





一、引言
1.1 技术背景
在数字化转型加速的当下,企业数据呈现爆炸式增长,数据处理与 AI 分析的协同需求日益迫切。传统方案中,数据需从数据库导出至外部机器学习平台进行训练与推理,存在三大核心痛点:一是数据跨平台传输引发的安全泄露风险;二是数据搬迁导致的端到端延迟,无法满足实时分析诉求;三是依赖多工具协同,要求用户同时掌握 SQL 与 Python 等多种技术,使用门槛高。
为解决上述问题,数据库内生 AI 技术应运而生,其核心思路是将机器学习算子、模型管理能力直接集成至数据库内核,利用数据库的资源调度、并发处理、数据管理优势,实现全流程库内 AI 训练与推理。目前业界主流方案包括 SQL UDF 扩展、SQL 语句扩展 + 外部平台协同等,但均存在性能或安全短板。移动云海山数据库(He3DB)基于 “存算一体、AI 内生” 设计理念,研究全栈自主的库内训推一体化架构,为企业提供高效、安全、易用的智能化数据处理解决方案。
1.2 核心目标
He3DB 库内训推技术的核心目标包括:
- 数据安全隔离:实现训练与推理全流程数据不出库,避免跨平台传输风险;
- 高效实时响应:利用数据库并发计算与异构算力调度能力,降低训推延迟;
- 极致易用体验:基于SQL-Centric范式,无需额外工具,通过标准SQL语句完成AI全流程操作;
- 灵活扩展适配:支持内置算法与自定义模型,适配分类、回归、聚类、大模型推理等多种需求;
- 可靠模型管理:提供模型全生命周期管理,保障模型一致性与可用性。
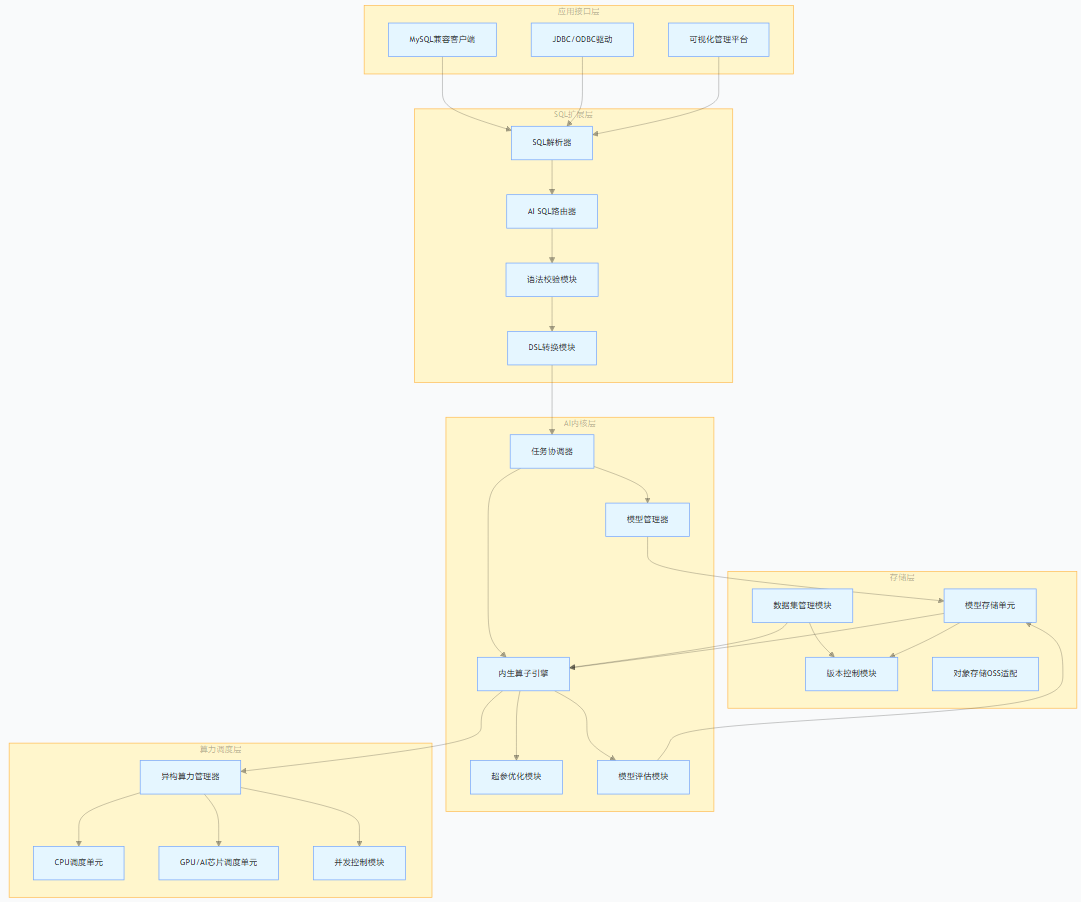
二、He3DB 库内训推技术架构设计
He3DB 采用 “五层架构” 设计,从下至上依次为存储层、算力调度层、AI 内核层、SQL 扩展层、应用接口层,各层协同实现库内训推全流程闭环。架构框图如下:
2.1 存储层:数据与模型的安全可靠管理
存储层是库内训推的基础,负责数据集与模型的全生命周期存储与管理,核心能力包括:
- 数据集管理:支持从单表或多表抽取列信息组建训练数据集,采用类 Git 的多版本控制机制,保障训练数据一致性;提供数据清洗、特征处理内置功能,自动过滤无效数据、补齐缺失值,提升数据可用性。
- 模型存储管理:将训练完成的模型文件(含算法参数、训练日志、评估结果)持久化至对象存储 OSS,同时在系统表中记录模型元数据(模型名称、算法类型、状态、创建时间等);支持模型导入、导出、定期验证与漂移检测,当模型性能下降时自动触发刷新机制。
- 安全隔离设计:数据集与模型文件均通过数据库权限体系进行访问控制,仅授权用户可执行训练、推理、模型查看等操作,避免数据泄露。
2.2 算力调度层:异构算力的高效协同
He3DB 针对不同 AI 任务的算力需求,构建了统一的异构算力调度层,实现 CPU 与专用 AI 芯片(GPU、昇腾等)的协同调度:
