




背景和意义
房多多是国内首家移动互联网房产交易平台。作为迅速崛起的行业新生力量,房多多通过移动互联网工具,为开发商、经纪公司、买房卖房者搭建了一个高效的、可信赖的O2O房产交易平台。
房地产行业的复杂性和业务创新环境注定了房多多的产品特点是不断持续创新和持续高速迭代的,在不断探索业务的可能性的过程中,提高持续快速交付价值的能力和创新能力是必不可少的。
软件行业没有所谓的“银弹”,房多多在业务解耦微服务化以后,服务指数型的增长带来了许多运维方面的困扰。
在我们内部比较突出的矛盾有:
虚拟机的资源依靠维护文档人肉调度,机器调度效率低。
维护测试、预发布、生产等环境的成本高。
某个业务的稳定太依赖某台物理机的稳定性,且难以快速扩容。
业务需求变化快导致雪花服务器增多,难以维护;
CI/CD 脚本复杂,新的需求难以快速交付。
在2018年房多多技术团队开始了服务容器化和容器云的建设,调研后选择了 Swarm 作为了容器集群。
可能很多人看到这儿就会关掉,"都9012年了还有人用 Swarm ?"
虽然在Swarm在和Kubernetes的竞争中已处于下风,但是 Swarm 的灵活性、性能和易用性促进了我们的容器化推进,且在我们落地过程中没有出现过系统级的 bug和线上故障,目前已经在生产环境支撑数百个服务的运行,每日300次左右的变更。
容器和调度编排系统的引入给难以运维的微服务架构带来了质的改变,但是服务容器化和容器云在推进过程中也踩过不少坑和积累了一些经验,希望给大家带来启发。
选型
在容器集群的选择上,Kubernetes事实上已成为容器届编排的标准,但是为什么我们选择了小众的 Docker Swarm呢?
房多多的生产环境硬件基础设施基本都在 IDC 机房,物理机器数量大概有几百台,实际可以供业务迭代用的机器大概在一半左右,且没有很多空闲机器可供使用、新建容器云的机器需要腾挪现有业务。
根据上述的自身的情况,我们做容器平台调研时,主要从以下三点考虑
性能:用户可以在多短的时间内启动并大规模运行容器?系统在大负载情况下响应速度如何?
易用性:起步时的学习曲线是什么?维持运转是否复杂?系统中有多少不定项?
