




【问】:Spark的工作流程?
【答】: Spark运行的基本流程如下图所示:
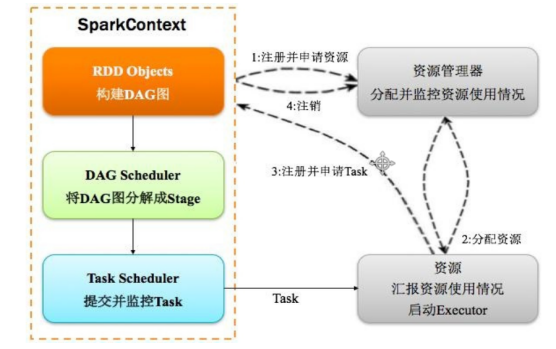
Step 1 注册并申请资源。当一个Spark应用被提交时,首先要为这个应用构建起基本的应用环境,即由任务控制节点(Driver)创建一个SparkContext(即Spark类),然后由SparkContext负责和管理资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控;
Step 2 分配资源。资源管理器为Executor分配资源,并启动Executor进程,而Executor的运行情况会随着“心跳”(即任务运行实时记录)发送到资源管理器上进行实时监控;
Step 3 注册并申请Task。SparkContext将根据RDD的依赖关系构建DAG图,然后DAG图提交给DAG调度器进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器进行处理。这一步的整体的运行逻辑是“Executor向SparkContext申请任务 → 任务调度器将任务分发给Executor → 与此同时SparkContext将应用程序代码发给Executor”;
Step 4 完成任务并注销。任务在Executor上运行,然后把执行的结果先反馈给任务调度器,再反馈给DAG调度器,在运行完毕后写入数据并释放资源。

文章转载自稀饭居然不在家,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
