




PostgreSQL对海量数据表的优化设计,主要从表结构、索引、配置、分区、写入、维护、架构七个层面系统性地优化。以下是具体方案:
一、表结构设计优化
精简字段类型是降低存储和提升I/O效率的基础:
CREATE TABLE url_info (
id BIGSERIAL PRIMARY KEY, -- 8字节,亿级必须用BIGINT
url VARCHAR(2048) NOT NULL, -- 限制长度,避免TEXT
source VARCHAR(64) NOT NULL DEFAULT '', -- 固定上限,减少空间
status SMALLINT NOT NULL DEFAULT 0, -- 2字节,比INT省50%
create_time TIMESTAMPTZ NOT NULL DEFAULT NOW(),
update_time TIMESTAMPTZ NOT NULL DEFAULT NOW(),
md5_hash CHAR(32) UNIQUE -- 固定长度哈希,比VARCHAR索引效率高
);关键原则:用SMALLINT替代INT,用CHAR(n)替代VARCHAR做哈希字段,避免TEXT类型,时间字段用TIMESTAMPTZ而非字符串。
二、索引策略(亿级数据的核心)
2.1 必建索引
-- 1. 主键索引(自动创建)
-- 2. MD5唯一索引(用于URL去重,比直接索引URL高效得多)
-- 3. 时间范围查询索引(最高频场景)
CREATE INDEX idx_create_time ON url_info (create_time DESC);
-- 4. 复合索引(覆盖高频查询)
CREATE INDEX idx_time_status ON url_info (create_time, status);
-- 5. 部分索引(减少索引体积,提升写入速度)
CREATE INDEX idx_active_urls ON url_info (create_time)
WHERE status IN (1, 2); -- 只索引有效数据2.2 索引选择指南

BRIN索引示例(适合亿级时间序列表):
CREATE INDEX idx_log_created_brin ON logs USING BRIN(created_at)
WITH (pages_per_range = 16);2.3 覆盖索引优化
使用INCLUDE避免回表:
CREATE INDEX idx_orders_cover ON orders (created_at, status)
INCLUDE (order_id, customer_id, amount);三、PostgreSQL配置调优(postgresql.conf)
亿级数据必须调整以下核心参数(以32GB内存服务器为例):
# 内存配置(核心)
shared_buffers = 8GB # 系统内存的25%
effective_cache_size = 24GB # 系统内存的75%
work_mem = 256MB # 排序/哈希操作内存
maintenance_work_mem = 2GB # VACUUM/CREATE INDEX内存
# 写入与WAL优化
synchronous_commit = off # 可容忍少量丢失的场景
wal_buffers = 64MB
checkpoint_completion_target = 0.9
max_wal_size = 4GB
min_wal_size = 1GB
# 并行查询
max_parallel_workers_per_gather = 8
max_parallel_workers = 16
parallel_setup_cost = 0.1
parallel_tuple_cost = 0.01
# 统计信息(大表必须调高)
default_statistics_target = 500
autovacuum_analyze_scale_factor = 0.01 # 每1%变更触发ANALYZE
autovacuum_analyze_threshold = 10000SSD环境关键调整:
random_page_cost = 1.1 # SSD随机I/O成本低,从默认4.0大幅降低四、分区表设计
4.1 按时间分区
-- 创建分区表(PostgreSQL 10+ 原生支持)
CREATE TABLE url_info (
id BIGSERIAL,
url VARCHAR(2048) NOT NULL,
source VARCHAR(64) NOT NULL,
status SMALLINT NOT NULL DEFAULT 0,
create_time TIMESTAMPTZ NOT NULL DEFAULT NOW(),
md5_hash CHAR(32)
) PARTITION BY RANGE (create_time);
-- 按月创建分区
CREATE TABLE url_info_2026_01 PARTITION OF url_info
FOR VALUES FROM ('2026-01-01') TO ('2026-02-01');
CREATE TABLE url_info_2026_02 PARTITION OF url_info
FOR VALUES FROM ('2026-02-01') TO ('2026-03-01');
-- 每个分区独立建索引
CREATE INDEX idx_url_info_2026_01_md5 ON url_info_2026_01 (md5_hash);
CREATE INDEX idx_url_info_2026_01_time ON url_info_2026_01 (create_time);分区优势:
- 分区裁剪:查询时只扫描相关分区,性能提升数量级
- 局部索引:每个分区索引更小,维护更快
- 独立维护:VACUUM/REINDEX可在单个分区执行
- 归档方便:直接DROP旧分区,比DELETE快得多
4.2 哈希分区
CREATE TABLE url_info (
id BIGSERIAL,
url VARCHAR(2048) NOT NULL,
md5_hash CHAR(32)
) PARTITION BY HASH (id);
CREATE TABLE url_info_p0 PARTITION OF url_info
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
-- ... 创建p1, p2, p3五、数据写入优化
5.1 批量写入(比单条INSERT快100倍)
-- 使用COPY(最快)
COPY url_info (url, source, status, create_time, md5_hash)
FROM '/data/urls.csv'
WITH (FORMAT CSV, DELIMITER ',', HEADER);
-- 或使用多值INSERT
INSERT INTO url_info (url, source, status, md5_hash)
VALUES
('url1', 'source1', 0, 'hash1'),
('url2', 'source2', 0, 'hash2'),
...; -- 每次1000-10000条5.2 导入时禁用索引和约束
-- 导入前
ALTER TABLE url_info DISABLE TRIGGER ALL; -- 禁用外键和触发器
-- 执行COPY/INSERT...
