




为了能够适应各类中大型企业对云数据库系统的需求,GaussDB云数据库系统提供了更强的存储资源、计算资源之间的组合能力。其主要目的是实现存储资源的独立扩容和缩容能力、计算资源的独立扩容和缩容能力、以及存储资源与计算资源在弹性扩缩容环境下的自由组合能力。从本质而言,GaussdB云数据库系统提供多租户(Multi-tenant)和扩缩容(Elasticity)的组合能力。
1. 多租户存储计算共享架构
单个应用服务独立部署转向共享服务,对企业内部数据库系统的运维产生较大的变革,并有效降低其运维成本。
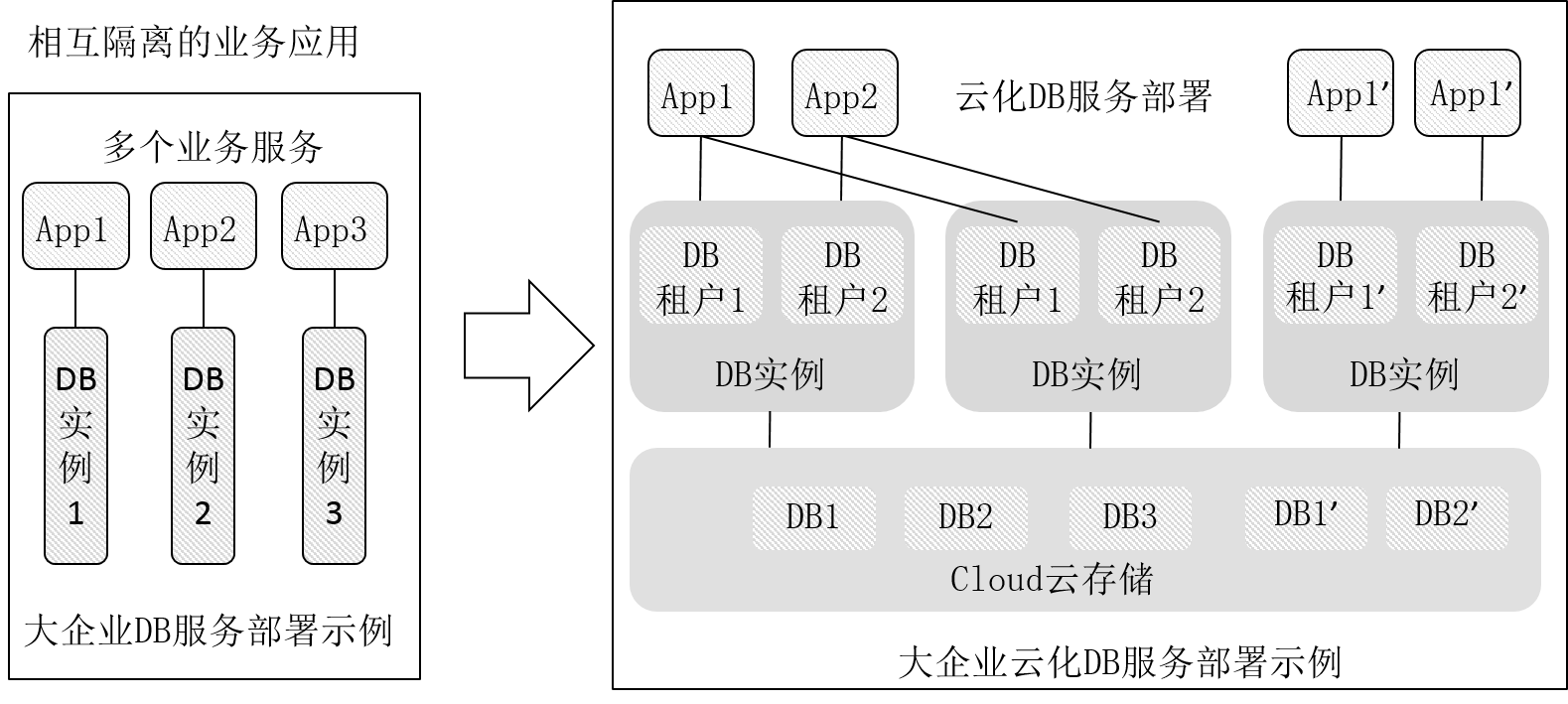
图5-15 多租户数据库系统部署形态
如图5-15所示,数据库系统从孤立的独立部署转向计算与存储共享的部署形态,在实现计算与存储共享的同时实现存储资源的独立扩缩容,以及计算资源独立的扩缩容。当云部署的数据库系统能够提供独立的存储、计算扩缩容能力后,数据系统需要被迁移的概率将被大幅度降低,由此可以提升数据库系统的业务连续性(Business Continuity),系统比较容易实现在运行过程中存储资源的扩缩容,以及计算资源的扩缩容。
2. 三层逻辑架构实现存储、计算独立扩缩容
为了有效实现云数据库系统在存储资源、计算资源的独立扩缩容,需要实现计算与存储的解耦,以及各自的扩缩容能力。
