




openGauss介绍
openGauss是什么?20字介绍openGauss,openGauss是一个开源的、单体式、弹性的、高可用、容错、支持行、列、内存的关系型数据库。
openGauss采用中国开源协议木兰(Mulan),这个 比 Apache License 更友好,这意味着中小企业都可以自由使用,不用担心任何商业问题。
openGauss是一个单体数据库,它的性质与MySQL、PostgresSQL一样是单机安装。起初,我阅读华为的Gauss书藉,一直以为openGauss有一个组件叫GTM,事实上GTM是分布式GaussDB的一个组件,与OpenGauss没有关系。OpenGauss与GaussDB有什么关系? GaussDB是华为高斯数据库的一个统称,之前GaussDB有Gauss 100和Gauss 200两个型号,为华为内部信息系统服务。最后GaussDB对外的发展只在云上提供商业服务,商业服务支持分布式版本。华为把GaussDB的内核能力整合,与商业版一样的内核能力提供单机版的GaussDB。这个就是openGauss。
约束于单机处理能力,openGauss的弹性扩展就迁移到云上才能扩展了。如果你的写请求不多,使用openGauss没有问题,如果请求太多,华为云的GaussDB也能解决你的性能问题。
openGauss支持高可用和容错,通过一主多从或者一主多从级联实现高可用。工作原理,主从之间通过WAL日志同步数据,如果主节点挂掉,那么从节点替代主节点的工作,继续对外提供服务。
openGauss是一个支持行、列、内存的关系型数据库,目前行式在各种业务场景最为常用。毕竟是单机式,列式和内存引擎再成熟也不能提供太多的计算能力。
OpenGauss布署方式
容器安装方式
拉取openGauss的docker镜像源
cat>/etc/docker/daemon.json<<EOF
{
"registry=mirrors": ["https://oinh00fc.mirror.aliyuncs.com"]
}
EOF
[root@hybriddb03 ~]# docker search openGauss
INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED
docker.io docker.io/enmotech/openGauss openGauss latest images created by Enmotech 12
docker.io docker.io/fibird/openGauss 1
docker.io docker.io/gaobo1997/opengauss_compile openGauss Compile Environment 1
docker.io docker.io/munanqing/openGauss 基于openGauss-2.0.1-CentOS-64bit.tar.bz2构建 1
docker.io docker.io/1049696130/openGauss opengauss的编译开发环境 0
docker.io docker.io/aff123/openGauss aff学习opengauss 0
[root@hybriddb03 ~]# docker pull munanqing/openGauss
单体数据库安装
IP:IP1
主机名:主机名
端口规划:26000
目录规划:/gaussdb
<?xml version="1.0" encoding="UTF-8"?>
<ROOT>
<!-- openGauss整体信息 -->
<CLUSTER>
<PARAM name="clusterName" value="dbCluster" />
<PARAM name="nodeNames" value="主机名" />
<PARAM name="backIp1s" value="IP1"/>
<PARAM name="gaussdbAppPath" value="/gaussdb/app" />
<PARAM name="gaussdbLogPath" value="/gaussdb/log" />
<PARAM name="gaussdbToolPath" value="/gaussdb/om" />
<PARAM name="corePath" value="/gaussdb/corefile"/>
<PARAM name="clusterType" value="single-inst"/>
</CLUSTER>
<!-- 每台服务器上的节点部署信息 -->
<DEVICELIST>
<!-- node1上的节点部署信息 -->
<DEVICE sn="1000001">
<PARAM name="name" value="主机名"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP1"/>
<PARAM name="sshIp1" value="IP1"/>
<!--dbnode-->
<PARAM name="dataNum" value="1"/>
<PARAM name="dataPortBase" value="26000"/>
<PARAM name="dataNode1" value="/gaussdb/data/db1"/>
</DEVICE>
</DEVICELIST>
</ROOT>
如果不用容器安装,openGauss就只能选择编译安装,目前没有支持yum安装,编译安装比较罗嗦,需要准备一份XML配置文件,里面指定端口参数、IP参数、主机名、集群名等等,然后运行环境检测脚本,等待系统各项指标是否 满足安装条件。当脚本提示各项指示一切正确,最后以OMM的身份指定XML配置文件 ,运行安装程序,如下。
[omm@hybriddb03 openGauss]$ ./script/gs_install -X ./cluster_config.xml
Parsing the configuration file.
Check preinstall on every node.
Successfully checked preinstall on every node.
Creating the backup directory.
