




OceanBase 社区版 4.5 OCP 部署避坑:在自动修复中memory_limit“灵异事件”的深度溯源与修复

前言
最近在本地沙箱环境折腾 OceanBase 社区版 4.5.0_20260203,碰上一个让人极度怀疑人生的死循环:无论我怎么手动修改配置文件,把 memory_limit 调到 8G 甚至更高,预检查(Pre-check)转个身,系统就立刻变脸,抛出“内存不足 6G”的报错。前前后后改配置、回滚、重试不下数次,始终无法绕过这个鬼打墙,让人几乎陷入深度自我怀疑。
事情的起因很简单:我想在三台 CentOS 7.9 虚拟机上部署一套 OCP,其中 ob1 节点分配了 16G 内存,ob2 和 ob3 各 10G。按官方文档的要求,这配置跑一套学习环境绰绰有余。然而,安装过程却反复提示“内存不足 6G”,让我一度怀疑自己是不是少装了什么组件。
接下来的几个晚上,我不停地在配置文件中调整 memory_limit、重启安装流程、查看日志,却总是回到同一个报错循环。直到某次我留意到 Config 文件中 memory_limit 的值会神秘地自动重置,才意识到:这可能不是配置的问题,而是 OBD Web 中“自动修复”逻辑的一个陷阱。
本文完整记录了这个问题的复现过程、根因分析和规避方法完整记录下来,希望能帮你在今后的运维部署中少走弯路、少熬夜、不掉坑。本文仅针对 OceanBase 社区版 4.5.0_20260203 版本,不确定其他版本是否存在相同问题。
OceanBase 社区版凭借其原生的分布式架构在高并发与海量数据场景下表现出色,并对 HTAP 混合负载提供了良好的支持。OCP(OceanBase Control Platform)作为其统一运维管理平台,能够有效降低集群运营的复杂度。但面对这类由内部自动化流程引发的“幽灵”参数重置,知其然更需知其所以然,才能在关键时刻稳得住。

一、环境准备:硬件与系统配置
1.1 硬件拓扑
为完整复现问题,部署架构为一套 3 节点模拟集群,其中 ob1 节点承担 OCP 集中管理职责,ob2、ob3 作为纯 OBServer 计算与存储节点。
环境说明
| 主机名 | 预装服务 | IP | 内存 |
|---|---|---|---|
| ob1 | 16G(OCP + OBServer + OBProxy) | 192.168.18.200 | 16G |
| ob2 | 10G(OBServer) | 192.168.18.201 | 8G(复现关键条件) |
| ob3 | 10G(OBServer) | 192.168.18.202 | 8G(复现关键条件) |
1.2 系统基础环境
- 操作系统:CentOS 7.9
- 安全前提:关闭防火墙、禁用 SELinux
- 网络环境:固定 IP,节点间网络互通
Tips:在 CentOS 7.9 环境下部署时,建议通过 systemctl stop firewalld 和 setenforce 0 确认防火墙与 SELinux 状态后再开始安装,否则后续会产生大量网络相关的 Pre-check 报错。
1.3 系统参数调优
在正式开始部署之前,需要调整 Linux 系统的资源限制参数。这是 OceanBase 部署的标准前置步骤,如果遗漏这一步,后续 observer 进程可能因文件句柄数不足而异常退出。
# 编辑 nofile 限制
[admin@ob1 ~]$ vi etc/security/limits.d/nofile.conf
* soft nofile 655350
* hard nofile 655350
# 编辑 limits.conf
[admin@ob1 ~]$ vi /etc/security/limits.conf
* soft nofile 655350
* hard nofile 655350
* soft stack unlimited
* hard stack unlimited
* soft nproc 655360
* hard nproc 655360
* soft core unlimited
* hard core unlimited
执行完成后,建议退出当前终端并重新登录,使配置生效。可以通过 ulimit -n 和 ulimit -u 验证。
1.4 安装 OBD 并启动 Web 界面
