




背景
在某省级政务数据平台的国产化信创改造项目中,数据库采用 KingbaseES 部署于鲲鹏 920 + 麒麟 V10 环境(ARM 架构)。业务系统通过 KFS 实现源端到目的端的实时数据同步。
在一段时间内,KFS 先后两次出现同步卡顿现象,导致业务数据中断同步。本文记录完整的故障排查与根因分析过程,并给出解决方案,供同类场景参考。
系统环境
| 项目 | 信息 |
|---|---|
| 硬件平台 | 鲲鹏 920(ARM 架构) |
| 操作系统 | 麒麟 V10 |
| 数据库 | KingbaseES(人大金仓) |
| KFS 版本 | v2(故障发生时版本) |
| 部署形态 | 国产化信创服务器 |
一、故障现象
两次故障(相隔约 48 小时)的现象高度一致:
- KFS 进程解析的 Seqno(序列号)停止递增,长时间不变;
- 数据库同步事件(Events)不再产生,目的端无法收到新数据;
- 源端数据库持续有写入,但同步链路完全停滞;
- 业务侧表现为目的端数据延迟累积,存在数据丢失风险。
故障影响范围:
- 数据同步链路中断,目标端数据库更新停滞;
- 业务数据无法实时同步,运维需人工介入重启 KFS 进程恢复。
二、诊断过程
2.1 第一次故障
Step 1 — 确认故障现象
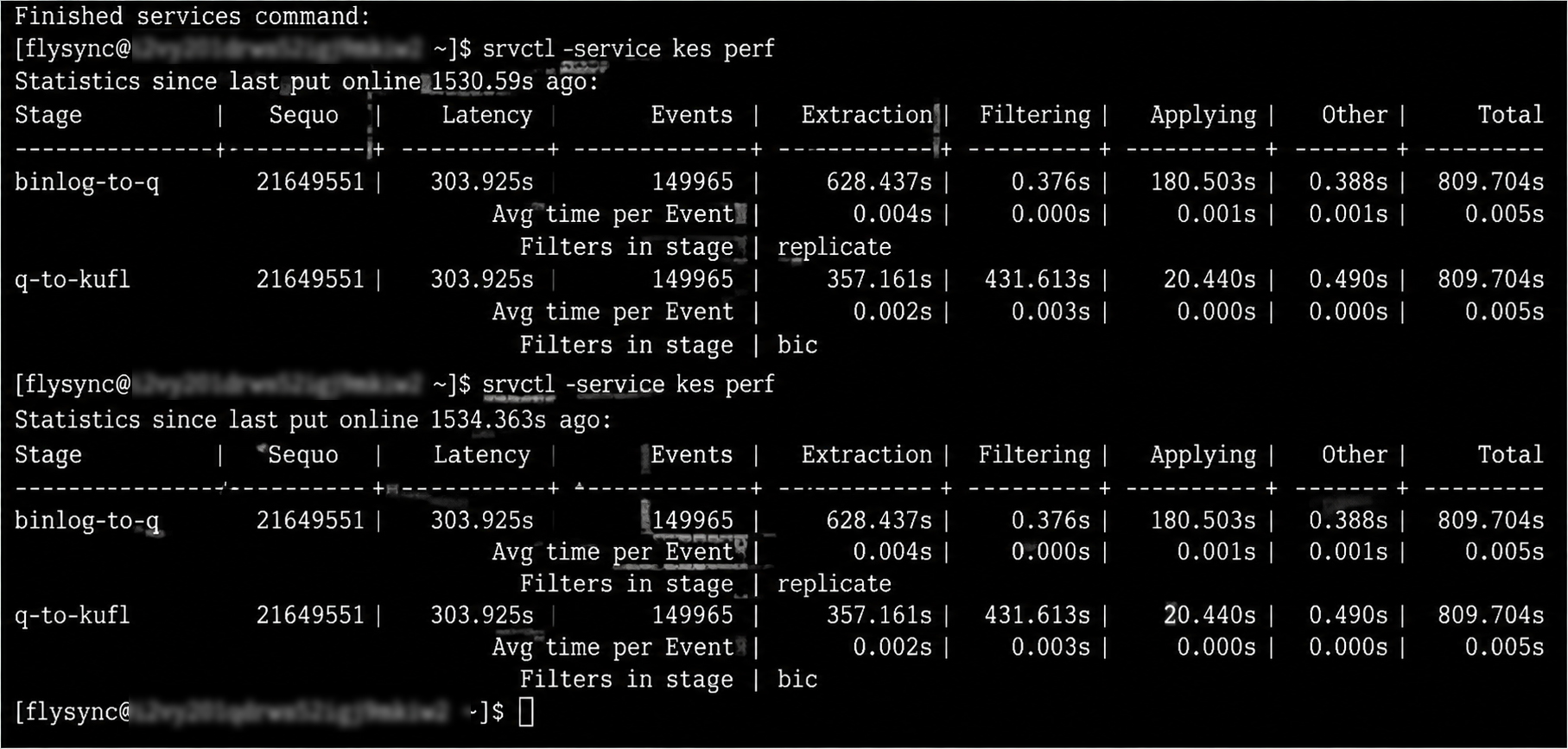
登录 KFS 管理控制台,观察核心监控指标:
Seqno: [停止递增,长时间无变化]
Events: [停止产生,无新同步事件]
两项指标同时静止,可确认 KFS 同步链路已陷入停滞。
Step 2 — 保留故障现场
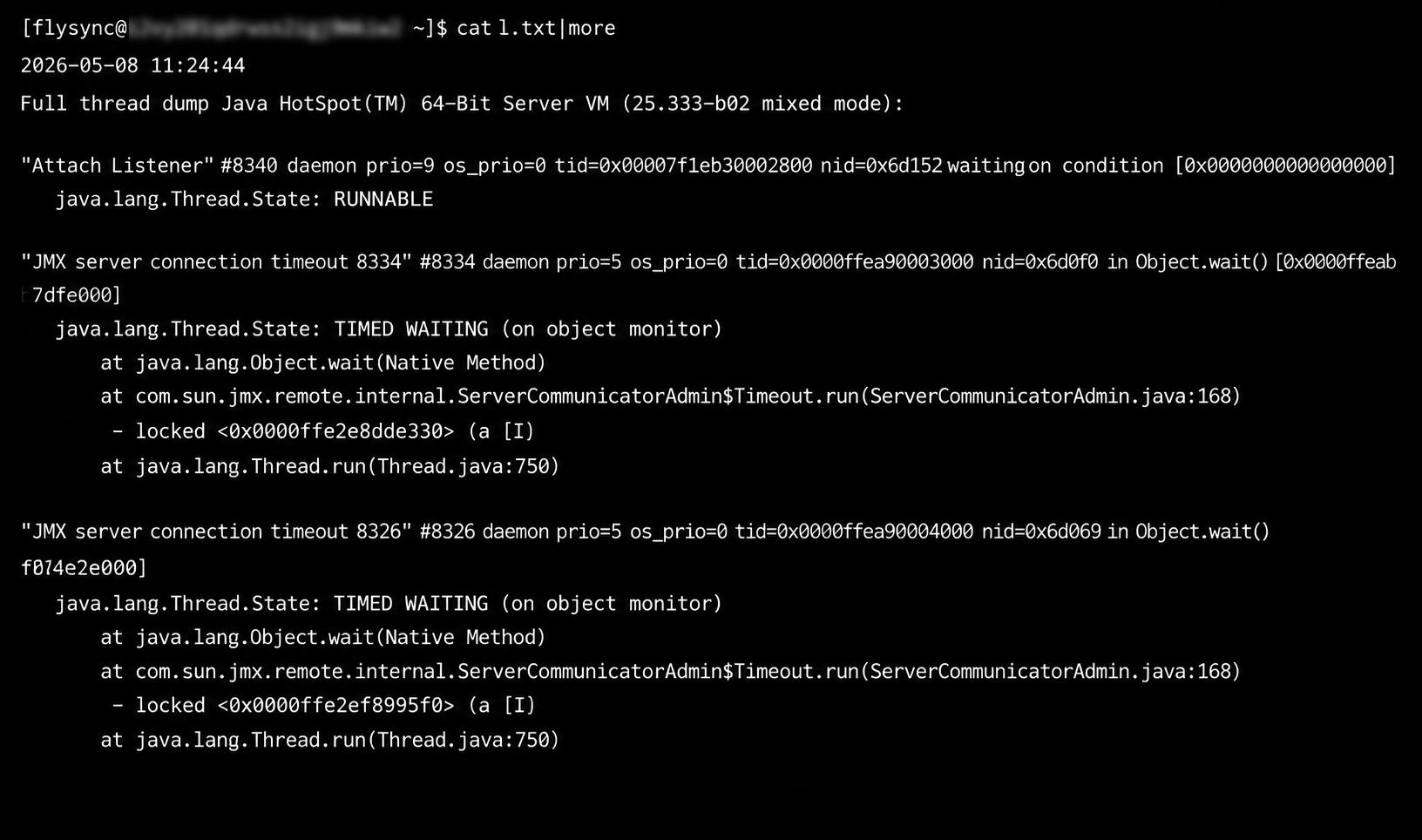
在重启 KFS 进程之前,先通过 jstack 命令输出 KFS Java 进程的线程栈快照:
保留现场数据是后续根因分析的关键,切勿在收集诊断信息前直接重启。
Step 3 — 重启恢复
执行 KFS 进程重启,Seqno 恢复递增,同步链路恢复正常。
Step 4 — 初步日志分析
分析 KFS 日志中 KUFL(KingbaseES Undo File Log) 的详细内容,发现一个关键异常:
初步判断与长事务相关。
2.2 第二次故障(约 48 小时后)
