




Part1环境背景
| 环境 | 项目 | 数据库 |
|---|---|---|
| 生产 | 流程 | Ora19.29 Rac |
| 预生产 | 流程 | Ora19.29 Rac |
Part1问题定位
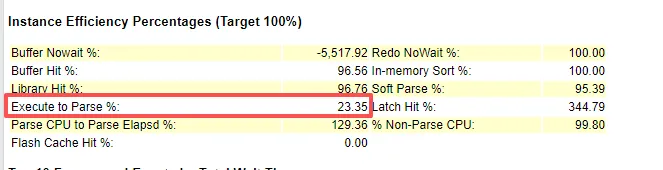
解析问题太过严重,尤其是硬解析占比也较大
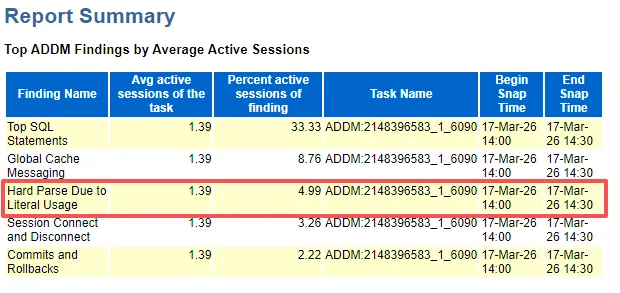 硬解析占比较高
硬解析占比较高
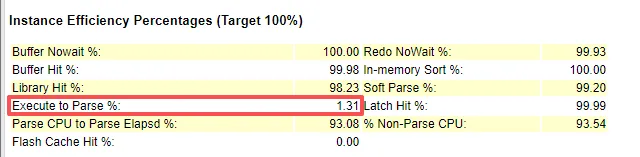 几乎是执行一次解析一次
几乎是执行一次解析一次
 几乎是执行一次解析一次
几乎是执行一次解析一次
 触发约束只有在DML中的(Update和Insert)才会触发,毕竟删除(Delete不会在乎你约束)查询(Select)也不会在乎约束。
触发约束只有在DML中的(Update和Insert)才会触发,毕竟删除(Delete不会在乎你约束)查询(Select)也不会在乎约束。
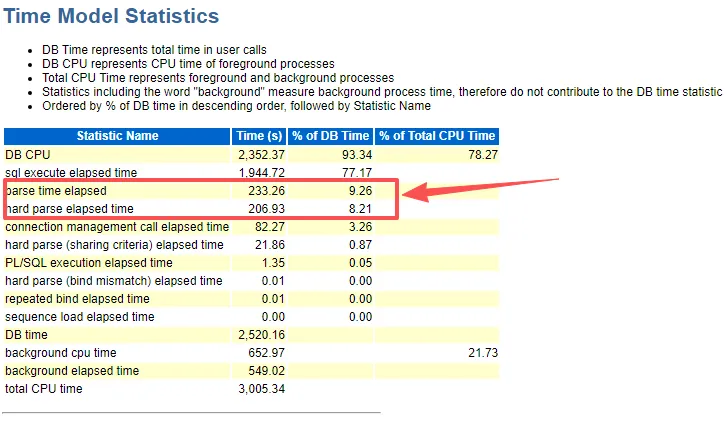 解析时间占比9.26%,
硬解析时间8.21%
解析时间占比9.26%,
硬解析时间8.21%
Part3解决步骤
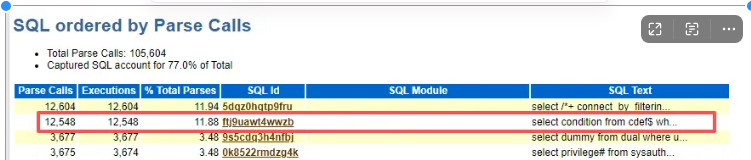
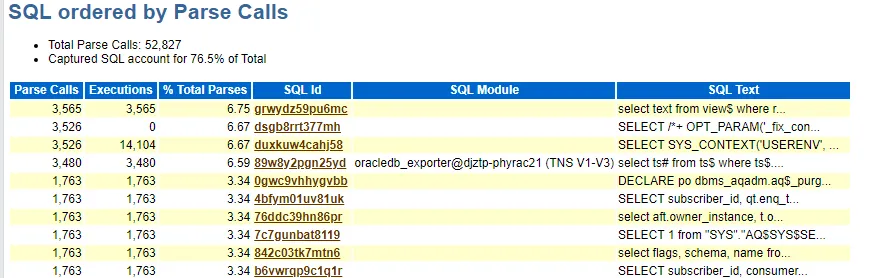
3.1、定位导致解析严重的SQL
SQL ordered by Parse Calls
242,430次
select condition from cdef$ where rowid=:1
76,793次
INSERT INTO FLOW_DATA(FLOW_ID, OBJ_GUID, OP_GUID, TASK_ADD_KEY, TASK_ADD_CDATA, TASK_ADD_NDATA, TASK_ADD_DATE) VALUES (:1 , :2 , :3 , :4 , :5 , :6 , to_date(:7 , 'yyyymmddhh24miss'))
就找了前两个,因为排名第一的次数 >= 第二名、第三名、第四名、第五名的总和
而且发现不管是第一条还是第二条都有绑定变量,但是还是执行一次解析一次
这有两种可能
一种是绑定变量的具体数值不是一样的长度,所以虽然是软解析,但是还是执行一次就需要解析一次
另一种可能是某些参数不适用,范围太小,导致了解析,这些参数可能包括shared_pool_size、open_cursors以及session_cached_cursors等
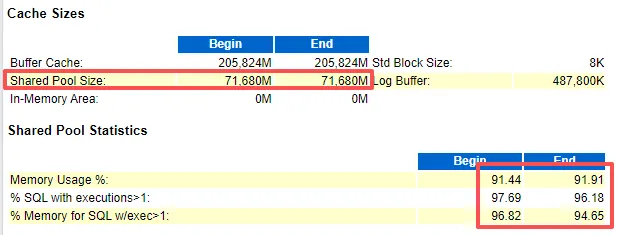 共享池的数值没有变化
共享池的数值没有变化
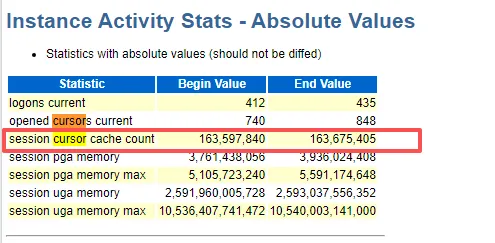 这里其实画错了,看 opened cursors current就行
这里其实画错了,看 opened cursors current就行
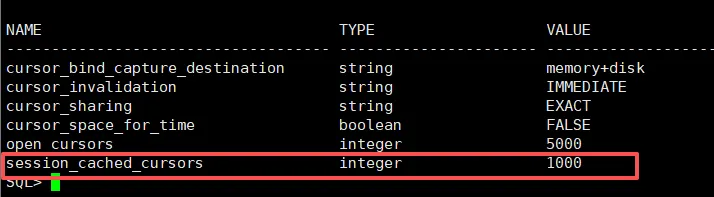 参数是1000
