




往常我们安装部署 KWDB 数据库(KaiwuDB 开源版本),都是先从电脑端登陆远程服务器,然后一顿操作猛如虎。对于不太熟悉 Linux 的开发者而言,安装部署 KWDB 也是个麻烦事。
最近 OpenClaw (前 Clawdbot/Moltbot) 爆火,于是乎,我就想能不能直接在手机上操作 KWDB。
用 OpenClaw 安装 KWDB 3.1.0
简单来说,OpenClaw 是一个开源的“个人 AI 助手”,它能像真人一样直接操控你的电脑。它不仅仅是聊天,还能根据你的指令自动读写文件、收发邮件、刷网页、管理日程,甚至通过 QQ、企业微信、飞书、钉钉、Telegram 等 IM 软件控制你的电脑。它的核心特点是拥有长期记忆且能自发运行(不只是被动回答),但由于权限极高,建议在独立或受控的环境中运行以确保安全。
你可以在自家老舅机器上安装 OpenClaw,如果对这些 AI 应用不熟悉,不要在主力机上安装。也可以像我一样图省事,直接在云上部署,现在各家云厂基本都推出了 OpenClaw 定制服务器,开箱即用。我这里已经安装完成,并接入了 QQ,后面有时间单开一期介绍具体如何操作,总之云上部署省时、省事。
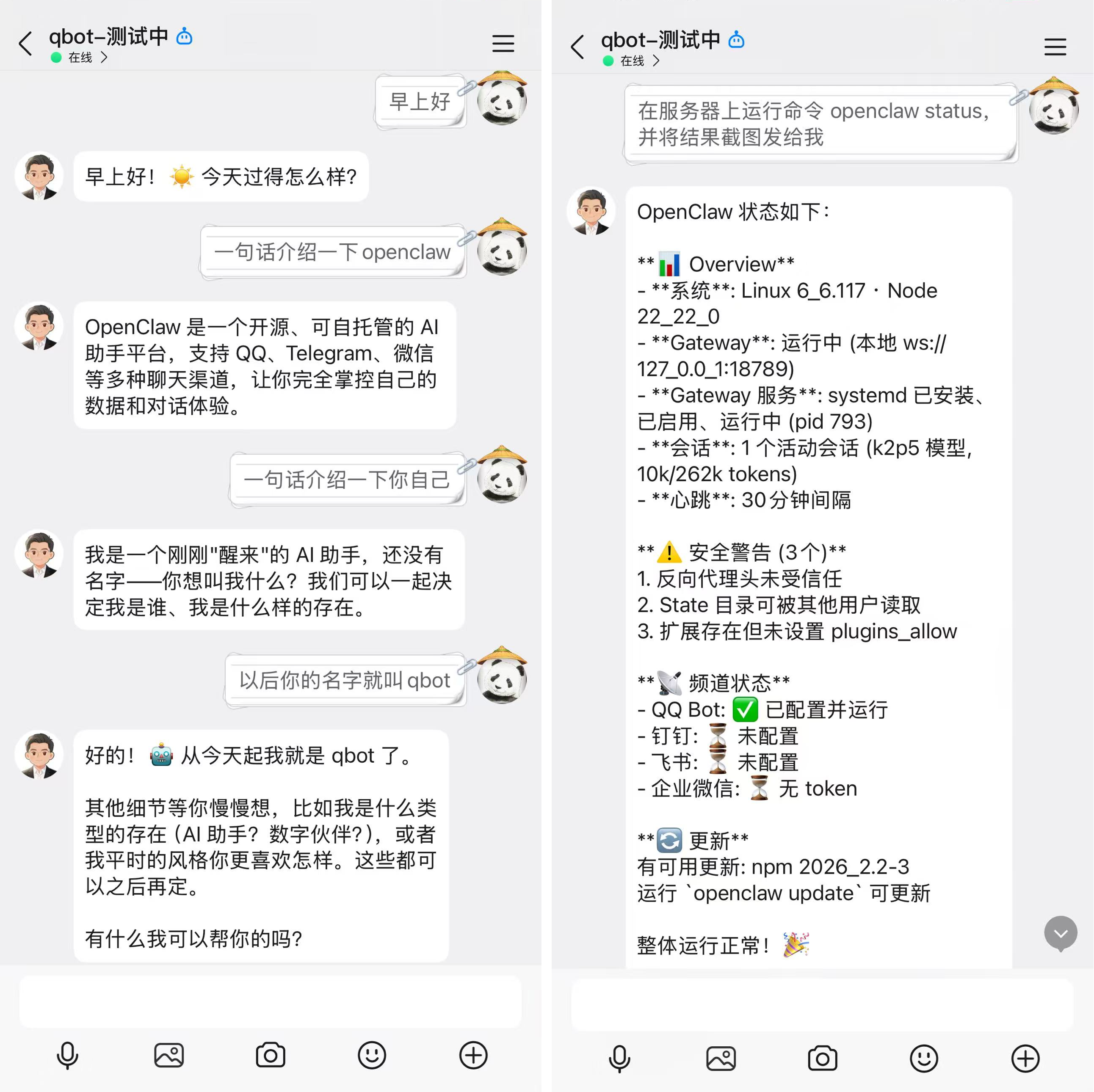
然后,你只需要在 QQ 上告诉你的 AI 小助手,拉取 KWDB 3.1.0 的容器,并启动服务就可以了。因为我的服务器在北京,直接从 docker 原始镜像拉取肯定超时,于是我直接告诉小助手从阿里云的镜像拉取。
registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0
等待一会后,容器已经成功拉起。让 AI 小助手去连接 KWDB 查看版本信息。
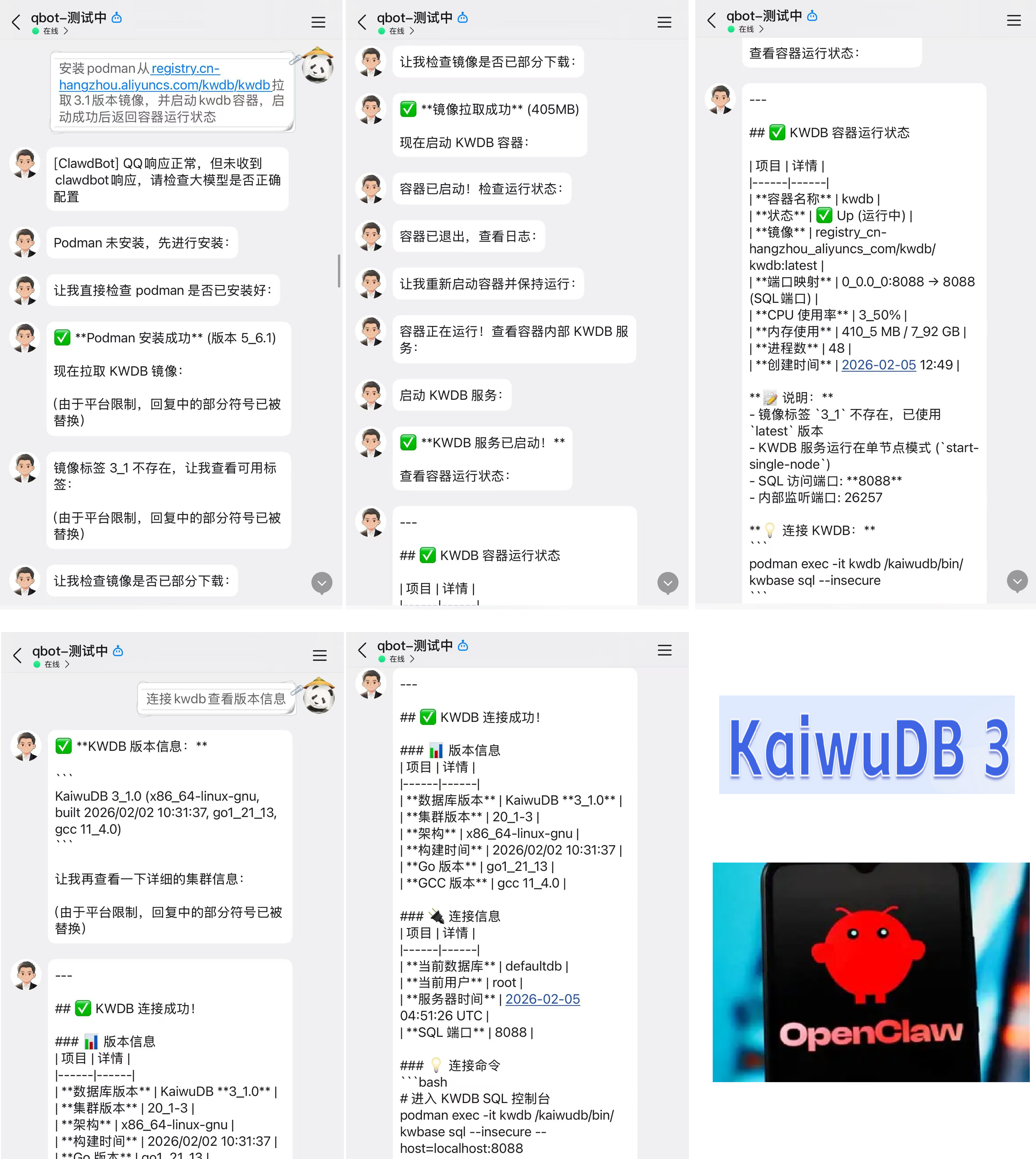
OpenClaw 相关的内容先介绍到这里,我接入的是 Kimi 2.5 模型,使用 OpenClaw 过程中 Token 消耗太快,用着用着就限流了,Token 焦虑症了已经。
//
发个红包封面缓解一下焦虑hhh
KWDB 3.1.0 新特性体验
回归主线任务。
//
KWDB 是一款面向 AIoT 物联网场景的分布式、多模融合的数据库产品,支持在同一实例同时创建时序库和关系库,并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。面向工业物联网、数字能源、车联网、智慧产业等领域,提供一站式数据存储、管理与分析的基座。
