




Part1问题概述
2026年5月7日下午15点,收到客户反馈财务库某个业务sql执行缓慢。在晚上17点至23点,开发人员对业务sql进行了调优,优化之后性能提升。客户想了解是否可以修改数据库内存参数进一步优化数据库性能。
Part2初次分析
2.1、阐述问题
业务反馈自从26年春节以后,每月月初的准备金的存储过程执行的越来越慢,甚至一个晚上都有可能执行不完,严重到只能拆开来单次执行,希望我能解决一下这个问题。
2.2、开始时间
业务方面的操作时间是由26年5月7号17:00开始
2.3、处理过程
存储过程,石油多个DML语句构成,主要是update和insert,前期两个SQL语句没有卡的地方,说是这次很顺利。
我也用查询语句查了一下,分别是
##检查该SQL的等待事件、检查该SQL是否被另一个SQL锁住、检查他的执行时间
SELECT distinct status,
state,
event,
blocking_session BLS,
' alter system kill session ''' || b.sid || ',' ||
b.serial# ||',@' || b.inst_id || ''' immediate;',
c.cpu_time,
c.elapsed_TIME,
c.SQL_TEXT,
c.SQL_ID,
b.username,
b.sid,
b.serial#,
logon_time,
osuser OUSER,
machine,
LAST_ACTIVE_TIME,
b.*
FROM gv$session b, gv$sqlarea c
WHERE b.SQL_ID = c.SQL_ID
and b.inst_id = c.inst_id
--and EVENT = 'enq: TX - row lock contention'
--and upper(sql_text )like '%TASK_SH%'
--and sid = '2545'
--and username = 'CW5'
order by CPU_TIME desc, c.SQL_TEXT, b.logon_time;
