




数据库的日志系统非常关键,它是数据持久化的关键保证。以其基于事务ID的多版本管理以及历史版本的累积及清理方式为基础,行存储引擎主要以Redo日志(也就是上文提到的XLOG)作为主要的持久化手段,配以增量的检查点(Checkpoint)以及日志的并行回放,支持数据库实例的快速故障恢复。
1. 事务的Redo日志机制
Redo日志在事务对数据进行修改时产生,用来记录事务修改后的数据、或是事务对数据做的具体操作。比如,简单的INSERT/UPDATE/DELETE操作会产生如图9-21所示的Redo日志。

图9-21 Redo日志
一些非事务直接修改的关键操作也会记录到Redo日志,比如申请新的页面、显式的事务提交、检查点(Checkpoint)等。记录Redo日志的原则,就是在数据库发生故障后,可以从最后一个检查点开始,通过Redo日志的回放,恢复到与数据库实例故障前的一致状态。
Redo日志除了应用于数据恢复,数据的备份、还原以及数据库主备实例之间的主备同步、不同数据库实例/集群间的同步都需要依赖Redo日志的机制。为了保障数据的一致性,在事务修改的相关页面刷盘之前,需要先把对应的Redo日志刷盘,也就是WAL(Write Ahead Log)的原则。
因为事务的提交以及操作之间的顺序对于数据一致性是至关重要的,因此Redo日志也必须将此顺序记录下来。每条Redo日志都配有一个日志编号,即Log Sequence Number (LSN)。在行存储的系统中,LSN为一个递增的64位无符号整数。系统中各类机制,如后面要说到的检查点,以及主备实例之间的同步机制、仲裁机制,都需要依靠系统中推进的LSN或是恢复出来的LSN作为重要的标记或判断依据。
2. 全量与增量检查点
在上述对事务日志以及共享缓冲区的描述中,有一个关键的信息,那就是事务日志的持久化与事务提交是同步的,但事务内对页面相关修改的持久化与事务提交不是同步的;也就是说,事务提交需要这个事物相关的Redo日志被强制刷盘,但是并不强制要求相关的页面也被强制刷盘。当一个数据库实例故障重启后,实例在启动过程中,之前没有能够及时刷盘的改动需要使用事务日志进行恢复。但是日志回放的代价是很高的,性能也相对比较慢。为了避免每次数据库都需要从头恢复事务日志,数据库自身会定期创建检查点,用户也可以通过命令手动创建检查点。
创建检查点的过程中,存储引擎会将数据缓冲区中脏页写到磁盘中,并记录日志文件和控制文件。记录信息中rec LSN代表着此次检查点中,在此LSN之前的日志对应的所有改动均已被持久化,下次的数据恢复可以直接从此LSN开始;同时在此LSN之前的事务日志,在其他用途(主备实例同步、数据备份等)时,也可以被回收重新使用。
由于检查点本身需要将缓冲区内所有的脏页面刷盘(全量检查点),因此每次检查点从性能角度会对数据库实例所在物理环境引入大量的IO,磁盘的峰值往往意味着性能的波动。同时因为存在大量的IO开销,因此检查点的打点不能过于频繁,rec LSN推进较慢,那么重启数据库时也就会存在较多的Redo日志需要回放,存在重启恢复时间过长的问题。为了解决这一问题,行存储引擎引入了增量检查点的概念。
增量检查点机制下,会维护一个脏页面队列(dirty page queue)。脏页是按照LSN递增的顺序放到队列中的,定期由一个专门刷脏页面的后台线程pagewriter(页面刷盘线程)进行定期定量的刷脏页下盘操作。如图9-22所示。