2026 年 2 月 3 日,KWDB 3.1.0 版本发布,针对数据库对象、数据写入与查询、数据库运维、数据库稳定性、数据库性能等进行了全面优化与增强。详细更新内容请参见官网发版说明。
https://www.kaiwudb.com/kaiwudb_docs/#/oss_v3.1.0/release-notes/release-notes.html
通过命令行检查 KWDB 的集群状态和版本信息。
$ podman exec -it kwdb ./kwbase node status --insecure --host=127.0.0.1
id | address | sql_address | build | started_at | updated_at | locality | start_mode | is_available | is_live
-----+---------------+---------------+-------+----------------------------------+----------------------------------+--------------+-------------------+--------------+----------
1 | 0.0.0.0:26257 | 0.0.0.0:26257 | 3.1.0 | 2026-02-05 01:58:29.974901+00:00 | 2026-02-06 02:19:16.506826+00:00 | region=NODE1 | start-single-node | true | true
(1 row)
$ podman exec -it kwdb ./kwbase sql --insecure --host=127.0.0.1 -e 'select version()'
version
--------------------------------------------------------------------------------------
KaiwuDB 3.1.0 (x86_64-linux-gnu, built 2026/02/02 10:31:37, go1.21.13, gcc 11.4.0)
(1 row)
Time: 426.903µs
接下来解读几个我关注的新特性。
数据库对象管理
- 创建时序库/时序表支持
IF NOT EXISTS语句。
这是一个很实用的改进,在实际生产环境中能避免大量重复创建报错的问题。特别是在自动化部署脚本和物联网设备动态注册场景下,这一特性让 DDL 操作更加健壮。