- 算力资源适配:CPU(X86/ARM 架构)负责基础机器学习算子计算、并行任务分发等轻量级操作;GPU/AI 芯片负责深度学习模型训练、大规模聚类、复杂特征工程等重度计算任务,通过硬件加速提升处理效率。
- 智能调度策略:基于任务类型与数据规模自动匹配最优算力资源,例如小规模数据集的逻辑回归训练优先使用 CPU,大规模图像数据的特征提取优先调度 GPU;支持算力动态扩容,应对突发训推需求。
- 并发控制优化:复用数据库成熟的并发控制机制,通过锁机制与事务管理,避免多用户同时训推导致的资源冲突,保障任务执行稳定性。
2.3 AI 内核层:训推能力的核心实现
AI 内核层是 He3DB 库内训推的核心,集成内生算子引擎、任务协调、模型管理等关键模块,实现 AI 能力与数据库内核的深度融合:
- 内生算子引擎:内置丰富的机器学习算子,涵盖分类算法(逻辑回归、XGBoost、LightGBM)、回归算法(线性回归、梯度下降)、聚类算法(KMeans、PCA)等,算子设计遵循数据库执行器逻辑,下层对接 Scan 算子获取数据,上层输出训推结果,与 Join、AGG 等传统算子无缝协同。
- 任务协调器:作为 AI 内核的 “大脑”,负责解析 SQL 语句参数、生成训推任务描述、投递任务至目标算力节点,并通过系统表实时记录任务状态(loading_data→training→saved→ready);支持异步任务调度,避免长时训推阻塞数据库核心业务。
- 超参优化模块:用户无需手动指定超参数或仅需设定参数范围,系统基于数据特征与算法特性自动搜索最优超参数组合,平衡训练效率与模型性能;支持用户自定义超参数优先级,适配特定业务场景需求。
- 模型评估与管理:训练完成后自动生成模型评估报告(含准确率、召回率、F1 值、均方误差等指标);支持模型版本回溯,用户可基于历史版本重新训练或对比性能;内置模型漂移检测算法,定期校验模型与新数据的适配性,触发模型更新。
2.4 SQL 扩展层:易用性的关键支撑
He3DB 采用 SQL-Centric 设计范式,在兼容标准 MySQL 协议的基础上扩展 AI 专用语法,用户无需学习 Python SDK 或外部工具,仅通过 SQL 即可完成全流程操作:
- 语法扩展设计:通过/*he3ai*/注释前缀标识 AI 相关 SQL 语句,例如创建模型、推理预测等,该语法在普通数据库中被识别为注释,确保兼容性;支持CREATE MODEL(创建模型)、PREDICT BY(推理预测)、SHOW MODELS(查看模型)等核心指令。
- 智能解析路由:SQL 解析器通过识别/*he3ai*/前缀,将 AI 任务路由至 AI 内核层处理,非 AI SQL 则按标准数据库流程执行,实现业务与 AI 任务的隔离处理。
