




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
简介
检测 在Zabbix前端对MGR的全部节点建立监控机制,检测MySQL的状态。 告警机制 通过对MySQL服务器端口(3306)及MGR服务端口(33061)的监控,收集MGR集群的数据,当返回值=0(未检测到33061端口)时,触发告警。 自愈 编写自愈脚本,内容包括尝试重新启动MySQL进程,检查MGR集群状态和集群中的主机数量,重新引导集群以及故障点恢复,并将所有MySQL状态和集群状态记录在指定的日志当中。
实施准备工作
准备zabbix所需yum源
rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/7/x86_64/zabbix-release-latest-5.0.el7.noarch.rpm
yum clean all
#清理yum缓存
安装Zabbix server,Web前端,agent
yum install zabbix-server-mysql zabbix-agent
安装zabbix前端
yum源下载
yum install centos-release-scl
编辑配置文件 etc/yum.repos.d/zabbix.repo

yum install zabbix-web-mysql-scl zabbix-apache-conf-scl
mysql -uroot -pmysql> create database zabbix character set utf8 collate utf8_bin;mysql> create user zabbix@localhost
identified by '123456';mysql> grant all privileges on zabbix.* to zabbix@localhost;mysql> set global log_bin_trust_function_creators = 1;mysql> quit;

zcat usr/share/doc/zabbix-server-mysql/create.sql.gz | mysql -uzabbix -p zabbix
mysql -uroot -pmysql> set global log_bin_trust_function_creators = 0;mysql> quit
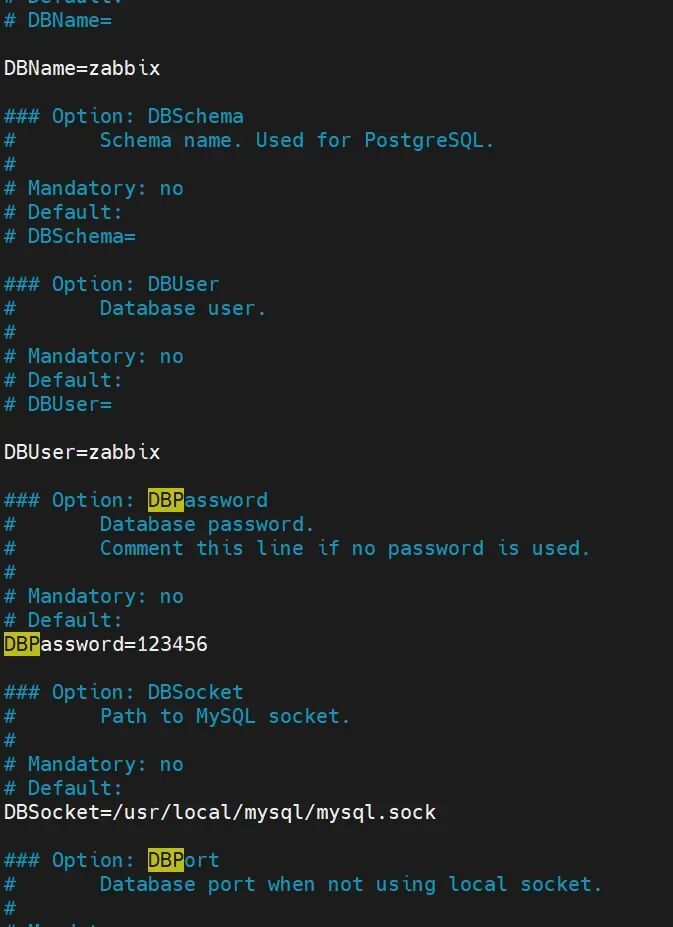
php_value[date.timezone] = Asia/Shanghai
# systemctl restart zabbix-server zabbix-agent httpd rh-php72-php-fpm# systemctl enable zabbix-server zabbix-agent httpd rh-php72-php-fpm
[root@localhost ~]# hostnamectl set-hostname mysql1.com
[root@localhost ~]# hostnamectl set-hostname mysql2.com
[root@localhost ~]# hostnamectl set-hostname mysql3.com
[root@localhost ~]# vim /etc/hosts

yum install zabbix-agent
[root@host2 ~]# vi etc/zabbix/zabbix_agentd.conf
Server=Zabbix #Server端主机名或IP地址
ServerActive= Zabbix #Server端主机名或IP地址
Hostname= #Agent端的主机名/IP
UnsafeUserParameters=1 #//是否限制用户自定义keys使用特殊字符


useradd -M -s sbin/nologin -r mysql

tar zxf mysql-5.7.28-linux-glibc2.12-x86_64.tar.gz -C usr/local/ & cd /usr/local
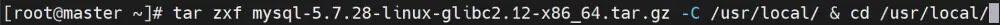
mv mysql-5.7.26-linux-glibc2.12-x86_64/ mysql

