




每个列自适应选择压缩,支持delta value encoding(差分编码)、Run length encoding(游程编码)、dictionary encoding(字典编码)、LZ4、zlib等混合压缩。根据数据特性的不同,压缩比一般可以有3X~20X。
列存储引擎支持低、中、高三种压缩级别,用户在创建表的时候可以指定压缩级别。
导入1TB原始数据量,分别测试低、中、高三种压缩级别,入库后数据大小分别是100GB、73GB、61GB。如图9-35所示。

图9-35 压缩比示意图
每次数据导入,首先对每个列数据按照向量组装,对前几批数据做采样压缩,根据数值类型和字符串类型,会选择尝试不同的压缩算法。一旦采样压缩完成后,接下来的数据就选择优选的压缩算法了。如图9-36所示,主要分数值压缩和字符压缩。其中对Numeric小数类型,会转换为整数后,再按照数值压缩。对数值型字符串,也会尝试转换为整数再按照数值压缩。
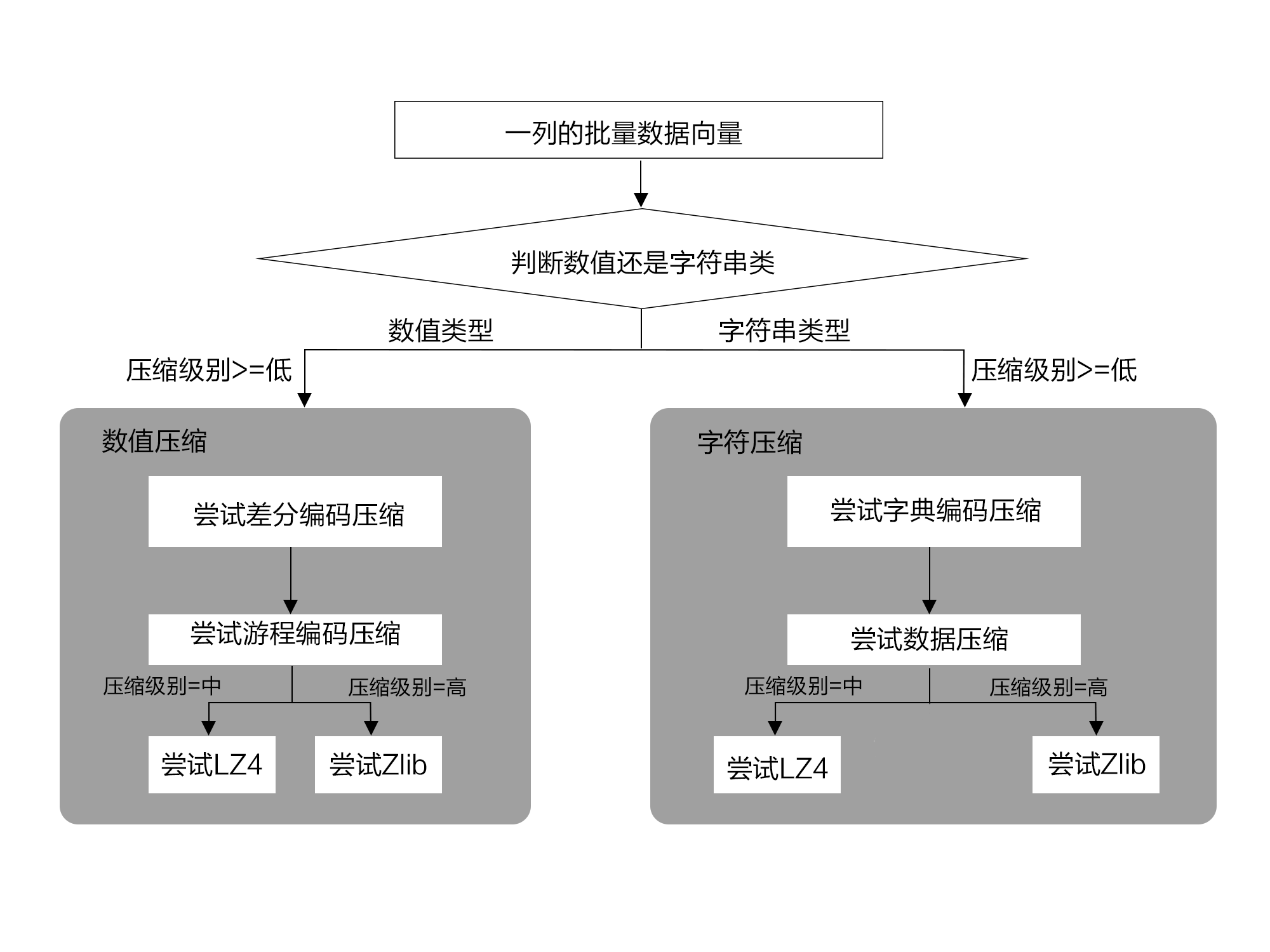
图9-36 面向列的自适应压缩
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