参数是1000
set lin 2000;
column parameter format a29;
column value format a5;
column usage format a40;
select 'session_cached_cursors' parameter,
lpad(value, 5) value,
decode(value, 0, 'n/a', to_char(100 * used / value, '999990') || '%') usage
from (select max(s.value) used
from sys.v_$statname n, sys.v_$sesstat s
where n.name = 'session cursor cache count'
and s.statistic# = n.statistic#),
(select value
from sys.v_$parameter
where name = 'session_cached_cursors')
union all
select 'open_cursors',
lpad(value, 5) value,
to_char(100 * used / value, '990') || '%'
from (select max(sum(s.value)) used
from sys.v_$statname n, sys.v_$sesstat s
where n.name in
('opened cursors current', 'session cursor cache count')
and s.statistic# = n.statistic#
group by s.sid),
(select value from sys.v_$parameter where name = 'open_cursors');
PARAMETER VALUE USAGE
----------------------------- ----- ------------
session_cached_cursors 1000 33%
open_cursors 5000 7%
有个大哥说 ,数据库参数,先记一下
open_cursors : session_cached_cursors = 3:1
从以上推断,数据库参数没有什么可以整改的地方
3.2、系统表cdef$的查询是为了什么(long)
select condition from cdef$;
"MDL_ID" IS NOT NULL
"UNIT_DCT" IS NOT NULL
"F_UNIT" IS NOT NULL
"F_GUID" IS NOT NULL
"FLOW_BH" IS NOT NULL
"FLOW_MC" IS NOT NULL
"FLOW_SYS" IS NOT NULL
"FLOW_OP_TYPE" IS NOT NULL
"FLOW_DATE_TYPE" IS NOT NULL
"F_STAU" IS NOT NULL
"F_CRDATE" IS NOT NULL
15516 rows selected.
