




一、StreamSets架构及抽象
(1)pipeline:
StreamSets能成为功能强大的大数据集成平台,离不开其简洁优雅的架构及插件式设计。架构层面,StreamSets将每个数据集成任务抽象成pipeline,数据记录在pipeline中以batch-record的形式流动,而pipeline则由代表数据来源的Origin,代表接收端的Destination,以及包含具体数据转换/映射/过滤等业务逻辑的Processor共同组合实现,具体如下图:
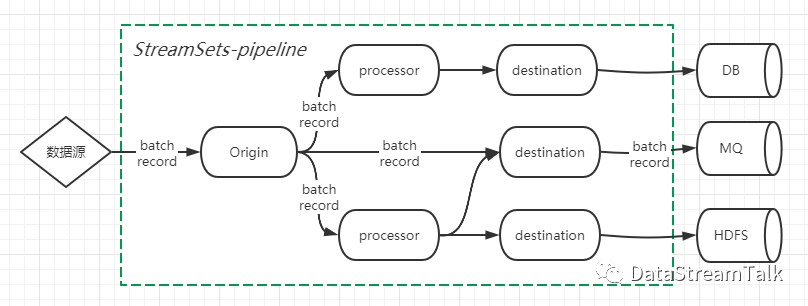
(2)record:
pipeline中的数据是以record形式在上下游之间流动。record可以简单看做是一条条记录,每个record都有自己的schema。record在StreamSets中以Map<String,Object>形式存在,其中key为字段名(field-name),value为字段实际值;record除了包含业务数据外,还自带header属性,保存元数据信息。

二、Origin插件
Origin对接pipeline的数据来源,从各种类型的数据源中摄取数据(绝大多数是以batch方式获取),并流转到下一pipeline节点进行后续处理。每个pipeline只能有一个Origin节点,代表该pipeline的源端。常用的Origin简介如下:
(1) 基于文件系统:
Directory:从指定本地目录获取数据
File Tail:通过tail方式从指定目录按行获取文件内容
Hadoop FS Standalone:从HDFS文件系统获取数据,可以使用多个线程并行处理
(2) 基于应用层网络协议:
HTTP Client:通过HTTP协议从指定URL获取流数据
HTTP Server:监听指定HTTP端口,并处理认证的POST/PUT请求内容,可以使用多个线程并行处理
SFTP/FTP/FTPS Client:从SFTP/FTP/FTPS服务器获取文件内容
REST Service:监听指定HTTP端口,并解析所有认证的请求参数,将响应体发送给REST-API调用端,可以使用多个线程并行处理
WebSocket Client:监听指定WebSocket服务端口,将响应体发送给原始系统
WebSocket Server:监听指定WebSocket端口,并解析客户端所有认证的请求参数,将响应体发送给原始客户端,可以使用多个线程并行处理
(3) 基于TCP/UDP协议:
TCP Server:监听指定端口,处理流经TCP/IP连接的数据,可以使用多个线程并行处理
UDP Multithreaded Source:从一个或多个UDP端口获取消息,可以使用多个线程并行处理
UDP Source:从一个或多个UDP端口获取数据
(4) 基于消息队列:
JMS Consumer:从JMS消费消息
Kafka Consumer:从单个Kafka-Topic消费消息
Kafka Multitopic Consumer:从多个Kafka-Topic消费消息,可以使用多个线程并行处理
MQTT Subscriber:监听MQTT代理的指定topic,并消费消息
Pulsar Consumer:从Aache Pulsar的topic消费消息
RabbitMQ Consumer:从RabbitMQ消费消息
(5) 基于JDBC数据源:
JDBC Multitable Consumer:通过JDBC连接从多个表中查询数据,可以使用多个线程并行处理
JDBC Query Consumer:通过JDBC连接及用户自定义SQL查询数据
MongoDB:从MongoDB或Microsoft Azure Cosmos DB查询文档数据
(6) 基于RDBMS-CDC(change data capture)技术:
MySQL Binary Log:读取MySQL-binlog生成CDC记录
MongoDB Oplog:从MongoDB的Oplog读取entry
Oracle CDC Client:从LogMiner-redo-log生成CDC记录
PostgreSQL CDC Client:从PostgreSQL的WAL-log生成CDC记录
(7) 基于NoSQL数据源:
Elasticsearch:从ElasticSearch集群查询数据,可以使用多个线程并行处理
Redis Consumer:从Redis中查询数据
(8) 其它
SDC RPC:从SDC的RPC-pipeline的destination端读取数据
JavaScript Scripting:运行JavaScript脚本生成SDC-record,可以使用多个线程并行处理
三、Destination插件
Destination对接pipeline的数据sink端。经过Origin和多个Processor等上游节点处理后,batch-record会通过Destination插件最终保存到指定位置。每个pipeline可以有多个Destination节点。常用的Destination和Origin基本类似,其简介如下:
(1) 基于文件系统:
Local FS:将数据保存到本地文件系统
Hadoop FS:数据保存到HDFS
(2) 基于应用层网络协议:
HTTP Client:保存数据到HTTP-endpoint
WebSocket Client:将数据保存到WebSocket-endpoint
SFTP/FTP/FTPS Client:通过SFTP/FTP/FTPS将数据发送到指定URL
(3) 基于消息队列:
JMS Producer:将数据保存到JMS
