




一、概述
在一次SQL优化过程中,我们在金仓数据库中观察到一个有趣的现象:当使用 LIKE 进行后模糊匹配查询,且查询条件的过滤性极佳时,优化器竟然没有选择走该字段上的索引(索引默认使用数据库的排序规则,本例中为 en_US.utf8)。这一行为颇为反常。解决方法是,单独创建一个排序规则为 “C” 的索引,才能促使优化器使用索引扫描,从而显著提升查询速度。
然而,若该字段上仅存在排序规则为"C"的索引,当查询使用该字段进行精确匹配时,该索引又无法被利用。因此,如果业务上同时需要支持LIKE后模糊匹配与精确匹配、并都希望走索引扫描,则需要在该字段上分别创建两个索引。总结如下:
- 对于排序规则为en_US.utf8的索引,LIKE后模糊匹配查询会导致索引失效。
- 对于排序规则为C的索引,精确匹配查询会导致索引失效。
同一字段上建立两个索引的弊端:一是额外占用存储空间;二是增、删、改操作需同步维护双索引,带来额外的写入性能开销。下文将首先明确本次测试所涉及的金仓数据库版本信息,随后对该现象进行具体演示。
补充:当创建索引,未通过关键字collate明确指定排序规则时,索引默认使用创建数据库时所指定的排序规则。
二、问题复现
1.测试环境
测试环境数据库版本为 KingbaseES V009R001C010,创建数据库时指定兼容模式为 Oracle,默认排序规则(collate)为 en_US.utf8。
test=# select version();
version
-------------------------
KingbaseES V009R001C010
(1 row)
