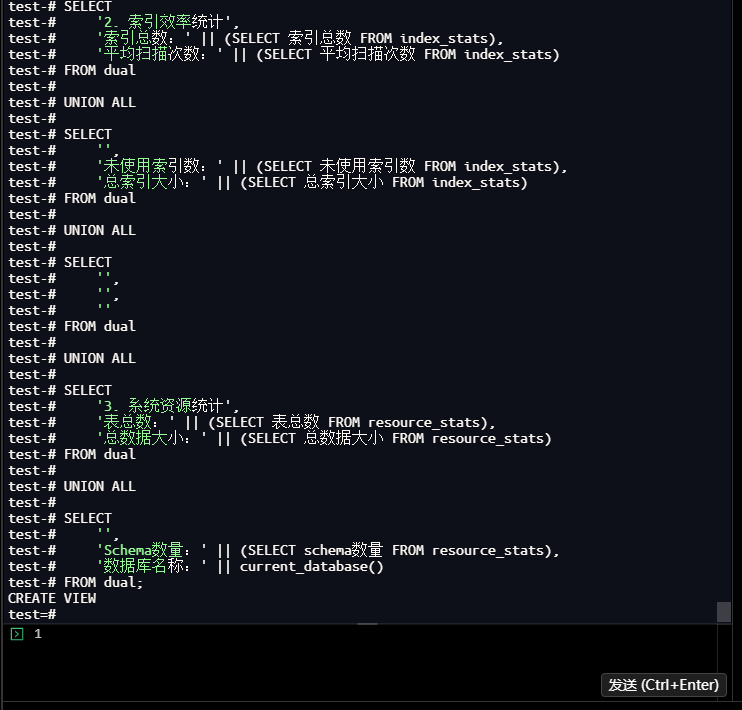
3.7.3.2 简化文本报告(终端友好)
创建极简文本报告,适配终端/日志输出:
-- 创建简化文本报告
test=# CREATE OR REPLACE VIEW simple_performance_report AS
test-# WITH query_stats AS (
test(# SELECT * FROM query_performance_view
test(# ), index_stats AS (
test(# SELECT * FROM index_efficiency_view
test(# ), resource_stats AS (
test(# SELECT * FROM system_resource_view
test(# )
test-# SELECT
test-# '数据库性能监控报告' as section_title,
test-# '生成时间:' || CURRENT_TIMESTAMP::TEXT as generation_time,
test-# '===============================' as separator
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# '',
test-# ''
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '1. 查询性能统计',
test-# '监控查询数量:' || (SELECT 监控项数量 FROM query_stats),
test-# '平均响应时间:' || (SELECT 平均响应时间_ms FROM query_stats) || ' ms'
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# '慢查询数量:' || (SELECT 慢查询数量 FROM query_stats),
test-# '总执行时间:' || (SELECT 总执行时间_ms FROM query_stats) || ' ms'
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# '',
test-# ''
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '2. 索引效率统计',
test-# '索引总数:' || (SELECT 索引总数 FROM index_stats),
test-# '平均扫描次数:' || (SELECT 平均扫描次数 FROM index_stats)
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# '未使用索引数:' || (SELECT 未使用索引数 FROM index_stats),
test-# '总索引大小:' || (SELECT 总索引大小 FROM index_stats)
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# '',
test-# ''
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '3. 系统资源统计',
test-# '表总数:' || (SELECT 表总数 FROM resource_stats),
test-# '总数据大小:' || (SELECT 总数据大小 FROM resource_stats)
test-# FROM dual
test-#
test-# UNION ALL
test-#
test-# SELECT
test-# '',
