




不止湖仓一体!Databricks Lakebase 湖库一体,解锁 AI 原生统一数据底座
2025年Databricks在Data+AI峰会上推出了一款数据库:“Lakebase”,这是一款首创的、专为 AI 打造的完全托管 PostgreSQL 数据库。通过 Lakebase,Databricks 为其数据智能平台增加了一个运营数据库层。2020年左右湖仓一体这一关键技术出现后为OLAP业务提供了巨大支撑,现在湖库一体的关键技术即将在AI时代为AI融合发挥巨大作用。
1、lakebase是什么
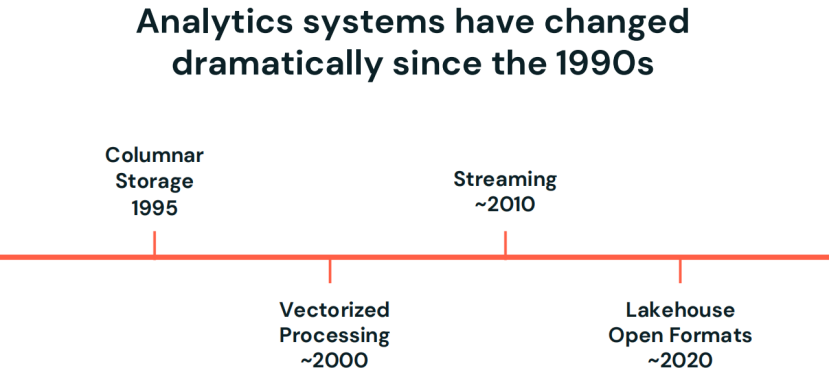
自从1990年代以来,分析系统经理了四次重大技术革命:从列存到向量处理再到流处理和湖仓一体。而OLTP数据库仍旧沿用着几十年前的架构。如今,由于环境和负载的变化,OLTP系统也迎来了技术拐点:一种新型、开放、可扩展的OLTP架构,作为湖仓一体的一种进化形态技术在AI时代出现了,他就是Lakebase--湖库一体。
Databricks对lakebase的定义:
Lakebase is a new database architecture that separates compute from storage, keeping data in a low-cost, open format cloud object storage while a serverless Postgres engine runs elastically on top. This design enables instant scaling, branching and unified transactional and analytical workloads, making it a cloud-native, AI-era reinvention of the traditional database.
A Lakebase is a new, open architecture that combines the best elements of transactional databases with the flexibility and economics of the data lake. Lakebases are enabled by a fundamentally new design: separating compute from storage and placing the database’s data directly in low-cost cloud storage (“lake”) in open formats, while allowing the transactional compute layer to run independently on top。
总而言之,LakeBase 作为统一数据基座,融合数据湖的可扩展性与数据库高性能、ACID 事务优势,依靠实时处理能力放大 AI 驱动的数据洞察价值。
2、为什么需要lakebase
AI正在从“查询方式、数据形态、开发节奏”三个维度重写数据库负载。
OLTP方面:AI编码写代码比人快4倍以上,催生处了高频开发循环,80%的新库都由AI创建,由此需要毫秒创建分支、秒级启动和一键回滚的能力;匿名数据集、沙箱环境需求量暴涨,推动“Serverless + 免费分支”成为默认。
OLAP方面:访问模式从“一条大 SQL”变成“投机式多小查询”,Agent 先并行发 50–100 条轻量查询探路,再拼出最终答案。传统 BI 的“巨型关联 SQL”被拆成“多轮小 SQL + 向量语义搜索”,对引擎提出“高并发轻查询 + 向量索引”双重要求。
共性需求:向量搜索与语义算子支持。
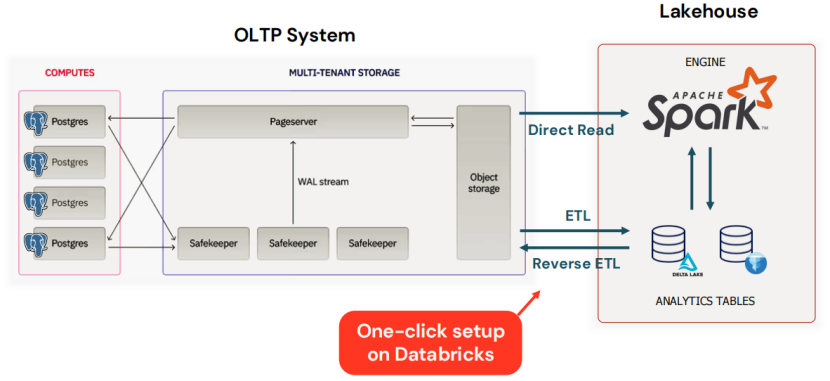
如下图所示,OLTP接入湖仓时,需要ETL等从湖读数据,做AI等分析时无法在库内完成所有操作:
3、lakebase的核心特性
3.1存算分离
这里先看下以往存算分离的架构以便区分lakebase的存算分离有何不同。
3.11 Polardb for PgSQL存算分离
