




为了解决大规模数据集合和多种数据种类带来的挑战,NoSQL数据库就应运而生。NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。NoSQL最常见的解释是“非关系型”(“Non-Relational”),但是“不仅仅是SQL语言”(“Not Only SQL”)的解释也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的四个特性:原子性、一致性、隔离性、持久性(ACID,Atomicity、Consistency、Isolation、Durability)。
NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系数据库运用,这一概念无疑是一种全新的思维注入。因为NoSQL数据库去掉了关系数据模型的特性,因此数据之间没有关系,容易进行扩展。例如,脸书或者推特每天都为他们的用户收集万亿比特的数据,这些数据的存取不需要固定的模式,使用NoSQL无需多余的操作就能实现横向扩展,无形之间也在架构的层面上带来了可扩展的能力。此外,得益于NoSQL数据库数据模型的无关系性,数据库的结构变得比较简单,因此容易支持海量数据的存储和高并发读写,性能比较优秀。
Johan Oskarsson在2009年发起了一场关于分布式开源数据库的讨论,Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。2009年在亚特兰大举行的“no:sql(east)”讨论会是一个里程碑,其口号是“select fun, profit from real_world where relational=false;”。因此,对NoSQL最普遍的解释是“非关系型的”,强调键值存储和文档数据库的优点,而不是单纯的反对关系数据库。
虽然NoSQL数据库具有灵活的数据模型、高扩展性和高可用性等特点,但是,NoSQL不支持SQL查询,不支持强一致事务处理(如附录表B-3所示),只能保证数据的弱一致性。NoSQL数据库主要包括4种类型:文档数据库(Document-Oriented Database)、列簇式数据库(Column-family Database)、键值数据库(Key-Value Database)和图数据库(Graph Database)。接下来,本文分别介绍这四类数据库。
- 文档数据库(Document-Oriented Database)
从1989年起,美国Lotus公司(已被IBM兼并)通过其群组工作软件产品Notes提出了数据库技术的全新概念——文档数据库(Document-Oriented Database),与传统数据库相比,文档数据库是用来管理文档的。在传统数据库中,信息被分割成离散的数据段,而在文档数据库中,文档是处理信息的基本单位。通俗地说,文档数据库假设存储的数据均按某种标准或编码来封装数据,这些封装好的数据可以是XML、YAML、JSON或者BSON等,也可以是诸如PDF和微软Office文档等二进制文档格式。例如,XML数据库是针对XML文档做了优化的面向文档的数据库的子类。一些搜索引擎(也称为信息检索)系统如Elasticsearch提供了足够的对文档的核心操作,从而满足面向文档数据库的定义。
常见的文档数据库有MongoDB、Apache CouchDB、亚马逊AWS的Document DB等。以MongoDB数据库为例,它是一个由C++语言编写的基于分布式文件存储的文档数据库。MongoDB的每个数据库(Database)下包含多个集合(Collection),每个集合下又可以有多个文档(Document),每个文档中的每条记录(Record)就是一条数据。这与关系数据库的记录(Record)和数据表(Table)的概念相似,但是同一个集合下的文档可以存储格式不同的数据,存储操作更加灵活。其它的文档数据库产品与之类似,在此不一一赘述。 - 列簇式数据库(Column-Family Database)