只截取了其中的部分数据,共 15516 行。
set long 2000000000 echo off feedback off heading off pagesize 0 linesize 30000 trimout on wrap on trimspool on termout off serveroutput off SQLPROMPT "SQL>"
spool /tmp/cdef.sql
set pages 999 lines 999
select condition from cdef$;
spool off
这个查询与表的约束有直接关系。cdef$是Oracle数据字典表,用于存储约束的定义信息,其中的condition列存放了约束的具体条件(如检查约束的表达式、外键引用关系等)。通过rowid定位到特定行,可以获取某个约束的详细定义。因此,该查询本质上是访问约束元数据,与表的约束密切相关。不过,执行这个查询本身并不触发对用户表数据的约束验证,只是读取数据字典中的约束定义。
简单来说就是DML的添加和更改每次都需要查询一下这个表的涉及修改的列是否有约束
3.3、约束的定义是什么(非空?)
在 Oracle 数据库中,约束(Constraint) 是用来确保表中数据的完整性和一致性的规则。
当你在列或表上定义约束后,数据库会自动检查所有对数据的修改(插入、更新、删除)是否符合这些规则,不符合的操作将被拒绝。
1. NOT NULL 约束(非空约束)
2. UNIQUE 约束(唯一约束)
3. PRIMARY KEY 约束(主键约束)
4. FOREIGN KEY 约束(外键约束)
5. CHECK 约束(检查约束)
3.4、如何查找这些引起约束的表(解析排序或者db改变最多的表)
SELECT TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24') SNAP_TIME,
DHSO.OBJECT_NAME,
SUM(DB_BLOCK_CHANGES_DELTA) BLOCK_CHANGED
FROM DBA_HIST_SEG_STAT DHSS,
DBA_HIST_SEG_STAT_OBJ DHSO,
DBA_HIST_SNAPSHOT DHS
WHERE DHS.SNAP_ID = DHSS.SNAP_ID
AND DHS.INSTANCE_NUMBER = DHSS.INSTANCE_NUMBER
AND DHSS.OBJ# = DHSO.OBJ#
AND DHSS.DATAOBJ# = DHSO.DATAOBJ#
AND BEGIN_INTERVAL_TIME BETWEEN TO_DATE('2026-03-17 14:00',
'YYYY-MM-DD HH24:MI')
AND
TO_DATE('2026-03-17 14:30', 'YYYY-MM-DD HH24:MI')
GROUP BY TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24'),
DHSO.OBJECT_NAME
HAVING SUM(DB_BLOCK_CHANGES_DELTA) > 0
ORDER BY SUM(DB_BLOCK_CHANGES_DELTA) DESC;
SNAP_TIME OBJECT_NAME BLOCK_CHANGED
-------------- ------------------------- ------------------
2026-03-17 14 FLOW_DATA 1262736
2026-03-17 14 FLOW_DATA_INX2 1125776
2026-03-17 14 FLOW_DATA_INX3 1063296
SELECT TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY_MM_DD HH24') WHEN,
DBMS_LOB.SUBSTR(SQL_TEXT, 4000, 1) SQL,
DHSS.INSTANCE_NUMBER INST_ID,
DHSS.SQL_ID,
EXECUTIONS_DELTA EXEC_DELTA,
ROWS_PROCESSED_DELTA ROWS_PROC_DELTA
FROM DBA_HIST_SQLSTAT DHSS, DBA_HIST_SNAPSHOT DHS, DBA_HIST_SQLTEXT DHST
WHERE UPPER(DHST.SQL_TEXT) LIKE '%FLOW_DATA%'
AND LTRIM(UPPER(DHST.SQL_TEXT)) NOT LIKE 'SELECT%'
AND DHSS.SNAP_ID = DHS.SNAP_ID
AND DHSS.INSTANCE_NUMBER = DHS.INSTANCE_NUMBER
AND DHSS.SQL_ID = DHST.SQL_ID
AND BEGIN_INTERVAL_TIME BETWEEN
TO_DATE('2026-03-17 14:00', 'YYYY-MM-DD HH24:MI') AND
TO_DATE('2026-03-17 14:30', 'YYYY-MM-DD HH24:MI');
WHEN SQL INST_ID SQL_ID EXEC_DELTA ROWS_PROC_DELTA