Kafka Producer:将数据保存到Kafka集群
MQTT Publisher:将消息数据推送到MQTT代理的topic
(4) 基于数据库:
JDBC Producer:通过JDBC连接保存数据到数据库
MongoDB:将数据保存到MongoDB
HBase:将数据保存到HBase库
Hive Metastore:当需要时会创建/更新Hive表元数据
Hive Streaming:数据保存到Hive表
(5) 基于NoSQL数据源:
Elasticsearch:数据保存到ElasticSearch
Redis:保存数据到Redis
(6) 其它
SDC RPC:将RPC-pipeline的数据传递给RPC-origin
Syslog:将数据发送到Syslog服务器
To Error:将数据发送到pipeline的error处理流
Trash:将数据从pipeline中删除(类似/dev/null)
四、Processor插件
StreamSets提供了类型多样,功能丰富的processor插件,方便用户应对各种场景下的数据处理需求。
(1) 字段转换
Field Flattener:嵌套数据拉平(变成普通k-v结构)
Field Hasher:敏感数据编码
Field Mapper:根据指定表达式变更字段path,名称或字段值
Field Masker:对敏感字符串进行伪装
Field Merger:将多个字段合并到一个字段中
Field Order:将map/map-list类型数据进行排序并输出
Field Pivoter:将list/map/list-map集合的数据进行逐个投影输出,为集合的每个元素创建一条新记录
Field Remover:字段移除
Field Renamer:字段改名
Field Replacer:字段值替换
Field Splitter:将字符串类型的字段切分为多个字段
Field Type Converter:字段类型转换
Field Zip:将2个集合型字段合并为单个集合
Base64 Field Decoder:将Base64编码的字段解码成二进制数据
Base64 Field Encoder:使用Base64对二进制数据进行编码
Encrypt and Decrypt Fields:字段加密/解密
XML Flattener:将string类型的XML数据进行拉平(取消嵌套)
(2) 字段格式解析
Data Parser:解析字段内的NetFlow/syslog数据
JSON Parser:解析string字段的JSON对象
Log Parser:根据指定日志格式解析字段中的日志数据
XML Parser:解析string字段中的xml
SQL Parser:解析string字段中的SQL查询语句
(3) 通过解释器处理数据
Expression Evaluator:根据指定表达式对数据进行计算,也能增加/修改record的header属性
JavaScript Evaluator:根据指定JavaScript脚本对数据进行处理
Jython Evaluator:根据指定Jython脚本对数据进行处理
Spark Evaluator:根据指定Spark程序对数据进行处理
(4) 数据补充
HBase Lookup:在HBase中进行k-v查询,并将结果补充到数据记录中
JDBC Lookup:通过JDBC连接进行数据库查询,并将结果补充到数据记录中
MongoDB Lookup:查询MongoDB数据库,并将结果补充到数据记录中
Redis Lookup:在Redis中进行k-v查询,并将结果补充到数据记录中
Static Lookup:在内存中进行k-v查询,并将结果补充到数据记录中
JDBC Tee:通过JDBC连接先将数据写入到数据库,然后获取数据库自生成的列数据(如自增主键)并补充到数据记录中
HTTP Client:通过HTTP向指定URL发送请求,并将响应结果补充到指定字段中
(5) 数据格式转换
Data Generator:使用指定数据格式将record序列化到单个字段
JSON Generator:将指定字段的数据序列化成JSON格式字符串
Schema Generator:为每个record中生成schema,并将scheme数据保存到record的header属性
(6) 数据流分组
Stream Selector:根据指定条件将数据发送到不同的下游stream中
HTTP Router:根据record的header属性中HTTP请求方法及URL,将数据发送到不同的下游stream中
五、参考资料
(1)Origin插件:
https://streamsets.com/documentation/datacollector/latest/help/datacollector/UserGuide/Origins/Origins_overview.html#concept_hpr_twm_jq
(2)Destination插件:
https://streamsets.com/documentation/datacollector/latest/help/datacollector/UserGuide/Destinations/Destinations_overview.html#concept_hpr_twm_jq
(1)Processor插件:
https://streamsets.com/documentation/datacollector/latest/help/datacollector/UserGuide/Processors/Processors_overview.html#concept_hpr_twm_jq
