




随着国产数据库替代进程的推进,一个新的概念逐渐频繁出现在技术视野中:融合数据库。
其核心理念是:在同一个数据库内核中,同时支持关系型、时序、文档、GIS、向量等多种数据模型,实现“一个数据库,多种用途”。
这听起来很理想,但问题也随之而来:
融合数据库是否真的具备“一库多用”的工程可行性?
它是架构演进方向,还是功能堆叠的结果?
基于官方技术资料与运维文档,本文从工程视角出发,对融合数据库(以金仓数据库 KingbaseES 为例)进行了一次技术研究与基础验证,并给出一些初步观察结论。
一、为什么需要研究“融合数据库”?
在传统企业架构中,数据库通常呈现出“多库并存”的状态:
- Oracle / MySQL:核心业务系统
- MongoDB:文档数据
- 时序数据库:设备采集数据
- GIS 数据库:空间信息
- 向量数据库:AI 与检索
这种“一事一库”的架构在早期是合理的,但随着系统规模扩大,逐渐暴露出几个问题:
- 技术栈高度复杂,运维成本上升
- 数据分散,跨模型分析困难
- 备份、安全、审计体系割裂
- 国产化替代需要多套数据库同时替换
融合数据库提出的目标是:
用一个数据库平台,承载多种数据模型,减少系统之间的“裂缝”。
这正是本文关注的研究对象。
二、研究目标与方法说明
本次研究重点关注四个问题:
- 是否具备关系型数据库的基本能力(建库、建表、事务、权限)
- 是否具备多模数据的统一管理能力
- 运维体系是否成熟(监控、备份、锁、性能分析)
- 对 DBA 的学习与运维成本如何
研究方法基于:
- 官方技术资料
- 实验环境中的功能验证
- 架构设计分析
三、基础能力验证:是否具备关系型数据库完整功能?
在实验环境中,首先验证最基本的数据库管理能力。
1. 用户与数据库创建
create user test_user with password '123456';
create database testdb owner test_user;
grant all on database testdb to test_user;
2. 模式与表管理
create schema biz authorization test_user;
create table biz.device_info(
id int primary key,
name varchar(100),
create_time timestamp
);
3. 并发连接与锁监控
select usename,state,count(*)
from sys_stat_activity
group by usename,state;
锁阻塞检测:
select pid, sys_blocking_pids(pid), query
from sys_stat_activity
where state<>'idle';
从操作体验来看,其管理方式与 PostgreSQL / Oracle 体系接近,对 DBA 并不陌生。
四、多模融合能力的技术观察
融合数据库的核心不在“能建表”,而在“能否统一管理不同数据模型”。
1. 时序数据与关系数据的融合
时序数据通常具有:
- 数据量大
- 按时间连续
- 查询以时间范围为主
融合数据库通过内置时序引擎与分区机制进行优化,同时仍保留标准 SQL 查询能力。
在支持多模型的融合数据库中,可以使用标准 SQL 对关系和时序数据进行联合查询。比如::
select d.device_id, t.value
from device_info d
join ts_device_data t
on d.device_id = t.device_id
where t.ts > now() - interval '7 days';
这一模式的关键价值在于:
不需要跨数据库同步数据,即可完成业务与采集数据的关联分析。
2. 文档模型的统一管理
在融合数据库中,JSON/BSON 文档数据可与关系数据共存,并支持协议级兼容 MongoDB 接口。
从架构上看,其意义在于:
- 原 MongoDB 应用可低成本迁移
- 文档数据进入统一事务体系
- 统一备份、审计、安全机制
这使“文档型数据库”不再成为系统外部孤岛。
3. GIS 与空间数据融合
融合数据库内置空间数据类型与空间函数(符合 OpenGIS 标准),可支持:
- 矢量数据
- 空间索引
- 空间查询
并能与业务表联合分析,例如:
select d.id, g.area_name
from device_info d
join gis_area g
on st_within(d.location, g.geom);
这为政务、交通、自然资源等场景提供统一数据平台基础。
五、运维体系验证:是否“可管、可控、可维护”?
