




本文主讲kafka在发送数据时会经历哪些,以及他是如何保证分区有序,以及失败后处理等。
开篇流程图
大家都知道kafka发送是异步的,所以他有两个阶段——一个是预备发送阶段,一个是发送阶段。
下面看图速览,下面看完代码可以回过头来在看下图,加深印象。
预备流程图
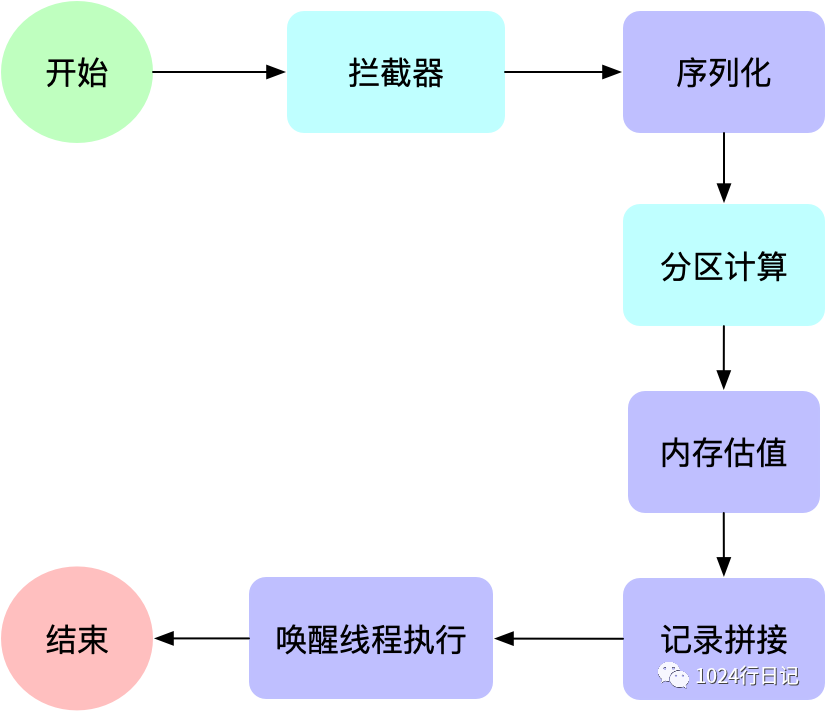
预备流程图
其中,蓝色部分表示可以定制的部分。
发送流程图
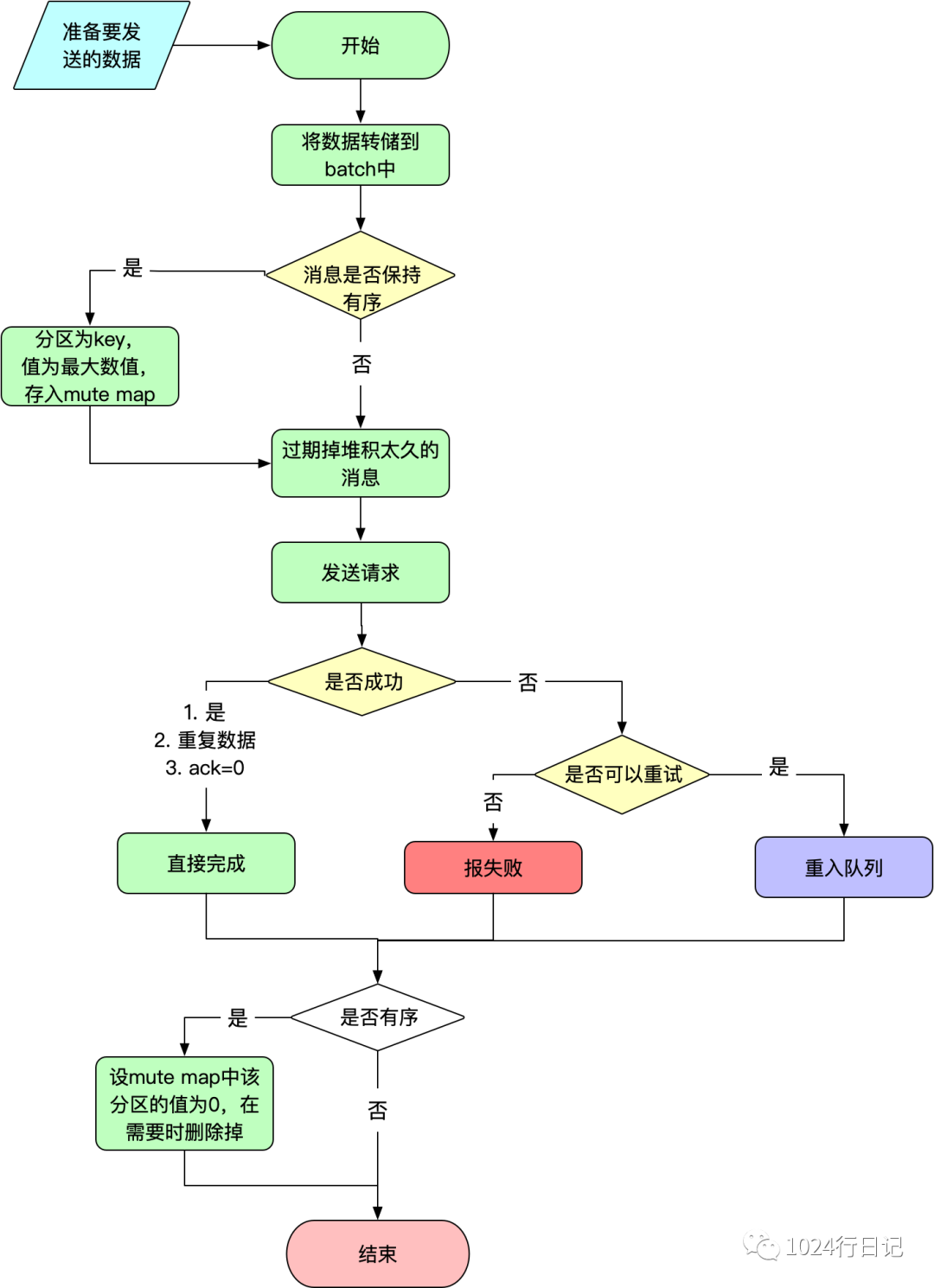
发送流程图
代码分析
开始发送
kafka的发送方法org.apache.kafka.clients.producer.KafkaProducer#send(org.apache.kafka.clients.producer.ProducerRecord<K,V>, org.apache.kafka.clients.producer.Callback)
中:
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// kafka拦截器,可以对全局所有消息进行处理。这个方法不会抛出异常
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
关于拦截器,另有一文叙议。
从上面进入到关注的重点——发送方法org.apache.kafka.clients.producer.KafkaProducer#doSend
:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// 首先检测元数据可用
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
// 剩余等待时间 = 总阻塞时间 - 在等待集群元数据上花费的时间
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
// key的序列化
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
// value的序列化
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 计算分区(如果指定,则直接用,否则走分区器)
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
// 估算数据最大可用多少大小
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//校验大小(默认范围:小于1M,)
ensureValidRecordSize(serializedSize);
//记录的时间设置
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// 生产者回调:将确保调用你提供的callback和interceptor的callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
// 记录的拼接
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
// 如果满了(队列长度大于1 或者 已写字节>=写入上限(batch.size))或者是新批次,就唤醒线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
// 此时将sender从selector()方法中唤醒,要传输数据了。
this.sender.wakeup();
}
return result.future;
} catch (...) {
//...省略异常
}
}
记录拼接
下面重点看一下记录的拼接这一部分,将数据拼接到双向队列deque中。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// 跟踪追加线程的数量,以确保我们不会丢批次
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 检查是否有在处理中的批次(因为一个分区只有一个deque)
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
// 锁住deque,添加数据
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
//分配大小,默认为batch.size大小。16384,即16K
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
// 如果是第一次,直接看这里。上面的都添加不成功。
// 添加到batch
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
// 将batch添加到deque中
dq.addLast(batch);
incomplete.add(batch);
buffer = null;
// 返回结果。此处可以看到队列长度大于1或者队列已满就认为队列已满
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
下面来看下上面的tryAppend方法org.apache.kafka.clients.producer.internals.RecordAccumulator#tryAppend
。这个方法是在deque中已经有数据的时候会执行到这里的。取出最后一个,然后append上去。
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque<ProducerBatch> deque) {
ProducerBatch last = deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, time.milliseconds());
if (future == null)
last.closeForRecordAppends();
else
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false);