在 ob1 节点上下载 OceanBase All-in-One 安装包,解压后安装并启动 OBD Web 服务:
# 下载安装包
[admin@ob1 ~]$ wget -c https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/download-center/opensource/oceanbase-all-in-one/7/x86_64/oceanbase-all-in-one-4.5.0_20260203.el7.x86_64.tar.g
# 进入解压后的 bin 目录,执行安装
[admin@ob1 ~]$ cd /home/admin/oceanbase-all-in-one/bin
[admin@ob1 bin]$ ./install
# 加载环境变量
[admin@ob1 bin]$ source ~/.oceanbase-all-in-one/bin/env.sh
# 启动 OBD Web 服务
[admin@ob1 bin]$ obd web
# 输出:start OBD WEB in 0.0.0.0:8680
# 访问:http://192.168.18.200:8680
运维提示:obd web 默认绑定 0.0.0.0:8680,如果主机开启了防火墙,需要放行该端口。本文实验环境已关闭防火墙,故不涉及此步骤。
二、OCP 部署配置详解
2.1 完整配置文件
下面贴出本次部署使用的完整 config.yaml 配置文件,位于 /home/admin/.obd/cluster/myocp/config.yaml:
# OB1 配置如下
[admin@ob1 ~]$ cat .obd/cluster/myocp/config.yaml
user:
username: admin
password: Zhou123
port: 22
oceanbase-ce:
version: 4.2.1.8
release: 108000022024072217.el7
package_hash: 499b676f2ede5a16e0c07b2b15991d1160d972e8
192.168.18.200:
zone: zone1
datafile_maxsize: 48G
192.168.18.201:
zone: zone2
datafile_maxsize: 54G
192.168.18.202:
zone: zone3
datafile_maxsize: 54G
servers:
- 192.168.18.200
- 192.168.18.201
- 192.168.18.202
global:
appname: myocp
root_password: Zhou123_
mysql_port: 2881
rpc_port: 2882
home_path: /home/admin/oceanbase
data_dir: /home/admin/data/1
redo_dir: /home/admin/data/log1
obshell_port: 2886
memory_limit: 8GB
ocp_meta_tenant:
tenant_name: ocp_meta
max_cpu: 2.0
memory_size: 2G
ocp_meta_username: root
ocp_meta_password: Zhou123_
ocp_meta_db: meta_database
ocp_monitor_tenant:
tenant_name: ocp_monitor
max_cpu: 2.0
memory_size: 2G
ocp_monitor_username: root
ocp_monitor_password: Zhou123_
ocp_monitor_db: monitor_database
cluster_id: 1778203781
proxyro_password: zWh8Eyxaoy
ocp_root_password: qYrz4inZeH
ocp_meta_tenant_log_disk_size: 8G
enable_syslog_wf: false
max_syslog_file_count: 16
