




openGauss行存储的多版本机制与业界比较常见的关系型数据库有较大的不同,核心区别为行存储的多版本在更新的时候并不是就地更新,而是在原有页面中保留上一个版本,转而在这个页面(如果空间不够会在新页面中)创建一个新的版本,来进行历史版本的累积更新。
相应的页面中会同时存有不同版本的同一行数据,拿到不同快照的事务,在读写这些不同版本时互不冲突,有着很好的并发性能。对历史版本的检索可以在页面本身或邻近页面进行,也不需要额外的CPU开销以及IO开销,有着非常高的效率。同时,事务管理以及持久化角度也变得非常的清晰简洁,省去了类似于就地更新所需要记录、执行以及持久化的Undo等相关操作。
以下就以一个DML的例子简单展开行存储结构以及MVCC的实现:
假设我们在一个Xid为10的事务中,在一个只有一列varchar(变长字符串(类型))数据的表中插入一条数据’A’,该行数据落入编号为0的数据页面上,则该行结构如图9-5所示。

9-5 行存储结构示意图1
可以看到xmax为0,此时此记录为有效记录。
假设我们在此基础上在事务xid=20做了delete此行的操作,则此记录变为如图9-6所示。
9-6 行存储结构示意图2
此时xmax被标记为20,如果此事务提交,那么此行最终会被回收。
如果我们在之前insert的基础上,在事务xid=30中连续对该行做两次更新,则改行记录则会如下所示:
第一次更新如图9-7所示。

9-7 行存储结构示意图3
原有行失效,通过ctid记录新版本的ctid,进而指向下一行
第二次更新如图9-8所示。

9-8 行存储结构示意图4
第二个版本也变为历史版本,通过ctid指向最新版本,不过值得注意的是,第二个版本的xmin、xmax都为30,即此版本在同一事务中被删除,而最新版本xmin也仍为30,只是cid从0增加为1(假设此事务连续执行了这两次Update操作)。
更新后的页面如图9-9所示。

9-9 行存储结构示意图5
以上几个简单的例子比较直白的展示了行存储的基本存储结构、行存储的DML以及行存储的MVCC是如何结合在一起共同作用的。
存储引擎内部,索引也是重要的组成部分,索引本身指向存储的是key到ctid的映射。上面我们也提到过了,ctid实际上指向的是line_pointer的检索信息,因此索引的页面上存储的信息以及其与数据页面的关系如图9-10所示。

9-10 索引的页面上存储的信息以及其与数据页面的关系
当然,可能会出现更新操作的新版本无法放入旧版本所在页面的情况,这种情况下页面和索引情况的对比如图9-11所示。
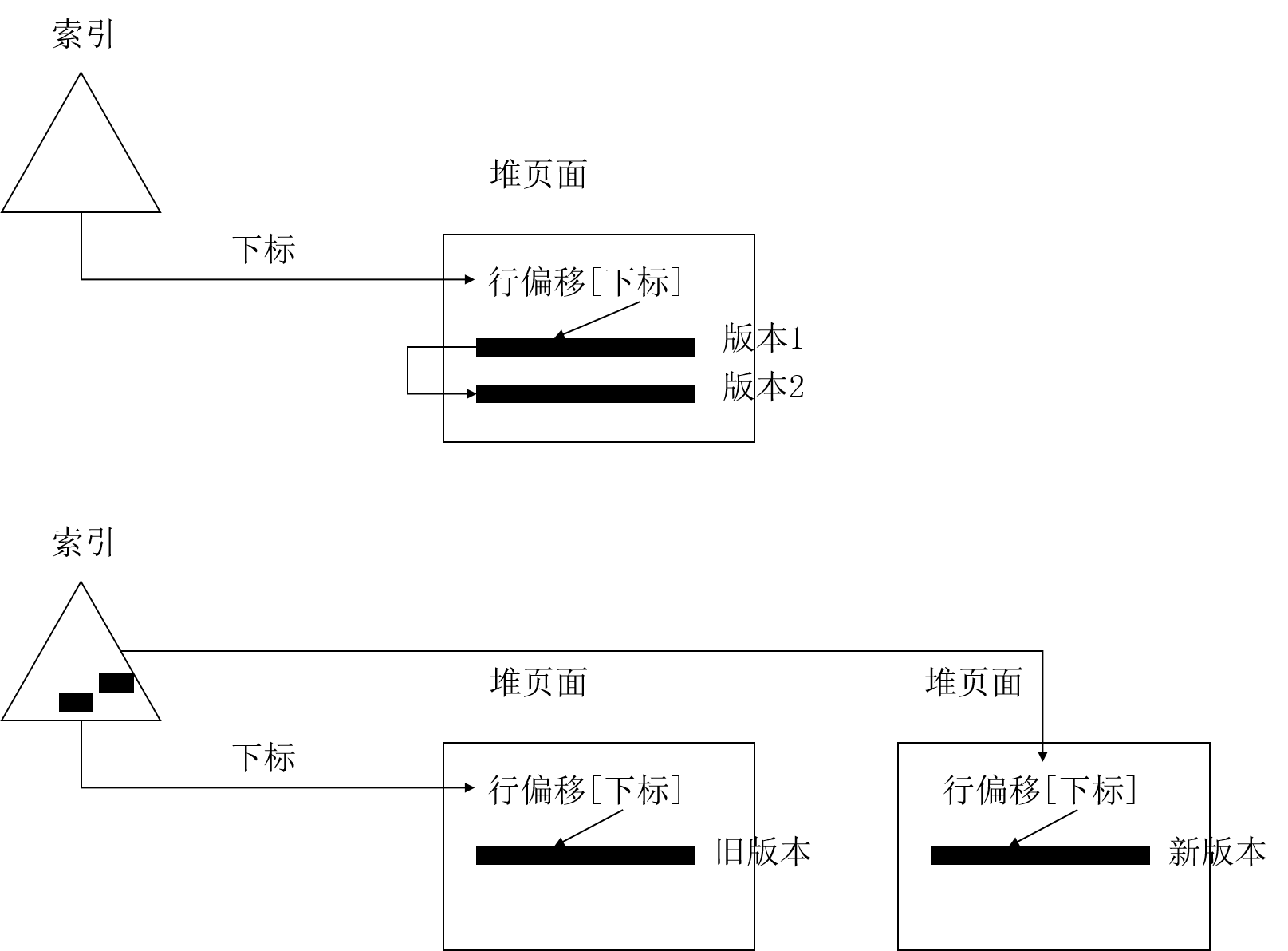
图9-11 新版本无法放入旧版本所在页面时的页面和索引情况
此种情况下,Index会有两条entry(记录),两条entry(记录)代表了key(键)对应新旧版本的ctid,这样方便从索引直接跨页面进行搜索。