另一个SQL是检查该SQL修改数据有没有变化,判断是否真的在执行
##查找未提交的事务(即使会话已断开也可能存在)
##通过定位SID来找到该语句,然后看最后一列undo_mb查看数值是否有变化,看看语句是否真的在执行
SELECT s.sid,
s.serial#,
s.username,
s.status,
s.taddr as transaction_addr,
t.start_time,
t.xidusn, -- 回滚段号
t.xidslot, -- 槽号
t.xidsqn, -- 序列号
t.status as tran_status,
t.used_ublk as undo_blocks,
t.used_urec as undo_records,
ROUND(t.used_ublk * 8 / 1024, 2) as undo_mb -- 估算undo大小(MB)
FROM gv$transaction t
LEFT JOIN gv$session s
ON t.ses_addr = s.saddr
WHERE t.status = 'ACTIVE';
前几个SQL看着都很顺利,虽然执行较慢,但是的确一直在顺利的执行,直到19:12,业务反馈有条SQL,执行时间超长,怀疑是卡死了,麻烦看一眼
查看该SQL是没有源头锁的
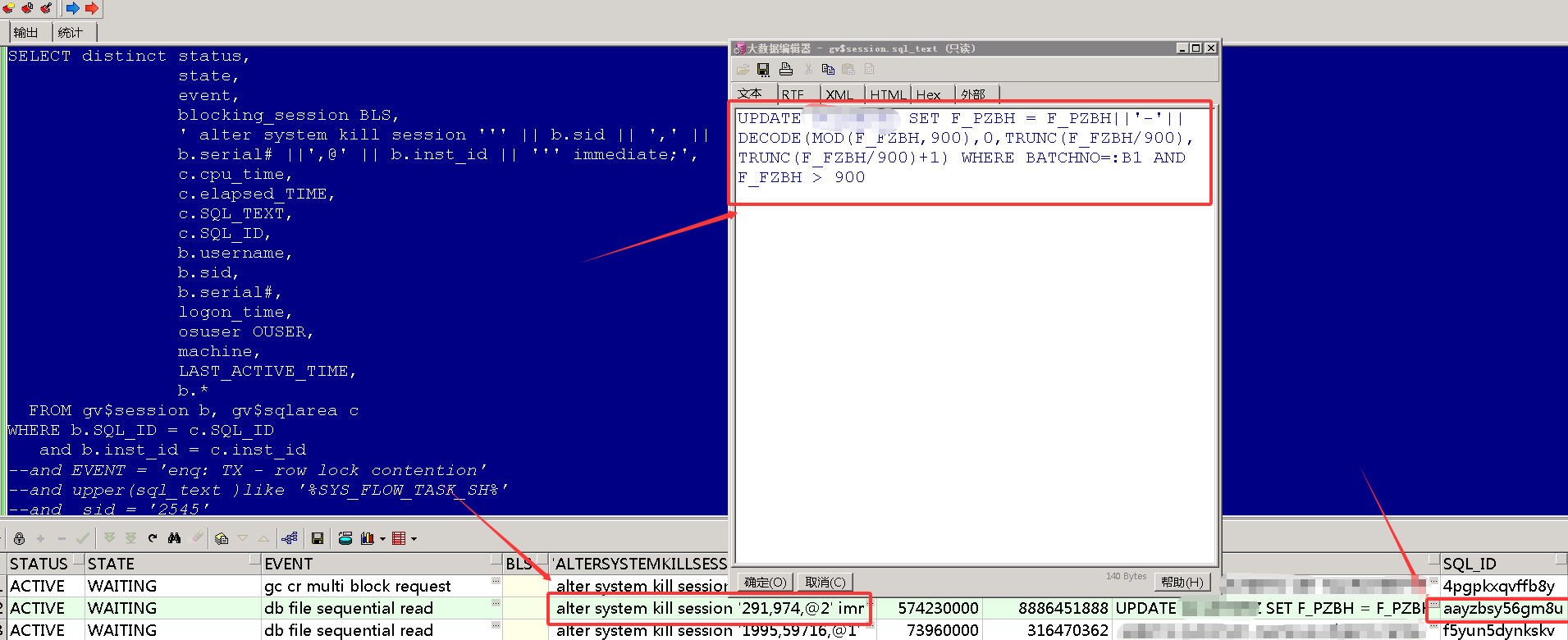
UPDATE GC SET F_PZBH = F_PZBH||'-'||DECODE(MOD(F_FZBH, 900), 0, TRUNC(F_FZBH/900), TRUNC(F_FZBH/900)+1) WHERE BATCHNO=:B1 AND F_FZBH > 900
查看SQL语句的真实绑定变量
SELECT snap_id,
MAX(CASE WHEN position = 1 THEN value_string END) AS bind1,
MAX(CASE WHEN position = 2 THEN value_string END) AS bind2,
MAX(CASE WHEN position = 3 THEN value_string END) AS bind3,