灵活性:是否可以和我当前的环境和工作流相整合?应用从开发到测试再到生产,是否可以无缝衔接?会不会被限制在某个平台上?
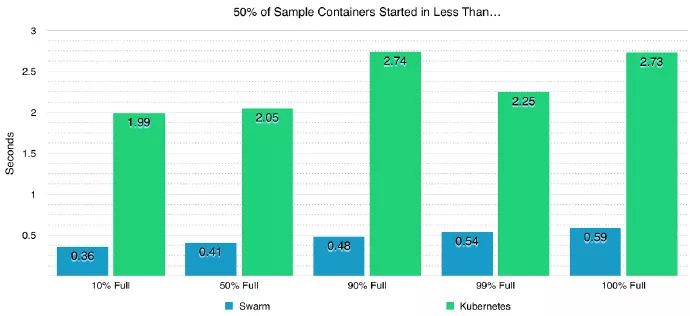
1.从性能看:房多多是自建机房,每一台物理机的利用率是比较高的。在我们测试调研过程中发现,Swarm通常可以在一秒内启动一台容器,调度效率和容器启动速度其实比 Kubernetes快很多。如下图(50%负载下,1000节点 启动每一个容器的平均时间):
2.从灵活性来看:Swarm 的 api 比较简单,可以很快的和现有的 DevOps 流程打通。且因为 Swarm 相当于Kubernetes 的子集,如果后面机器规模继续扩展,业务有大量编排需求,我们可以花不多的时间就可以迁移到Kubernetes上。其实只要我们的服务容器化了,后续更换什么容器集群其实问题都不大。
3.从易用性来看:API使用简单,资源抽象简单,可以快速启动上手。我们使用 Swarm 比较多的功能其实是调度功能,编排功能暂时没有大规模使用。Swarm 的结构比较简单,在最新的版本中内置分布式 k-v 数据库代替了 etcd,内置DNS用来服务发现。在规模中等情况下,几乎没有基础设施运维负担。
容器云架构
Swarm 的实现和Kubernetes相似,最近的版本也在慢慢模仿 Kubernetes 的思想。
想了解如何搭建集群的操作可以查阅 Swarm 官网的文档。
因为 Manager 节点只负责调度集群的 Task ,配置要求不高,所以我们用虚拟化 Xenserver 虚拟了3台低配置机器(在不同的物理机上)作为 Manager 节点,根据 raft 算法,3台可以容许1台机器出问题,5台可以允许2台机器出问题,大家可以按需求部署。Worker 节点的作用是运行业务容器,我们选择了直接用物理机来部署已达到最好的性能和资源利用。同时,在 Manager 和 Worker 节点上,会以容器方式部署机器监控和日志收集,上面还需要运行网络和存储插件。