故障症状与第一次完全一致。此次在重启前额外补充了以下诊断动作:
- 再次收集 jstack:与第一次快照对比,排查线程死锁或长时间阻塞;
- 深入解析 KUFL:重点追踪
oldestLsn的历史变化曲线,验证长事务假设; - 确认两次 jstack 中均无死锁,线程阻塞点一致,进一步锁定根因。
2.3 根因分析
核心机制说明
KFS 在解析数据库日志时,需要持续跟踪最旧活跃事务的 LSN(oldestLsn)。其日志解析位点不能超过 oldestLsn,因为该事务随时可能回滚,需要保证日志的完整性。
问题链路
长事务长时间未提交
↓
oldestLsn 被"钉住",长时间不推进
↓
commitLsn 持续增大,与 oldestLsn 差值扩大
↓
KFS 日志解析线程进入等待/阻塞
↓
Seqno 停止递增,Events 停止产生
↓
同步卡顿
关键指标对比
| 指标 | 正常状态 | 故障时状态 |
|---|---|---|
| Seqno | 持续递增,随日志解析推进 | 停止变化,卡顿不动 |
| Events | 随数据变更事件持续产生 | 停止产生,无新事件 |
| oldestLsn | 随事务提交正常推进 | 长时间不推进,与 commitLsn 差距过大 |
| commitLsn | 与 oldestLsn 差距正常 | 远超 oldestLsn,差距持续扩大 |
根因结论
数据库中存在长事务(长时间运行、未提交),导致 KFS 的 oldestLsn 被锁定无法推进,日志解析线程进入阻塞状态,最终造成 KFS 同步卡顿。
此外,当前版本 KFS 缺乏针对长事务阻塞场景的自动恢复机制,卡顿后只能依赖人工重启,无法自愈。
三、解决方案
3.1 紧急处置
- 确认 KFS 卡顿后,立即通过
jstack保留故障现场; - 重启 KFS 进程,恢复数据同步链路;
- 重启后持续观察 Seqno 和 Events,确认完全恢复后方可结束处置。
3.2 短期方案(新版本上线前)
① 创建心跳表
通过心跳机制保持 KFS 日志解析端持续有新日志块可处理,规避因长时间无日志变化导致的解析停滞:
-- 创建心跳表
CREATE TABLE kfs_heartbeat (
id SERIAL PRIMARY KEY,
