




今天浏览新闻时看到华为近期开源了一款名为 openLooKeng 数据虚拟化引擎。正好最近在研究跨源跨域异构数据分析的问题,于是便继续了解了一下。访问其官方网站 感觉页面风格做得还挺简洁清爽。阅读了一些概念和简介,大概七七八八了解了个轮廓。然后顺着首页 quick start 指导,我准备动手实践一下。

根据文档说明,仅仅只要一台 linux 环境,内存大于 4G 即可,于是我就用了我自己的公有云机器:

安装和使用
在 linux 命令行窗口执行:
wget -O - https://download.openlookeng.io/install.sh|bash

过了一会儿,日志显示部署成功了。如下图:

总体感觉安装很顺畅,整个过程我并没有做任何操作。不过也吐槽一下,中间有有一个环节卡了一会儿,我估计是在下载 openLooKeng 的安装,整个过程没有任何信息输出,我还以为部署脚本卡住了。好在过了一分钟后脚本继续往下走了。估计是我网络导致下载缓慢的缘故吧。
安装结束时,脚本提示它已自动将 openLooKeng 的服务运行起来了, 并提示可以运行运行 cli 来连接 openLooKeng。
照着部署结束的提示,运行如下命令:
/opt/openlookeng/bin/openlk-cli
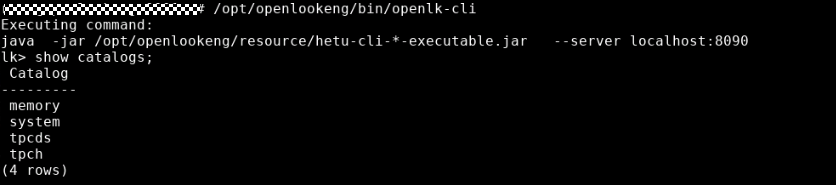
可以看到 openlk-cli 连接到了 localhost 的 8090 端口,通过简单的查询可以看到系统已经内置了几个数据源:system, memory, tpcds, tpch
进一步看 tpdcs 下有哪些数据表:
show tables from tpcds.sf100
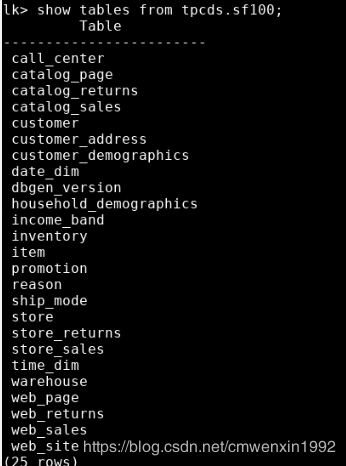
从表名字来看,就是标准的 tpcds benchmark 的测试数据了。不管三七二十一,先看看数据量大小:
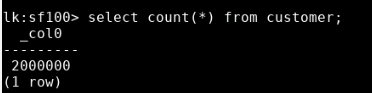
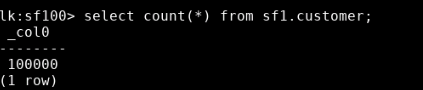
对比结果比较明了,sf 后缀的数值越大,数据量也越大。
顺手我就跑了几个 tpcds 标准的查询。先从数据量小的跑一个吧:
use tpcds.sf1;
select dt.d_year, item.i_brand_id brand_id, item.i_brand brand, sum(ss_ext_sales_price) sum_aggfrom date_dim dt, store_sales, itemwhere dt.d_date_sk = store_sales.ss_sold_date_skand store_sales.ss_item_sk = item.i_item_skand item.i_manufact_id = 436and dt.d_moy=12group by dt.d_year,item.i_brand,item.i_brand_idorder by dt.d_year,sum_agg desc,brand_idlimit 100;
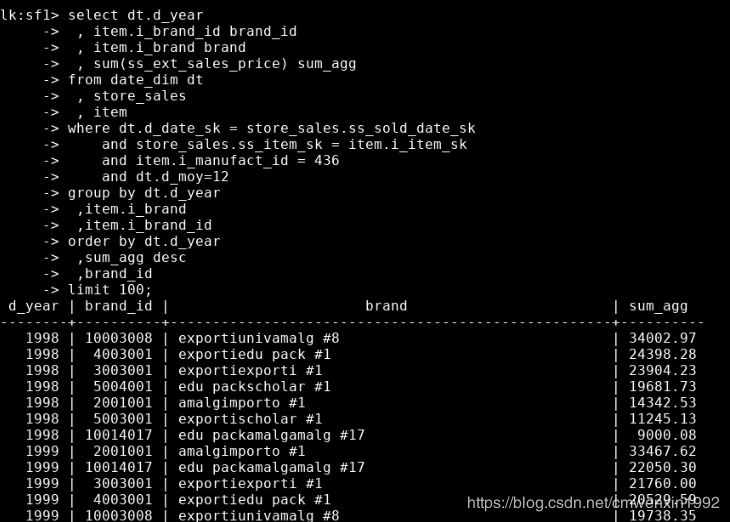