都加入到集群之后,Swarm 会提供网络管理、负载均衡、基于DNS容器发现、集群状态管理、扩容缩容等功能,我们在 DevOps 流程层面,可以组合成发布、回滚应用、查看服务的状态、日志、终端,更改发布配置(例如环境变量、默认副本数等)等功能。这个层面我们引入了 Portainer 这个开源项目,提供了更好用集群管理的 UI 界面和类似Kubernetes Apiserver 设计的 docker 集群 API 接口服务。
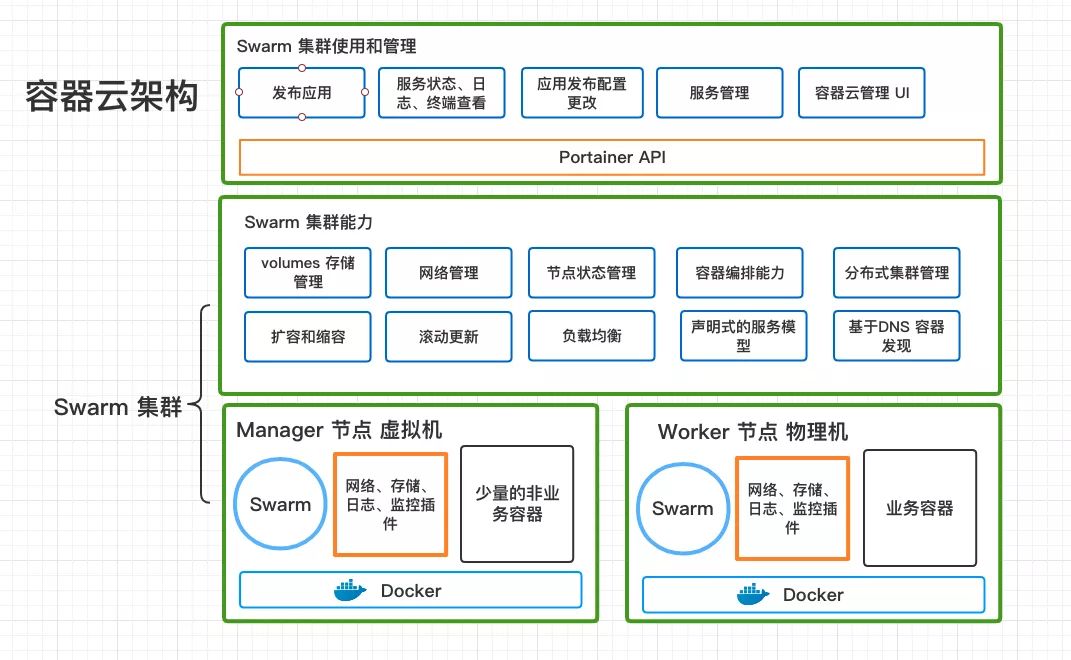
Docker Swarm 的资源抽象比较简单,在没有容器编排的情况下,我们主要使用 Services,这个和Kubernetes上的 Services 有些不一样,可以理解为Services和Deployment 的合体,用来管理和定义 容器的调度和扩容等,也可以直接做端口映射,在容器集群里任意ip 都可以访问。
下图可以比较简单的描述我们是怎么把服务让外部和内部调用的:
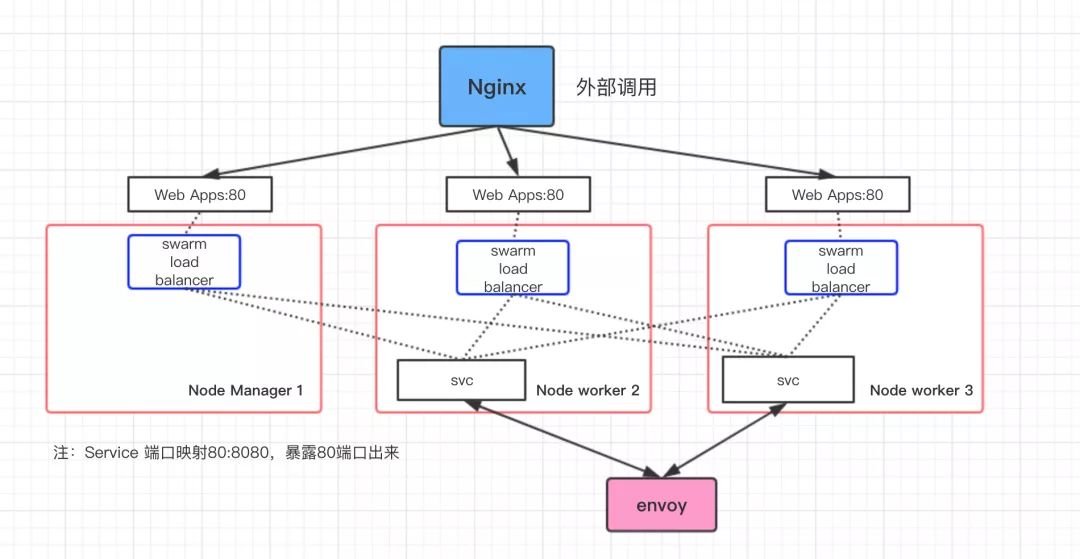
外部调用我们目前是通过 nginx 做反向代理到集群的节点,因为 ingress 的特性我们可以转发到任何一台 worker或者manager 节点上,然后通过内置的 routing mesh 的 load balancer 通过 LVS 转发请求到service 的其中一个副本,一个值得注意的点是,就算这台 node 上没有运行这个 service 的容器load balancer也会找到其他机器上存在的副本,这个主要是通过 内置的 DNS 加 LVS转发实现。
内部调用我们是走我们的 Envoy Mesh 网关,通过自研的 xds-service 来自动发现加路由,本质是走容器之间互通的 overlay 网络 或者Macvlan 网络。
网络
网络我们主要解决两个问题:
容器间互相通信
容器直接互相调用打通,并且可以作为基础的容器网卡,以支持容器集群的 routing mesh功能。
容器和外部网络互相通信
类似使用了dubbo 服务容器化,在虚拟机和容器并存的迁移过程中,必须要让容器和外部网络互通,不然会导致在容器集群外部的虚拟机调用不通容器。虽然也可以通过其他方法实现,但是打通容器和外部网络互相通信是较可行也是稳定的一种方法。