production_mode: false
datafile_size: 22G
system_memory: 1G
log_disk_size: 22G
cpu_count: 8
datafile_next: 5G
obproxy-ce:
version: 4.3.5.0
package_hash: f17b277b681adb1c86bfc3cfda369ad88896da9d
release: 3.el7
servers:
- 192.168.18.200
global:
home_path: /home/admin/obproxy
prometheus_listen_port: 2884
listen_port: 2883
enable_obproxy_rpc_service: false
proxy_mem_limited: 1GB
obproxy_sys_password: vsGS6EScnw
skip_proxy_sys_private_check: true
enable_strict_kernel_release: false
enable_cluster_checkout: false
depends:
- oceanbase-ce
192.168.18.200:
proxy_id: 1748
client_session_id_version: 2
ocp-server-ce:
version: 4.4.0
package_hash: f673d693677a2c640f925ad2127a604aaebf00bf
release: 20251114143405.el7
servers:
- 192.168.18.200
global:
home_path: /home/admin/ocp
soft_dir: /home/admin/software
log_dir: /home/admin/logs
ocp_site_url: http://192.168.18.200:8080
port: 8080
admin_password: Zhou123_
memory_size: 2G
manage_info:
machine: 10
depends:
- oceanbase-ce
- obproxy-ce
2.2 关键参数说明
在 oceanbase-ce.global 中,有以下几个与内存密切相关的参数需要重点关注:
- memory_limit: 8GB:指定 OceanBase 进程可使用的最大内存。默认为 6G,本次部署手动配置为 8G。
- system_memory: 1G:系统内部内存,不属于任何租户,用于 OBServer 自身运行。
- ocp_meta_tenant.memory_size: 2G:OCP 元数据租户的内存配额。
- ocp_monitor_tenant.memory_size: 2G:OCP 监控租户的内存配额。
这四个参数构成了 MetaDB 的内存分配骨架。总可用内存 8G 中,system_memory 占用 1G,ocp_meta 占用 2G,ocp_monitor 占用 2G,合计 5G,理论上还有富余。
注意:本文第 4 节将揭示问题的触发前提——需要将 ob2 和 ob3 的内存设置为 8G 以复现问题。三节点中如果有节点的物理内存低于 10G,部署工具在预检查阶段会判定内存偏紧,自动修复机制便会介入干预。
三、预检环节正常流程
3.1 首次预检查
在 OBD Web 界面完成配置填写后,进入预检查阶段。此时系统会扫描三台主机的硬件资源、依赖包、端口占用等条件。
初始预检查结果中,仅出现 2 项报错(通常是 kernel 参数或依赖包相关)。这两项报错均在自动修复范围内,系统在界面上提供了“自动修复”按钮。
3.2 手动设置 memory_limit
在进入预检查之前,已手动将 memory_limit 设置为 8GB:
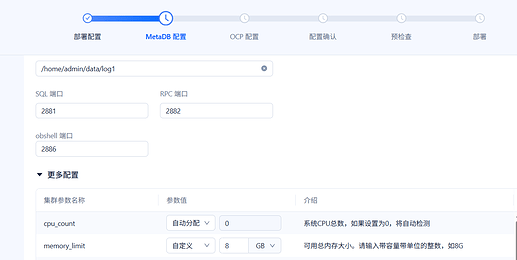
这一步操作在 OBD Web 的配置页面中完成,对应的 YAML 路径为 oceanbase-ce.global.memory_limit。
此时一切正常,预检查也顺利通过——直到点击“自动修复”按钮之后。
四、问题复现:自动修复导致 memory_limit 重置为 6G
4.1 问题触发链路