-------------------------- --------------------------------------- ---------- -------------------------- ---------- ---------------
2026_03_17 14
INSERT INTO FLOW_DATA(FLOW_ID, OBJ_GUID, OP_GUID, TASK_ADD_KEY, TASK_ADD_CDATA, TASK_ADD_NDATA, TASK_ADD_DATE) VALUES (:1 ,:2 ,:3 ,:4 ,:5 ,:6 ,to_date(:7 ,'yyyymmddhh24miss'))
2 7mfbry7xf557w 92464 466584
2026_03_17 14
delete from FLOW_DATA where OBJ_GUID = :1 AND TASK_ADD_KEY <> :2 AND TASK_ADD_KEY <> :3
2 a10bvsk3k6mgk 3054 311434
2026_03_17 14
INSERT INTO FLOW_DATA(FLOW_ID, OBJ_GUID, OP_GUID, TASK_ADD_KEY, TASK_ADD_CDATA, TASK_ADD_NDATA, TASK_ADD_DATE) VALUES (:1 ,:2 ,:3 ,:4 ,:5 ,:6 ,to_date(:7 ,'yyyymmddhh24miss'))
1 7mfbry7xf557w 90729 448921
2026_03_17 14
delete from FLOW_DATA where OBJ_GUID = :1 AND TASK_ADD_KEY <> :2 AND TASK_ADD_KEY <> :3
1 a10bvsk3k6mgk 3102 318914
INSERT INTO FLOW_DATA(FLOW_ID, OBJ_GUID, OP_GUID, TASK_ADD_KEY, TASK_ADD_CDATA, TASK_ADD_NDATA, TASK_ADD_DATE) VALUES (:1 ,:2 ,:3 ,:4 ,:5 ,:6 ,to_date(:7 ,'yyyymmddhh24miss'))
涉及表分开查看他的创建语句
FLOW_TASK ADD_DATA 这表看下表结构,有没有加约束
=====================生产
-- Create table
create table FLOW_DATA
(
flow_id VARCHAR2(30) not null,
obj_guid VARCHAR2(60) not null,
op_guid VARCHAR2(30) not null,
task_add_key VARCHAR2(256) not null,
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX on FLOW_DATA (OP_GUID, FLOW_ID, OBJ_GUID);
create index FLOW_DATA_INX2 on FLOW_DATA (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3 on FLOW_DATA (OBJ_GUID, TASK_ADD_KEY);
3.5、能否查到cdef$的绑定值
抓取已执行的目标SQL中的绑定变量的数值
ftj9uawt4wwzb
select condition from cdef$ where rowid=:1
SELECT snap_id,
MAX(CASE WHEN position = 1 THEN value_string END) AS bind1
FROM dba_hist_sqlbind
WHERE sql_id = 'ftj9uawt4wwzb'
GROUP BY snap_id
ORDER BY snap_id;
cdef$:这是 Oracle 核心的内部数据字典表(Constraint Definition),专门用来存储数据库中所有**约束(Constraints)**的元数据。
是不是表的字段定义有check 约束,在频繁进行dml操作引起。
说是只能10056,但是也没成功
3.6、如何做实验确定或者优化
我们要把这个操作及其频繁的表进行优化,把约束去掉,询问了开发,可以在前台设置非空约束,
在这个前提下,我们找个测试库把实验分为三步,1把约束表插入约束表、2把约束表插入非约束表、3把非约束表插入非约束表
Part4实验
1、查询生产库表的表结构 2、将生产表复制到预生产 3、预生产分别创建 FLOW_DATA_TEST(目的表)和 FLOW_DATA_TEST_A(源表)
=====================生产
-- Create table
create table FLOW_DATA
(
flow_id VARCHAR2(30) not null,
obj_guid VARCHAR2(60) not null,
op_guid VARCHAR2(30) not null,
task_add_key VARCHAR2(256) not null,