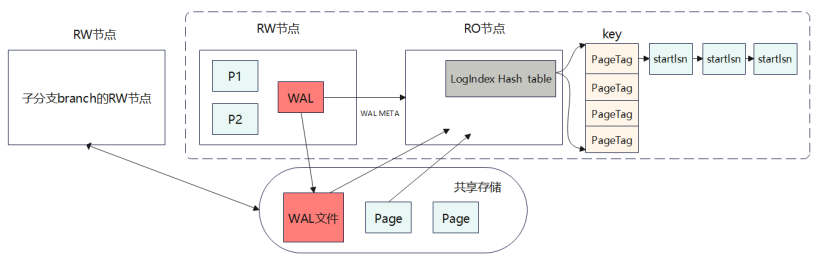
以PolarDB for PgSQL的存算分离架构为例,它的架构以日志即数据为核心:
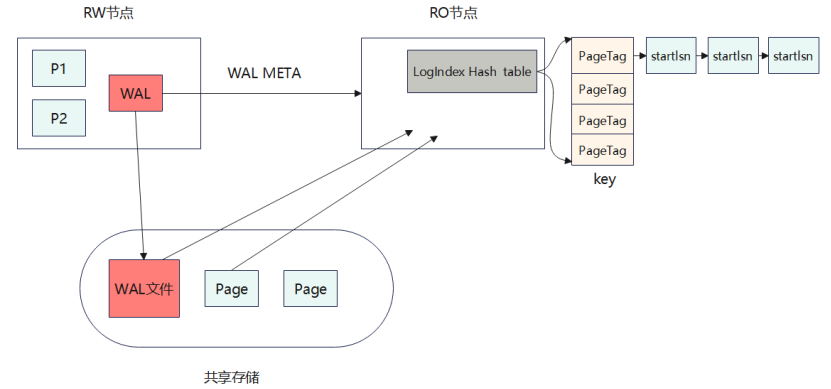
简单来说,WAL META就是WAL日志中除去数据部分的头,包括页号、起始lsn等信息;
WAL META传递到RO节点后,RO节点进行解析,将其转换到LogIndex Hash table中,其中key是PageTag:表空间OID+表OID+页号,唯一确定一个数据页,value是修改该数据页的WAL日志的头部位置,也就是起始LSN。
同一个桶以递增的形式形成一个链表。构建好后更新该lsn结束位置作为Apply LSN,超过这个位置的WAL不能回放,因为还没有解析到logindex hash table中,找不到 WAL、事务可见性信息不全,数据不一致。普通读查询的 target_lsn 直接等于这个 Apply LSN,因此页面回放截止点最大不会超过它。
共享存储中不进行回放,它的数据页仅由RW节点异步刷脏。
当RW节点checkpoint后,会将checkpoint lsn发给RO节点,将该lsn位置之前的lsn从logindex hash table中删除。
所以,RO节点的回放的基准数据页总是在共享存储中,一旦RO节点数据页没有命中时,需要从共享存储加载上来,然后看下该数据页是否需要回放,如果需要则从startlsn位置开始从共享存储取WAL然后回放,直到回放到apply lsn位置,然后返回给上层,由MVCC机制判断里面数据是否可见。如果命中,需要回放则基于该数据页进行回放。
总的来说:RW节点的数据需要异步写到共享存储,需要给RO发送WAL META供其解析成log index;RO节点需要加载基准数据页,在此基础上从start lsn位置加载WAL进行回放;由MVCC机制决定回放出来的数据页里面数据是否可见。
3.12 Neon PgSQL存算分离
接下来看下lakebase中的存算分离:Neon serverless postgres结构。
Lakebase首先需要支持存储与计算分离,然后才可以很好地提供即时分支、scale-to-zero等能力。下面是databaricks的存算分离架构,由Postgres的内核大佬Heikki领衔开发的NEON无服务PG架构(开源):
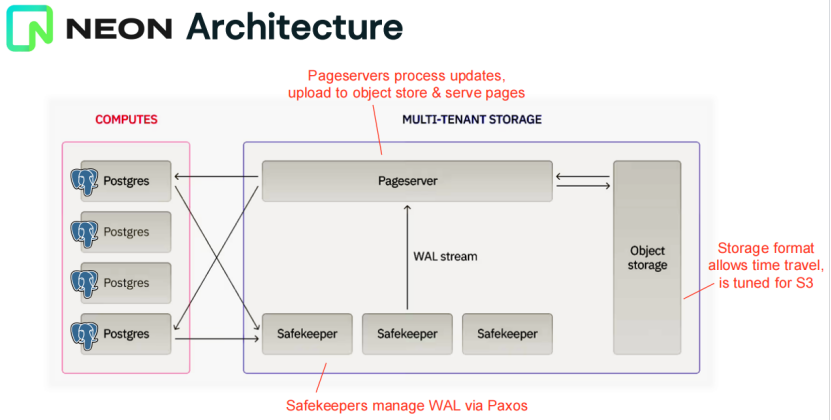
具备存储与计算分离、单写节点和多读节点、多租户存储、单租户计算以及copy-on-write branching能力。
上图中各个部件说明:
1)computes:负责计算以及事务和锁的管理,这部分基本是原来PgSQL的代码,在原来基础上hook了对SMGR存储部分的代码。读数据页时,从Pageserver获取,另外新创建了一个WAL proposer进程将WAL同步到Safekeeper。
2)Safekeeper:WAL服务,负责持久化WAL日志,这里一个Safekeeper接收到WAL后会将其写到本地的SSD盘,并且通过Paxos实现3副本以保证WAL的高可靠和高可用。
3)Pageserver:存储服务,负责重放从Safekeeper过来的WAL日志,并解析成自己的格式。相应compute的GetPage的请求到来时,按需重放WAL,并定期把快照写入上述的Object Storage。
4)Object storage:保存Safekeeper和Pageserver的数据。
和以往存算分离架构不同的是,neon的计算层的脏页不会持久化共享存储。原理说明:
1)safekeeper负责接收RW节点的WAL日志,并会存储到safekeeper的本地磁盘。
2)Pageserver会消费safekeeper的WAL。
3)Pageserver分为数据镜像层和deta wal层。其中数据镜像层作为数据恢复的基准数据页,最开始的镜像由initdb或者pg_basebackup等导入时生成的基础数据,后续的数据镜像快照都是基于这个开始构建的,pageserver解析WAL时仅生成deta wal;deta wal层是解析后提取变更,保存增量修改内容,以key+lsn+value三元组的形式写入内存增量层。WAL转换到增量层后,safekeeper层对应的WAL就可以清理掉了。