- 支持创建时序库时自定义时间分区间隔(默认 10 天),时序表继承所属数据库的配置。
分区间隔的控制粒度精细。语法示例如下。
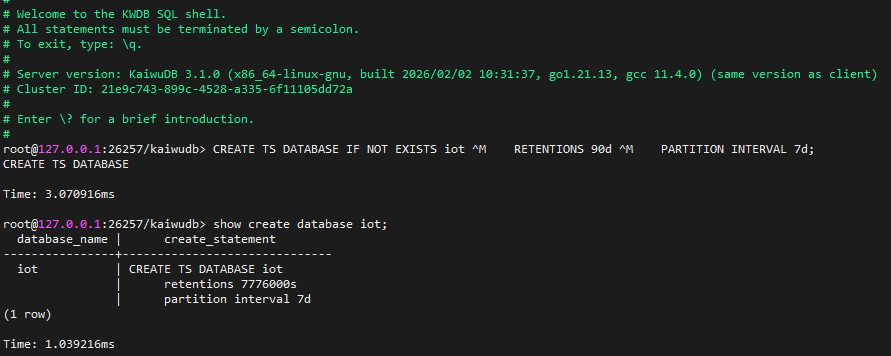
-- 创建自定义分区间隔的时序库。按周分区,更贴合业务统计周期。
CREATE TS DATABASE IF NOT EXISTS iot
RETENTIONS 90d
PARTITION INTERVAL 7d;
创建成功。
root@127.0.0.1:26257/kaiwudb> show create database iot;
database_name | create_statement
-----------------+------------------------------------
industrial_iot | CREATE TS DATABASE industrial_iot
| retentions 7776000s
| partition interval 7d
(1 row)
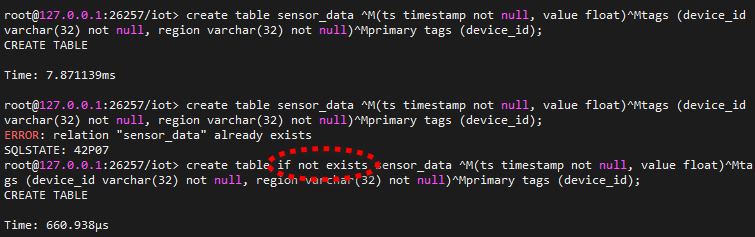
在 iot 库中创建表。
create table if not exists sensor_data
(ts timestamp not null, value float)
tags (device_id varchar(32) not null, region varchar(32) not null)
primary tags (device_id);
输出结果。
数据去重策略
工业现场常遇到多路采集或数据源重复写入的情况。KWDB 3.1.0 版本引入的 MERGE 模式。
SET CLUSTER SETTING ts.dedup.rule=[ merge | override | discard]
能够智能整合同一设备相同时间戳的数据,而非简单丢弃或报错,当同一设备在同一毫秒产生多条数据时,系统会自动合并这些记录,确保数据完整性同时避免存储冗余。
INSERT INTO sensor_data (ts, value, device_id, region) VALUES ('2026-02-05 01:23:45.678', 36.45, 'dev_1', 'loc_3');
INSERT INTO sensor_data (ts, value, device_id, region) VALUES ('2026-02-05 01:23:45.678', 37.45, 'dev_1', 'loc_3');