cd /usr/local/mysql

mkdir data

chown -R mysql.mysql usr/local/mysql/

bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data

export PATH=/usr/local/mysql/bin:$PATH

./etc/profile.d/mysql.sh或source /etc/profile

cd /usr/local/mysql && cp support-files/mysql.server etc/init.d/mysqld

chmod +x etc/init.d/mysqld

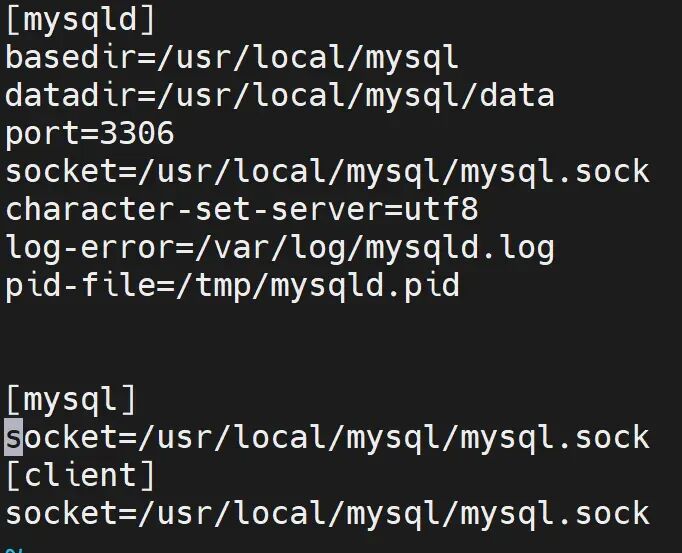
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
/etc/init.d/mysqld start

登陆
mysql -uroot -p'初始密码'
修改密码
mysql>set password for root@localhost=password('123456');

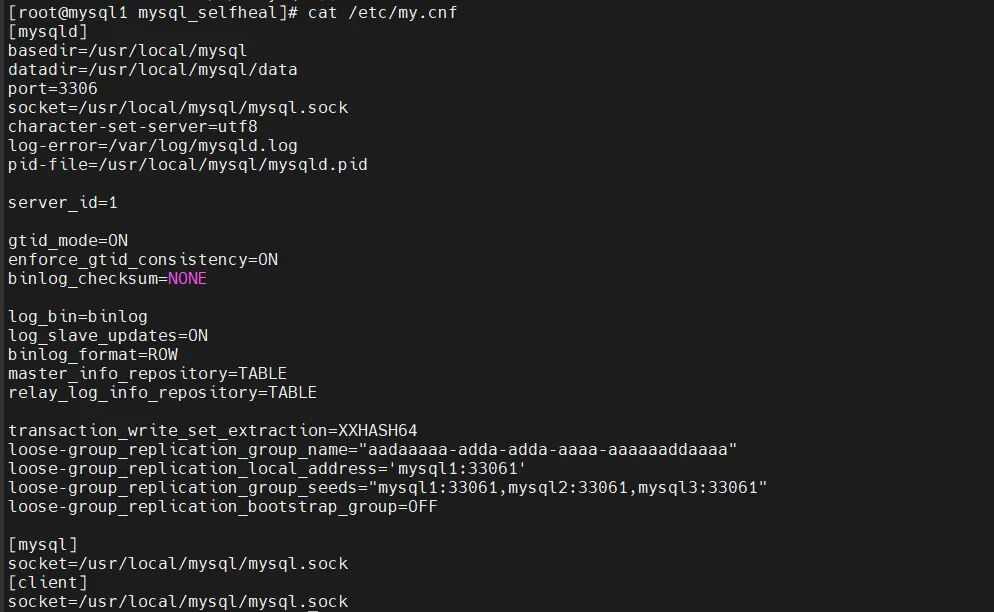
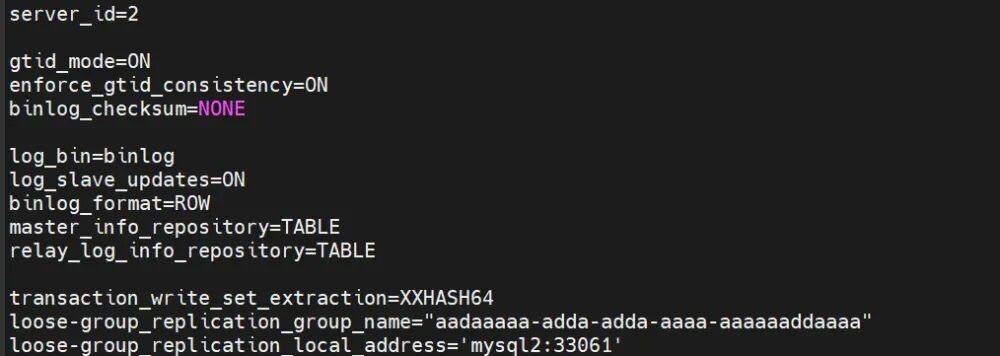
mysql2:
server id=2
loose-group_replication_local_address= "mysql2:33061"
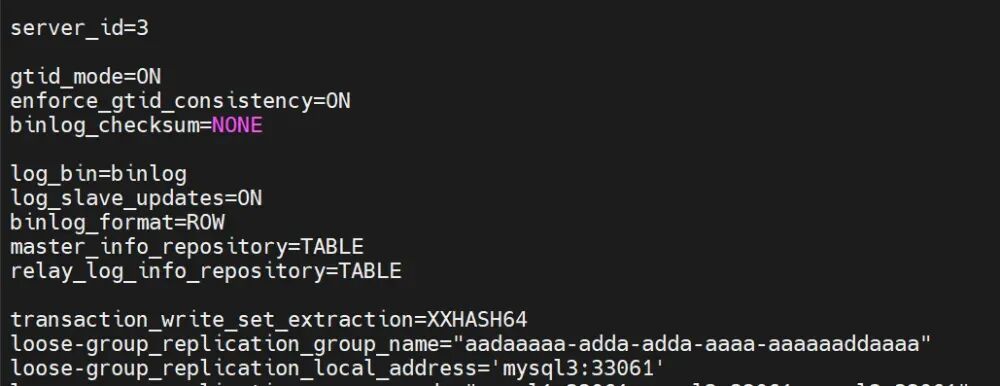
mysql3:server id=3
loose-group_replication_local_address= "mysql3:33062"
SET SQL_LOG_BIN=0;
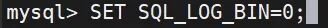
CREATE USER mgruser@'%' IDENTIFIED BY '123456';#授予用户 mgruser 从任何主机 ('%') 连接到 MySQL 服务器并进行复制的权利

