




Apache Cloudberry™ (Incubating) 是 Apache 软件基金会孵化项目,由 Greenplum 和 PostgreSQL 衍生而来,作为领先的开源 MPP 数据库,可用于建设企业级数据仓库,并适用于大规模分析和 AI/ML 工作负载。
GitHub: https://github.com/apache/cloudberry
01 从 AOCS 到 PAX:一次架构边界的重新审视
1.1 AOCS 的云原生适配困境
Greenplum 及其演化版本 AO/AOCS 列存引擎,诞生于企业本地部署环境。在块设备与传统文件系统前提下,“列分文件 + 追加写入”的模型能够稳定支撑分析负载,并在 OLAP 场景中取得良好表现。
然而,当存储介质迁移至云原生对象存储后,这套设计开始暴露出结构性冲突。对象存储强调顺序写入、请求聚合与大块 I/O,而 AOCS 依赖列级独立文件与频繁追加操作,两者在访问模型上存在天然错位。
这种错位带来了直接而具体的工程后果:
扫描宽表时,请求数量随列数线性增长,HTTP 请求风暴显著增加; 小块写入难以合并,请求放大效应导致访问成本与延迟迅速上升; 列文件分散布局削弱顺序读优势,吞吐与稳定性波动加剧。
与此同时,内核高度耦合、缺乏线程安全抽象,使得多线程扫描与向量化协同优化难以落地。在对象存储成为主流基础设施的背景下,这种架构约束已不再只是性能问题,而是演进能力问题。
AOCS 在本地块存储时代是合理的工程选择,但在云环境下,其设计前提已经发生根本变化。
1.2 结构性不匹配下的架构重构选择
多轮真实业务场景压测结果表明,瓶颈并非单点性能退化,而是存储模型与云环境之间的系统性不匹配。无论通过参数调优、缓存增强,还是在执行层增加并发策略,都只能缓解症状,无法消除结构性矛盾。
如果继续在 AOCS 之上进行补丁式演进,适配层将持续堆叠,复杂度呈指数增长,维护成本与技术债务同步扩大。
在多轮架构评审与技术可行性论证后,团队形成了明确结论。与其围绕旧引擎不断叠加适配逻辑,不如重新设计一套原生面向对象存储的存储模型,从数据布局、I/O 模式到并发抽象进行整体重构。
于是,一个更直接的问题被摆上台面——是否需要从架构层面重建存储引擎?
在多轮架构评审后,答案逐渐清晰。与其为旧引擎不断添加适配层,不如重新设计一套真正面向对象存储的存储模型。
PAX 项目由此启动。
02 面向对象存储重构:PAX 的体系化设计
PAX 的目标并非简单替代 AOCS,而是在云环境中同时满足高性能分析查询与事务一致性需求,为 Cloudberry 构建统一、可演进的存储基础。
2.1 行列共生的设计理念
数据库的存储布局历来存在“行存”与“列存”的分歧:前者适合事务型场景,后者适合分析型场景。传统架构往往在二者之间做出取舍,而 PAX 的核心设计理念是“行列共生”。 在 PAX 中,数据在同一物理文件、同一逻辑块(Block)中以列式组织,同时保留行级访问能力。这一设计带来以下特征:
在分析型查询(如聚合、排序)中,系统仅扫描所需列,大幅降低 I/O 成本; 在事务和宽表更新场景下,PAX 支持多列合并写入,减少对象存储上的小文件生成; 各列数据共享同一文件结构,显著降低对象存储请求次数,提高整体访问效率。
这种设计使得 PAX 在 OLTP 与 OLAP 混合负载下均能保持稳定性能,成为云原生数据仓库场景下更具普适性的选择。
2.2 分层架构:模块化与演进能力
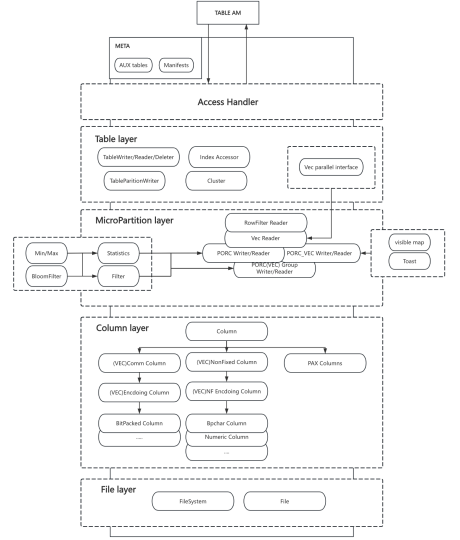