-- 导入后
ALTER TABLE url_info ENABLE TRIGGER ALL;
CREATE INDEX CONCURRENTLY idx_url_info_md5 ON url_info (md5_hash); -- 重建索引5.3 并行导入
# 使用timescaledb-parallel-copy工具
timescaledb-parallel-copy \
-connection $DATABASE_URI \
-table url_info \
-workers 8 \
-batch-size 5000 \
-split '\t' \
/data/urls.csv六、维护策略
6.1 定期维护任务
-- 1. 更新统计信息(慢查询最常见原因)
ANALYZE url_info;
-- 2. 清理死元组(防止膨胀)
VACUUM (ANALYZE, VERBOSE) url_info;
-- 3. 重建索引(防止索引膨胀)
REINDEX INDEX idx_url_info_md5;
-- 4. 查看表膨胀情况
SELECT * FROM pgstattuple('url_info');6.2 自动维护配置
# 高频更新表调优
autovacuum_vacuum_scale_factor = 0.05 # 5%变更即触发VACUUM
autovacuum_analyze_scale_factor = 0.02 # 2%变更即触发ANALYZE
autovacuum_max_workers = 8
autovacuum_naptime = 10s七、架构扩展方案
7.1 读写分离(读多写少场景)
主库(写入+强一致性读)
↓ 异步流复制
50个只读副本(分布查询)实现方式:
- 应用层路由:写入走主库,查询走副本
- 使用PgBouncer连接池管理连接
- 副本延迟>500ms自动降级
7.2 水平分片(超大规模)
当单实例无法支撑时,使用Citus扩展:
-- 创建分布式表
SELECT create_distributed_table('url_info', 'user_id'); -- 按user_id分片分片架构:3主库+15副本,每个分片承载约2600万用户。
7.3 多级缓存架构
应用层本地缓存(热点数据)
↓
Redis集群(会话/查询结果缓存)
↓
PostgreSQL主库/副本八、诊断与监控
8.1 慢查询诊断流程
-- 1. 查看执行计划
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM url_info
WHERE create_time > '2026-01-01' AND status = 1;
-- 2. 监控索引使用率
SELECT schemaname, tablename, indexname, idx_scan
FROM pg_stat_user_indexes
WHERE tablename = 'url_info';
-- 3. 查找最耗资源的查询
SELECT query, calls, total_time, mean_time
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;
-- 4. 监控表膨胀
SELECT relname, n_dead_tup, n_live_tup,
round(n_dead_tup::float / (n_live_tup + n_dead_tup + 1) * 100, 2) AS dead_pct
FROM pg_stat_user_tables
WHERE relname = 'url_info';8.2 关键监控指标
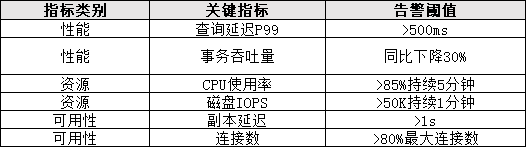
九、优化优先级总结
按投入产出比排序:
- 第一优先级:表结构精简 + 合理索引 +
ANALYZE更新统计信息 - 第二优先级:分区表 +
postgresql.conf核心参数调优 - 第三优先级:批量写入优化 + 定期VACUUM策略
- 第四优先级:读写分离架构 + 连接池
- 第五优先级:水平分片(仅当单实例确实无法支撑时)
核心原则:没有放之四海而皆准的最优配置,必须基于具体的数据特征、查询模式和硬件环境持续调优。每次优化后必须通过EXPLAIN ANALYZE验证效果,并建立完善的监控告警体系。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
