




目录 · 逐层递进
起源 · The Origin
一、为什么 Agent 必须有记忆:技术起源
Agent Memory 这个技术方向的诞生,不是因为"有人觉得该加个功能",而是被一连串工程失败逼出来的。
1.1 种子:ReAct 的"边想边做"理想
2022 年,ReAct 论文提出了"让模型交替推理和行动"的范式——模型先想一步、产出一个动作、看到结果、再想下一步。这是 Agent 循环的概念原型。但论文只解决了"怎么想和做交替",完全没有回答一个关键问题:当任务越来越长,模型怎么记住之前想过什么、做过什么?
1.2 蛮荒时代的集体翻车
2023 年上半年,AutoGPT、BabyAGI 等第一批"全自动 Agent"刷屏。它们有循环、有工具,但几乎没有像样的记忆系统。结果是灾难性的:Agent 陷入死循环反复执行同样的操作、中途忘了最初目标、在已经解决的问题上继续叠加错误、烧光 token 预算却一事无成。这次集体翻车,让业界第一次明确意识到——光有模型和一个 while 循环远远不够,Agent 需要一个"记忆器官"。
1.3 根因:LLM 的"先天失忆症"
为什么必须有记忆?因为 LLM 的底层架构决定了它是一个纯函数(pure function)——每次 API 调用都是独立的,模型不"记得"上一句说了什么。它能"接着聊",纯粹是因为你把历史又喂了一遍。这带来三个结构性矛盾:
| 无状态 Stateless | ||
| 有界窗口 Bounded Context | ||
| 成本线性增长 Linear Cost |
一句话本质:LLM 被训练成"在给定文本上预测下一个词"的函数,而不是"在真实世界里持续完成目标"的主体。记忆系统,就是在模型的能力之外,用工程手段补齐"持久状态"这个它学不到的部分。
痛点 · Pain Points
二、六大痛点:没有记忆的 Agent 就是"每次都要重新培训的临时工"
记忆不是锦上添花的功能,而是把 Agent 从"一次性问答工具"变成"能长期协作的工作者"的必需品。每个痛点都直接对应商业价值:
售前话术:跟客户讲价值时可以这样收口——"模型决定 Agent 有多聪明,记忆决定它能不能长期、低成本、个性化地为你工作。没有记忆的 Agent,是一个每次都要重新培训、还记不住公司规矩的临时工。"
框架 · Taxonomy
三、认知科学框架:四类记忆——行业通用的讨论语言
客户技术同学张口就会提的,是这套借自人类认知科学的四分法。它已经成为讨论 Agent Memory 的"通用语言",务必记牢:
Working | |||
Episodic | |||
Semantic | |||
Procedural |
注意一个常被忽视的点:Skills AGENTS.md 本质上就是"程序记忆"。很多人以为 Memory 只指"记住事实",其实"记住怎么做事"(Procedural) 同样是记忆的一支。这也是为什么在 Harness 架构中,"指令层"和"记忆层"彼此渗透。
演进 · Evolution
四、演进脉络:从拼接历史到自组织记忆
Agent Memory 的技术演进,可以清晰地划分为五个阶段。每个阶段都在解决上一代遗留的核心缺陷:
图1 · Agent Memory 五代演进路线
一条主线贯穿始终:每当模型变强,人们先用它去挑战更长、更复杂的任务,而这些任务对记忆的要求只会更高。从"把历史全塞进去"到"让 Agent 自己管理记忆",这条线的方向是确定的——记忆系统越来越像人类的记忆机制。
核心 · Architecture Deep Dive
五、六大架构流派深度横评
截至 2026 年中,Agent Memory 领域形成了六大主流架构流派。每种流派解决的核心问题不同,适用场景也不同。下面逐个拆解。
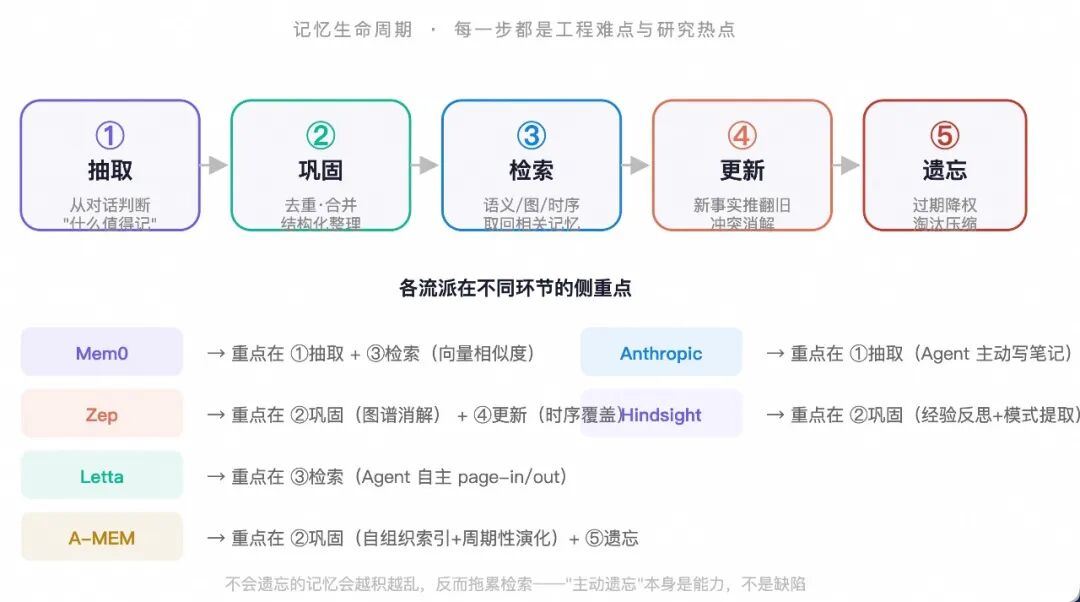
流派一:自动记忆抽取层 · 代表 Mem0
Mem0 · ECAI 2025 论文(arXiv:2504.19413) · GitHub 40K+ stars
核心思想:在对话流上插一个"自动抽取层",用 LLM 实时判断"什么值得记",把事实条目抽出来存进向量库+图数据库,下次需要时按语义相似度检索回来。