PAX 的内部实现采用严格的分层设计,以模块化和可扩展性为核心目标。其架构由五个主要层次组成:
Access Handler 层:负责与 Cloudberry 的 AM(Access Method)接口交互,处理事务上下文、异常转换及资源生命周期管理。 Table Layer 层:提供表级别的读写接口,兼容行式与向量化执行模式,是执行器与存储引擎之间的关键桥梁。 MicroPartition Layer 层:管理文件与 Group(Stripe)级的数据分布,同时对应逻辑块(Block)的存储单元组织,负责统计信息生成与过滤逻辑,是性能优化的核心。 Column Layer 层:在内存中抽象列数据结构,负责数据的编码、解码和内存对齐,确保高效的数据传输与访问。 File Layer 层:封装底层文件系统接口,负责数据文件、元数据及可见性映射(Visimap)的持久化管理。
这一分层模型使得 PAX 的各组件职责边界清晰,层间依赖最小化,为未来的功能增强(如多线程向量化、分布式事务支持)提供了良好的扩展空间。
2.3 元数据管理
PAX 的元数据由辅助表(基于 Heap AM)维护,每个物理数据文件对应辅助表中的一条记录。该设计使引擎能够快速定位数据文件、跟踪文件生命周期并进行事务可见性判断。 辅助表主要字段说明:
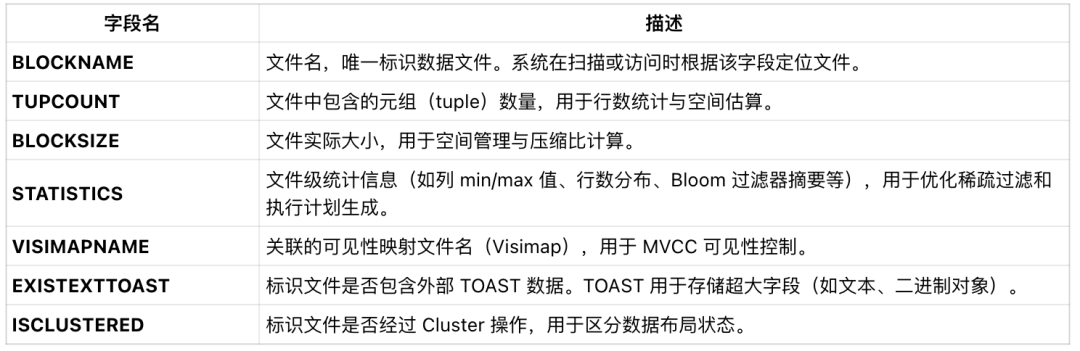
此外,系统维护一个全局 fast sequence 表,用于生成唯一的 BLOCKNAME
,保证跨节点、跨事务的文件命名唯一性,是 Visimap 与数据文件关联的核心基础。
2.4 MVCC 与 Visimap:文件级可见性控制
在传统 PostgreSQL 中,MVCC(多版本并发控制)通过行级版本控制实现高并发访问。但在对象存储场景下,频繁的行级版本操作会带来巨大的 I/O 与元数据维护成本。 PAX 对 MVCC 机制进行了重构,提出了基于文件级的可见性控制模型。 每当事务修改文件内容时,系统会生成对应的可见性映射文件(Visimap),命名规则为 <blocknum>_<generation>_<tag>.visimap
:
blocknum:对应数据文件编号; generation:文件修改代数,每次删除或更新操作都会递增; tag:事务唯一标识,用于保证 visimap 文件名全局唯一。
通过该机制,事务在读取数据时仅需判断对应的 visimap 文件即可确定可见数据范围,从而实现无锁的并发读,以及读写之间的无竞争访问。
2.5 PORC_VEC:直存格式的性能突破
在传统执行模型中,数据在读取后需要被转换为向量化执行器可接受的结构,这一过程通常包括空值判断、必要的解压缩或转码操作。由于传统存储格式仅为空值记录标志位,实际数据需要逐行复制到新的缓冲区以重构向量化执行器所需的列式布局,因此会消耗大量 CPU 和内存带宽。而 porc_vec 的设计目的正是为了避免或减少这一转换过程中的复制开销。
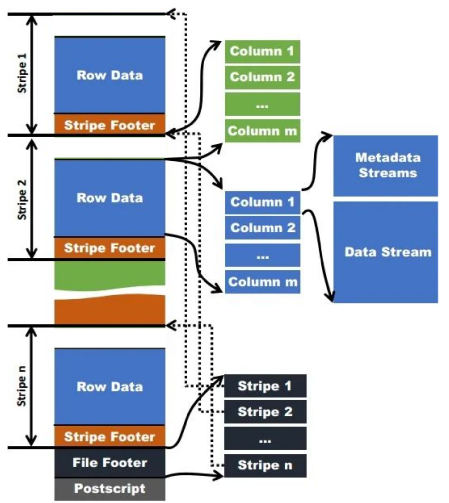
PORC_VEC(PostgreSQL ORC Vectorized)
直存格式具备以下特性:
零拷贝访问:执行器可直接读取列向量数据,无需中间转换。 内存对齐优化:数据块按向量边界对齐,提高 CPU 缓存命中率。 统一元信息结构:与 PAX 的 Column 抽象结构一一对应,减少元数据解析成本。
2.6 Column 结构设计
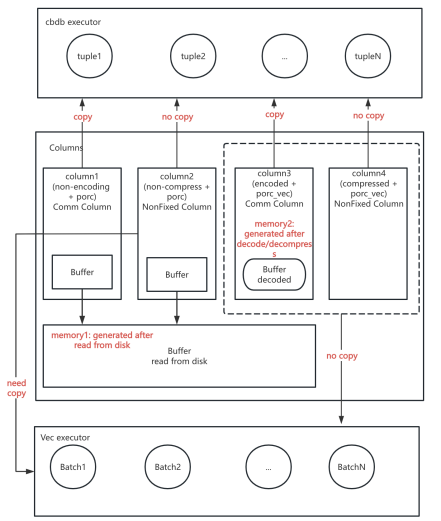