总耗时 46 秒, 处理了 297 万行数据, 印象还不错。
换个数据大的,在换个更复杂的联合查询试了一下:
use tpcds.sf100;
withcustomer_total_returnas(select sr_customer_sk as ctr_customer_sk, sr_store_sk as ctr_store_sk, sum(SR_FEE) as ctr_total_returnfrom store_returns, date_dimwhere sr_returned_date_sk = d_date_sk and d_year =2000group by sr_customer_sk,sr_store_sk)select c_customer_idfrom customer_total_return ctr1, store, customerwhere ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2from customer_total_return ctr2where ctr1.ctr_store_sk = ctr2.ctr_store_sk)and s_store_sk = ctr1.ctr_store_skand s_state = 'NM'and ctr1.ctr_customer_sk = c_customer_skorder by c_customer_idlimit 100;
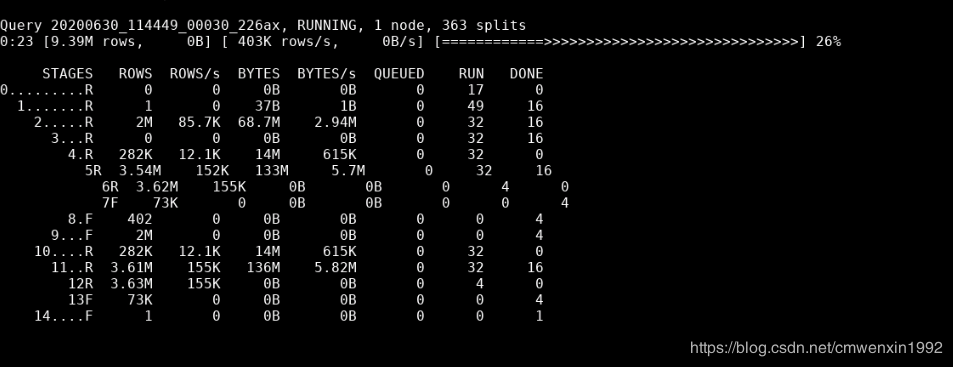
可以看到,总耗时2分46秒处理了近6千多万记录。
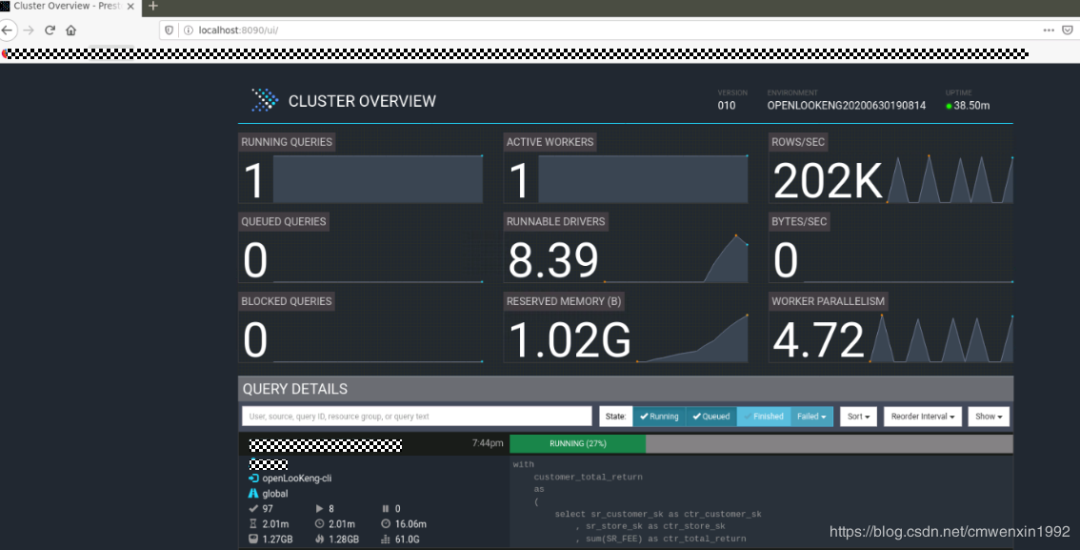
实际上,我们去 WEB UI 界面上去看,浏览器登陆 http://localhost:8090, 可以看到整个执行中间过程,包括内存使用,数据传输率等信息。
初步体验感受
整个安装过程比较简单,一键式无需干预。脚本也完成了创建用户、校验/安装 jdk依赖、配置以及默认数据源的添加等操作,对于我们初尝 openLooKeng 来说非常方便,省去了阅读冗长安装部署的文档。
从使用 openLooKeng 的角度而言,我还需要做更多的探索。目前是单节点运行,且体验了内置数据源。下一步,我先了解下 openLooKeng 的 connector, 然后试着去连接更多的真实数据源。如果能找到更多的机器,我也会试一下多节点安装,以及多节点部署后的 openLooKeng 是否会带来性能的极大提升。
to be continued : )
https://blog.csdn.net/cmwenxin1992/article/details/107094914