GRANTREPLICATIONSLAVEON *.* TO mgruser@'%';

FLUSH PRIVILEGES; #刷新数据库权限

SET SQL_LOG_BIN=1; 开启二进制日志记录
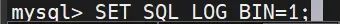
CHANGE MASTER TO MASTER_USER='mgruser', MASTER_PASSWORD='123456'FOR CHANNEL 'group_replication_recovery';
#创建复制账号,设置用户名和密码,以便其他节点可以从这个节点恢复数据。

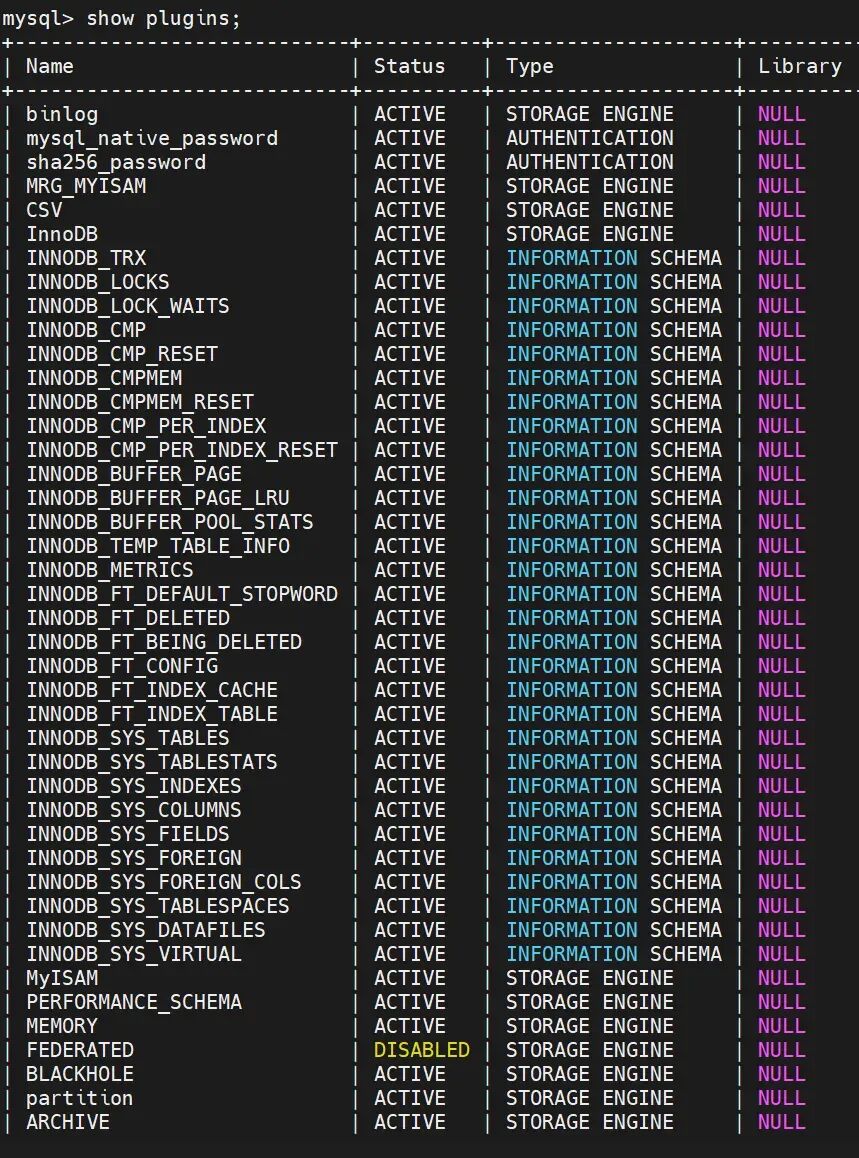
install PLUGIN group_replication SONAME 'group_replication.so';-

show plugins;
SET GLOBAL group_replication_bootstrap_group=ON;#准备引导新的组

START GROUP_REPLICATION;#启动组复制

SET GLOBAL group_replication_bootstrap_group=OFF;
# 取消引导标志

SELECT * FROM performance_schema.replication_group_members;

加入MGR
START GROUP_REPLICATION;

SELECT * FROM performance_schema.replication_group_members;