Column 是 PAX 在内存中用于表示列数据的核心结构。它提供从磁盘到内存的双向映射与格式转换机制,是连接执行引擎与文件系统的重要中间层。 主要特性如下:
磁盘数据映射:Column 负责加载磁盘上的列数据至内存结构,并在写入时将内存数据持久化回磁盘。 格式转换机制:支持在读写过程中进行数据格式转换,保证磁盘与内存布局的一致性与高效传输。 编码与压缩支持:集成多种编码与压缩算法(RLEv2、字典压缩、ZSTD 等),在保证查询性能的同时显著降低存储成本。 灵活访问接口: 行级读写接口:用于事务型操作(逐行处理)。 批量读写接口:用于分析型查询(批量处理)。 内存对齐与复合类型优化: 内存布局遵循 CPU 缓存对齐策略,提升访问性能; 对复合类型(如数组、范围类型)采用独立对齐与偏移控制,提高解析效率。
03 性能支点:PAX 的四个关键机制
PAX 的演化不是源于抽象设计,而是对真实性能瓶颈的系统性优化。每一项机制的引入,都针对具体的云场景问题提出可验证的解决方案。以下四个方面,是其在架构稳定性与性能表现上的关键支点。
3.1 稀疏过滤(Sparse Filter):最小化无效扫描
PAX 在文件级与 Stripe(组)级维护多维统计信息,包括最小值、最大值以及布隆过滤器(Bloom Filter)摘要。
在查询阶段,执行引擎可在正式扫描前基于这些统计信息快速判断文件是否可能命中查询条件,从而提前跳过不相关的数据块。
例如,当执行 WHERE age < 18
时,若某个 Group 的最小值大于 18,则该数据块会在扫描前直接被排除。结合 Bloom Filter 的精确排除机制,整体 I/O 请求量平均可降低 60% 以上。
当表数据经过 Cluster 排序(如按时间戳或地理区域字段)后,数据分布的局部性进一步增强,稀疏过滤命中率显著提升。
这一机制使 PAX 即使在“对象存储 + 宽表 + 高并发”场景下,也能维持接近内存级的查询延迟。
3.2 Cluster 与物理布局优化:从文件组织开始提升查询性能
在传统数据库中,分区往往停留在逻辑层面;而在 PAX 中,系统会根据关键列(如时间戳、地区 ID)的最小值与最大值自动判断数据应写入的目标文件,使物理数据布局更贴近实际访问模式。
此外,PAX 提供两种 Cluster 算法,用于优化数据的物理排序,使文件内部的排列更具顺序性与空间局部性:
Z-Order 排序:将多维数据映射为一维空间序列,提升范围查询(尤其是多维过滤条件)的定位效率。 Lexical 排序:按照多列的字典序对数据排序。其核心优化点在于能够快速过滤第一列的数据;仅当第一列匹配时,才进一步比较第二列,以此类推,从而加速多列过滤场景。
经过 Cluster 处理后的文件布局在访问时更具可过滤性和局部性。查询执行器在过滤阶段能够更快定位目标文件并更高效地排除无关数据,从而减少随机 I/O 与无效扫描。
这种自底向上的物理布局优化,使数据在进入查询流程之前就具备更高的“读友好性”,在存储层面便开始为整体查询性能加速。
3.3 向量化与直存格式:释放计算资源
Cloudberry 的执行层原生支持向量化,但早期列存格式在加载阶段需要进行数据重组与格式转换,导致 CPU 与内存带宽被额外消耗。
PAX 在设计阶段即同步考虑了这一问题,引入了 PORC_VEC 直存格式,使数据在磁盘上即以向量化布局存储。 该设计带来了三项直接优化:
数据读取后可直接被执行层使用,无需额外格式转换; 每列在内存中以向量结构表示,可按批(batch)处理; 与向量化执行引擎接口保持一致,消除重复拷贝与解码步骤。
3.4 内存管理体系的迭代与稳定化