}
return null;
}
开始准备发送数据org.apache.kafka.clients.producer.internals.Sender#sendProducerData
。
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// 获取要发送数据的分区清单
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果leader不知道有任何分区,强制更新元数据信息
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}", result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// 移除不需要发送的节点
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
// 创建生产请求
// 将指定节点的数据转储到batch中
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
// 消息是否保持有序,guaranteeMessageOrder默认为false。
// MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION设置为1时,该order为true。
if (guaranteeMessageOrder) {
// 将要发送消息的分区放入mute map中,value为long类型最大值
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
// 防止批次在累加器accumulator中呆太久,即消息堆积,过期掉他们
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(this.requestTimeoutMs, now);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
// 失败批次的处理,同时返回超时异常
failBatch(expiredBatch, -1, NO_TIMESTAMP, expiredBatch.timeoutException(), false);
if (transactionManager != null && expiredBatch.inRetry()) {
transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);
}
}
// 更新生产者统计数据,每一个topic发送的大小、数量、压缩速率等
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
// 发送请求
sendProduceRequests(batches, now);
return pollTimeout;
}
开始发送生产者请求org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest
。
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
// 头部魔数处理,用于校对请求协议版本等信息,忽略掉
byte minUsedMagic = apiVersions.maxUsableProduceMagic();
for (ProducerBatch batch : batches) {
if (batch.magic() < minUsedMagic)
minUsedMagic = batch.magic();
}
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
produceRecordsByPartition.put(tp, records);
recordsByPartition.put(tp, batch);
}
String transactionalId = null;
if (transactionManager != null && transactionManager.isTransactional()) {
transactionalId = transactionManager.transactionalId();
}
// 构建请求
ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,
produceRecordsByPartition, transactionalId);
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
// 处理生产者响应体
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
String nodeId = Integer.toString(destination);
// 这个callback就是上面注册的 处理响应体的 方法
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
// 发送请求
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
处理响应
下面看处理响应体方法org.apache.kafka.clients.producer.internals.Sender#handleProduceResponse
:
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, ProducerBatch> batches, long now) {
RequestHeader requestHeader = response.requestHeader();
long receivedTimeMs = response.receivedTimeMs();
int correlationId = requestHeader.correlationId();
// 连接断开处理
if (response.wasDisconnected()) {