下图是我们主要的容器网络架构
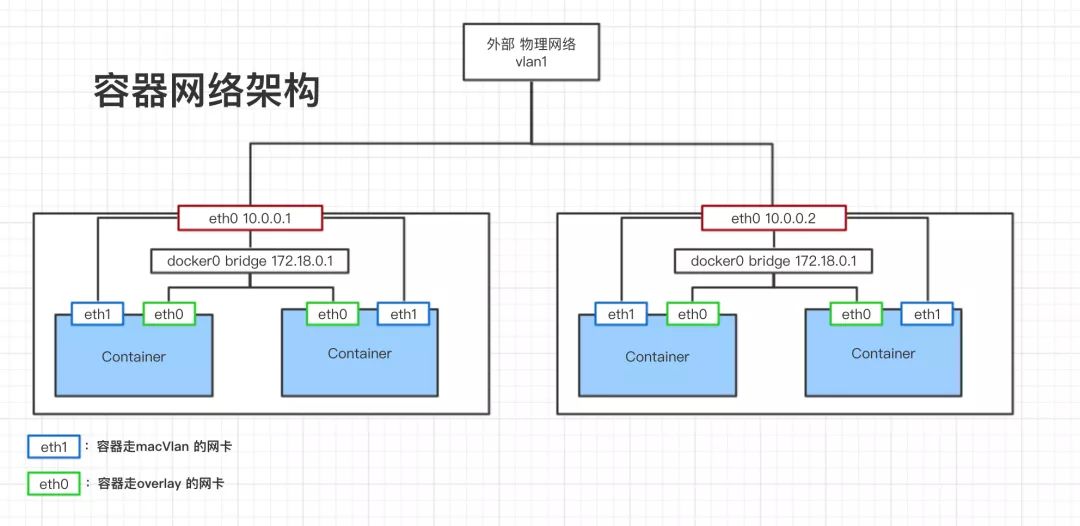
容器间互通的解决方案是我们在容器集群中创建 overlay 网络,并将网络附加到容器容器上,容器中就有了名为 overlay的网卡(图中的 eth0),每个容器的 eth0 都会经过宿主机的 docker0 网卡和 eth0与别的宿主机的网络进行交互。
容器与外部网络互通的解决方案是 Macvlan。其工作原理是通过为物理网卡创建Macvlan子接口,允许一块物理网卡拥有多个独立的MAC地址和IP地址。虚拟出来的子接口将直接暴露在底层物理网络中。从外界看来,就像是把网线分成多股,分别接到了不同的主机上一样,这样也可以拥有近似物理机直连的性能。
公有云一般会限制 Macvlan,不一定可以实施。因为我们是自建机房,所以没有这方面的限制,只要让网络工程师在交换机上配置好网段,我们就可以在此网段下分配容器的 ip 了。
具体使用方法是,在容器worker 节点创建一个 config-only 的 network,写划分的网段和网关,例子:
docker network create --config-only --subnet=10.0.127.0/20 --gateway=10.0.112.1 --ip-range=10.0.112.0/25 -o parent=bond0 pub_net_config# bond0 为指定的依附的物理机网卡
然后在 manager 节点创建 network,例子:
docker network create -d macvlan --scope swarm --config-from pub_net_config pub_net
然后只需要把网络附加到 service 上即可:
docker service update m-web --network-add pub_net
容器化
容器化首先是要把业务代码 build 成镜像,我们内部的技术栈主要以 Node 和 Java为主。