MAX(CASE WHEN position = 4 THEN value_string END) AS bind4,
MAX(CASE WHEN position = 5 THEN value_string END) AS bind5
FROM dba_hist_sqlbind
WHERE sql_id = 'aayzbsy56gm8u'
GROUP BY snap_id
ORDER BY snap_id;
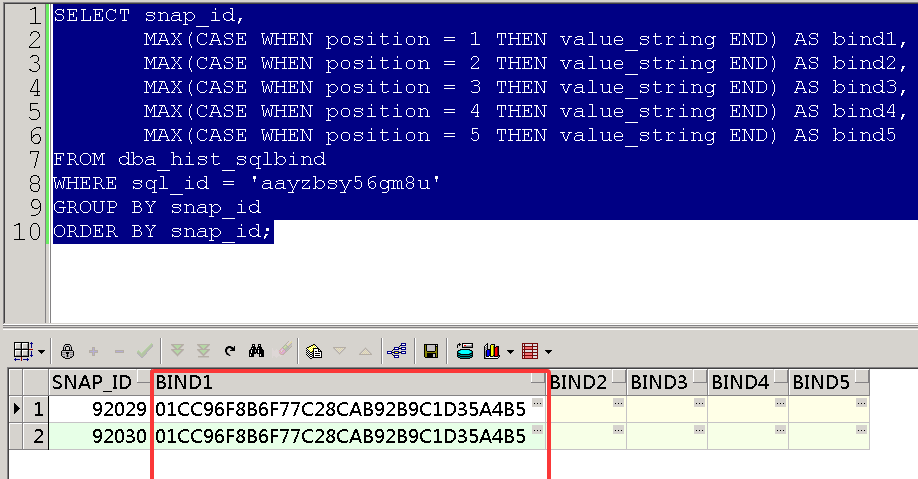
然后根据该结果改变查询语句,争取跑出来真实的执行计划
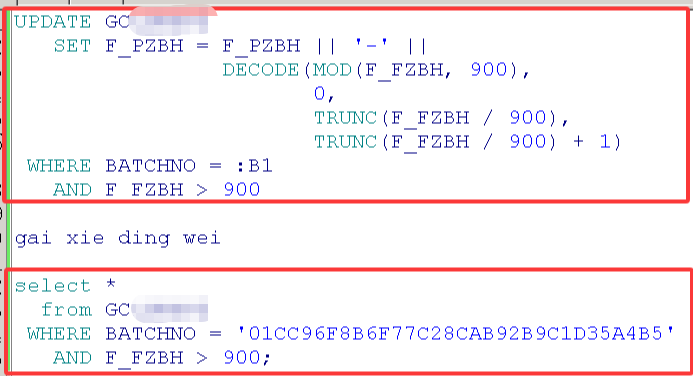
但是该语句执行失败了,执行大概40分钟后,直接断开失败,应该是数据库的参数设置的,没有办法,只好想个别的办法来解决
alter session set statistics_level=all;
或者在SQL语句中添加
hint:/ *+ gather_plan_statistics */
select *
from GC
WHERE BATCHNO = '01CC96F8B6F77C28CAB92B9C1D35A4B5'
AND F_FZBH > 900;
SQL> select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

只好通过自己的经验来判断 查询该SQL涉及的表,表涉及的列,列与现在索引之间的关系。发现极度不匹配

然后再查询该表的统计信息,发现很新

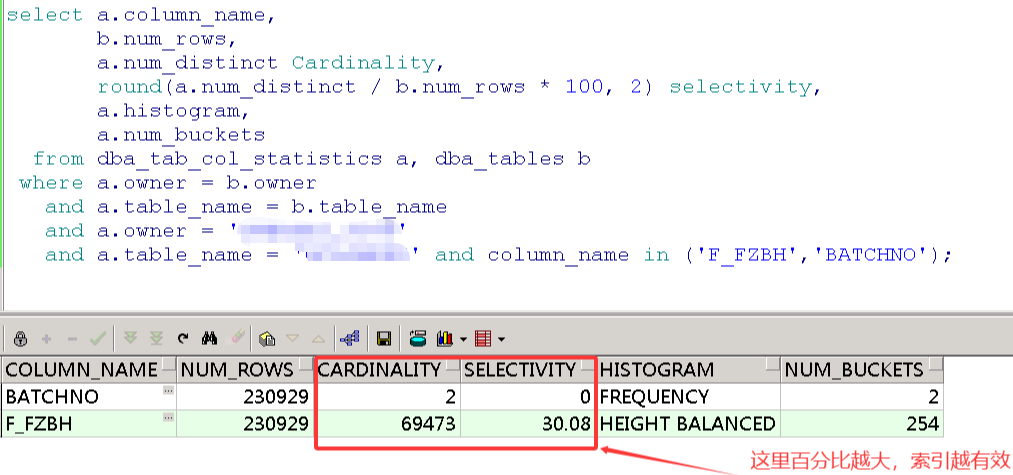
查询基数
select a.column_name,
b.num_rows,
a.num_nulls,
a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100, 2) selectivity,
a.histogram,
a.num_buckets
from dba_tab_col_statistics a, dba_tables b