- 语法校验与适配:内置语法校验模块,自动检查特征列、标签列、算法类型等参数的合法性;支持动态适配不同算法的参数要求,降低用户使用门槛。
2.5 应用接口层:多场景的便捷接入
应用接口层提供多样化的接入方式,满足不同用户的使用需求:
- 兼容传统客户端:支持 MySQL 官方客户端、Navicat 等第三方工具接入,用户可直接通过 SQL 终端执行 AI 操作;
- 标准化驱动支持:提供 JDBC/ODBC 驱动,方便 Java、Python 等编程语言开发的应用系统集成;
- 可视化管理平台:提供 Web 端可视化界面,支持数据集创建、模型训练监控、推理结果查看、模型版本管理等操作,降低非技术人员使用门槛。
三、核心技术创新点
3.1 全流程数据不出库,安全与效率双重保障
He3DB 通过 “数据 - 模型 - 推理” 全流程库内闭环设计,彻底避免数据跨平台传输:训练数据直接从数据库表抽取,通过内部 RPC 与共享存储供 AI 节点访问,无需导出至外部文件;模型文件存储于数据库关联的 OSS 中,推理时直接加载至算力节点,结果实时写入数据库表或返回给用户。该设计不仅消除了数据泄露风险,还减少了数据传输延迟,端到端训推效率较传统方案提升 30% 以上。
3.2 内生算子与数据库内核深度协同
不同于基于 UDF 或外部平台的集成方案,He3DB 的 AI 算子完全内生嵌入数据库执行器,与传统数据处理算子共享资源调度、并发控制、优化器等核心能力:优化器可基于数据分布统计信息与 AI 算子执行代价(数据量、算法复杂度)生成最优执行计划,支持通过EXPLAIN语句查看训推流程开销;算子执行过程中复用数据库的并行计算框架,支持大规模数据的分片并行训推,训练效率较单线程方案提升 5倍。
3.3 异构算力智能调度,适配多场景需求
He3DB 构建了统一的算力调度框架,实现 CPU 与 GPU/AI 芯片的无缝协同:通过任务类型自动匹配算力资源,例如轻量级逻辑回归训练优先使用 CPU 集群,深度学习模型 Fine-Tune 调度 GPU 资源;支持算力弹性扩容,基于业务负载动态调整资源分配,避免算力浪费;针对大模型推理场景,优化 GPU 显存管理,支持模型并行与数据并行,提升大规模并发推理吞吐量。
3.4 大模型轻量化集成,拓展应用边界
He3DB 内置Qwen,DeepSeek等大模型适配器,将大模型能力封装为数据库内生模型,用户可通过 SQL 语句直接调用情感分析、文本摘要、翻译、向量转换等功能。例如,通过PREDICT BY _he3ai_LLM_sentiment语句可实现文本情感分析,无需关注大模型部署与调用细节。大模型推理结果实时写入数据库表,支持与结构化数据联合查询,拓展智能化分析场景。