我们容器化迁移是先从 Node 服务开始,因为 Node 服务普遍比较新且项目都按照规范创建,没有很多历史债务且基本都是无状态的,这样我们就可以写出一个比较通用的 Dockerfile 让开发在迭代需求是时候顺便加上,基本只需要改一下暴露的端口号和监控检查 URL 就可以完成容器化。
Java 的构建工具主要以 Maven 和 Gradle 为主,我们使用了 Google 开源的 jib 工具来把构建 docker 镜像并上传的工作集成到 Maven 和 Gradle 中,实际操作只需要改一下 pom文件或者build.gradle,加入 jib plugins就可以了。
实际推广过程中,如果是还在迭代的项目,因为操作简单且容易理解,业务开发还是比较容易推动的。如果是历史项目且还运行在线上,可以让业务运维帮忙逐个操作,然后重新发布,测试,上线。
优化和Tips
镜像大小优化
镜像大小是容器化很重要的一个问题。镜像越小,容器发布和调度就越快,宿主机磁盘用量也不会过大。
除了大家常用的镜像优化手段比如减少层级等,我们优化基础镜像baseimage 使用了alpine3.9版本,并对使用到的基础库做了选择,比如使用最新的musl 1.1.21等,最终基础镜像控制42M,最终降低80%镜像大小到300M 以内。
信号量优化
当容器的启动脚本是一个 shell 脚本时,因为 shell 不响应退出信号的特性,会导致容器无法正常退出,只能等超时后自动杀死进程,这样在我们的实践中会导致物理机上有很多僵尸进程。所以我们的解决方案是消除进程树中的 shell 进程,我们改用了一个 tini 这个来作为主进程,在基础镜像中添加 ENTRYPOINT ["/tini", "—"] 即可,虽然不等子进程返回的方式可能不太优雅,但是可以快速 stop 容器带来的灵活性足以弥补这个缺点,当然特殊应用可以特殊处理。
Java 容器化问题