where a.owner = b.owner
and a.table_name = b.table_name
and a.owner = 'SCOTT'
and a.table_name = 'T_STATS'
and column_name in ('F_FZBH','BATCHNO');
于是我想创建个索引
create index GC_INX1 on GC (batchno,f_fzbh) online parallel 8;
发现是被锁了
接着用语句查询
SELECT distinct status,
state,
event,
blocking_session BLS,
' alter system kill session ''' || b.sid || ',' ||
b.serial# ||',@' || b.inst_id || ''' immediate;',
c.cpu_time,
c.elapsed_TIME,
c.SQL_TEXT,
c.SQL_ID,
b.username,
b.sid,
b.serial#,
logon_time,
osuser OUSER,
machine,
LAST_ACTIVE_TIME,
b.*
FROM gv$session b, gv$sqlarea c
WHERE b.SQL_ID = c.SQL_ID
and b.inst_id = c.inst_id
--and EVENT = 'enq: TX - row lock contention'
--and upper(sql_text )like '%SYS_FLOW_TASK_SH%'
--and sid = '2545'
--and username = 'CW5'
order by CPU_TIME desc, c.SQL_TEXT, b.logon_time;
可以发现是源头锁已经变成了那个执行时间很长的SQL,创建索引正在等
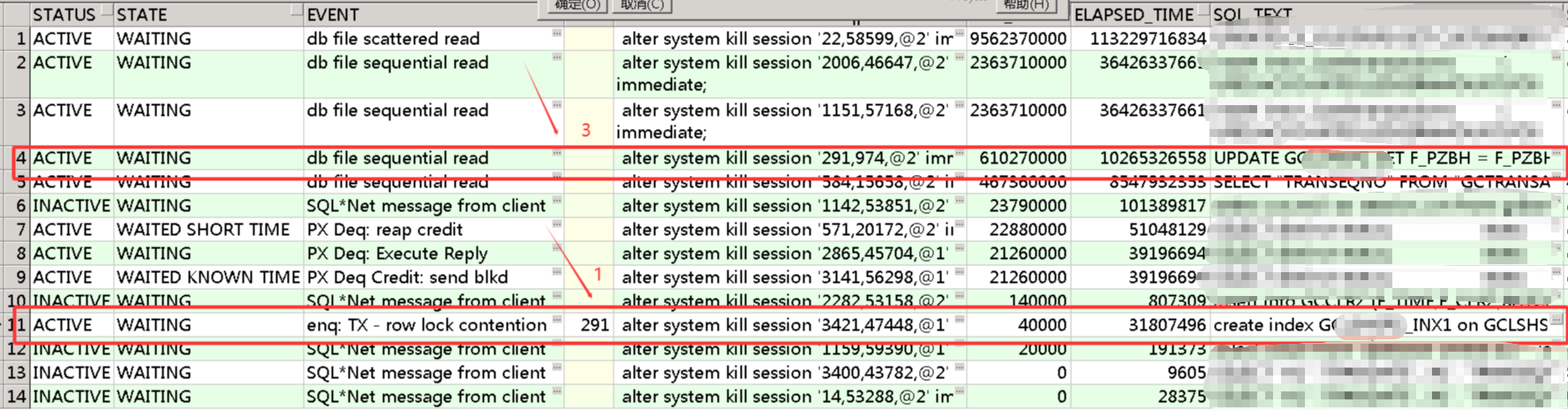
与业务人员的沟通如下
于是和业务人员沟通,该表涉及的业务是从什么时候开始的?
说是七年前
该表的运作方式是什么?