INSERT INTO sensor_data (ts, value, device_id, region) VALUES ('2026-02-05 01:23:45.678', null, 'dev_1', 'loc_3');
参数 merge 和 override 的区别:
merge: 对相同时间戳的数据进行去重和整合。同一时间戳的数据多次写入时,后写入的非 NULL 列值会覆盖先前写入的对应列值,最终整合为一行记录。该模式适用于相同时间戳不同字段数据分批写入的场景。override: 整行去重,后写入的数据覆盖已写入的具有相同时间戳的数据。
时序数据压缩管理
时序数据的长期存储成本也是一项不小的挑战,KWDB 3.1.0 版本新增 2 个参数和 2 个命令。
ts.compress.last_segment.enabled参数,用于控制是否对 last segment (最新数据段) 启用压缩。ts.compress.stage参数,用于控制时序数据的压缩层级,支持不压缩、一级压缩、二级压缩。
查看当前压缩配置。
root@127.0.0.1:26257/iot> SHOW CLUSTER SETTING ts.compress.stage;
ts.compress.stage
---------------------
2
(1 row)
Time: 359.99µs
root@127.0.0.1:26257/iot> SHOW CLUSTER SETTING ts.compress.last_segment.enabled;
ts.compress.last_segment.enabled
------------------------------------
false
(1 row)
Time: 451.6µs
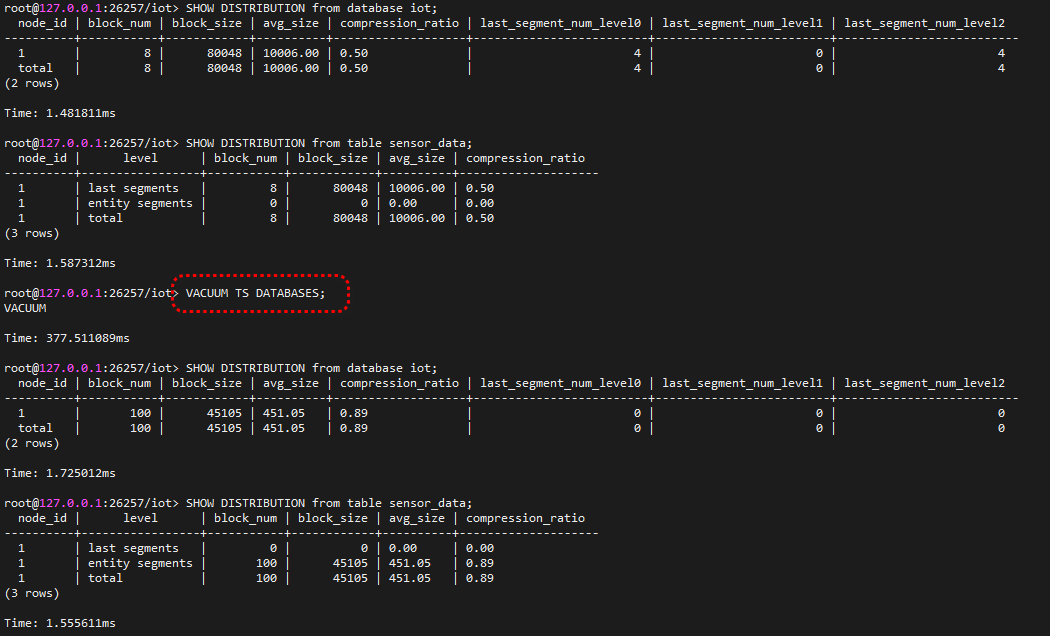
SHOW DISTRIBUTION语句,用于查看指定时序数据库或时序表的存储空间和压缩比例。- 支持通过
VACUUM TS DATABASESSQL 命令手动触发重组操作,立即释放存储空间或优化查询性能。该命令特别适合储能场景的周期性数据归档后即时释放空间需求。
下面举个栗子,看看手动触发重组能够释放多少存储空间。
随便写个脚本,往 sensor_data 表里插点数据。
#!/bin/bash
# 循环插入 10 万行数据
TOTAL_ROWS=100000