融合数据库如果只是功能丰富,但运维体系不成熟,很难在生产环境使用。
本次重点关注了几个运维维度。
1. 性能分析(kbbadger)
kbbadger -j 10 kingbase.log -o report.html
可生成慢 SQL、资源消耗、热点对象的分析报告,便于定位瓶颈。
2. 表与索引膨胀检测
select schemaname||'.'||relname,
n_dead_tup, n_live_tup
from sys_stat_all_tables
order by n_dead_tup desc limit 10;
并支持 vacuum、reindex、sys_squeeze 等维护手段。
3. 集群状态与主备监控
repmgr cluster show repmgr service status
select * from sys_stat_replication where usename='esrep';
从运维能力角度看,其集群与高可用机制较为完整。
六、融合数据库带来的架构变化
从架构层面看,融合数据库的最大价值不在“多支持几种模型”,而在于:
1. 技术栈收敛
由原来的:
- Oracle
- MongoDB
- 时序数据库
- GIS 数据库
转为:
- 一套融合数据库平台
2. 数据不再割裂
关系数据、文档数据、空间数据、时间序列数据可以在同一系统内进行关联分析。
3. 运维体系统一
- 一套备份
- 一套审计
- 一套监控
- 一套高可用
这对大型系统尤其重要。
七、金仓数据库多模融合
基于前述对融合数据库基础能力、多模型支持及运维体系的验证,可以看到:
融合数据库在工程实践中表现出的能力,已经不再是简单的功能叠加,而逐步体现为一种面向企业数据架构演进的工程化方案。
以金仓数据库 KingbaseES 为例,其多模融合能力在统一数据库内核下,实现了关系型、时序、文档、GIS、向量等多种数据模型的协同管理,并能够在同一 SQL 体系中完成跨模型联合查询。
从工程角度看,这种能力带来的核心变化主要体现在三个方面。
1. 架构由“多库并存”走向“平台化融合”
传统系统往往需要多种数据库分别承载不同数据模型,而融合数据库通过统一平台承载多类数据,使原本分散的数据库体系收敛为一套统一数据平台。
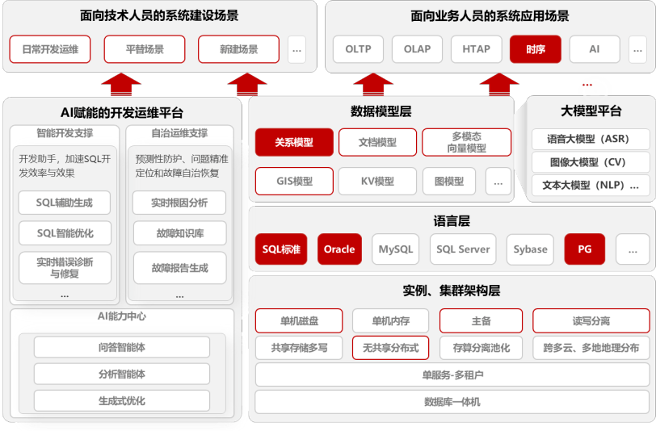
这种架构变化,不仅降低了系统复杂度,也为后续扩展新数据模型提供了统一基础。
2. 数据由“割裂管理”走向“统一分析”
多模融合使关系数据、时序数据、空间数据与文档数据能够在同一系统内直接关联分析,避免了跨数据库同步、接口转换及数据一致性维护问题。
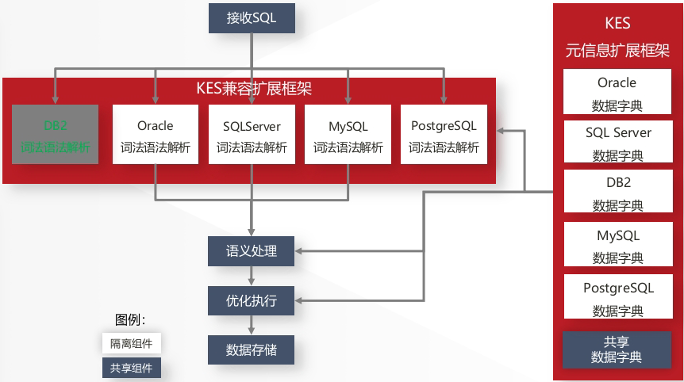
在实际业务场景中,这种能力在智慧政务、能源、电力、交通等涉及多源数据协同分析的系统中具有较高适配价值。
3. 运维由“多体系维护”走向“统一治理”
融合数据库在多模型场景下仍保持统一的高可用架构、备份体系、安全机制及性能监控能力,使 DBA 可以在同一运维体系中管理不同数据模型。
这使多模数据环境不再意味着运维复杂度成倍增加,而是通过平台化能力实现统一管理与控制。
4. 对国产化替代的现实意义
在国产化替代背景下,融合数据库提供了一条不同于“多产品拼装”的路径:
通过一套融合数据库平台,同时承载原本由多种数据库分别支撑的业务系统,从而降低替代工程的复杂度与长期运维成本。
从实践角度看,这种“平台级替代”模式,更有利于形成稳定、可持续演进的数据底座。
小结
综合工程验证结果可以认为:
融合数据库并非单纯的功能叠加,而是一种面向多模数据场景的体系化解决方案。
金仓数据库通过多模融合架构,在保持关系型数据库成熟能力的同时,逐步构建统一的数据管理平台,使“一库多用”从概念走向可落地的工程实践。
该模式为企业在多模数据场景下构建统一数据底座,提供了一条具有工程可行性的实现路径。
八、局限与挑战(必须面对的问题)
从研究角度看,融合数据库仍存在一些现实挑战:
- 数据建模复杂度提升
多模数据混用,对表设计与规范要求更高 - DBA 技能要求提高
需要同时理解关系、时序、GIS、文档模型 - 性能调优依赖实际业务负载
不同模型混合场景需谨慎评估 - 并非所有系统都适合融合
简单 OLTP 系统未必需要多模能力
结语
数据库正在从单一数据管理工具,逐步演进为企业级统一数据底座平台。
融合数据库的意义,不只是支持更多数据模型,而是在多模数据并存的背景下,重新定义系统架构的复杂度边界。
从本文的工程验证结果来看,以金仓数据库 KingbaseES 为代表的融合数据库实践,已经在关系型、时序、文档与空间数据等场景中体现出一定的工程可行性,使“一库多用”从概念走向可落地路径。
当然,融合数据库并非适用于所有系统,其设计复杂度与运维要求也对 DBA 提出了更高要求。但在多模数据成为常态的业务环境中,这种平台化的数据底座模式,值得持续关注与深入实践。
这也许正是融合数据库在当前阶段存在的真正价值。