传统数据库有列数的限制,而宽表(BigTable、HBase)通过列簇的概念来降低这一限制。但是宽表带来了存储的开销,而列簇数据库通过融合行健值和列来形成统一关键字,并且可以把值分成多个列簇,让每个列簇代表一张数据映射表。典型的列簇式数据库包括Hbase、BigTable、Cloudera和Cassandra等。以Hbase为例,它是一个开源的非关系型分布式数据库(NoSQL),参考了谷歌的BigTable建模,实现的编程语言为Java。Hbase是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为Hadoop提供类似于BigTable规模的服务。
但列簇数据库不同于列数据库。数据库存储方式分为两种:行存和列存。行存即按照行进行组织存储,适合于交易型业务,例如整行数据的增加和删除;而列存是按照列进行存储,适合于分析型业务,例如单列数据的聚集分析。图1-5是两种存储方法的图形化对比。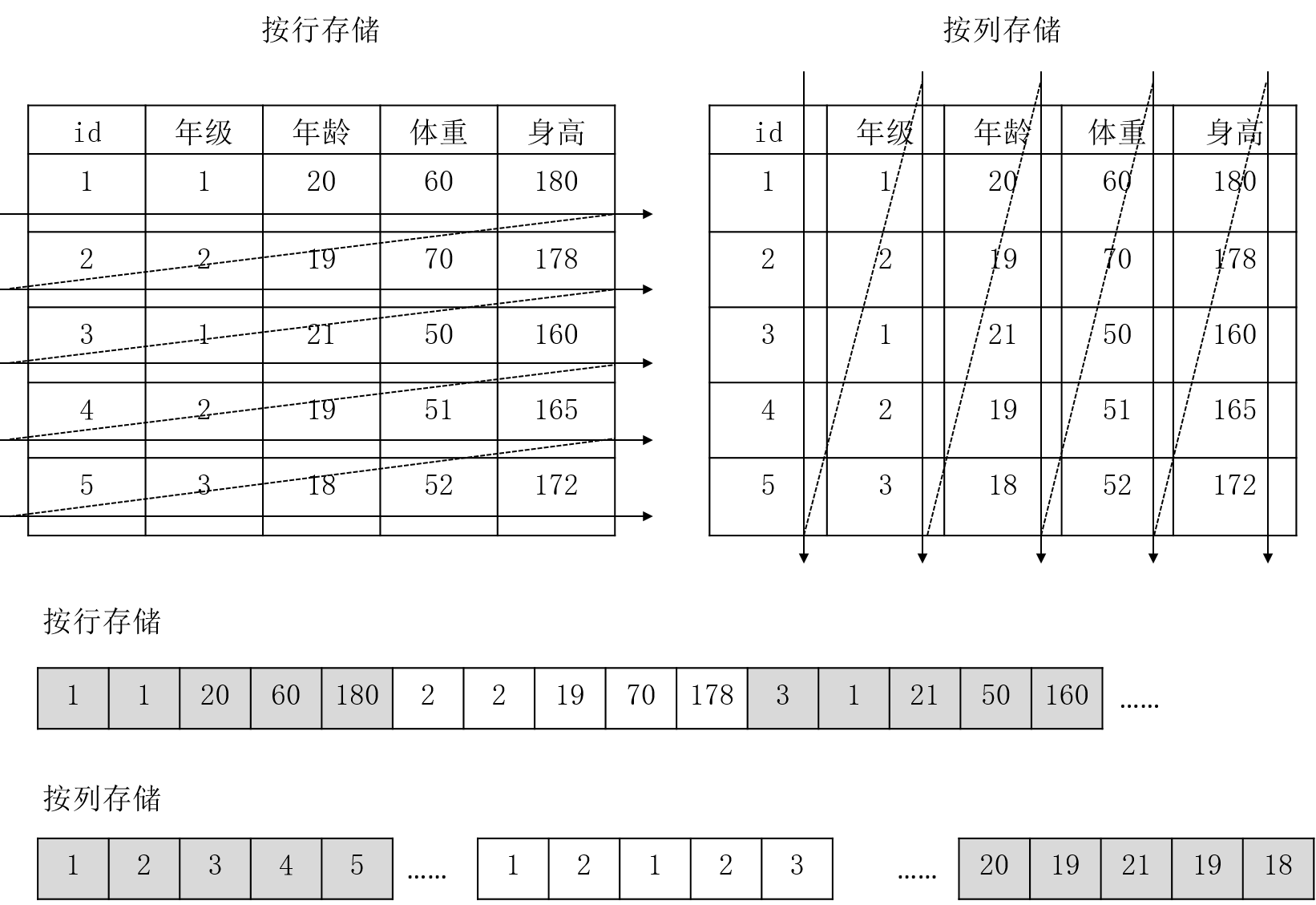
图1-5 列式存储和行式存储对比(图源自互联网) - 键值数据库(Key-Value Database)
键值数据库使用简单的键值方法来存储数据,是一种最简单的NoSQL数据库,具有较高的容错性和可扩展性。该类数据库将数据存储为键值对集合,其中键作为唯一标识符,键和值都可以是从简单对象到复杂对象的任何内容。在不涉及过多数据关系业务的需求中,使用键值存储可以非常有效地减少读写磁盘的次数,比关系型存储拥有更好的读写性能,能够解决关系数据库无法存储的数据结构问题。但是该类数据库的事务不能完全地支持ACID特性(如附录表B-3所示)。
常见的键值数据库包括面向内存的键值数据库Redis和Memcached,面向磁盘的键值数据库RocksDB和LevelDB等。
Redis是一个使用ANSI C语言编写的开源、基于内存、支持网络、可选持久性的键值对存储数据库。Redis是目前最流行的键值对存储数据库之一,经常被用于存取缓存数据。
Memcached是一个开放源代码、高性能、分布式的内存对象缓存系统。用于加速动态Web应用程序,减轻关系数据库的负载。它可以应对任意多个连接,使用非阻塞的网络IO。由于它的工作机制是在内存中开辟一块空间,然后建立一个Hash表,Memcached自管理这些Hash表。Memcached简单而强大,简单的设计促进迅速部署,易于发现所面临的问题,解决了很多大型数据缓存的问题。
LevelDB是一个由谷歌研发的键值对嵌入式数据库管理系统编程库,以开源的BSD许可证发布。 - 图数据库(Graph Database)
图数据库的历史可以追溯到上世纪60年代的Navigational Databases,这时IBM也开发了类似树形结构的数据存储模型。经过30多年的漫长发展,期间出现过可标记的图形数据库Logic Data Model。直至本世纪初,具有ACID特性的里程碑式图数据库产品,如Neo4j、Oracle Spatial and Graph,才被开发出来并进行商业化。到2010年后,可支持水平扩展的分布式图数据库开始兴起,例如OrientDB、ArangoDB、MarkLogic。至今,各式各样的图数据库越来越受到重视,在谷歌、领英、脸书等一些大公司中,已经有了广泛应用。图数据库的成功可以归结为很多因素,但归根结底是因为它们可以将大量复杂的信息,支撑各类新型应用,例如知识图谱、社交网络分析。