Java 容器化的坑比较多,JDK 我们使用了 openjdk8(version "1.8.0_191") ,jvm opts我们加上了-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.00,这个版本 java 已经可以正确获取到正确的 cpu 资源和内存资源,默认使用75%的cgroup空间为heap memory,留25%空间给 stack memory。防止因为heap memory加 stack memory 太大导致容器内存使用超出 Cgroup 限制被 Kill掉。
除此之外,我们还优化了随机数生成的原理:
echo "securerandom.source=file:/dev/urandom" >> /usr/lib/jvm/default-jvm/jre/lib/security/java.security
DNS Performance(lookup failed)
两方面原因:
一方面,docker 自身的 dns 允许并发数太低,已经提 issue并修复了:docker Increase max concurrent requests for DNS from 100 to 1024。
另一方面,musl的代码在dns解析的实现上有些问题,如果有ipv6的A记录那么解析性能不会出现问题,如果只有AAAA的ipv4记录,那么解析可能会出现卡死的情况,等待2.5s才返回,所以要添加一个break代码防止出现等待,在最新的 musl 的版本解决了(没有 发布,需要自行编译)
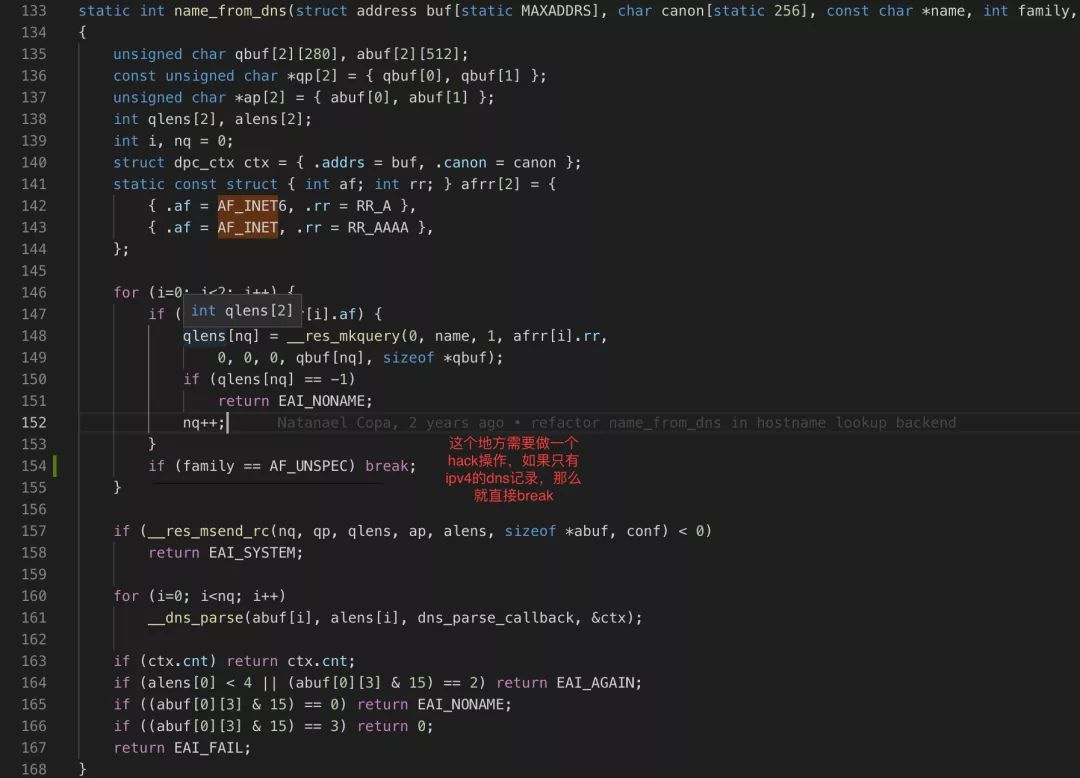
最后,这个问题其实是因为业务服务大多数是使用 http 短链接造成的,现在房多多已经全站使用 http2 长连接,这个瓶颈其实也就不存在了。
流量突然增高 slab分配失败导致机器负载高
容器平台集群不定期的报slab memory malloc的错误
系统负载高时,服务器内核大量报slab cache错误,升级centos 7.5 新内核862解决。值得一提的是,在容器时代,大家对内核的要求越来越高也越来越依赖内核的功能,很多公司其实都走在了内核迭代的前列 发现了很多 bug 并对社区做出了贡献。
物理机配置问题导致容器网络不通