内存管理是 PAX 架构中最复杂且影响性能的部分之一。 在开发早期,系统经历了三次主要演进:
阶段一:裸指针 + malloc/free —— 手工管理简单直接,但在并发下易导致内存泄漏与碎片化。
阶段二:重载全局 new/delete 与 Memory Context 集成 —— 提升了资源可控性,但影响调试工具兼容性,且不适合多线程场景。
阶段三:智能指针与线程复用池模型 —— 当前采用方案。通过将 unique_ptr shared_ptr 与专用的内存资源管理器结合使用,实现了 C++ 对象与内存块的安全管理。无论执行路径处于向量化扫描逻辑,还是在 C 语言环境中由于错误而提前退出,内存资源管理器都能确保 PAX 所分配的 C++ 内存及相关资源被正确释放,从根源上避免资源泄漏。
该体系使 PAX 能在多线程向量化扫描场景下保持稳定内存占用,避免上下文错乱与资源悬挂问题。这一改进为后续在云环境中的大规模并行执行提供了可靠的内存基础。
04 基准测试结果:结构优化带来的量化收益
为验证其在真实场景下的表现,团队在 1TB 规模的 TPC-H 与 TPC-DS 基准测试上,对比了 PAX 与传统 AOCS 引擎的执行效率。 https://github.com/apache/cloudberry/blob/main/contrib/pax_storage/doc/performance.md
测试环境
数据规模:1 TB 节点数量:5 CPU:96 核 Intel® Xeon® Platinum 8275CL @ 3.00GHz 内存:192 GB 存储:4TB SSD(IOPS 10000,带宽 500MB/s) 对比方案:PAX 与 AOCS(batch size = 32K)
测试结果概览
在相同查询计划与执行条件下,PAX 在 TPC-H 与 TPC-DS 两组基准测试中平均性能提升约 15%~25%。 在涉及宽表聚合、复杂过滤与多表 Join 的场景中,提升幅度最高可达 40%。 性能改进主要得益于以下三方面:
I/O 模型优化 PAX 的稀疏过滤机制与 Cluster 排序策略显著减少了对象存储请求次数, 实测中 I/O 请求量约为 AOCS 的一半,读放大现象明显缓解。 数据格式与 CPU 效率 直存格式(PORC_VEC)消除了执行阶段的数据拷贝与转换开销, CPU 利用率更集中在计算任务上,缓存命中率和多线程并行度显著提升。 执行稳定性 在复杂 SQL 查询(如多层嵌套 Join、Group by、Order by)中, PAX 的响应时间波动明显低于 AOCS,性能更线性、可预测。
05 结语
在 Apache Cloudberry 团队眼中,PAX 不只是一个技术项目,而是一种工程哲学的回归。它没有追逐“炫技”的算法,而是扎根于真实的云场景。PAX 的未来路线也清晰而坚定:
Delta 支持:优化小批量更新与增量写入; 优化器联动:实现无 Sort-Merge Join 的新执行计划; 更深度的向量化:利用 SIMD 加速批量计算; 智能统计采集:让引擎能自我学习和调整。
加入社区,共建未来
GitHub: https://github.com/apache/cloudberry 官网: https://cloudberry.apache.org 邮件列表: dev@cloudberry.apache.org Slack: https://inviter.co/apache-cloudberry
👇🏻️扫码加入 Apache Cloudberry 交流群👇🏻️