工作流程:
关键数据(ECAI 2025 论文):在 LOCOMO 基准上,Mem0 相比 RAG-only 方案实现了 91% 更低的 p95 延迟和显著提升的准确率。token 消耗大幅降低——因为不再每轮重喂全部历史,只注入检索到的相关记忆。
优势 · 即插即用,集成成本最低(几行代码) | 劣势 · 抽取质量依赖 LLM 能力(小模型效果打折) |
适用场景:通用对话记忆、客服机器人、个人助手、快速 POC 验证。
流派二:时序知识图谱 · 代表 Zep Graphiti
Zep · arXiv:2501.13956 · 基于 Neo4j · Graphiti 开源
核心思想:用知识图谱(而非向量库)作为记忆底座。每条事实是一个"节点",实体之间是"边",关键创新是给每条事实加上"有效时间区间"(valid_at invalid_at),让记忆能表达"事实会随时间变化"这个现实。
Graphiti 的核心机制:
优势 · 天然表达实体关系和时序变化 | 劣势 · 部署复杂(需要 Neo4j 实例) |
适用场景:事实强时效性、实体关系复杂的场景——金融投顾、医疗病历、CRM 客户关系管理、法务文档。
流派三:OS 式虚拟记忆 · 代表 Letta(原 MemGPT)
Letta · MemGPT 论文(arXiv:2310.08560) · Andrew Ng DeepLearning.AI 合作课程
核心思想:借鉴操作系统的虚拟内存管理——把 LLM 当 CPU,上下文窗口当 RAM,外部存储当硬盘。Agent 自己负责在"主存"和"外存"之间做分页调度(page in page out),就像一个操作系统管理内存那样。
核心概念——Memory Blocks:
关键创新在于:记忆的管理权交给了 Agent 自己。不是开发者写死"什么该存什么该取",而是给 Agent 一组 memory editing tools(core_memory_append、core_memory_replace、archival_memory_insert、archival_memory_search),让它自己决定何时读写。
优势 · 思想深度最强("LLM as OS"理论源头) | 劣势 · 自编辑记忆的可靠性依赖模型能力(小模型易出错) |
适用场景:需要完全可控的自托管 Agent 状态管理、研究型长对话、对记忆操作透明性要求高的企业场景。
流派四:自组织记忆 · 代表 A-MEM
A-MEM · NeurIPS 2025 · arXiv:2502.12110 · 动态索引+自我巩固
核心思想:让记忆系统像人脑一样"自组织"——不只是被动存取,而是会主动索引(Indexing)、巩固(Consolidation)、演化(Evolution)。这是目前学术界最前沿的 Agent Memory 架构之一。
三大核心机制:
优势 · 最接近人类记忆机制的设计 | 劣势 · 仍处学术阶段,产品化程度低 |
适用场景:需要长期积累和知识演化的场景——研究助手、知识管理、组织级知识沉淀。
流派五:结构化笔记 · 代表 Anthropic Claude Code
Anthropic《Effective context engineering for AI agents》· Claude Code · QoderWork
核心思想:最"工程化"的路线——不做复杂的自动抽取或图谱构建,而是让 Agent 自己把关键信息写到上下文窗口之外的文件里(如 MEMORY.md、NOTES.md),需要时再读回来。本质是"给 Agent 一个笔记本"。
Anthropic 提出的两个核心打法:
Manus 的实践补充:2025 年 Manus Agent 公开了其上下文工程经验——核心也是"让 Agent 把记忆写到文件里"。关键设计是可恢复的快照机制:Agent 周期性地把当前工作状态序列化到文件,任务中断后可以从快照恢复,避免长任务的"失忆"问题。
优势 · 工程化程度最高,已在 Claude Code/QoderWork 大规模验证 | 劣势 · 记忆质量完全依赖 Agent 的"笔记能力" |