如图5-16所示,为了实现GaussDB云数据库系统在存储和计算方面的弹性,我们将整个数据库系统分解为3个层次,分别是弹性的存储层、弹性的事务处理层、以及无状态的SQL执行层。和当前比较流行的云数据系统Aurora、PolarDB相比,所不同的是,GaussDB云数据可以在事务处理层实现横向扩展,以保证满足中大型企业对数据库系统的不同需求(SLA)。无状态的SQL处理层,可以实现对不同客户端连接请求数进行扩展的能力。
GaussDB虽然实现了在数据库系统3个层次上的不同可扩展能力,但是并不要以为这些组件是部署在不同的物理机器上。相反的,为了更好的提供性能,这3个层次的组件通常在部署的时候,具有很强的相关性,需要尽可能的联合部署(尽量部署在一台物理机上,或一个交换机内),以降低网络时延带来的开销。

图5-16 GaussDB云数据库系统的分层架构
3. 云数据数据库的克隆复制支持
将企业的数据库系统搬到云系统之上,可以提供更加便利的数据库系统管理功能,以满足企业对业务的测试、新业务的构建等不同需求,加速业务上线的速度。
由于云数据库系统实现多个数据库系统之间数据的共享(即在一个存储池中,存储大量的数据库)。因此,可以实现对这些数据库高效的复制、克隆、回合等功能。比如,某公司可能需要基于现有数据库系统的当前数据,开发一个新的应用。传统的做法是,为了测试应开发的应用不影响到现有的线上应用,公司通常会构建一个新的数据库系统,并从当前线上系统导出一份最新的数据,并将这份新的数据导入到另外一个数据库系统中(比如刚创建的数据库系统实例),并在该数据库系统开发、测试新的应用。
