




电力行业大概是国内对"数据"二字最敏感的行业之一。
从调度中心那块几米宽的大屏,到风机塔筒里密密麻麻的传感器;从千家万户的智能电表,到储能电站里每秒跳动的BMS数据——每一秒都在产生海量带时间戳的数据。这些数据怎么存、怎么查、怎么分析,直接关系到电网安不安全、新能源能不能消纳、电力市场交易效率怎么样。
这篇文章,我把最近研究的几块内容串起来聊聊。如果你正在做电力行业的数据库选型,或者手头有个信创替代的任务,希望这篇文章能给你一些参考。
01. 电网调度时序数据:从产生到入库的全链路
1.1 数据从哪来
电网调度系统的时序数据来源可以归纳为三层架构,每层产生的数据特征和频率都不一样。
最上层是广域监测层,WAMS系统通过PMU(同步相角测量单元)采集电网主要节点的电压相角、频率、功率,响应时间是毫秒级,百毫秒量级。目前主要覆盖220kV及以上电压等级。
中间层是调度控制层,EMS能量管理系统通过SCADA和RTU采集遥测、遥信、遥控、遥调数据,采集频率是秒级或分秒级。这是时序数据的最大来源。以华北电网某省调D5000系统为例,日均处理SCADA点位超2,000万,历史库容量年增15TB。
最下层是配电执行层,DMS配电管理系统通过DTU/FTU和智能电表采集配变状态、线路负载、用户用电数据,采集频率通常是15分钟级。
除了这三层,还有AGC自动发电控制系统,每4到8秒计算一次区域控制偏差ACE,实时下发机组出力指令。以及配电自动化系统,覆盖配电变压器5,000+台实时监测、数百万只智能电表、分布式电源出力数据等。
1.2 数据怎么写进数据库
从现场设备到数据库,典型的数据流是:现场设备通过RTU/PMU/DTU采集数据,经过调度数据网传输到前置机,前置机完成协议解析后写入时序数据库。
写入方式主要有三种。
第一种是直接协议写入。SCADA系统通过IEC 60870-5-104、IEC 61850、DNP3.0等电力标准协议,批量缓冲写入,每批次1,000到10,000条记录,与SCADA扫描周期同步,通常1到5秒一个周期。同时会同步写入数据质量码,标记数据是好、坏、可疑还是替代值。
第二种是异构数据库同步写入,这在信创替代场景很常见。以金仓时序数据库替代InfluxDB的实践经验为例,典型的双轨写入架构分为三步:第一步通过异构同步工具实时捕获原时序库的写入流,借助Telegraf输出插件捕获数据流并转换为标准SQL;第二步通过时序语法兼容层将InfluxQL自动翻译为标准SQL窗口函数和时间分组逻辑;第三步灰度双轨并行,所有写入同时发往新旧两套系统,读请求按灰度比例分流。金仓时许数据库的中广核案例中,最终验证查询响应小于200毫秒,原系统平均480毫秒,错误率0%,数据一致性100%。
第三种是边缘中心协同写入,针对新能源场站分布广、网络条件差的场景。场站侧部署边缘数据库节点,本地缓存7到30天数据,网络恢复后自动补传断点数据。Apache IoTDB支持边缘设备直接生成标准TsFile文件批量上传至中心,边缘侧先压缩再传输,降低带宽占用。
1.3 写入性能怎么优化