log.trace("Cancelled request with header {} due to node {} being disconnected",
requestHeader, response.destination());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now, 0L);
// 版本不匹配处理
} else if (response.versionMismatch() != null) {
log.warn("Cancelled request {} due to a version mismatch with node {}",
response, response.destination(), response.versionMismatch());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now, 0L);
} else {
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// 如果响应还有响应体的处理
// 发送成功会进入到这里
if (response.hasResponse()) {
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
ProducerBatch batch = batches.get(tp);
completeBatch(batch, partResp, correlationId, now, receivedTimeMs + produceResponse.throttleTimeMs());
}
this.sensors.recordLatency(response.destination(), response.requestLatencyMs());
} else {
// 剩下的都是ack=0的,全部完成就完了
for (ProducerBatch batch : batches.values()) {
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now, 0L);
}
}
}
}
可以看到上面的每一个分支都会走到completeBatch方法,这个方法负责完成或者重试给定的batch。那么我们来看下这个方法org.apache.kafka.clients.producer.internals.Sender#completeBatch(org.apache.kafka.clients.producer.internals.ProducerBatch, org.apache.kafka.common.requests.ProduceResponse.PartitionResponse, long, long, long)
:
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId,
long now, long throttleUntilTimeMs) {
Errors error = response.error;
// 如果错误是消息太大,且记录数>1且(魔数不对 或 是压缩批次)
if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 &&
(batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {
// 如果消息体太大,分割消息成小批次,并将消息小批发送过去
log.warn("Got error produce response in correlation id {} on topic-partition {}, splitting and retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts(),
error);
// 事务,忽略掉
if (transactionManager != null)
transactionManager.removeInFlightBatch(batch);
// 分割然后重入队列(这个时候是从头部直接插入的)
this.accumulator.splitAndReenqueue(batch);
this.accumulator.deallocate(batch);
this.sensors.recordBatchSplit();
} else if (error != Errors.NONE) {
// 重试条件:1)次数小于最大次数,2)属于重试错误或事务管理器允许重试
// 一般是没有事务管理器的,需要ack=all
if (canRetry(batch, response)) {
log.warn("Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts() - 1,
error);
if (transactionManager == null) {
// 重入队列
reenqueueBatch(batch, now);
} else if (transactionManager.hasProducerIdAndEpoch(batch.producerId(), batch.producerEpoch())) {
log.debug("Retrying batch to topic-partition {}. ProducerId: {}; Sequence number : {}",
batch.topicPartition, batch.producerId(), batch.baseSequence());
reenqueueBatch(batch, now);
} else {
failBatch(batch, response, new OutOfOrderSequenceException("Attempted to retry sending a " +
"batch but the producer id changed from " + batch.producerId() + " to " +