完整的触发链路如下:
- 手动配置
memory_limit: 8GB并保存配置 - 执行预检查,出现 2 项可自动修复的报错
- 点击“自动修复”按钮,系统开始修复 kernel 参数或依赖包问题
- 自动修复完成后,系统再次执行预检查
- 第二次预检查中,新增一条 memory_limit 相关的内存不足报错
- 查看
config.yaml,发现memory_limit已被重置为6G
4.2 现象截图
自动修复前,预检查仅有两项报错:

自动修复后,再次预检查时出现 memory_limit 报错:

4.3 配置文件验证
在出现报错后,立即检查配置文件中的 memory_limit 值:
cat .obd/cluster/myocp/config.yaml | grep memory_limit
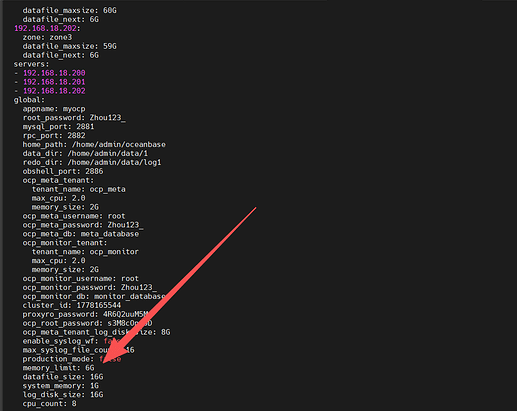
可以看到,memory_limit 的值已经由手动设定的 8GB 被重置为 6GB——即 OceanBase 的默认值。OBD 在执行自动修复时,似乎会触发一次配置文件的重新生成或参数回写,而 memory_limit 在这个回写过程中被“打回原形”。
五、根因分析
5.1 行为特征总结
通过反复实验,总结出以下关键行为特征:
| 实验步骤 | memory_limit 值 | 预检查结果 |
|---|---|---|
| 手动配置为 8GB | 8GB | 仅 2 项非内存报错 |
| 点击自动修复 | 8GB → 6GB(自动重置) | 新增 memory_limit 报错 |
| 再次手动设为 8GB | 8GB | 预检查通过,部署正常 |
5.2 原因推断
结合社区的类似反馈(如《吐槽一下 OCP 部署》一文中提到的“即便配置了新的 memory_limit,实际部署过程中仍然会使用自动分配的大小”),问题可能源自 OBD 自动修复流程中的以下环节:
- 自动修复触发配置重写:OBD 在执行自动修复时,不仅修复检测到的报错项,还会对配置文件进行一次全局校验与重写。
- 参数回写时使用默认值:在重写过程中,
memory_limit参数的写入逻辑可能未正确读取用户设定的自定义值,而是直接写入了默认的 6G。 - 时间窗口内的延迟重置:重置行为并非立即发生,而是在点击自动修复后一段时间内逐步完成,这解释了为何修复完成后立刻查看配置文件时 memory_limit 可能仍显示 8GB,但数秒后便变为 6GB。
5.3 为什么不是所有环境都会触发
这个问题并非每次部署都会遇到。其触发与以下条件密切相关:
- 自动修复确实有可修复项:如果首次预检查完全通过(无报错),就不会触发自动修复流程,自然也不会重置参数。
- 部分节点内存偏紧:ob2 和 ob3 节点内存仅为 8G 时,预检查会判定资源紧张,从而引发 OBD 的“资源重新评估”逻辑介入。
- 自定义 memory_limit 与默认值不一致:只有当用户手动修改了
memory_limit且该值大于默认的 6G 时,重置才会带来可见影响。
运维洞察:在分布式系统的部署工具中,“自动修复”这类特性就像一把双刃剑。出发点可能是降低部署门槛,减少手动干预,但如果对用户自定义参数的合并逻辑不够健壮,反而会在特定条件下制造出比原始报错更难排查的新问题。正如 Andy Pavlo 在 2025 年度数据库回顾中所言,数据库世界的许多“意料之外”,往往不是新功能不够强大,而是老机制的维护跟不上节奏。这里的“自动修复”正是这样一个例子——它解决了你看到的问题,却悄悄地制造了一个你没有看到的陷阱。
六、解决方案
6.1 核心策略:规避自动修复对 memory_limit 的重置
经过多次实验验证,以下方案可以稳定绕过该问题:
方案一:手动修复 + 跳过自动修复
- 首次预检查结束后,记录所有报错项
- 不要点击“自动修复”按钮
- 返回上一级配置页面,检查
memory_limit是否仍为 8GB - 如有被重置,手动再次设置为 8GB
- 重新执行预检查,确认无自动修复项后开始部署
方案二:扩容 ob2/ob3 内存(一劳永逸)
如果条件允许,建议将 ob2 和 ob3 的内存从 8G 提升至 12G 或 16G。内存充足时,OBD 预检查不会触发资源重评估逻辑,“自动修复”引发的连锁反应自然也不会发生。这是从根源上解决问题,而不只是在症状上做修补。