beat_time TIMESTAMP DEFAULT NOW()
);
-- 定时任务(每分钟写入一条心跳数据)
-- 可通过 crontab 或数据库 job 实现
INSERT INTO kfs_heartbeat (beat_time) VALUES (NOW());
KFS 目的端同步规则中配置过滤,排除 kfs_heartbeat 表,避免心跳数据污染业务库。
② 增加 KFS 监控告警
在监控平台对 KFS 的 Seqno 指标设置变化检测:
- 告警规则:若 Seqno 在 15 分钟内无变化,触发告警;
- 告警通知:推送至运维值班人员,要求 5 分钟内响应。
3.3 长期方案
① KFS 版本升级
新版本 KFS 针对长事务导致 oldestLsn 过旧的场景进行了专项修复,增加了自动检测与恢复机制,可从根本上解决该类故障。建议在新版本完成内部测试后,优先安排升级。
② 优化事务管理规范
- 控制事务粒度,避免大批量操作在单一事务中执行;
- 对必须运行的长事务,安排在业务低峰期执行;
- 定期(建议每日)巡检数据库中运行时间超过 30 分钟的未提交事务:
四、建议事项汇总
| 序号 | 建议事项 | 说明 | 优先级 |
|---|---|---|---|
| 1 | 创建心跳表 | 当前版本即可实施,有效防止卡顿 | 🔴 高 |
| 2 | 加强 KFS 监控告警 | Seqno 15 分钟无变化触发告警 | 🔴 高 |
| 3 | KFS 版本升级 | 新版本从根本上修复长事务阻塞问题 | 🔴 高 |
| 4 | 优化事务管理规范 | 控制事务粒度,定期巡检长事务 | 🟡 中 |
五、总结
本次故障的根因清晰:长事务 → oldestLsn 不推进 → KFS 日志解析阻塞 → 同步卡顿。这是一个在 CDC(Change Data Capture)类同步组件中较为典型的问题,不限于 KFS,在 Debezium、OGG 等工具中也有类似机制。
几个关键经验:
- 故障现场保留优先于快速恢复:jstack 日志是定位根因的核心证据,重启前务必先采集;
- 心跳表是低成本的有效防护手段:可在不升级版本的情况下显著降低卡顿概率;
- 长事务是 CDC 同步的隐患:数据库层面的事务管理规范与同步组件的稳定性高度相关,需要 DBA 与业务开发团队协同治理。