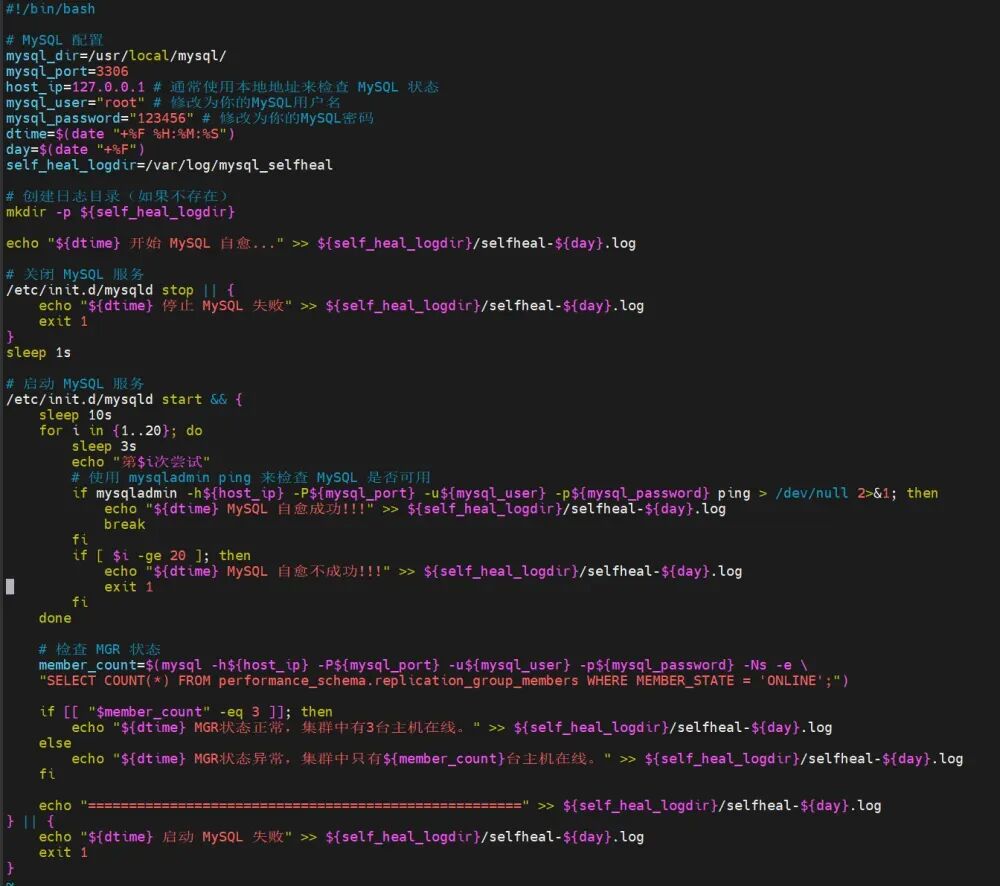
chmod +x /mysql_heal.sh
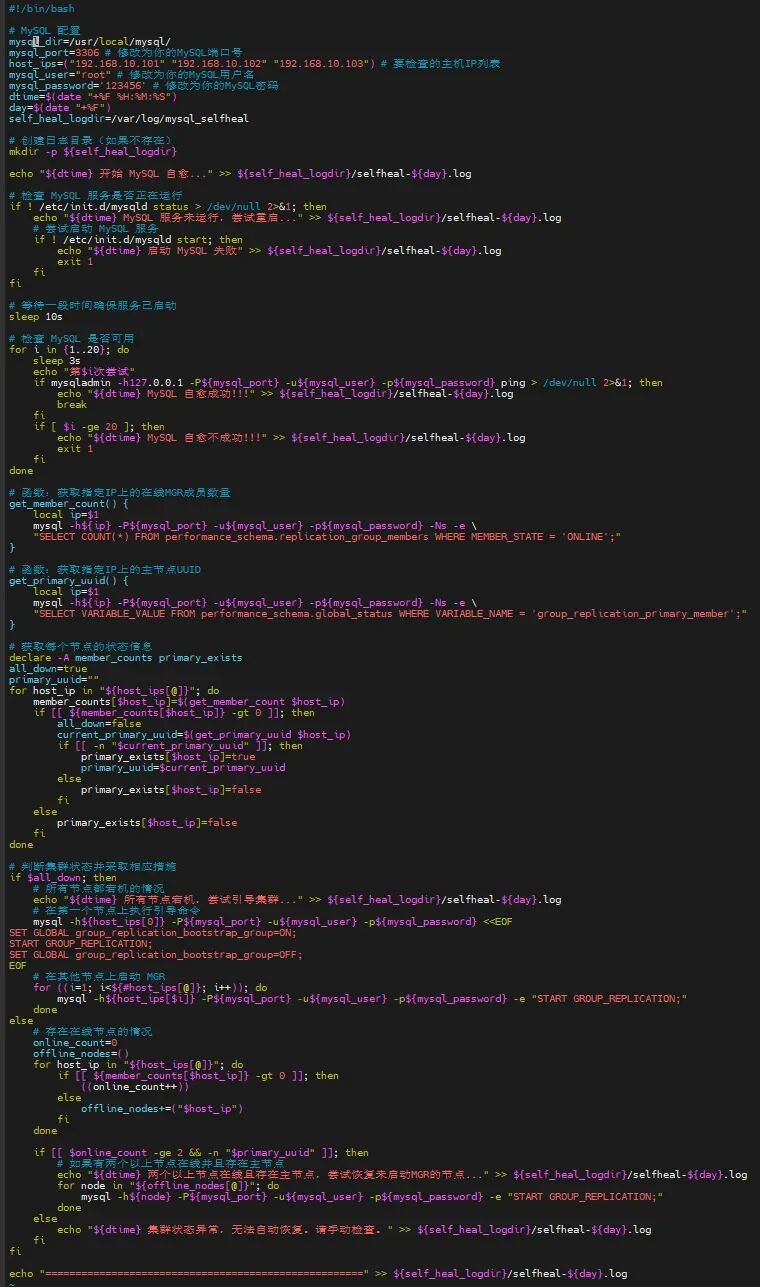
chmod +x /mgr_heal.sh
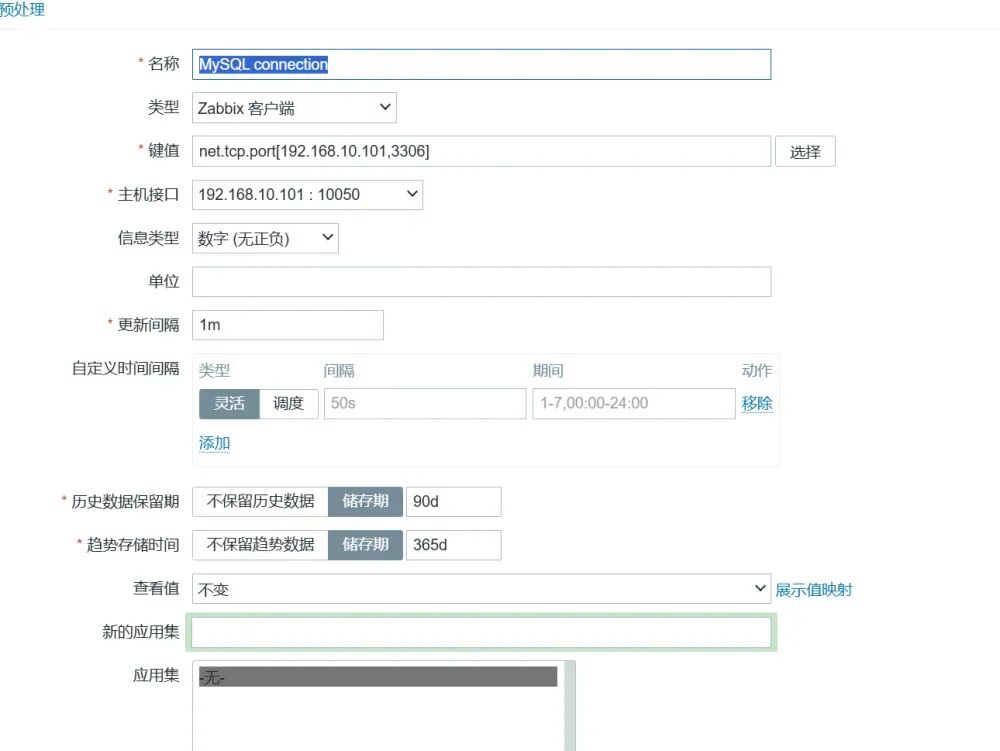
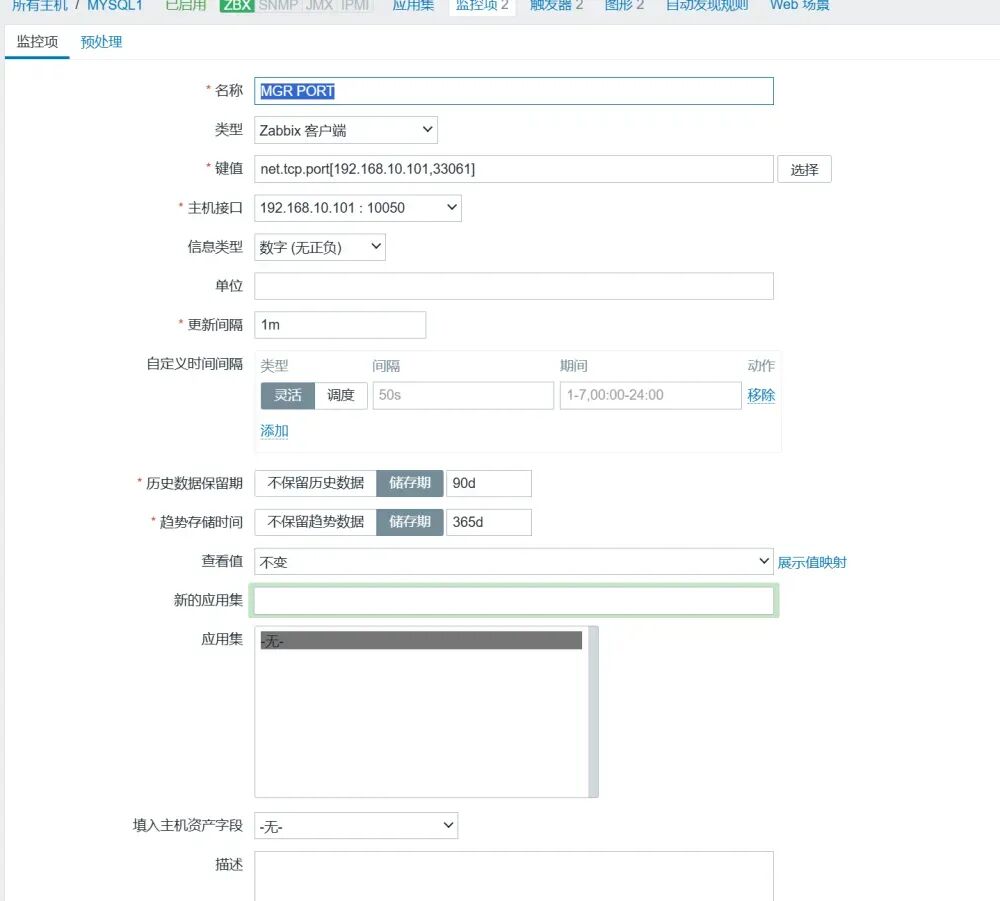
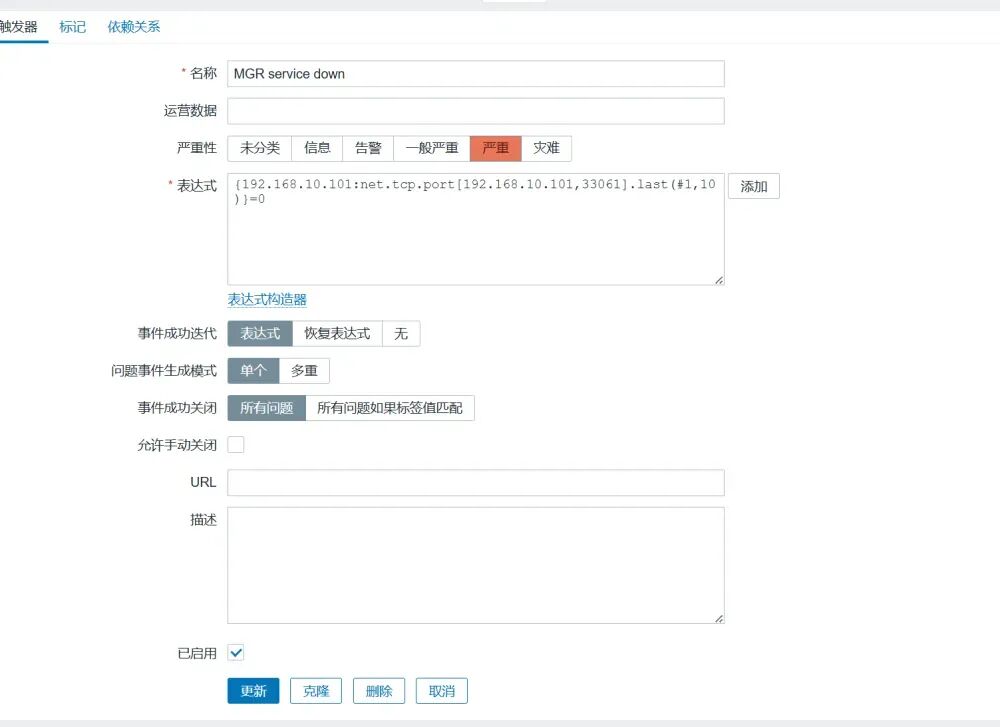