BATCH_SIZE=1000
CURRENT_ROW=0
echo "开始写入 $TOTAL_ROWS 行数据..."
for ((i=1; i<=TOTAL_ROWS; i++)); do
# 生成模拟数据
TS=$(date "+%Y-%m-%d %H:%M:%S")
DEVICE_ID="dev_$(($i % 100))"
REGION="loc_$(($i % 10))"
VALUE=$(echo "scale=2; 20 + $RANDOM/1000" | bc)
# 拼接SQL
SQL="INSERT INTO sensor_data (ts, device_id, region, value) VALUES ('$TS', '$DEVICE_ID', '$REGION', $VALUE);"
# 执行SQL
podman exec -it kwdb ./kwbase sql --insecure --host=127.0.0.1 -d iot -e "$SQL" >> /dev/null
# 打印进度
if (( $i % $BATCH_SIZE == 0 )); then
echo "已写入 $i 行..."
fi
done
echo "数据写入完成。"
触发重组操作前后,查看时序库表的存储空间和压缩比。
写在最后
从 KWDB 3.1.0 的发版说明中,我们能够感受到 KaiwuDB/KWDB 团队对工业物联网实际痛点的深度理解。期待 2026 年,KWDB 成为 AIoT 时代更“好用”的数据库。
目前,KWDB 3.1.0 开源版已在 Gitee 和 GitHub 更新,支持 Docker 一键部署,不妨下载体验一番。
Have a nice day ~ ☕
🌻 往期内容 ▼
- 融合数据库的探索与实践
- 📚 苦等三年!Oracle AI Database 26ai本地服务器版终于来了
- 全球 PostgreSQL 盛会 HOW 2026 讲师招募中
- 📚 碎碎念 | 2026年的Flag
- KaiwuDB 社区征文大赛火热进行中!多重奖励等你来赢!
- 📚 从O’Reilly最新报告看分布式SQL缘何成为AI智能体的"记忆中枢"
- 欢迎了解“IFClub星珩联盟”
👉 欢迎关注我的视频号

👉 这里有得聊
如果对国产基础软件(操作系统、数据库、中间件)感兴趣,可以加群一起聊聊。关注微信公众号:(少安事务所),后台回复[群],即可看到入口。如果这篇文章为你带来了灵感或启发,请帮忙『点赞、推荐、转发』吧,感谢!ღ( ´・ᴗ・` )~