当这些数据库系统共同部署在云数据库系统中时,可以实现数据库系统的克隆(包括数据与系统)和复制(仅数据),比如使用COW机制(对于持久化存储的Copy-on-Write机制)可以实现对于数据库数据的快速克隆(仅克隆了元数据,数据库数据并未拷贝)。通过COW机制,构建在克隆数据库上的业务可以直接修改克隆的数据库系统中的数据。
如图5-17所示,云数据库系统可以对生产数据库系统进行克隆、复制等操作,对于克隆、复制出来的数据库系统可以用于非生产系统,并用于开发、测试流程或是参与到基准测试中。需要说明的是,用户非生产系统的数据库系统保持了和生产系统当前一致的数据,同时生产系统中更新的一部分数据也可以实时同步到非生产数据库系统中,进而保持这两部分数据之间的一致性。
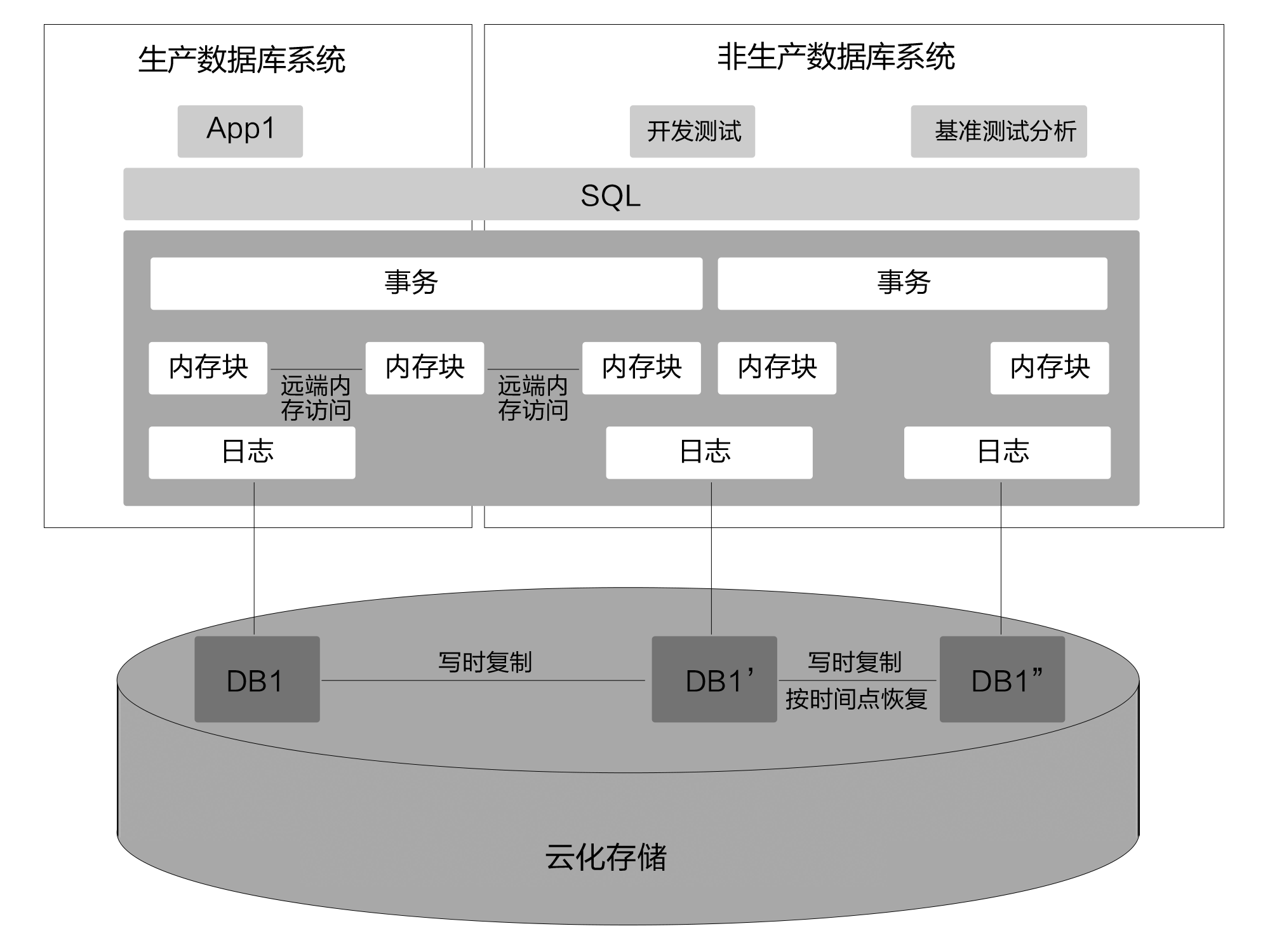
图5-17 GaussDB云数据库系统的数据库克隆与复制
注:PITR pint-in-time-recovery
通过上述分析,GaussDB云数据库系统通过分层,实现了在存储层的弹性、在计算层的弹性、这两者的任意组合,能够较好的适应中大型企业对云数据库系统的需求。另外,GaussDB云数据库系统在此基础上又进一步实现了对现有数据库系统的高效克隆、复制,以满足中大型企业提升业务演进的速度和节奏。