4)内存增量层和数据镜像层会定期持久到到对象存储
5)内存增量层可以合并成一个大的增量
6)当增量大小超过比如10GB的时候,就基于上一个镜像+回放增量WAL形成一个新的镜像
7)当然还可以设定一个周期,时间到了,就基于上一个镜像+增量WAL回放形成一个新镜像
下面以一个例子来说明如何生成镜像:

1)初始基线镜像层:image_1000,对应lsn=1000,表示1000之前wal都生成到镜像中形成全量页面快照了
2)已落盘的5个delta层及大小如上图所示,按照lsn先后排序,范围互不重叠
3)调度配置阈值:镜像生成的增量阈值假设10GB,表示上一个镜像后累计增量超过10GB就强制生成新镜像
4)最大回溯深度:3层,表示单词页面读取最多穿过3个delta层
5)GC保留地平线:LSN3000,表示早于3000的历史数据允许被回收
场景一:累计增量触发
这个是最常见的触发方式,由空间比例阈值驱动。触发条件:image_1000之后的delta总大小=2+2.5+2+2.5+1.8=10.8GB,超过了10GB的镜像生成阈值。目标LSN选择:直接取最新delta层的结束编辑,也就是delta_5的end_lsn=7000。执行:选取7000之前最近的镜像也就是image_1000为基准,将delta_1到delta_5的更新合并到image_1000中,生成新镜像image_7000,即lsn=7000时刻的全量页快照。后续影响:image_1000+delta_1-delta_5都是历史层,超过PITR保留窗口的可以被GC回收,新读取从image_7000开始,回溯深度是零。
场景二:回溯深度触发
当写入速度快、增量还没有攒够阈值,但读放到已经超标时,触发生成新镜像。触发条件:假设当前只生成到delta_4,总大小是9GB还未到10GB,此时读取最新的LSN=6100的页面,需要从image_1000触发,依次穿过delta_1、delta_2、delta_3、delta_4,共4层,超过了最大回溯深度3层。目标LSN选择:选择回溯路径中间delta层边界,即delta_2的end_lsn=3500。执行结果:生成中间镜像image_3500。效果:读取lsn>3500的页面,从image_3500出发,仅需要穿过delta_3和delta——4,符合深度要求。不用等增量攒满10GB,提前控制读延迟,避免性能劣化。
场景三:GC需求出发
垃圾回收必须有基线镜像才能安全清理旧数据。触发条件:GC的地平线是LSN=3000,意味着系统可以回收早于3000的历史数据。但此时3000之前仅有image_1000,没有更近的镜像,如果删除掉image_1000,3000之前就没有镜像快照,历史数据无法读取。硬约束:目标LSN必须是delta的边界,不能选3000,所以选择delta_1的end_lsn=2200作为目标LSN。执行结果:生成镜像image_2200。后续有了image_2200,更早的image_1000就可以回收了。
场景四:delta层合并,不生成新镜像
这类compaction只合并小增量层,输出delta层,不涉及镜像生成。触发条件:写入流量波动大,短时间生成了大量小体积的L0 delta层比如delta_a(1000-1200)、delta_b(1200-1500)、delta_c(1500-1800)...累计超过L0层的阈值。目标LSN:被合并的最后一个delta层end_lsn=2100,起始LSN取第一个层的start_lsn=1000。合并成1个大的L1 delta层,LSN范围1000-2100,可以范围不变。
3.2写时复制的瞬时branch能力
分支本质是元数据级操作,而非物理数据复制。
1)创建分支时,系统仅生成一个指向父库共享存储的新指针,并标记分支的起始分歧点,不复制任何实际数据页。因此无论父库是 MB 级还是 TB 级,分支创建都是时间复杂度 O (1) 的操作,可在 1 秒内完成,创建初始不产生额外存储开销。