分片策略是写入性能的关键。采用时间维度加业务维度的组合分片模式,按季度切分主时间轴,再按区域进行二级划分。批量写入和缓冲机制也很重要。单批次写入1,000到50,000条记录,前端采集与后端写入解耦,通过内存队列缓冲。
金仓数据库的中广核某案例中,600多个场站并发写入,集群整体吞吐从35万点/秒提升到82万点/秒。金仓集群的写入P99延迟稳定在86毫秒,而原系统峰值曾达到11.3秒,集群整体吞吐从35万点/秒提升至82万点/秒。
02. 电力行业六大核心应用场景
时序数据库在电力行业的应用,可以归纳为六大场景。
场景一:发电侧集中监测。覆盖火电、水电、风电、光伏场站内成百上千台设备的运行参数、故障信号、环境数据。某省级电力集团覆盖全省200多个新能源场站,接入设备超15,000台,日均10亿+数据点。
场景二:智能电网调度支撑。依托时序数据库对输变电设备的电压、潮流、谐波等毫秒级数据进行实时采集与分析,支撑调度决策系统完成风险识别、负荷预测与异常预警。
场景三:新能源出力辅助分析。融合气象、历史出力、设备状态等多源数据,构建标准化时序数据,为AI建模提供高质量训练样本。
场景四:电网设备状态监测与预测性维护。对变压器油温、开关柜局放、电缆接头温度等关键参数持续监测,实现从被动抢修到主动预防。
场景五:虚拟电厂与需求响应。聚合工商业用户、储能电站、充电桩等资源参与电力市场交易。典型规模包括500+用户、100MW光伏、50MW储能、10,000+充电桩,需要实时监测各聚合资源的运行状态和可调节能力。
场景六:储能系统管理。储能电站的充放电状态、SOC、温度、电压、电流等参数需要高频采集和实时分析。核心监测指标包括电芯级电压/温度/内阻、模组级SOC/SOH、系统级充放电功率,以及热失控早期特征识别。

03. 电力行业时序数据库选型全景
3.1 主流产品速览
| 产品 | 所属公司 | 开源协议 | 核心定位 |
|---|---|---|---|
| 金仓数据库 | 电科金仓(原人大金仓) | 商业版 | 多模融合数据库(含时序引擎) |
| Apache IoTDB | 天谋科技 | Apache 2.0 | 工业物联网时序数据库 |
| DolphinDB | 智臾科技 | 商业版/社区版 | 时序数据库+分析平台 |
| InfluxDB | InfluxData(国外产品) | MIT/商业版 | 通用时序数据库 |
| TimescaleDB | Timescale(国外产品) | Apache 2.0/商业版 | 时序+关系型融合 |
| KaiwuDB | 浪潮开务 | 商业版 | 多模融合数据库 |
3.2 场景化选型建议
| 场景 | 推荐产品 | 核心理由 |
|---|---|---|
| 省级电网调度/SCADA | 金仓 / IoTDB | 国产化要求、多模融合、高可靠 |
| 变电站/配电设备状态监测 | 金仓 / IoTDB | 树状模型贴合设备层级、端边云协同 |
| 虚拟电厂运营平台 | 金仓 / IoTDB | 高并发写入、实时聚合、灵活标签 |