先delete符合条件的数据,然后再插入,保证数据正确
该表的数据是否都有用,是否能归档
回答都没用,可以直接清理
那清理的时候,如果是删除部分数据请用delete,然后我再清理碎片
如果是都没用,那就可以用truncate
然后再创建索引
沟通完以后,按照我说的操作,第二天再问 昨天跑过去了,按昨天提到的新加索引和truncate 表,确实有效果 20分钟就能跑完整个存储过程
Part3结论
此次很大原因是因为业务方面的原因引起的,业务和我沟通说,有没有从数据库参数或者硬件方面来进行优化,方便让数据库的抗压能力更强一些。于是我再次分析一遍。
Part4再次分析
4.1、确认问题SQL
UPDATE GC SET F_PZBH = F_PZBH||'-'||DECODE(MOD(F_FZBH, 900), 0, TRUNC(F_FZBH/900), TRUNC(F_FZBH/900)+1) WHERE BATCHNO=:B1 AND F_FZBH > 900
4.2、慢SQL等待事件
查询aayzbsy56gm8u相关等待事件,
5月7日6:25至9:45,有大量IO等待,plan_hash_value3434759413。
5月7日11点至11:15,执行sql产生IO等待,plan_hash_value210362714。
还发现4月8日和4月24日的记录,plan_hash_value3434759413。
ALTER SESSION SET nls_date_format='YYYY-MM-DD HH24:MI:SS';
set linesize 200 pagesize 2000
col min(sample_time) for a25
col max(sample_time) for a25
col event for a37
col sql_opname for a10
col cc for 9999
col wait_class for a20
col PROGRAM for a24
col MODULE for a24
col MACHINE for a20
col program for a24
col inst_id for a10
col bid for 99999
col bid# for 99999
col sample_time for a26
col p1 for 999999999999999
col p2 for 999999999999999
col p3 for 999999999999999
select instance_number,
event,
sql_id,
TOP_LEVEL_SQL_ID,
SQL_PLAN_HASH_VALUE,
SQL_EXEC_ID,
BLOCKING_SESSION bid,
BLOCKING_SESSION_SERIAL# bid#,
min(sample_time),
max(sample_time),
count(*) cc
from DBA_HIST_ACTIVE_SESS_HISTORY
where sample_time >
to_date('2026-04-01 00:00:00', 'yyyy-mm-dd HH24:Mi:SS')
and sample_time <
to_date('2026-05-09 00:00:00', 'yyyy-mm-dd HH24:Mi:SS')
and sql_id = 'aayzbsy56gm8u'
group by instance_number,
event,
sql_id,
TOP_LEVEL_SQL_ID,
SQL_PLAN_HASH_VALUE,
SQL_EXEC_ID,
BLOCKING_SESSION,
BLOCKING_SESSION_SERIAL#
order by min(sample_time);
看 cc(等待次数)最大的几行,揪出主要矛盾。
看 event 列,明确具体在等什么。
看 BLOCKING_SESSION,如果有值,定位阻塞源。结合 min/max(sample_time) 判断阻塞持续了多久。
看 SQL_PLAN_HASH_VALUE,如果同一个 sql_id 对应多个不同的执行计划(多个哈希值),那大概率是执行计划出了问题。
4.3、查看执行计划
查询aayzbsy56gm8u执行计划。
set pagesize 2000
set linesize 200
col options for a15
col operation for a28
col object_name for a26
select sql_id,
plan_hash_value,
id,
operation,
options,
object_name,
depth,
cost,
to_char(TIMESTAMP, 'yyyymmdd hh24:mi:ss')
from DBA_HIST_SQL_PLAN
where sql_id in ('aayzbsy56gm8u', '6jkhy0kyaqta8')
order by sql_id, plan_hash_value, ID, TIMESTAMP;
两个执行计划类似: 执行1000秒的执行计划,plan_hash_value210362714使用索引GC_INX1,产生时间2026年5月7日23点;
执行3000多秒没有执行完的执行计划,plan_hash_value3434759413使用索引PK_GC,产生时间2026年1月1日。
4.4、查看表结构
GC 表和PK_GC 索引创建时间2026年2月6日,GC _INX1创建时间5月7日,最后一次ddl操作2026年5月7日22点。
这条sql检查问题的和他的索引的相关信息,尤其是创建时间
alter session set NLS_DATE_FORMAT="YYYY-MM-DD HH24:MI:SS";
set pagesize 2000
set linesize 200
col owner for a20