Successfully created the backup directory
如果考虑数据库性能,可以在安装指定参数
[omm@hybriddb03 openGauss]$ ./script/gs_install -X ./cluster_config.xml
--gsinit-parameter="--encoding=UTF8"
--dn-guc="max_connections=10"
--dn-guc="max_process_memory=3GB"
--dn-guc="shared_buffers=128MB"
--dn-guc="bulk_write_ring_size=128MB"
--dn-guc="cstore_buffers=16MB"
max_connections 全局的最大连接数:由运行参数max_connections指定,默认值为5000
max_process_memory 设置一个数据库节点可用的最大物理内存
shared_buffers 设置openGauss使用的共享内存大小。
bulk_write_ring_size 数据并行导入使用的环形缓冲区大小,建议导入压力大的场景中增加数据库节点中此参数配置
cstore_buffers 列存表使用cstore_buffers设置的共享缓冲区,几乎不用shared_buffers。因此在列存表为主的场景中,应减少shared_buffers,增加cstore_buffers。
一主多备安装
一主多备与单机安装差不多,基于篇幅,这里就不说了。只列出配置
IP:IP地址1,IP地址2,IP地址3
主机名:prod,stb1,casstb
端口规划:26000
目录规划:/gauss
<?xml version="1.0" encoding="UTF-8"?>
<ROOT>
<!-- openGauss整体信息 -->
<CLUSTER>
<PARAM name="clusterName" value="gscluster" />
<PARAM name="nodeNames" value="prod,stb1,casstb" />
<PARAM name="gaussdbAppPath" value="/gauss/app" />
<PARAM name="gaussdbLogPath" value="/gauss/log" />
<PARAM name="tmpMppdbPath" value="/gauss/tmp"/>
<PARAM name="gaussdbToolPath" value="/gauss/om" />
<PARAM name="corePath" value="/gauss/corefile"/>
<PARAM name="backIp1s" value="IP地址1,IP地址2,IP地址3"/>
</CLUSTER>
<!-- 每台服务器上的节点部署信息 -->
<DEVICELIST>
<!-- node1上的节点部署信息 -->
<DEVICE sn="prod">
<PARAM name="name" value="prod"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP地址1"/>
<PARAM name="sshIp1" value="IP地址1"/>
<!--dn-->
<PARAM name="dataNum" value="1"/>
<PARAM name="dataPortBase" value="26000"/>
<PARAM name="dataNode1" value="/gauss/data/db1,stb1,/gauss/data/db1,casstb,/gauss/data/db1"/>
<PARAM name="dataNode1_syncNum" value="0"/>
</DEVICE>
<!-- node2上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="stb1">
<PARAM name="name" value="stb1"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP地址2"/>
<PARAM name="sshIp1" value="IP地址2"/>
</DEVICE>
<!-- node3上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="casstb">
<PARAM name="name" value="casstb"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP地址3"/>