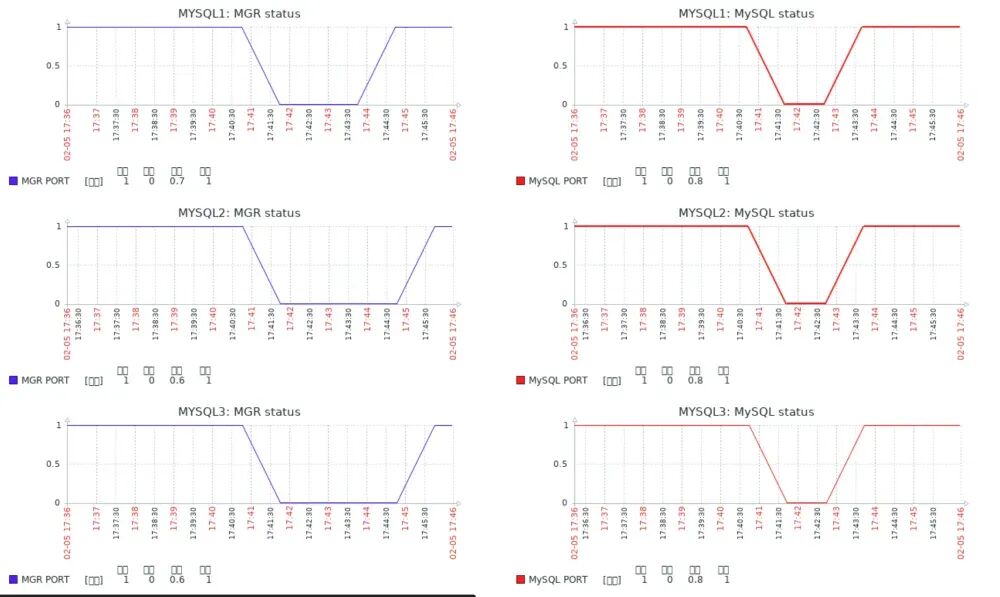
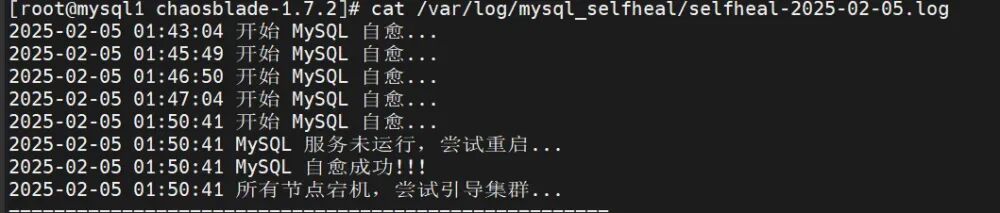
在故障节点调用mysql自愈脚本,重新启用mysql服务,以支持主节点的MGR自愈脚本连接mysql服务器; 在主节点(MYSQL1)调用MGR自愈脚本,重新检测mysql服务、检查故障点,并启用判断机制,即当集群正常运作,仅单一节点宕机时,则启动该节点,若集群崩溃,则在主节点执行引导命令,其他节点启动MGR以加入集群。