| 储能系统BMS数据管理 | 金仓 / IoTDB | 高频采集、毫秒级响应、长周期存储 |
| 大规模新能源集控(十万级设备+) | IoTDB | 高基数稳定、高压缩比、集群成熟 |
| 电力市场交易分析 | DolphinDB / TimescaleDB | 复杂时序分析、流计算、SQL灵活度 |
| 信创替代项目 | 金仓 / DolphinDB / IoTDB | 全面国产化适配、等保合规、本地化服务 |
04. 金仓时序数据库技术内核深度解析
4.1 公司简介
中电科金仓(北京)科技股份有限公司(简称“电科金仓”)成立于1999年,是中国电子科技集团成员企业,专注国产数据管理软件研发与服务,核心产品为金仓数据库管理系统KingbaseES。金仓数据库在北京、成都、天津、青岛、西安等地设有研发和服务中心,服务网络覆盖31个省、自治区、直辖市及港澳地区,产品应用于电子政务、国防军工、能源等超过20个行业,累计部署超百万套。
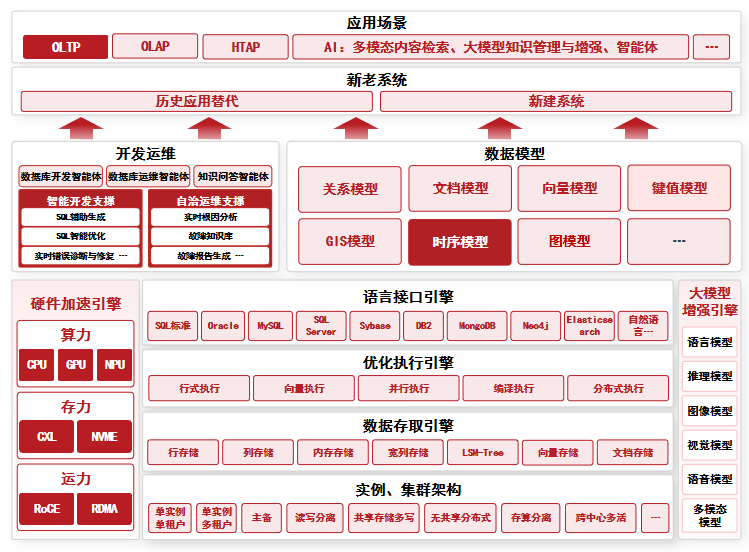
4.2 金仓数据库融合多模架构
金仓数据库 KES V9 采用融合数据库架构,由五大核心引擎协同工作:语言接口引擎支持Oracle、MySQL、SQL Server、PostgreSQL等多种数据库方言;优化执行引擎集成行式执行、向量执行、并行执行、编译执行、分布式执行等多种模式;数据存取引擎支持单实例、主备集群、读写分离、共享存储多写RAC、Shared Nothing 分布式、存算分离等多种部署架构;多模数据模型引擎原生支持文档模型、向量模型、OLAP分析模型、时序模型;大模型增强引擎集成语言模型、推理模型、图像模型等AI能力。
这种融合架构的核心价值在于:跨模型联合查询可以在同一数据库内原生支持时序数据、关系数据、文档数据的SQL联合查询;HTAP能力使得一份数据同时支撑高并发写入和复杂分析;TCO可降低35%到50%,开发周期缩短40%。
4.3 时序存储引擎核心技术
金仓时序数据库在存储引擎层面引入了专门的时序优化机制。核心设计包括:Append追加写模式避免传统B+树更新的随机I/O开销;文件预扩展机制提前分配存储空间;增量检查点技术缩短检查点时间;日志压缩减少WAL磁盘占用;无锁化设计通过MVCC实现读写互不阻塞;异步I/O充分利用现代存储设备的并发处理能力。此外还支持批量插入、乱序插入、插入时即时完成压缩、压缩状态下快速更新、并行插入等高级特性。
金仓时序数据库采用两级压缩架构:一级压缩针对数据,根据不同类型自动匹配压缩算子;二级压缩针对页面,在数据压缩基础上进一步压缩存储页面。
对于冷数据,支持行中列级压缩,每列数据聚合到一个数组中,约1,000行一组进行压缩。压缩效果方面,随机数压缩率高达6:1,数字压缩率高达10:1,冷数据压缩比可达3到20倍。在某省煤矿安全监测项目中,30万个传感器数据压缩比达到1:10。
