






以下为论文内容介绍:
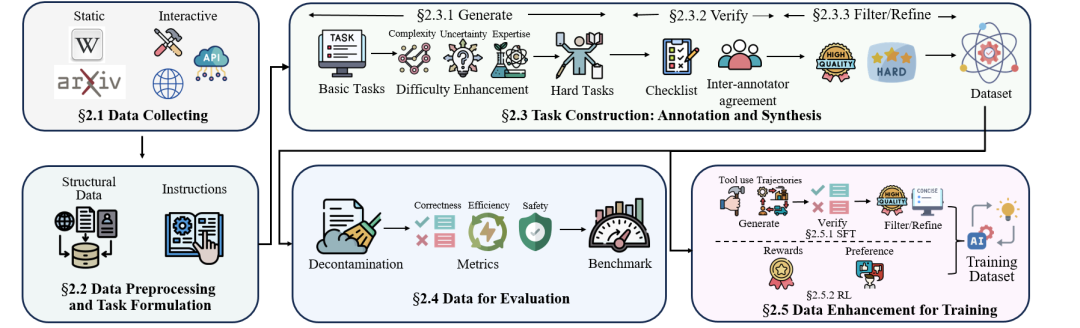

论文项目页:https://github.com/fatty-belly/Awesome-AgenticRAG-Data/
由上海交通大学计算机学院周煊赫教授团队联合 OceanBase 等研究团队共同完成的研究成果《Automating Database-Native Function Code Synthesis with LLMs》被数据库领域国际顶级会议 SIGMOD 2026 正式录用。
近年来,数据库等大型系统的代码量急剧增长,其复杂的开发需求给开发工程师带来了巨大难题;与此同时,即便借助现有的自动化编码智能体(Coding Agent)框架,也难以高效应对这类高耦合代码仓库的增量开发。
针对这一双重挑战,该论文创新性地提出了首个面向数据库内核函数生成的专用编码智能体——DBCooker。
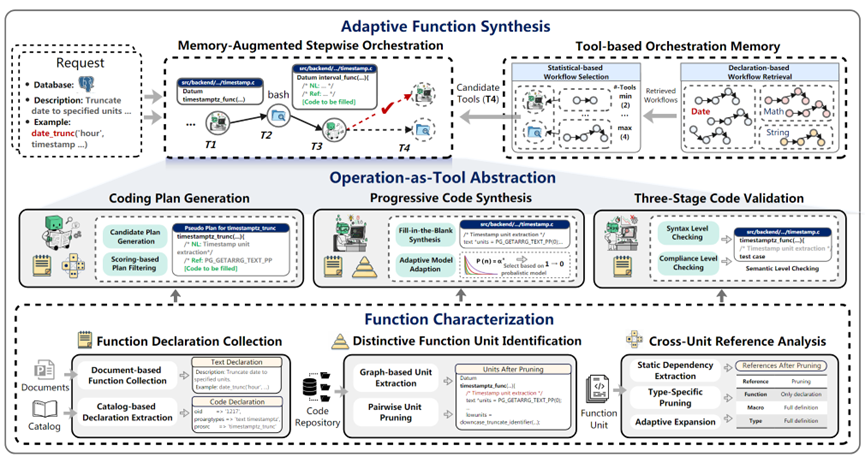
DBCooker 架构示意图
该框架通过函数特征分析、函数生成算子、自适应工具编排等核心模块,在多个真实数据库源码测试中取得了显著优于通用框架(例如,Claude Code)的编译成功率和结果准确率,平均准确率提升达 34.55%,有效解决了数据库内核函数生成的难题。
此外,DBCooker 针对数据库内核函数生成中“多处注册、大量引用、任务差异”三大难点,首次将静态分析引导的模板提取、填空式代码生成与自适应工具编排有机融合,形成了一套可落地的专用智能体方案。
这项工作的核心价值在于:将高耦合代码仓库的增量开发,从“人力密集、易错难验”的工程活动,转化为“模板引导、按需编排”的可自动化任务,为数据库内核及其他大型系统软件的高质量演进提供了新的技术路径。
论文链接:https://dl.acm.org/doi/10.1145/3802018
项目主页:https://code4db.github.io/hi-opencook/
代码仓库:https://github.com/OpenDataBox/OpenCook
由华东师范大学与OceanBase团队联合撰写的论文《Automatic Parameter Tuning for Compaction in LSM-Tree based Databases》被数据库领域顶级会议 ICDE 2026 接收。
该论文首次提出“Compaction 引起的性能波动”应该成为 LSM-Tree 数据库调优的目标,并通过自动化参数调优的方法,有效缓解了 LSM-Tree 在合并时引起的性能波动,提升延迟、吞吐量和 CPU 利用率的稳定性。