6.2 推荐操作流程(经过验证的稳定部署路径)
以下流程已在实际环境多次验证通过,可作为标准操作流程参考:
# 第一步:环境准备
# - 确保三台主机均已配置 limits.conf 中的 nofile、nproc、stack 参数
# - 关闭防火墙和 SELinux
# - 检查各节点内存:free -h
# 第二步:安装 OBD
cd /home/admin/oceanbase-all-in-one/bin
./install
source ~/.oceanbase-all-in-one/bin/env.sh
obd web
# 第三步:在 Web 界面中
# 1. 填写集群配置,将 memory_limit 设为 8GB
# 2. 执行首次预检查
# 3. 记录所有报错项(不点击自动修复)
# 4. 返回配置页面,确认 memory_limit 未被重置
# 5. 重新执行预检查,确认无报错
# 6. 点击“部署”,等待安装完成
# 第四步:验证安装
# obd cluster list
# obd cluster display myocp
运维避坑提醒:部署 OCP 时,建议全程避免使用“自动修复”功能。提前手动解决各类系统环境问题(如 kernel 参数、依赖包、端口占用等),确保预检查环节“零报错”,是最稳妥的安装策略。与其让自动化帮你修了三个隐患又悄悄埋下一个新坑,不如把主动权攥在自己手里,一次把路走直。
6.3 部署完成后的验证
部署完成后,通过以下命令验证集群状态:
# 查看集群列表
obd cluster list
# 查看集群详情
obd cluster display myocp
# 连接 OceanBase 验证
obclient -h192.168.18.200 -P2881 -uroot -p'Zhou123_' -Doceanbase
# 检查 memory_limit 实际生效值
show parameters like 'memory_limit';
附上完整安装流程演示视频供参考:
https://ask.oceanbase.com/uploads/default/original/3X/f/6/f65885fa365f3dddfe31eff39203d4f699bae31a.mp4
总结
这起 memory_limit “幽灵重置”事件,本质上是一个自动化工具对用户显式配置缺乏尊重的问题。回过头来看,这个问题的本质并不复杂:OBD 的“自动修复”在修复其他报错项的过程中,无意间将 memory_limit 重置为了默认值 6G。但由于重置发生的时机隐蔽——在自动修复完成后、第二次预检查之前——很容易让人误以为是自己配置有误,从而反复修改却始终无效。
这类问题在运维中并不罕见,但往往最难排查。在探索一个分布式数据库的部署工具时,遇到这类表现隐晦的问题并一步步找到其触发条件,本身也是运维路上有趣的试炼。排查这类问题的过程也印证了一个老生常谈的道理:自动化工具虽然便利,但在复杂场景下仍需保留人工干预的余地。盲目信任“自动修复”,可能会引入比原始报错更隐蔽的新问题。 工具从人手中接过了零散的体力活,但关于架构的判断、对异常的嗅觉,依然是运维者不能交出去的东西。
数据库世界的许多问题不是因为技术不够先进,而是因为工具在设计时没有充分考虑用户的真实使用场景。这个 case 恰是如此——自动修复的本意是好的,但没有给用户留一个 “我就要用我设的值” 的开关。
作者注
本文所有操作及测试均基于 CentOS 7.9 操作系统与 OceanBase 社区版 4.5.0_20260203 All-in-One 安装包完成,核心围绕 OBD Web 部署 OCP 过程中
memory_limit参数被自动修复重置的问题复现、根因分析及应对方案展开。
请注意,OceanBase 社区版迭代节奏较快,文中涉及的组件版本均可能随后续版本更新而发生变化。本文所述现象仅针对 4.5.0_20260203 版本明确复现,其他版本未必存在相同行为。请务必以 OceanBase 官方文档 及 GitHub 仓库 的最新说明为准。
本文作者:James-zhou OceanBase 版主 以上内容仅为个人经验总结,不代表任何组织或社区的官方观点。文中涉及的技术架构、部署步骤、问题诊断方法等,仅供参考。