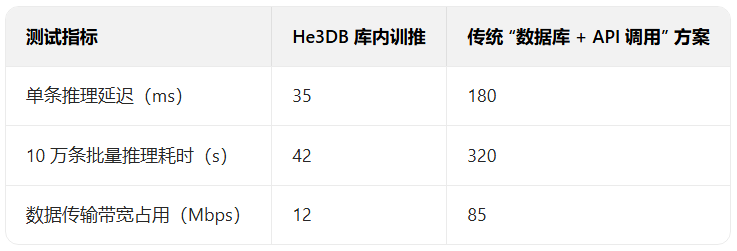
四、性能验证与测试结果
为验证 He3DB 库内训推技术的性能优势,基于公开数据集与模拟业务场景进行测试,测试环境如下:
- 硬件配置:CPU(Intel Xeon 8375C 2.9GHz,32 核)、GPU(NVIDIA A100 40GB)、内存 128GB、SSD 存储 2TB;
- 测试数据集:文本数据集(新闻评论数据集,500 万条文本);
- 对比方案:传统 “数据库 + Python sklearn” 方案。
基于新闻评论数据集调用情感分析模型,测试结果如下表:
五、应用场景与实践价值分析
5.1 核心应用场景
- 金融风控领域:基于用户交易数据(存储于 He3DB),通过库内训推构建欺诈检测模型,实时识别异常交易;支持模型定期自动更新,适配新型欺诈手段。
- 电商推荐领域:利用用户浏览、下单等行为数据,训练个性化推荐模型,通过库内推理实时生成推荐结果,无需数据导出至推荐平台,提升推荐响应速度。
- 工业质检领域:工业设备传感器数据实时写入 He3DB,通过库内训练的异常检测模型,实时识别设备故障风险,生成预警信息,保障生产连续性。
- 文本智能分析:企业客户评论、客服对话等文本数据存储于 He3DB,通过内置大模型能力实现情感分析、关键词提取、文本摘要,支持结构化数据与文本分析结果联合查询,辅助业务决策。
5.2 实践价值
- 降低技术门槛:SQL-Centric 设计让非 AI 专业的开发人员、数据分析师可直接使用 AI 能力,推动智能化技术的普惠应用。
- 降低部署成本:无需搭建独立的机器学习平台,减少硬件投入与运维成本;数据不出库设计降低数据安全合规成本。
- 提升业务响应速度:全流程库内处理大幅缩短训推延迟,满足实时性业务需求,提升用户体验与业务竞争力。
- 保障数据安全:避免数据跨平台传输与泄露风险,符合《数据安全法》《个人信息保护法》等合规要求。
六、总结与展望
He3DB 库内训推一体化技术通过 “五层架构” 设计,实现了机器学习能力与数据库内核的深度融合,解决了传统方案中数据安全、实时性、易用性等核心痛点。其核心优势体现在全流程数据不出库、内生算子高效协同、异构算力智能调度、SQL 化易用接口等方面,通过性能测试验证了其在训推效率、资源占用、响应延迟等指标上的显著优势,已在金融、电商、工业等多个领域具备实践价值。
未来,He3DB 库内训推技术将从三个方向持续演进:一是拓展大模型集成能力,支持更多开源与自定义大模型,优化大模型推理的显存占用与速度;二是深化自动化能力,实现数据集自动划分、特征自动工程、模型自动选择的端到端智能分析;三是加强跨集群协同,支持分布式训推与多租户资源隔离,适配更大规模数据与更复杂的业务场景,为企业数字化转型提供更强大的智能化数据处理支撑。