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX on FLOW_TASK_ADD_DATA (OP_GUID, FLOW_ID, OBJ_GUID);
create index FLOW_DATA_INX2 on FLOW_TASK_ADD_DATA (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3 on FLOW_TASK_ADD_DATA (OBJ_GUID, TASK_ADD_KEY);
=====================预生产
-- Create table
create table FLOW_DATA
(
flow_id VARCHAR2(30) not null,
obj_guid VARCHAR2(60) not null,
op_guid VARCHAR2(30) not null,
task_add_key VARCHAR2(256) not null,
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX on FLOW_DATA (OP_GUID, FLOW_ID, OBJ_GUID);
create index FLOW_DATA_INX2 on FLOW_DATA (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3 on FLOW_DATA (OBJ_GUID, TASK_ADD_KEY);
===============================实验(目的)
-- Create table
create table FLOW_DATA_TEST
(
flow_id VARCHAR2(30) not null,
obj_guid VARCHAR2(60) not null,
op_guid VARCHAR2(30) not null,
task_add_key VARCHAR2(256) not null,
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX_TEST on FLOW_DATA_TEST (OP_GUID, FLOW_ID, OBJ_GUID);
create index FLOW_DATA_INX2_TEST on FLOW_TEST (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3_TEST on FLOW_DATA_TEST (OBJ_GUID, TASK_ADD_KEY);
===============================实验(源)
-- Create table
create table FLOW_DATA_TEST_A
(
flow_id VARCHAR2(30) not null,
obj_guid VARCHAR2(60) not null,
op_guid VARCHAR2(30) not null,
task_add_key VARCHAR2(256) not null,
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX_TEST on FLOW_DATA_TEST (OP_GUID, FLOW_ID, OBJ_GUID);
create index FLOW_DATA_INX2_TEST on FLOW_DATA_TEST (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3_TEST on FLOW_DATA_TEST (OBJ_GUID, TASK_ADD_KEY);
本来使用存储过程来做实验的,但是没有模拟出来,跟领导讨论,他说是你这个存储过程其实是一个会话里完成的数据插入,虽然插入一次提交一次,但是基本的数据库前置检查只做了一次,所以最好使用sqlplus创建一个会话插入一条或者多条数据,这样才有可能模拟出问题。不愧是领导。
CREATE OR REPLACE PROCEDURE copy_data_to_test IS
CURSOR cur IS SELECT * FROM FLOW_DATA WHERE rownum <= 76793;
v_counter NUMBER := 0;
BEGIN
FOR rec IN cur LOOP
INSERT INTO FLOW_DATA_TEST VALUES rec; -- 直接使用记录插入,需要列顺序一致
v_counter := v_counter + 1;
COMMIT;
END LOOP;
DBMS_OUTPUT.PUT_LINE('插入完成,共插入 ' || v_counter || ' 行。');
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('出错: ' || SQLERRM);
RAISE;
END;
/
begin
copy_data_to_test;
end;
/
总共执行了 9 次
select count(*) from FLOW_TASK_ADD_DATA_TEST;
需要达到 76,793
虽然没满足,但是也保留起来,下回再用。
4.1、约束表插入约束表
也许我应该开四个服务器一起跑?