col object_name for a28
select OBJECT_ID,
OWNER,
OBJECT_NAME,
OBJECT_TYPE,
CREATED,
LAST_DDL_TIME,
TIMESTAMP,
STATUS
from dba_objects
where object_name in
('PK_GC', 'GC_INX', 'GCZ_INX1', 'GC')
and owner = 'CW5';
这条sql是确定这个表的索引的涉及的列
SELECT i.owner AS index_owner, i.table_name, i.index_name, c.column_name
FROM all_indexes i
JOIN all_ind_columns c
ON i.owner = c.index_owner
AND i.index_name = c.index_name
WHERE i.owner = 'CW5'
AND i.table_name = 'GC'
ORDER BY i.index_name, c.column_position;
这里确定的是表的层级和大小
SELECT b.tablespace_name,
a.owner,
a.index_name,
a.blevel,
ROUND(b.bytes / 1024 / 1024, 2) AS mb,
b.blocks
FROM dba_indexes a
JOIN dba_segments b
ON a.owner = b.owner
AND a.index_name = b.segment_name
and a.owner = 'CW5'
and b.segment_name = 'GC'
-- and a.index_name = '待定'
WHERE b.segment_type = 'INDEX';
在这里需要注意blevel层级越小,使用情况越好,搜索成本越低
索引GC_INX1是在5月7日22点新建的,只包含sql查询必须的列。索引PK_GC比GC_INX1包含更多列,索引大小是GC_INX1的6倍,而且层级3比GC_INX1多1级,查询GC_INX1的效率显然更好。
4.5、查看内存使用情况
查看内存自动调整情况
5月7日sga占用6G,pga占用15G,sga中buffer pool占用700M,shared pool占用5G。
set pagesize 2000
set linesize 200
col inst_idfor 99
SELECT INST_ID,
start_time,
end_time,
component,
oper_type,
initial_size / 1024 / 1024 ASinitial_mb,
target_size / 1024 / 1024 AStarget_mb,
FINAL_SIZE / 1024 / 1024 ASfinal_mb
FROM gv$memory_resize_ops
order by start_time;
set pagesize 2000
set linesize 200
col inst_id for 99
SELECT INST_ID,
start_time,
end_time,
component,
oper_type,
initial_size / 1024 / 1024 AS initial_mb,
target_size / 1024 / 1024 AS target_mb,
FINAL_SIZE / 1024 / 1024 AS final_mb
FROM gv$memory_resize_ops
order by start_time;
set pagesize 2000
set linesize 200
col BEGIN_INTERVAL_TIME for a30
col NAME for a30
col pool for a20
select HS.BEGIN_INTERVAL_TIME,
ss.SNAP_ID,
ss.DBID,
ss.INSTANCE_NUMBER,
ss.NAME,
ss.POOL,
round(ss.BYTES / 1024 / 1024, 2) MB
from DBA_HIST_SGASTAT ss, dba_hist_snapshot hs
where SS.SNAP_ID = HS.SNAP_ID
and SS.INSTANCE_NUMBER = HS.INSTANCE_NUMBER
and bytes > 10000000
and ss.instance_number = 2
and name in ('buffer_cache')
and HS.BEGIN_INTERVAL_TIME >
to_date('2026-05-07 17:00:00', 'yyyy-mm-dd hh24:mi:ss')
and HS.BEGIN_INTERVAL_TIME <
to_date('2026-05-08 10:00:00', 'yyyy-mm-dd hh24:mi:ss')
order by ss.snap_id;
这里忘了截图,后来数据库也不让登陆了,就把语句发出来吧
Part5再次总结
综上,查询了aayzbsy56gm8u的执行情况和等待事件,数据库内存使用情况。
影响aayzbsy56gm8u执行效率主要是由于扫描主键效率太低,更换成扫描索引GC_INX1的执行计划之后效率明显提升。
5月7日17点至23点buffer cache大小并没有显著变化,17点至23点64M,24点192M。
因为修改内存参数需要重启数据库,建议先绑定执行计划或者添加使用GC_INX1的hint,如果采取这些措施之后还有严重性能问题,再考虑修改内存参数。
Part6备注
不懂的知识总结
1、索引建好的一瞬间需要一个数据字典锁library cache锁,所以就算创建索引加了 online ,也会卡住
2、索引的层级的知识点