金仓时序数据库采用基于行列引擎的HTAP执行框架。在OLAP分析场景中,经常涉及大量数据的查询分析,而参与计算的仅涉及一个宽表的少数列。传统行式存储以行为单位读取,会引入与目标数据无关的数据列的读取,造成大量I/O浪费。KES的解决方案是采用列式存储,按需读取列的数据,节省I/O。不参与计算的列可以延迟读,并通过粗糙集过滤提高查询性能。列的数据特征相似,适合压缩,用户可自定义压缩等级,节省存储空间,进一步减少I/O。在复杂查询场景下,表的列数越多,查询涉及的列越少,性能提升越高。
4.4 查询引擎四大性能优化
向量化执行模型。替代传统火山模型,每次从下游算子读取上千行数据而非一行,减少函数调用次数,批量按列计算充分利用CPU Cache,利用CPU多核并行处理并支持SIMD加速。
基于任务拆分的查询并行技术。充分利用SMP架构中的多核处理器,多核心同时处理同一个查询的不同数据分片。在复杂查询场景下,根据CPU核数、并行度等情况,性能可提升数倍。
基于LLVM的表达式动态编译执行。引入LLVM即时编译技术,在运行时生成专用机器码,消除大量冗余逻辑。在复杂查询场景下,根据表达式的复杂程度和数据量,性能可提升50%甚至数倍。
分区剪枝与执行计划优化。自动识别查询条件中的时间范围,仅扫描相关分区,避免全表扫描。针对高并发分区表查询进行了专项优化:在分区总数2000、索引数量10、剪枝后剩余子分区1000的场景下,500并发持续5分钟测试,响应时间快10倍以上,内存占用减少90%。
4.5 时序分析能力:从聚合到预测
KES TSDB支持连续聚合和实时聚合两种互补方法。连续聚合通过预计算和自动更新汇总信息来提高查询性能,适用于需要快速访问历史趋势分析的场景。实时聚合提供即时响应能力,并支持复杂的动态窗口函数,适合实时监测和当前状态分析。
支持分层聚合,在连续聚合上继续创建连续聚合,以不同时间间隔级别处理数据,实现从细粒度到粗粒度的逐层聚合、逐层复用。例如在一个时间间隔为1小时的连续聚合之上,创建时间间隔为1天(24小时)的连续聚合,再创建时间间隔为1个月的连续聚合。分层聚合比在表上直接创建一个时间间隔为1天的连续聚合更有效,因为复用了时间间隔为1小时的连续聚合结果,减少了重复扫描。提供了专门的Top-N聚合函数,通过分区内局部计算避免全表排序,大幅提升性能。例如min_n_by和max_n_by函数,可以获取分组内最小或最大的N个值,并关联返回其他列数据。
在AI能力方面,KES TSDB支持数据写入即分析、实时产生决策,从"事后复盘"进化到"事前预判"。内建分析预测功能包括智能填补缺失值、近似分位数、统计聚合、回归分析、数据降采样、特征工程。还内置基本的ML能力,支持模型的训练和预测。开放集成能力支持与流式分析引擎集成,在写入路径上直接完成聚合、异常检测;支持与外部模型集成,通过SQL扩展接入开源模型。从数据采集到决策反馈的全流程延迟控制在100毫秒以内。
4.6 AI Ready 数据库平台
KES V9正在构建全流程机器学习平台,使数据库成为AI应用的控制中心。内嵌本地模型可以直接在数据库进程中运行和推理开源模型,内置模型训练推理能力,支持广泛的NLP能力,本地向量生成直接调用本地模型生成Embedding。AI应用编排工具支持通过函数调用云服务商的模型,自动化RAG流程,Text-to-SQL将自然语言转为SQL,调用外部LLM进行文本补全、分类、总结。