我们有出现过一次交付物理机 restart network 后没有开启 ipv4_forward 导致的改物理机上的容器 overlay 网络挂的问题。
我们的解决方法是在启动容器前通过 ping 网关的方式检查 DNS服务和网络是否打通。
发布系统改造
构建流程自定义
在容器化的过程中,我们也把构建流程做了优化,引入了 jenkins pipeline 功能。Pipeline 对于我们的最重要的好处是可以把构建流程 DSL 代码化,并可以针对每一个项目自定义构建流程,当然我们有提供一个大体的框架,用户只需要更改自己所需要的就可以了,如下图:
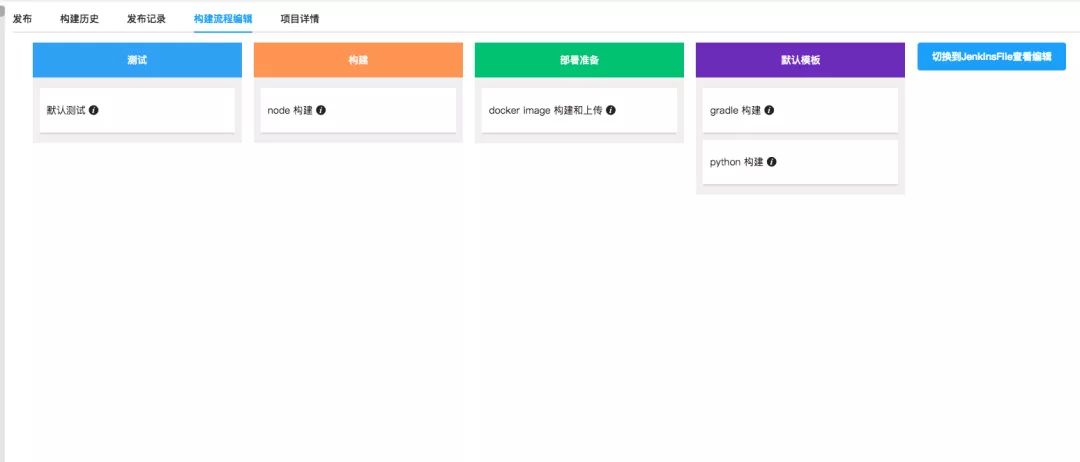
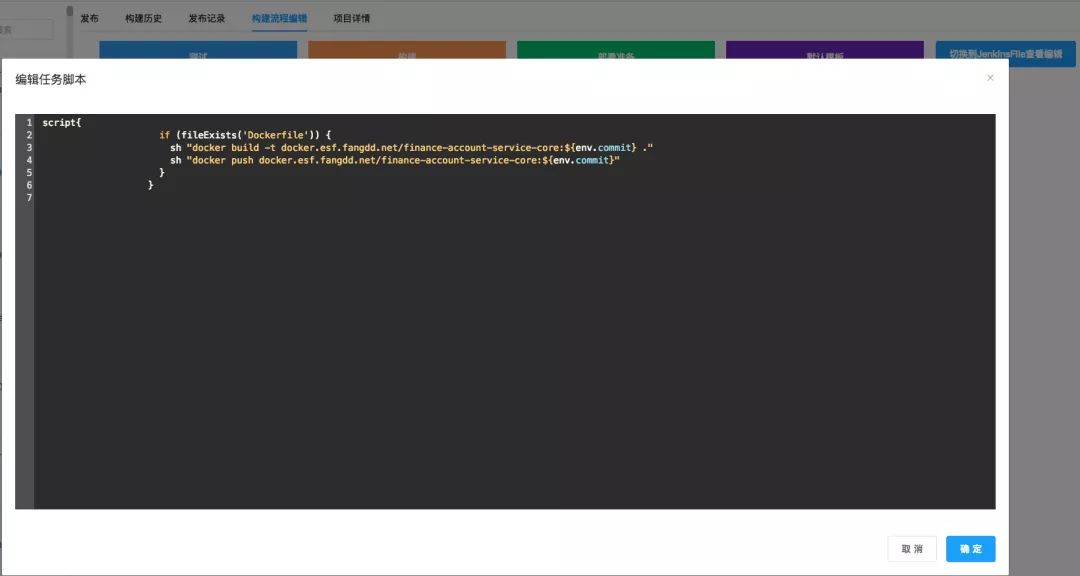
最终会生成一个 jenkinsfile 并在每次构建的时候都回去调用项目对应的 jenkinsfile。有了这样的功能,开发就可以根据自己的需求,轻松的更改自己项目的构建流程。
Web Terminal
我们根据业务开发的需求开发了 web 进入 docker 容器的功能。原理是转发 docker exec 命令到对应的物理机上,并转发输入输出。支持快捷键和高亮,体验良好。
Log
日志我们通过在转发 docker logs 请求获取最新的2000条(默认,可配置)日志打印到 web 页面上,支持自动刷新和滚动。
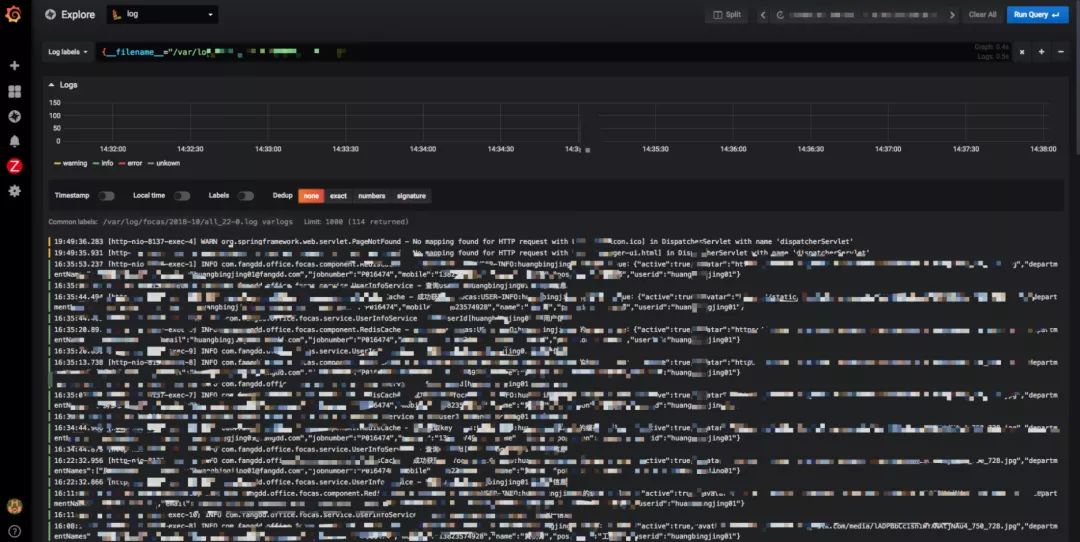
日志收集
我们会把项目输出的日志通过 volume 都挂载到每台宿主机的固定目录下,并用 global 模式部署 filebeat 进行采集,输出到我们的elastic集群上,然后在 elk 平台上查询日志。最近我们也在测试环境尝试 grafana loki 项目,他和 elastic 的原理相反,只索引必要的字段,可以节省大量的机器资源,如果是用来做"distribute grep"的话就很合适。
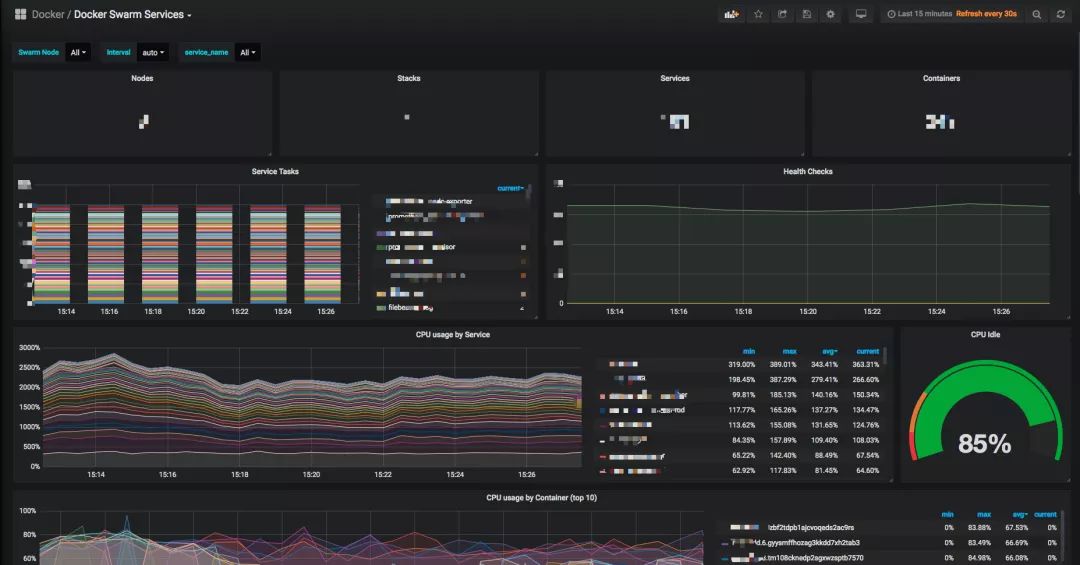