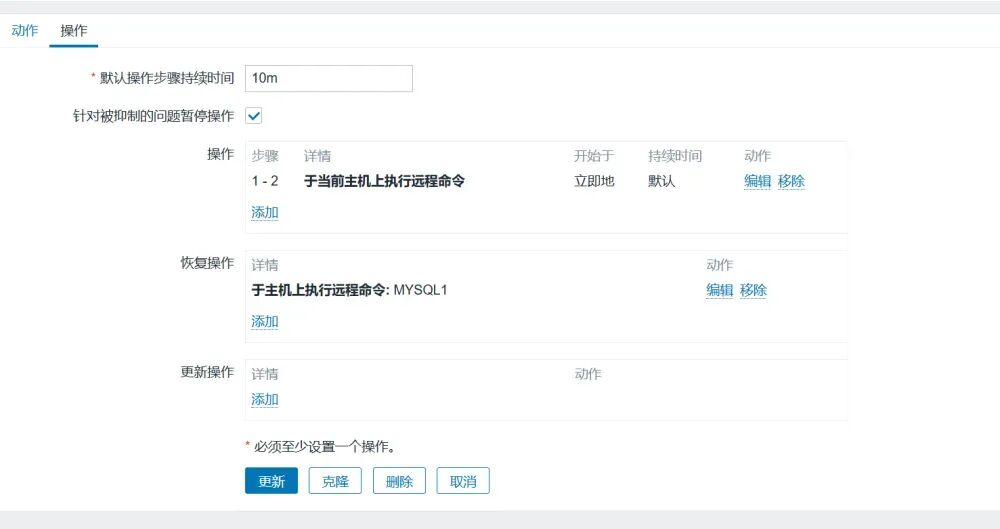
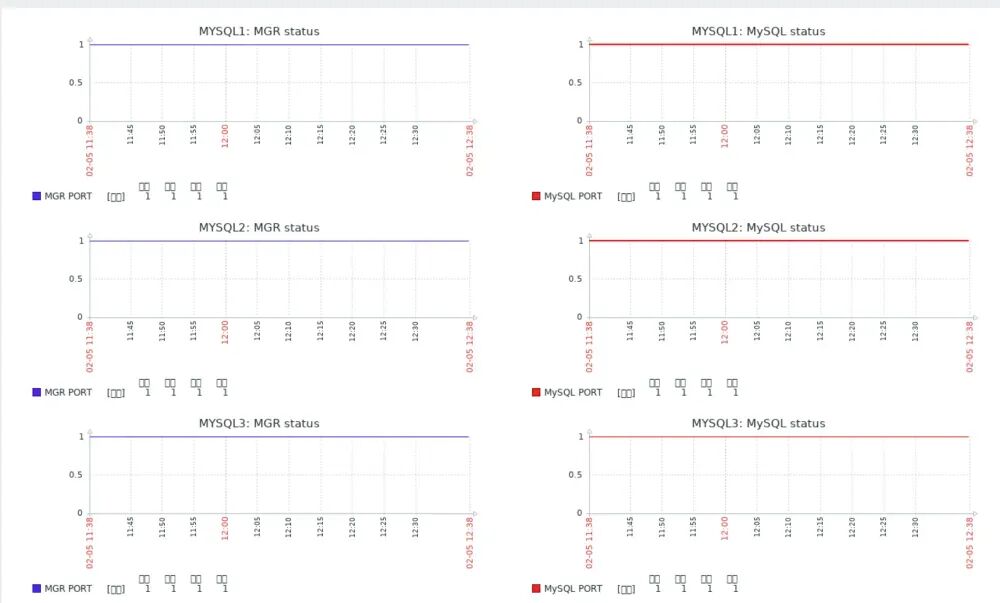
测试
下载
wget
https://github.com/chaosblade-io/chaosblade/releases/download/v1.7.2/chaosblade-1.7.2-linux-amd64.tar.gz
解压
tar -xvf chaosblade-1.7.2-linux-amd64.tar.gz && cd chaosblade-1.7.2/