#!/bin/bash
# 数据库连接信息
USER="用户"
PASS="密码"
# 获取源表的前 76793 行数据的主键或 ROWID,此处以 ROWID 为例
sqlplus -s $USER/$PASS@HY2 <<EOF > rowids.txt
set pagesize 0 feedback off verify off
SELECT ROWID FROM FLOW_DATA WHERE ROWNUM <= 76793;
EOF
# 循环每一行 ROWID,单独连接插入
while read rowid; do
sqlplus $USER/$PASS@HY2 <<EOF
INSERT INTO FLOW_DATA_TEST
(flow_id, obj_guid, op_guid, task_add_key, task_add_cdata, task_add_ndata, task_add_date)
SELECT flow_id, obj_guid, op_guid, task_add_key, task_add_cdata, task_add_ndata, task_add_date
FROM FLOW_DATA
WHERE ROWID = '$rowid';
COMMIT;
EXIT;
EOF
done < rowids.txt
select count(*) from FLOW_DATA_TEST;
16:14 开始
775554
17:02结束
820111
 模拟出来了
模拟出来了
4.2、约束表(源)插入非约束表(目的)
SQL> truncate table FLOW_DATA_TEST;
修改表结构没有约束
select count(*) from FLOW_DATA_TEST;
17:10 开始
20244
17:28 结束
验证失败
当源表有约束,目的表没有约束的时候,
也会查询系统约束表 select condition from cdef$ where rownum = :1
4.3、非约束表插入非约束表
-- Create table
create table FLOW_DATA_A
(
flow_id VARCHAR2(30),
obj_guid VARCHAR2(60),
op_guid VARCHAR2(30),
task_add_key VARCHAR2(256),
task_add_cdata VARCHAR2(1530),
task_add_ndata NUMBER(26,6),
task_add_date DATE
);
-- Create/Recreate indexes
create index FLOW_DATA_INX2_A on FLOW_DATA_A (OP_GUID, OBJ_GUID, TASK_ADD_KEY, FLOW_ID);
create index FLOW_DATA_INX3_A on FLOW_DATA_A (OBJ_GUID, TASK_ADD_KEY);
create index FLOW_DATA_INX_A on FLOW_DATA_A (OP_GUID, FLOW_ID, OBJ_GUID);
INSERT INTO FLOW_DATA_A SELECT * FROM FLOW_DATA where rownum < 1000000;
commit;
修改表结构没有约束
select count(*) from FLOW_DATA_TEST;
11:05 开始
22612
11:30 结束

Part5总结
1、解析方面的优化可以先从sql绑定变量开始
2、如果抓取到的sq已经绑定变量了,那说明绑定变量的列,每次数值长度不一样,所以每次都还会软解析