AI交互式运维方面,通过自然语言交互给AI下达运维任务,数据库自动巡检、自治优化。问题分析准确度超过98%,详细证据链展示避免幻觉,精准根因分析。传统运维模式下耗时4到5个小时的问题排查,AI交互运维模式下仅需10分钟,运维效率提升80%。
4.7 工业协议生态与数据接入
金仓时序数据库支持丰富的工业级数据传输协议。采集代理支持Telegraf,通过Go驱动连接KES。设备协议支持OPC-UA、Modbus、MQTT。应用协议支持SQL、HTTP、WebSocket、RESTful等。数据采集路径为:终端设备/芯片/日志/程序/网络,通过Telegraf采集代理,进入KES时序数据库,再到监控分析平台。
4.8 安全与合规
金仓时序数据库支持SM2/SM3/SM4国密算法,满足等保2.0/3.0三级要求。还支持行列级权限控制,可对敏感时序数据实施细粒度访问控制。
05. 金仓在电力行业标杆项目
金仓自2009年参与华北电网信息化建设以来,已覆盖国家电网、南方电网、国家能源集团、国家电投、中国华能、中国大唐、中国华电、中国三峡、中广核等12家能源龙头企业,覆盖调度自动化、配电自动化、电厂集控、电力交易、营销管理五大类关键业务,部署于多个省级电网单位、200余个地市调度中心,数据库实例规模超1,000套,核心调度系统连续稳定运行超过15年。
5.1 国家电网D5000调度系统
原Open3000系统长期采用Oracle数据库,2008年国家电网启动调度系统国产化升级专项。2009年华北电网率先引入金仓并行验证,2010年正式承担主调任务。
系统覆盖26省84地市,管理超1,000个数据库节点,日均处理数据量达PB级别。华北电网典型节点峰值达每分钟30万条人工库数据入库。平均事务响应时间从86毫秒降至23毫秒,峰值从1,200毫秒降至210毫秒。RTO达到秒级,RPO趋近于0,故障平均恢复时间从18分钟降至2.3秒。用户代码修改率低于0.3%,Oracle常用功能兼容性表现良好。通过了国家信息安全等级保护四级测评、国密SM4加密认证、GB/T 36572-2018全项检测。连续17年7×24小时无故障运行,年可用性达99.999%。
5.2 某大型省级电网电力现货交易辅助决策系统
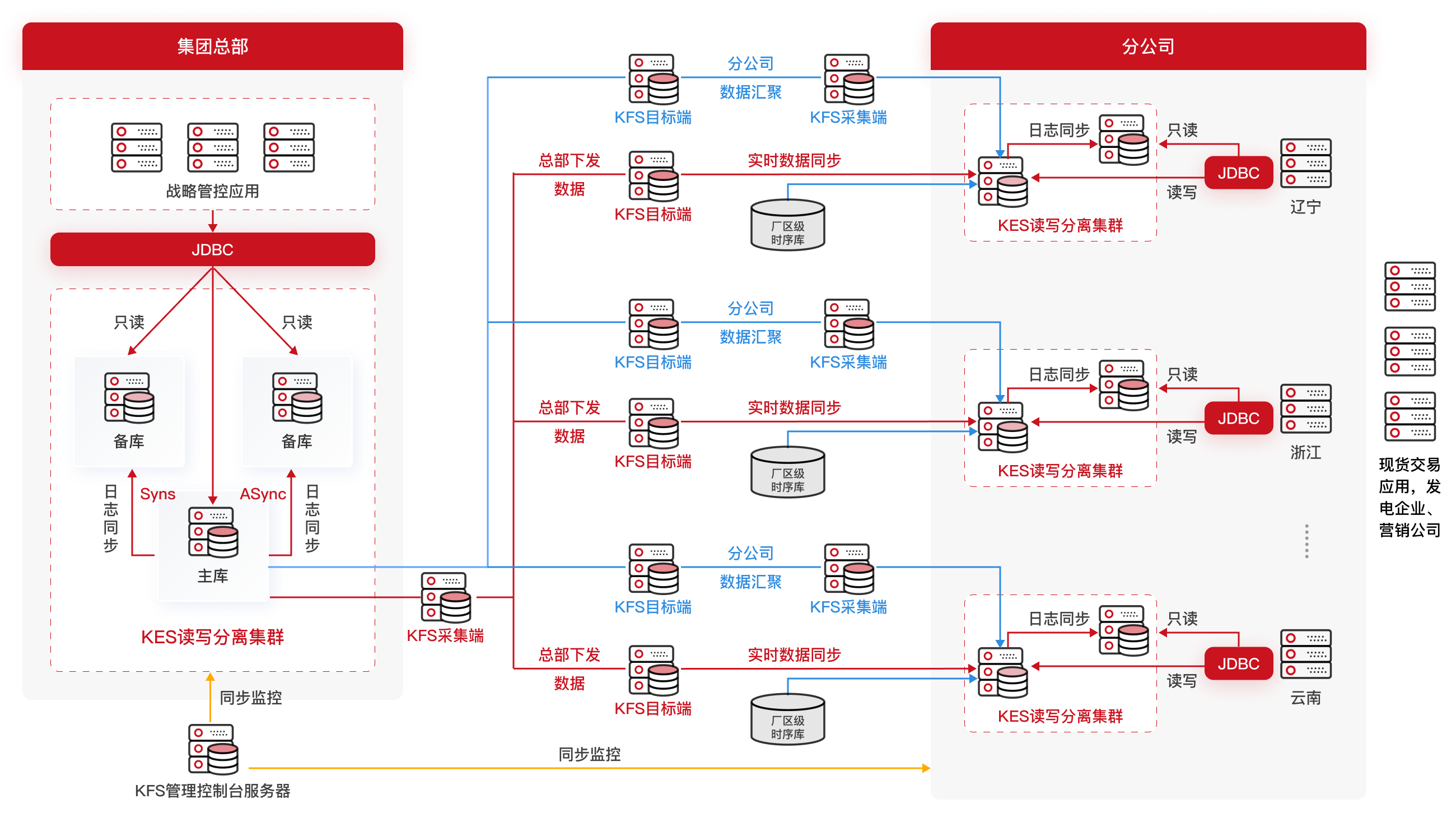
电力现货市场进入常态化运行阶段,交易精度从"小时级"向"15分钟级"持续细化。某省级电网公司原系统采用InfluxDB + Kafka + Grafana技术栈,面临集群扩容困难、数据一致性保障不足、缺乏统一权限管理与审计机制等问题,且不符合等级保护三级要求。2024年,该电网公司启动"去O+去外"行动,选定金仓数据库替代InfluxDB,构建电力现货交易辅助决策系统。新系统采用"KES读写分离集群 + KFS时序同步引擎"混合架构,KES承担主业务逻辑与复杂查询,KFS负责从各厂站边缘侧采集原始时序数据。