transactionManager.producerIdAndEpoch().producerId + " in the mean time. This batch will be dropped."), false);
}
} else if (error == Errors.DUPLICATE_SEQUENCE_NUMBER) {
// 事务部分
completeBatch(batch, response);
} else {
final RuntimeException exception;
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
exception = new TopicAuthorizationException(batch.topicPartition.topic());
else if (error == Errors.CLUSTER_AUTHORIZATION_FAILED)
exception = new ClusterAuthorizationException("The producer is not authorized to do idempotent sends");
else
exception = error.exception();
// 重试耗尽
failBatch(batch, response, exception, batch.attempts() < this.retries);
}
// 元数据信息错误,强制更新元数据
if (error.exception() instanceof InvalidMetadataException) {
if (error.exception() instanceof UnknownTopicOrPartitionException) {
log.warn("Received unknown topic or partition error in produce request on partition {}. The " +
"topic/partition may not exist or the user may not have Describe access to it", batch.topicPartition);
} else {
log.warn("Received invalid metadata error in produce request on partition {} due to {}. Going " +
"to request metadata update now", batch.topicPartition, error.exception().toString());
}
metadata.requestUpdate();
}
} else {
completeBatch(batch, response);
}
// 消息是否保持有序,guaranteeMessageOrder默认为false。
// MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION设置为1时(但默认为5),该order为true。
if (guaranteeMessageOrder)
// 将已发送完消息的分区放入mute map中,value一般为0
this.accumulator.unmutePartition(batch.topicPartition, throttleUntilTimeMs);
}
失败重入
失败后,重入队列。从头部直接插入。
public void reenqueue(ProducerBatch batch, long now) {
batch.reenqueued(now);
Deque<ProducerBatch> deque = getOrCreateDeque(batch.topicPartition);
synchronized (deque) {
if (transactionManager != null)
insertInSequenceOrder(deque, batch);
else
deque.addFirst(batch);
}
}
分区有序性保证
关于kafka保证分区的有序性,是将当前TopicPartition放入mute的map中,在需要时执行下面的方法进行校验。如果结果为false,即muted的value是<=now的,然后会移除这个tp,那么此时可以发送,否则就不可以发送。
private boolean isMuted(TopicPartition tp, long now) {
boolean result = muted.containsKey(tp) && muted.get(tp) > now;
if (!result)
muted.remove(tp);
return result;
}
附录
重试异常类图
关于重试异常的子类,看下面这个图,全是集群什么异常,所有很少有机会去重试的。
重要的参数
下面的参数都在org.apache.kafka.clients.producer.ProducerConfig
类中:
| - | 参数java常量 | 参数属性 | 参数含义 | 默认值 |
|---|---|---|---|---|
| 1 | MAX_REQUEST_SIZE_CONFIG | max.request.size | 每一个请求的最大字节数 同时也是批处理记录上限值 | 1024*1024(1M) |
| 2 | BUFFER_MEMORY_CONFIG | buffer.memory | 生产者client的最大使用缓存大小 | 32*1024*1024(32M) |
| 3 | MAX_BLOCK_MS_CONFIG | max.block.ms | 一次发送最大阻塞时间 | 60*1000(1min) |
| 4 | BATCH_SIZE_CONFIG | batch.size | 批处理大小 太小会降低吞吐率 太大会造成浪费 | 16384(16K) |
| 5 | LINGER_MS_CONFIG | linger.ms | 本地缓存延迟发送时间 如果分区累计到达BATCH_SIZE_CONFIG大小,则忽略该值,立即发送 | 0(0ms) |
16K在很多软件设计时都使用到了。比如mysql的页,netty最小的page等都是16K。