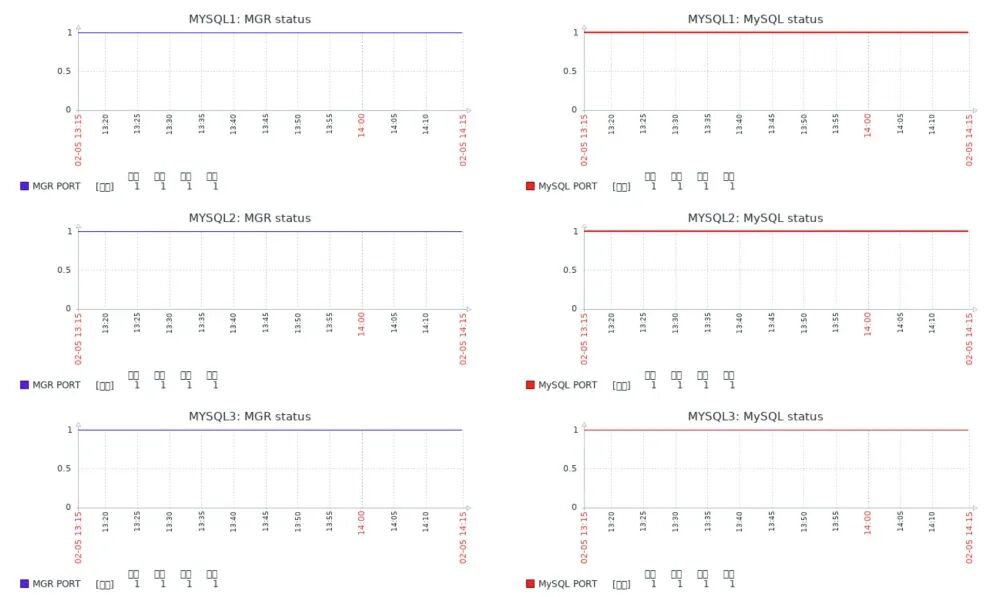
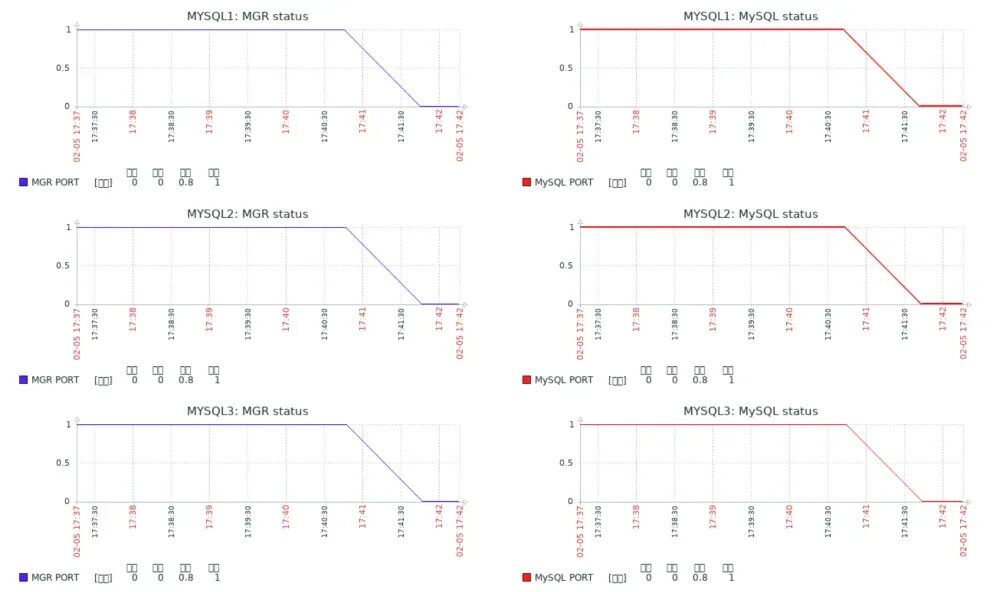
./blade create process kill --process mysqld --signal 9