图9-22 脏页面队列
队列中维护一个rec LSN,记录目前已经被刷盘的脏页对应的LSN大小,即在队列中脏页对应的事务提交、其相对的事务日志下盘后,此rec LSN标记会被更新。在触发增量检查点时,并不需要等待脏页刷盘,而是可以使用当前脏页队列的rec LSN作为检查点的rec LSN记录。增量Checkpoint的存在使得整个系统中的IO更加平滑,并且系统的故障恢复时间更短,可用性更高。
3. 并行回放
Redo日志的回放指的是将Redo日志中记录的改动重新应用到系统/页面中的过程,这个过程通常发生在实例故障恢复亦或是主备实例之间的数据同步过程中的备机实例上(即主实例的改动,备机实例也需要回放完成,以达到与主实例状态一致的效果)。当前数据库所在物理实例往往有较多的CPU核,而日志回放却往往还是单线程进行运作,在日志回放的过程中数据库实例无法充分利用物理环境资源。
为了能够充分利用CPU多核的特点,显著加快数据库异常后恢复及备机实例日志回放的速度,行存储引擎采用了多线程并行方式回放日志,如图9-23如示。
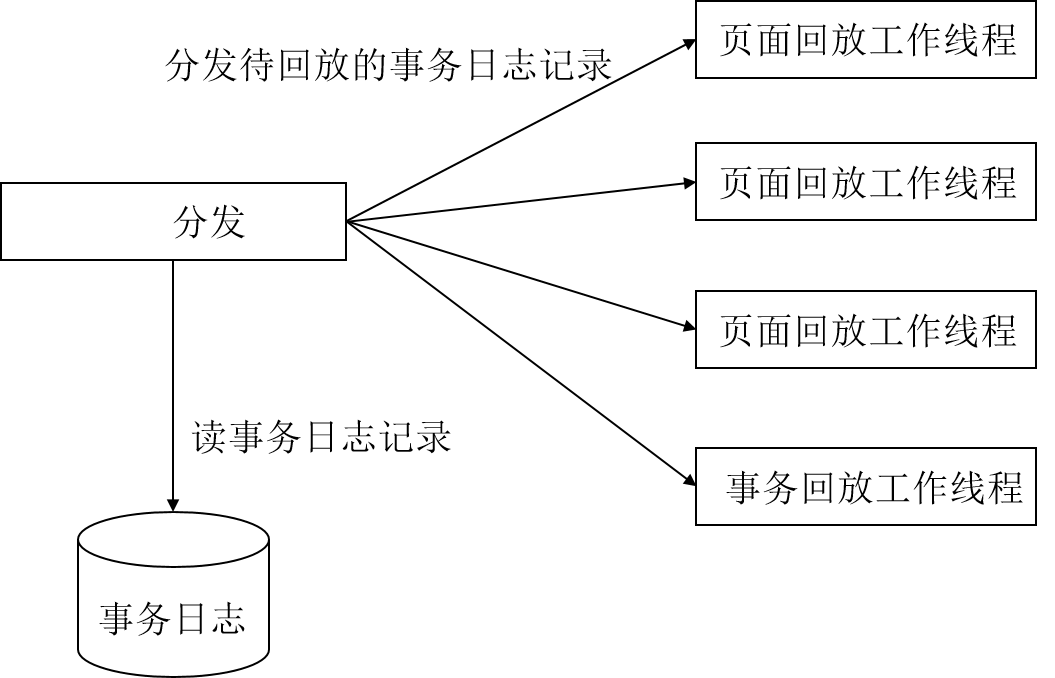
图9-23 多线程并行方式回放日志
整个并行回放系统的设计采用生产者-消费者模型,分配模块负责解析、分配日志到回放模块,回放模块负责消费、回放日志。
为了达成这一设计,实现中采用了带阻塞功能的无锁SPSC(Single Producer Single Consumer)队列。分配线程作为生产者将解析后的日志放入回放线程的列队中,回放线程从队列中消费日志进行回放。如图9-24所示.

图9-24 无锁SPSC队列
为了提升整体并行回放机制的可靠性,会在对一个页面的回放动作中,对事务日志中的LSN和页面结构中的last_LSN(详见前面章节中描述的HeapPageHeader(堆页面头)结构体)进行校验,以保证回放过程中数据库系统的一致性。