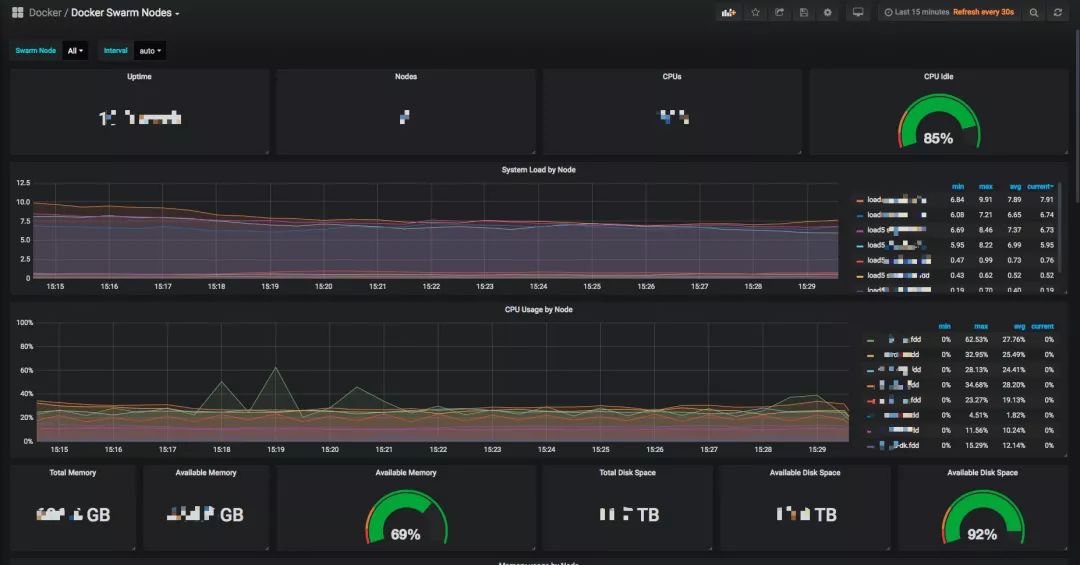
监控
监控我们使用了 swarmprom 开源项目,监控项比较丰富,覆盖了机器基础指标,容器指标,可以较快的定位问题,当时当容器集群出现宕机等情况时,监控会暂时失效,所以我们在容器集群外也部署了针对机器的基础监控。具体效果如下:
推广
容器的推广需要业务开发和业务运维的支持,不然很难推动。
推广首先要让开发和运维感受到红利:
容器相对于虚拟机更轻量化,可以实现秒级启动。
测试、预发布、线上的容器部署配置、环境 完全一致。
可以根据 CPU、内存或者 QPS 和延时快速扩容,提升服务能力。
服务 crash 会自动启动,自带高可用。
这四个特性的组合,可以给业务带来更大的灵活度和更低的计算成本。
我们团队是把这个容器平台当成一个产品来运作,业务开发就是我们的用户。
在推进容器化的过程中,我们还会做如下的事情:
通过培训让开发了解我们的产品优势(对比虚拟机)。
提供使用文档、接入文档等使得产品的易用度增加。
在迁移时给予开发更高优先级的支持。
资源尽量都加入容器集群,停止并减少虚拟机的供给。
总结
从传统的虚拟机架构到现在的基于云原生的容器云架构,带来了秒级部署、秒级扩缩容、简化了CI/CD 流程、提供Service Mesh 微服务治理能力。
如果按虚拟机时代运维人肉调度服务,人肉管理资源,在新虚拟机部署一个新应用或者扩容一个应用的时间在10分钟以上,和现在的按秒计算时间是质的变化,这是招再多的业务运维人员也达不到的,无形中省去了很多人力成本。
通过容器云的落地,我们得到了一个面向服务的平台,把机器资源抽象,屏蔽了和发布无关的机器细节、部署细节,开发不用再了解自己的应用在哪一台物理机上面。运维也可以从茫茫多的管理表格中解脱出来,只需要关注集群利用率,添加机器资源即可。这样有利于公司 DevOps 的推行,提高开发效率和开发个体的创造力不再被运维限制,大大提升团队生产力。
接下来,我们还会根据自身的需求迭代服务治理、容器编排的功能,把管理集群的常规操作平台化,尽量做到日常操作可以不登录物理机去操作。
欢迎大家和我们一起探讨和交流,谢谢!