ICDE 是数据库领域顶级学术会议之一,与中国计算机学会(CCF)推荐的 A 类会议 SIGMOD、VLDB 并称为数据库三大顶会。
在现代数据库系统中,LSM-Tree(Log-Structured Merge Tree)已经成为 OceanBase、RocksDB 等主流存储引擎的核心架构。它最大的优势在于:能够以极高的写入吞吐支撑海量数据场景。但与此同时,一个长期困扰工业界的问题也随之而来——Compaction(压缩合并)。
为此,论文提出了:MerTune —— 面向 LSM-Tree Compaction 的自动化参数调优系统。
MerTune 的整体架构由三部分组成:Compaction Characterization Layer(合并行为分析层)、LLM-Assisted Knowledge Generation(LLM 参数知识提取层)、Knowledge-Guided Bayesian Optimization(知识驱动的贝叶斯优化引擎)。
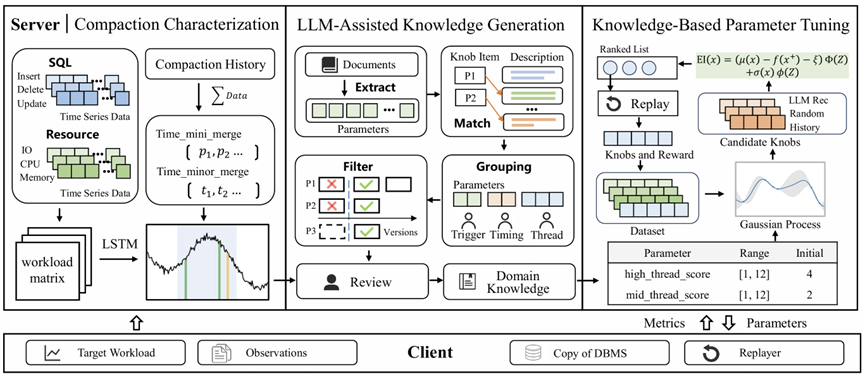
MerTune 整体系统架构
为验证 MerTune 性能,研究团队在 OceanBase 使用 Sysbench 和 TPC-C 进行评测,并与 SMAC、GP、DDPG++、GPTuner 等主流自动调优方法进行了对比。
在 Sysbench 写密集场景中,MerTune 显著降低了 Compaction 导致的性能抖动。
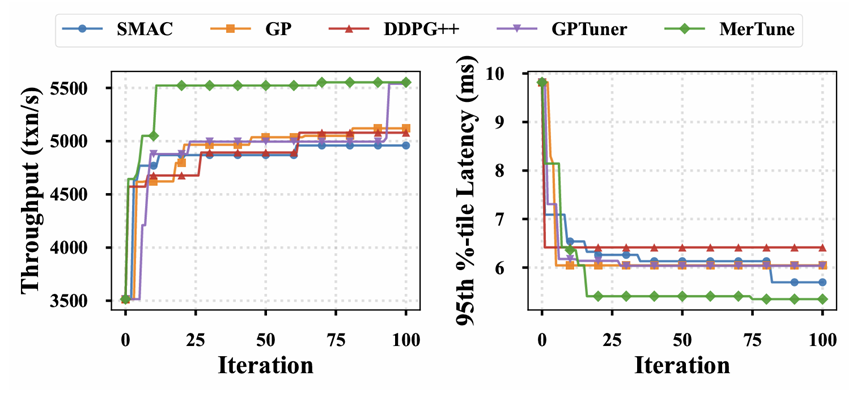
Sysbench 调优效果
在 TPC-C OLTP 场景下,MerTune同样表现突出。
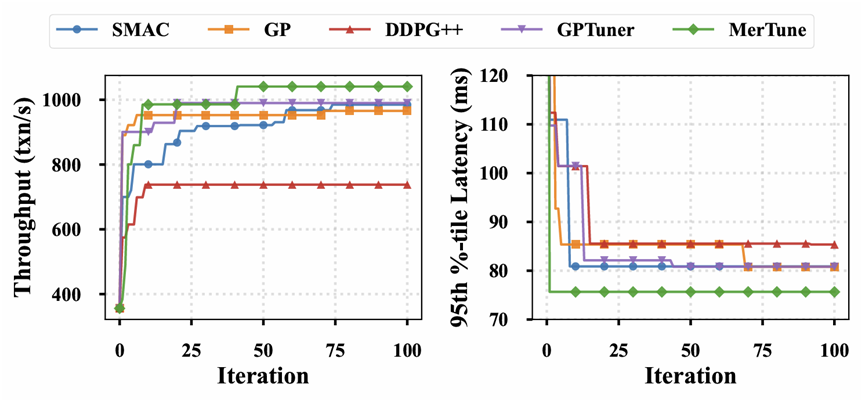
TPC-C 调优效果
论文还进一步评估了Compaction 导致的 CPU Spike。
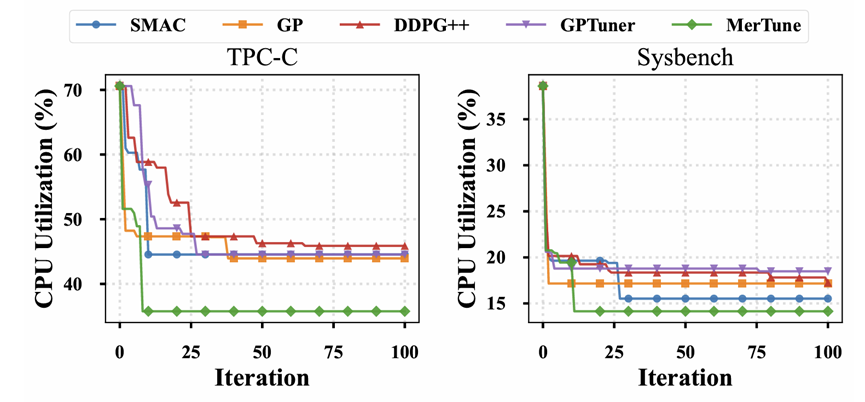
CPU 利用率波动优化
MerTune 通过 Compaction 行为建模、LLM 参数知识抽取、知识引导的贝叶斯优化,构建了一套面向工业生产环境的智能调优系统。
相比传统调优系统,MerTune 更关注:性能稳定性、SLA 保证、系统鲁棒性。这也代表了数据库自动化运维未来的重要方向:从“追求极致性能”转向“追求稳定、可预测、低风险的性能”。




▼点击「阅读原文」,查看星闻热点