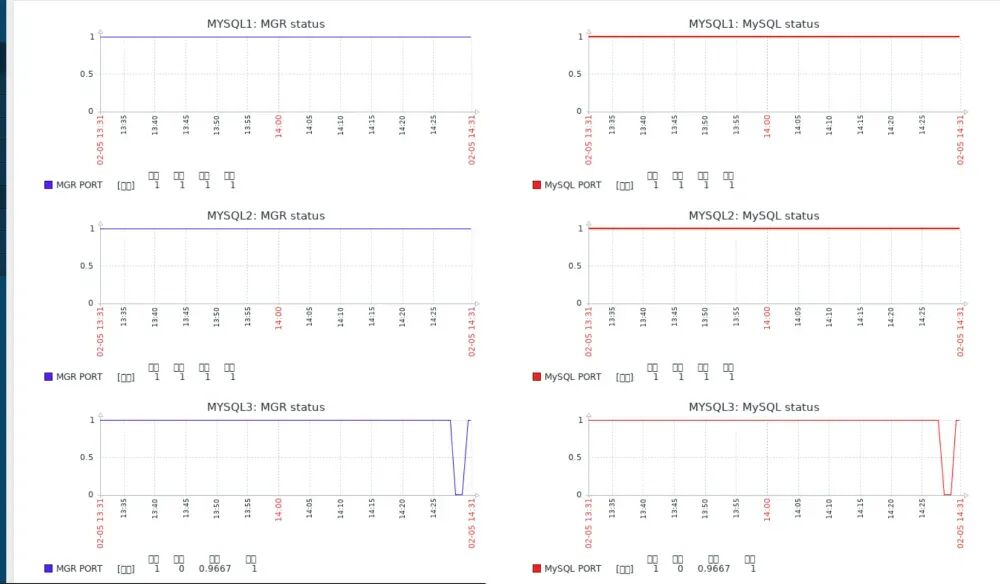


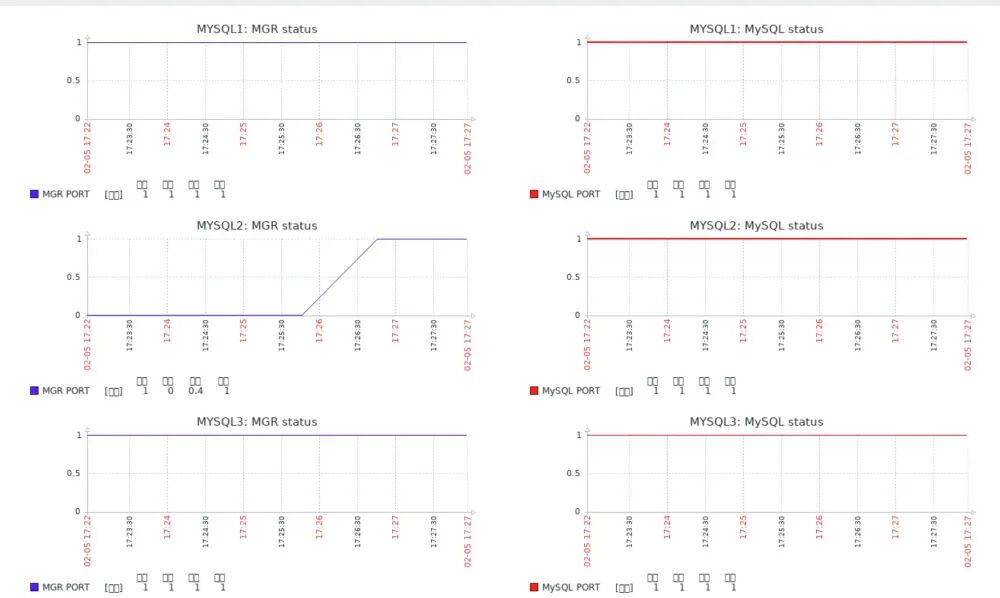
./blade create process kill --process mysqld --signal 9





本文作者:周登晖 (上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