迁移过程采用四步法:评估适配(97%以上查询可通过语法转换直接运行)、数据迁移(总数据量8TB,持续72小时,全程无业务中断)、功能验证与压测(并发用户500+,峰值TPS突破12,000)、灰度上线与监控(在河南、江西等试点省份先行部署)。
系统上线后,数据查询效率提升85%以上,平均响应时间从3.2秒降至0.5秒;总体拥有成本TOC下降40%,取消商业TSDB授权采购,节省年均软件支出近百万元;开发迭代周期缩短60%,基于统一SQL接口,新业务模块原型验证最快可在两天内完成;系统可靠性增强,RTO<30秒,RPO≈0,达到金融级容灾标准。日前出清模拟耗时从42分钟缩短至6.5分钟,支持每日3轮动态申报;实时风险预警响应从"分钟级"进入"秒级";结算复盘报告生成时效由T+2日提前至T+0日18:00前自动推送。
5.3 某大型核电集团集控平台升级
原有Oracle集群面临版本老旧、补丁支持终止、维保成本上升等问题。基于金仓兼容语法解析与迁移评估工具,完成存量PL/SQL脚本自动转换与性能调优。系统资源占用率下降约15%,备份窗口缩短近40%,日常巡检自动化覆盖率提升至98%以上。
06. 总结
6.1 金仓时序数据库的独特价值
金仓时序数据库在国产时序数据库赛道中占据独特的生态位,其核心价值主张可以概括为"三个一"。
"一套数据库"解决所有问题。企业无需为时序数据单独部署和维护一套专用数据库,在同一KingbaseES实例中即可同时处理时序数据、关系数据、GIS数据、文档数据和向量数据。这种"一库多模"架构从根本上消除了数据孤岛,简化了系统架构,TCO可降低35%到50%。
"一次迁移"平滑过渡。金仓的多语法兼容层使得98%以上的数据库对象可以直接运行,配合KDTS加KFS工具链实现从评估到切换的全流程自动化。
"一个团队"统一运维。由于时序能力是KingbaseES的内置特性,企业无需组建专门的时序数据库运维团队,现有DBA可以直接利用已掌握的KingbaseES运维技能管理时序数据。
6.2 未来展望
金仓时序数据库正沿着三个方向持续演进:AI融合,内置时序异常检测、趋势预测、根因分析;云原生与Serverless,托管型数据库服务弹性伸缩按需付费;自治运维,AI驱动自动巡检、自治优化,目标实现"自治、自愈、自优"。
累计100万套装机部署、60余个行业覆盖、大量标杆案例、连续5年关键应用领域销售套数第一,并同时蝉联中国医疗与交通行业数据库国产厂商销量双料冠军,这些数字背后是金仓数据库始终如一的技术深耕和对"数据库国家队"使命的坚守。在信创产业全面推进和数字化转型深化的双重机遇下,金仓时序数据库正从"国产替代"走向"价值创造",为中国企业构建安全、高效、智能的时序数据底座。
Have a nice day ~ ☕
🌻 推荐阅读 ▼
👉 这里有得聊
如果你对国产基础软件(操作系统、数据库、中间件)、AI Agent、Vibe Coding、OpenClaw 、Hermes Agent 等感兴趣,欢迎关注微信公众号:「少安事务所」。如果这篇文章为你带来了灵感或启发,请帮忙『点赞、转发、推荐』,感谢!ღ( ´・ᴗ・` )~