test=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Iculocale | Access privileges
-----------+--------+----------+-------------+-------------+-----------+-------------------
kingbase | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | |
security | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | |
template0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | =c/system +
| | | | | | system=CTc/system
template1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | =c/system +
| | | | | | system=CTc/system
test | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | |
(5 rows)
test=# show database_mode;
database_mode
---------------
oracle
(1 row)
2.测试数据构建
通过generate_series()内置函数,快速生成10w行数据。
create table t3 as select generate_series(1,100000) id,'xxxxdsgxx' name;
insert into t3 values(100001,'dgaha');
3.问题复现
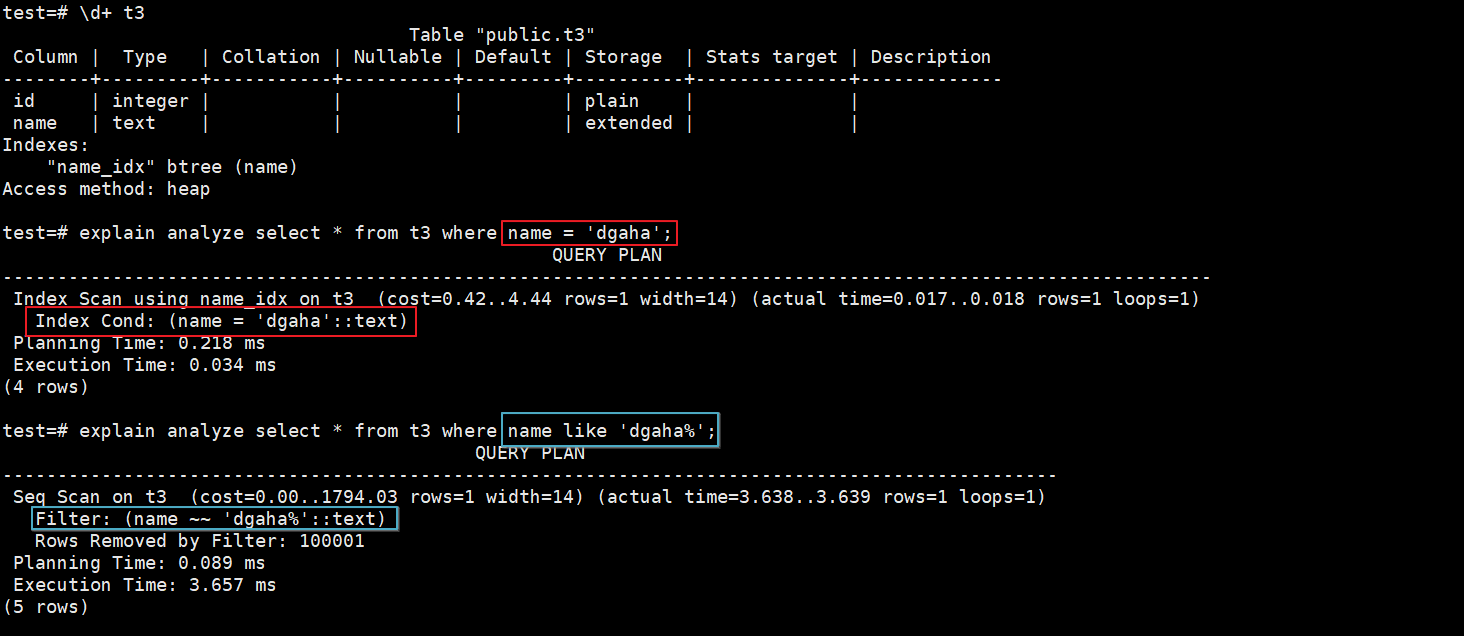
情况一:对name列创建索引,排序规则使用默认的en_US.utf8。测试结果发现LIKE后模糊匹配查询会导致索引失效,如下:
create index name_idx on t3(name);
explain analyze select * from t3 where name = 'dgaha';
explain analyze select * from t3 where name like 'dgaha%';
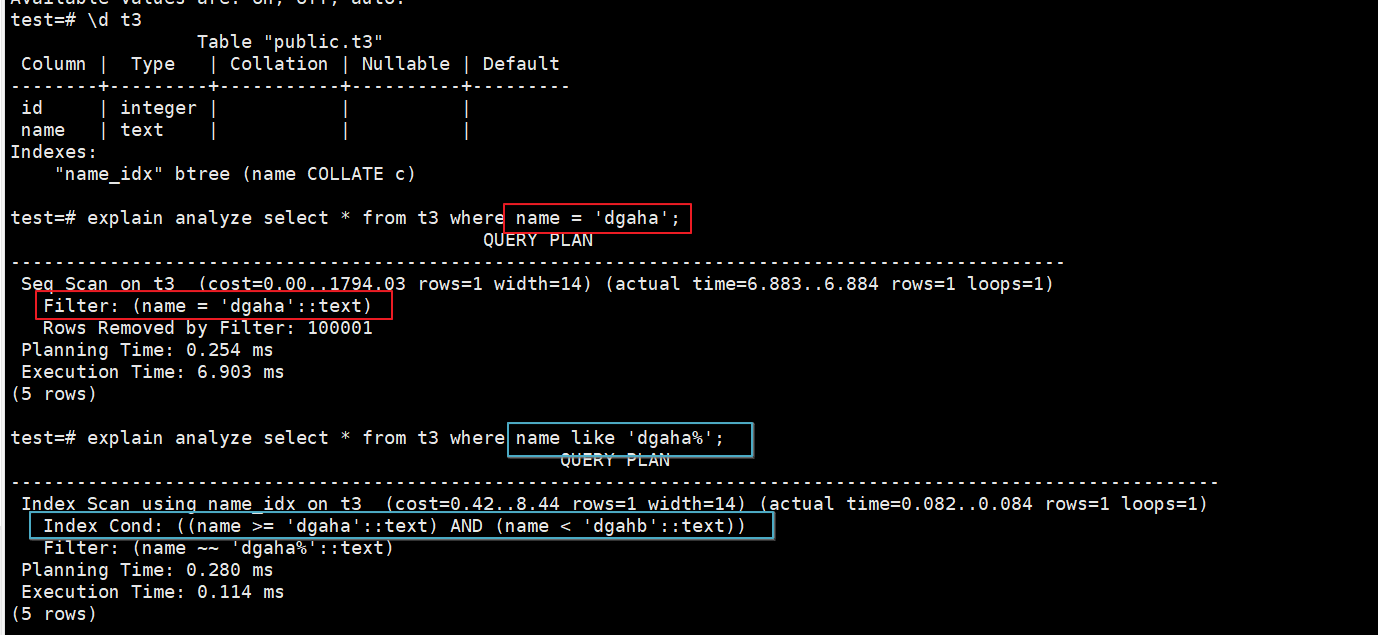
情况二:对name列创建索引,通过collate指定索引排序规则为“C”。测试结果发现精确匹配查询会导致索引失效,如下:
create index name_idx on t3(name collate "C");
explain analyze select * from t3 where name = 'dgaha';
explain analyze select * from t3 where name like 'dgaha%';
情况一:当上述两个索引同时存在时,针对like后模糊匹配及精确匹配查询,优化器会选择相应的索引访问数据,如下:
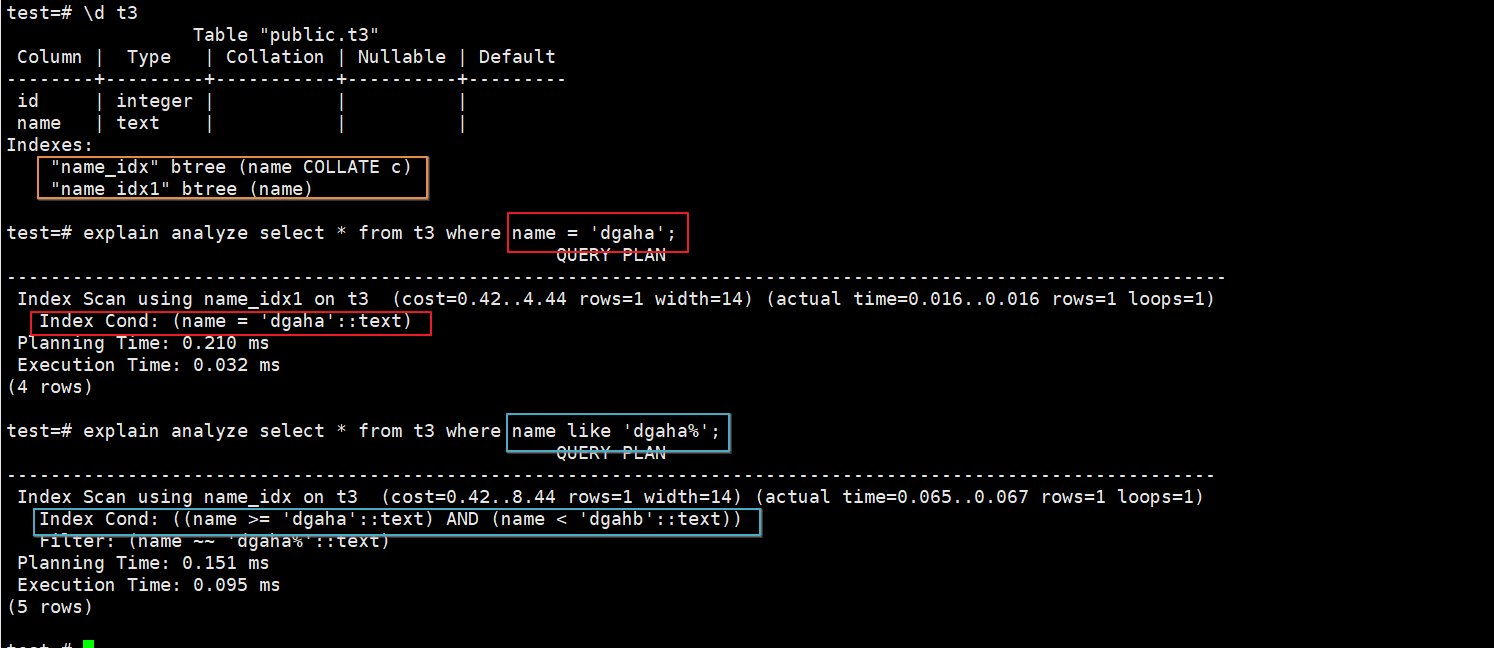
按理来说,这种情况不应该出现才对。