适用场景:编码 Agent、桌面助手、任务型 Agent、需要记忆透明可控的场景。
流派六:经验学习记忆 · 代表 Hindsight
Hindsight · arXiv:2512.12818 · Vectorize.io · 2025-2026 新兴
核心思想:不只是"记住事实",更要"从经验中学习"。Hindsight 把 Agent 的历史交互视为一种可回放的"经验流",记忆系统负责从中提取可复用的模式和教训(而非单纯的事实条目),并在未来类似场景中主动提示。
与 Mem0 的"抽取事实"不同,Hindsight 更强调"记住做过什么、学到了什么、下次该怎么做"。这更接近人类的"经验记忆"——你不只记得"那个 bug 在 line 42",更记得"遇到类似报错时应该先检查依赖版本"。
优势 · 从经验中提取可复用模式,Agent 越用越聪明 | 劣势 · 较新,生态和社区尚不成熟 |
适用场景:编码 Agent、运维自动化、任何需要从"踩坑经验"中持续学习的场景。
全景 · Architecture Landscape
六大架构流派全景对比图
图2 · 六大架构流派定位图(横轴=结构化程度,纵轴=自主管理程度)
评测 · Benchmarks
六、基准评测之争:LOCOMO 上的"罗生门"
谈 Agent Memory 就绕不开评测基准。目前最主流的基准是 LOCOMO(Long Conversation Memory)和 LongMemEval。但围绕 LOCOMO 分数的争议,恰恰揭示了当前评测体系的深层问题。
6.1 LOCOMO 基准简介
LOCOMO 是 2024 年发布的 Agent Memory 评测基准,用长对话(平均 9K 轮、300K+ token)生成后提问,测试 Agent 对多类型信息的记忆能力。它覆盖五类问题:单跳事实、多跳推理、时序判断、对话摘要、和模糊查询。
6.2 各家声称的分数与实际争议
售前必知的"评测陷阱":Agent Memory 领域的 LOCOMO 分数目前不可直接横向比较。各家使用的评测配置(模型、prompt、检索策略)差异很大,且基准本身存在"短对话题准确率虚高"的问题。建议跟客户沟通时,不要只看一个数字,而是关注具体场景下的实测结果。
6.3 比分数更重要的三个维度
选型 · Decision Matrix
七、一张总表:六方案选型决策矩阵
这是你可以直接拿去跟客户对话的选型总表。核心决策变量是"你的记忆要不要表达时间变化和实体关系"——要,就往图谱走;不要,向量抽取层就够。
快速POC | CRM | 研究型对话 | 长期积累 | 任务型Agent | 经验学习 |
售前选型速记口诀:"快速 POC 找 Mem0,时序关系上 Zep,完全可控选 Letta,长期沉淀看 A-MEM,编码任务 Anthropic 自带,踩坑学习 Hindsight。先问客户——'你的记忆要不要表达时间变化和实体关系?'要,往图谱走;不要,向量抽取就够。"
未来 · Future Directions
八、未来方向
8.1 五个值得关注的演进方向
主要参考:Mem0 ECAI 2025 论文 (arXiv:2504.19413) · Zep/Graphiti 时序知识图谱 (arXiv:2501.13956) · MemGPT/Letta "LLM as OS" (arXiv:2310.08560) · A-MEM 自组织记忆 (NeurIPS 2025, arXiv:2502.12110) · Hindsight 经验学习记忆 (arXiv:2512.12818) · Anthropic《Effective context engineering for AI agents》· Manus 上下文工程实践 · LOCOMO / LongMemEval 评测基准 · EVOLVE-MEM 自适应层级记忆 (NeurIPS 2025) · G-Memory 多Agent层级记忆追踪 (NeurIPS 2025) · MemMachine 基准评测 (arXiv:2604.04853) · LangMem SDK (LangChain 2025)。具体数字与版本以各厂商官方最新文档为准。