2)分支创建后与父库共享所有未修改的数据页;只有当分支内发生写入(数据修改、Schema 变更等)时,被修改的数据页才会单独存储,形成分支独有的数据。整个过程中父库的数据完全不受影响,分支与父库、分支与分支之间实现物理级隔离。
和postgres的备机promote提升时间线,变成主是一个原理,但是promote是主备复制之间发生故障被动提升的,而这里的分叉是主动行为。
假设研发需要一份和当前线上完全一致的数据,搭建一个独立的测试环境,不能更改线上数据。
1)在平台上选择线上集群,在当前运行点位LSN=2000的位置创建新分支test_branch
2)给测试分支单独部署一个RW读写计算节点
3)Pageservver自动给测试分支分配全新时间线TL2,比如下图的子branch
4)线上原有集群不受影响,继续在TL1上正常业务写入
5)研发连接的test_branch的RW节点做测试修改,所有变更全部写入TL2的日志文件中
分叉结果:以LSN 2000为分界,分裂TL1和TL2两个时间线

分支行为瞬时完成,不会回放WAL,仅新建独立的时间线,写入元数据:父分支ID、branchpointlsn。查询访问时按需回放,pageserver检索页面需要找到branchpointlsn前面最近的镜像点,从最近的镜像开始回放delta到分叉点,然后再将该页返回。分支进行写时,将日志通过写到safekeeper中(由时间线等标记日志是该分支的),这个WAL和父分支没有关系。
分叉点lsn强制落在事务提交的边界,所以分支回放到branchpointlsn点的数据页一定是一致的。
3.3无限、低成本、高持久化存储
数据存放在数据湖中,存储容量近乎无限,成本远低于需要固定容量基础设施的传统数据库。同时,其存储依托云对象存储(如 S3)的持久化能力,默认提供 11 个 9(99.999999999%)的数据持久性,远优于传统数据库通过副本实现存储冗余的方案 —— 传统方案大多采用异步更新,意味着多数配置下若发生双重故障,存在数据丢失的风险.
3.4弹性serverless Postgres 计算
Lakebase 提供全托管的无服务器 Postgres 服务,可随业务需求即时扩容,空闲时自动缩容。成本与实际用量完全匹配,非常适合波峰波谷明显的突发型负载、开发环境,以及 AI 智能体临时启动实例的场景.
3.5事务与分析负载一体化
Lakebase 可与湖仓一体(Lakehouse)架构无缝集成,在 OLTP(联机事务处理)与 OLAP(联机分析处理)场景下共享同一存储层。这意味着用户可以直接基于事务数据运行实时分析、机器学习与 AI 优化任务,无需搬运或复制数据.
3.6原生开放与多云兼容
以开放格式存储的数据避免了专有格式锁定,可在 AWS、Azure 等多云环境间实现真正的可移植性。用户对数据拥有完全自主权,不再受引擎厂商的深度绑定,锁定程度大幅降低。内置的多云灵活能力支撑容灾部署、长期技术自主,且能长期优化成本效益。
4、参考材料
https://www.databricks.com/blog/what-is-a-lakebase
https://www.databricks.com/product/lakebase
https://www.bilibili.com/video/BV1Y84y1B7kX/?vd_source=10ce859f3f7b1da2094a1283c19fe9b9
https://www.databricks.com/blog/enabling-evolutionary-database-development-database-branching-lakebase-part-3
https://www.databricks.com/blog/enabling-evolutionary-database-development-database-branching-lakebase-part-2
https://www.databricks.com/blog/enabling-evolutionary-database-development-database-branching-lakebase
https://zhuanlan.zhihu.com/p/624075600
https://github.com/neondatabase/neon