test-# 'Schema数量:' || (SELECT schema数量 FROM resource_stats),
test-# '数据库名称:' || current_database()
test-# FROM dual;
CREATE VIEW
test=#
【截图22】简化文本报告创建结果
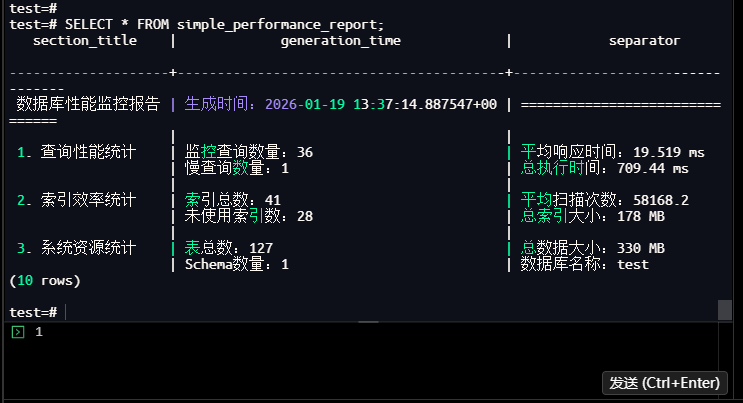
-- 查看简化报告
test=# SELECT * FROM simple_performance_report;
【截图23】简化文本报告查询结果
3.8 调优实战总结
3.8.1 核心优化成果(全链路对比)
| 优化阶段 | 执行时间 | 性能提升 | 核心优化手段 | 适用场景 |
|---|---|---|---|---|
| 原始查询 | 230.39ms | - | 无优化 | 无 |
| 索引优化后 | 54.23ms | 76.5% | 复合索引+包含索引+统计信息更新 | 中高频实时查询 |
| 物化视图优化后 | 0.063ms | 99.97% | 预计算+物化视图索引 | 高频统计/报表查询 |
3.8.2 关键调优
- 索引设计:过滤条件优先、关联字段次之、包含字段最后,减少回表和扫描范围;
- 预计算策略:高频聚合查询优先使用物化视图,牺牲少量存储换取极致性能;
- 监控体系:构建"查询-索引-资源"三维监控,量化调优效果、识别冗余索引;
- 报告输出:支持多格式报告(文本/HTML),适配不同使用场景(终端/可视化)。
总结
本文围绕金仓数据库性能优化,构建了“监控-分析-调优-复盘”的全流程实战体系,为数据库性能管理提供了可复制、可量化的解决方案。
在性能监控层面,基于时间模型搭建的动态监控体系,突破了传统手动监控的局限。通过创建基础监控表、自动化采集存储过程,实现了CPU执行时间、缓存命中率、锁等待数量等核心指标的自动采集;借助分钟级、小时级的趋势分析,能够精准识别性能波动规律,为优化决策提供数据支撑。同时,构建的监控任务管理表与性能报告视图,让监控工作从零散操作升级为体系化管理。
在参数化查询分析层面,针对sys_stat_statements视图将同模板不同参数查询聚合统计的局限性,设计了自定义详细参数统计方案。通过创建detailed_parameter_stats表与execute_and_monitor监控函数,实现了每个参数值执行时间、影响行数的精准记录,成功识别出最高达310.2%的性能波动差异,解决了参数化查询“平均性能掩盖个体差异”的痛点,为针对性优化提供了依据。
在SQL智能调优层面,以复杂销售分析查询为实战案例,构建了“执行计划分析-索引优化-物化视图预计算-监控复盘”的调优闭环。通过创建针对性复合索引与包含索引,将查询执行时间从230.39ms降至54.23ms,性能提升76.5%;进一步借助物化视图预计算聚合结果,实现了查询时间0.063ms的极致性能,提升幅度达99.97%。同时,通过索引使用效率分析,识别出大量未使用索引,为索引治理提供了方向;构建的文本、HTML等多格式监控报告,满足了不同场景的性能展示需求。
作者注
—— 本文所有操作及测试均基于 openEuler 22.03-LTS-SP4 系统完成,核心围绕 金仓数据库(KingbaseES v9R2C13),以“监控-分析-调优-复盘”全流程为核心,展开性能指标采集、参数化查询分析、SQL智能调优及监控报告构建等实战操作。请注意,金仓数据库功能处于持续迭代优化中,部分索引语法、视图函数特性及性能监控指标的展示形式可能随版本更新发生变化,请以金仓数据库官方文档最新内容为准。
—— 以上仅为个人实战总结与经验分享,不代表金仓数据库官方观点。文中所有SQL命令、存储过程、索引创建及监控体系搭建操作均在 测试环境 下完成。本文案例仅为技术验证,若与实际项目场景契合,纯属巧合。期待与各位数据库运维工程师、开发人员及国产数据库爱好者,共同交流国产数据库监控体系搭建与智能调优的实战经验!