3、数据库方面的优化主要是 共享池(shared_pool_size)、游标(open_cursors、session_cached_cursors) 共享池的先从awr判断是否变化Shared Pool Size,再从Shared Pool Advisory判断几倍合适 open_cursors的数值从opened cursors current判断,我简单来判断的话可以从1500设置 open_cursors:session_cached_cursors=3:1
4、这个时候SQL ordered by Parse Calls里抓取sql,具体问题具体分析了
5、以我这次举例,系统sql是因为约束,约束是因为大量插入业务表(四个非空列),业务表那改进的办法就是是否可以批量提交或者取消约束,由前端来判断插入数据是否非空
Part6Mos说法
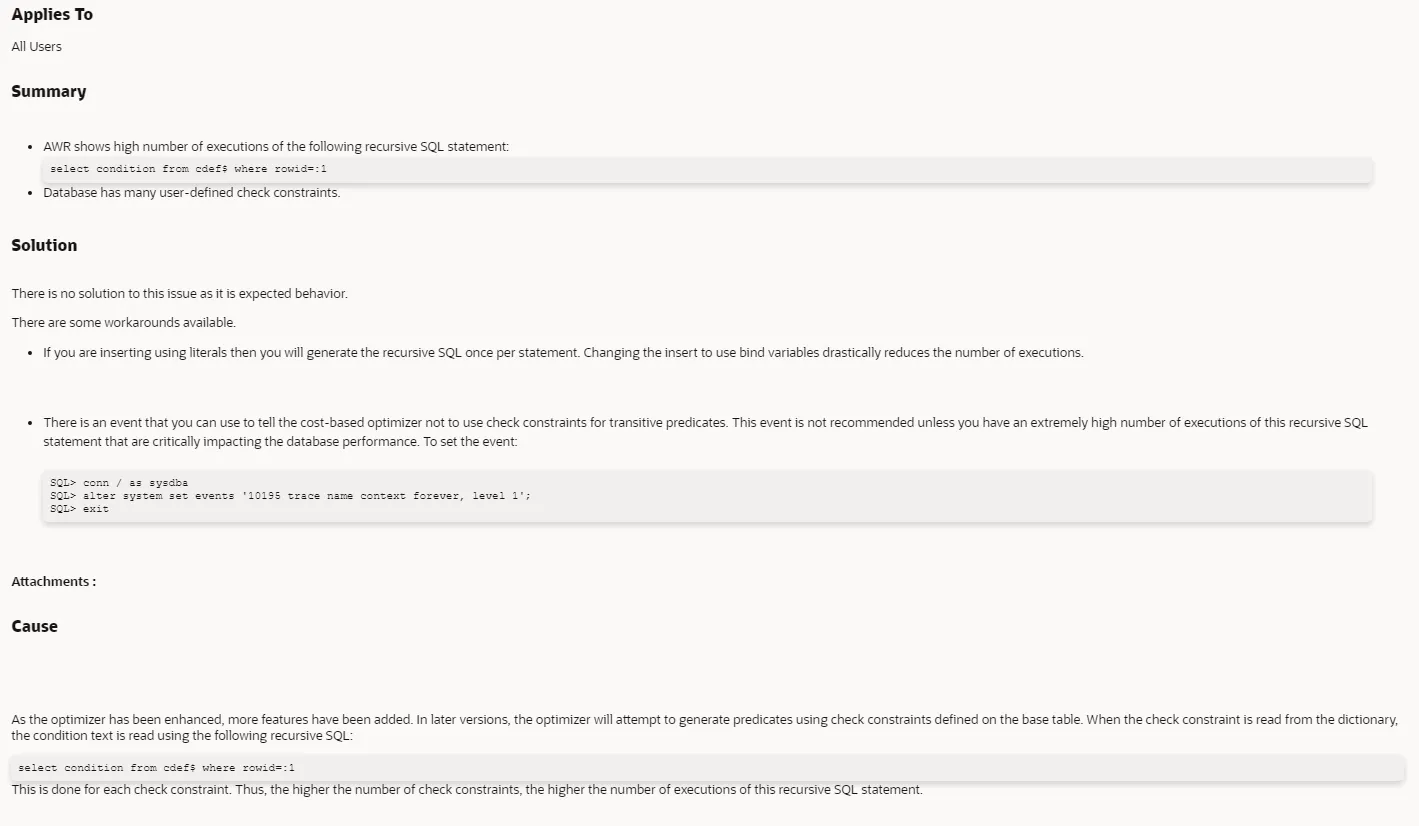
SQL> conn / as sysdba
SQL> alter system set events '10195 trace name context forever, level 1';
SQL> exit
但是这个说是有风险不敢操作
Part7用到的SQL
exec dbms_workload_repository.create_snapshot();
SELECT sql_id,
executions,
parse_calls,
sql_text,
module,
parsing_schema_name,
ROUND(executions / (parse_calls + 1), 2) AS execution_to_parse_ratio
FROM v$sql
WHERE executions > 1000 -- 执行次数大于 1000(可调整)
AND parse_calls > 0 -- 存在解析调用
AND executions / (parse_calls + 1) < 10 -- 执行与解析比值较低(表示未使用绑定变量)
ORDER BY executions DESC;
-- executions:SQL 语句的执行次数。
-- parse_calls:SQL 被解析的次数(高解析调用可能是未绑定变量的症状)。
-- execution_to_parse_ratio:执行次数与解析次数的比值,越低越可能是未绑定变量。
-- sql_text:SQL 文本,可以查看具体内容
SELECT * FROM v$sql_bind_capture WHERE sql_id = '&SQL_ID';
VALUE_STRING 最近一次捕获的绑定变量值(以字符串形式存储)。
SELECT top_level_sql_id, COUNT(*) AS hits
FROM dba_hist_active_sess_history
WHERE sql_id = 'ftj9uawt4wwzb' -- 替换成 cdef$ 的真实 SQL_ID
AND sample_time BETWEEN
TO_DATE('2026-03-12 14:00:00', 'YYYY-MM-DD HH24:MI:SS') AND
TO_DATE('2026-03-12 14:30:00', 'YYYY-MM-DD HH24:MI:SS')
GROUP BY top_level_sql_id
ORDER BY hits DESC;
查出排名第一的 top_level_sql_id 后,
再拿这个 ID 单独去 dba_hist_sqltext 表里查具体的 SQL 文本
SELECT sql_text FROM dba_hist_sqltext WHERE sql_id = '&top_level_sql_id';```