<PARAM name="sshIp1" value="IP地址3"/>
<PARAM name="cascadeRole" value="on"/>
</DEVICE>
</DEVICELIST>
</ROOT>
一主多备多级联安装
IP:IP1,IP2,IP3
主机名:prod,stb1,casstb
端口规划:26000
目录规划:/gauss
<?xml version="1.0" encoding="UTF-8"?>
<ROOT>
<!-- openGauss整体信息 -->
<CLUSTER>
<PARAM name="clusterName" value="gscluster" />
<PARAM name="nodeNames" value="prod,stb1,casstb" />
<PARAM name="gaussdbAppPath" value="/gauss/app" />
<PARAM name="gaussdbLogPath" value="/gauss/log" />
<PARAM name="tmpMppdbPath" value="/gauss/tmp"/>
<PARAM name="gaussdbToolPath" value="/gauss/om" />
<PARAM name="corePath" value="/gauss/corefile"/>
<PARAM name="backIp1s" value="IP1,IP2,IP3"/>
</CLUSTER>
<!-- 每台服务器上的节点部署信息 -->
<DEVICELIST>
<!-- node1上的节点部署信息 -->
<DEVICE sn="prod">
<PARAM name="name" value="prod"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP1"/>
<PARAM name="sshIp1" value="IP1"/>
<!--dn-->
<PARAM name="dataNum" value="1"/>
<PARAM name="dataPortBase" value="26000"/>
<PARAM name="dataNode1" value="/gauss/data/db1,stb1,/gauss/data/db1,casstb,/gauss/data/db1"/>
<PARAM name="dataNode1_syncNum" value="0"/>
</DEVICE>
<!-- node2上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="stb1">
<PARAM name="name" value="stb1"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP2"/>
<PARAM name="sshIp1" value="IP2"/>
</DEVICE>
<!-- node3上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="casstb">
<PARAM name="name" value="casstb"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="IP3"/>
<PARAM name="sshIp1" value="IP3"/>
<PARAM name="cascadeRole" value="on"/>
</DEVICE>
</DEVICELIST>
</ROOT>
安装体验总结
在产品安装方面对比,相对TiDB和OceanBase,openGauss比较稚嫩,没有太大优势,但是它大有发展空间。MySQL为什么能够成为流行数据库,最主要的一个原因它拿来就用。openGauss是一个单机数据库,以后openGauss发展成为解压就能用,或者直接yum安装可以提高它的流行程度
OpenGauss数据库内存和进程管理
由于openGauss是基于postgresql9.2.4,先看PG的进程结构和内存结构。
PostgreSQL是一个客户端/服务器风格的关系型数据库管理系统,采用多进程架构,运行在单台主机上,包含下列进程:
- Postgres服务器进程(postgres server process)是所有数据库集簇管理进程的父进程。
- 每个后端进程(backend process)负责处理客户端发出的查询和语句。
- 各种后台进程(background process)负责执行各种数据库管理任务(例如清理过程与存档过程)。
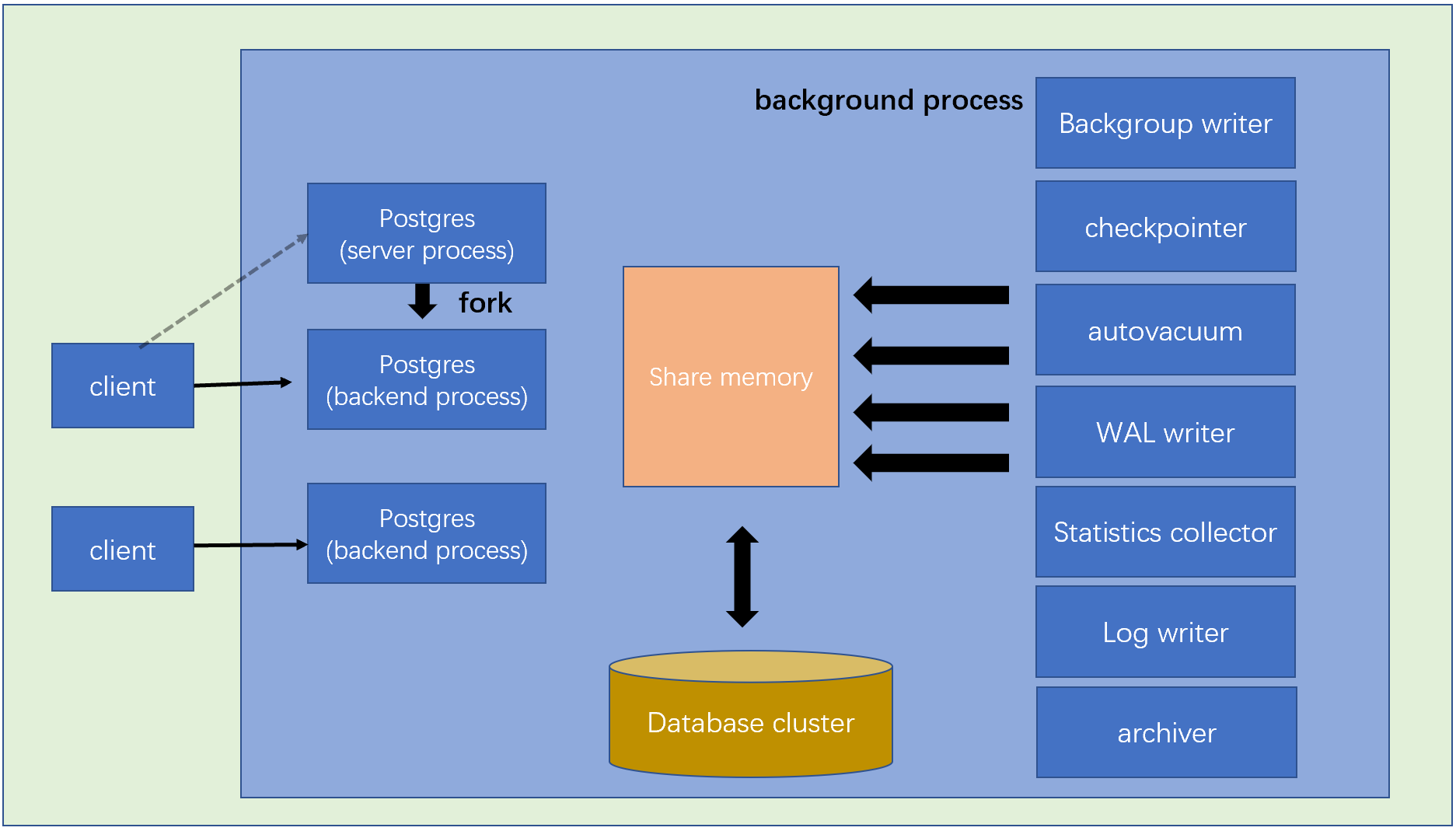
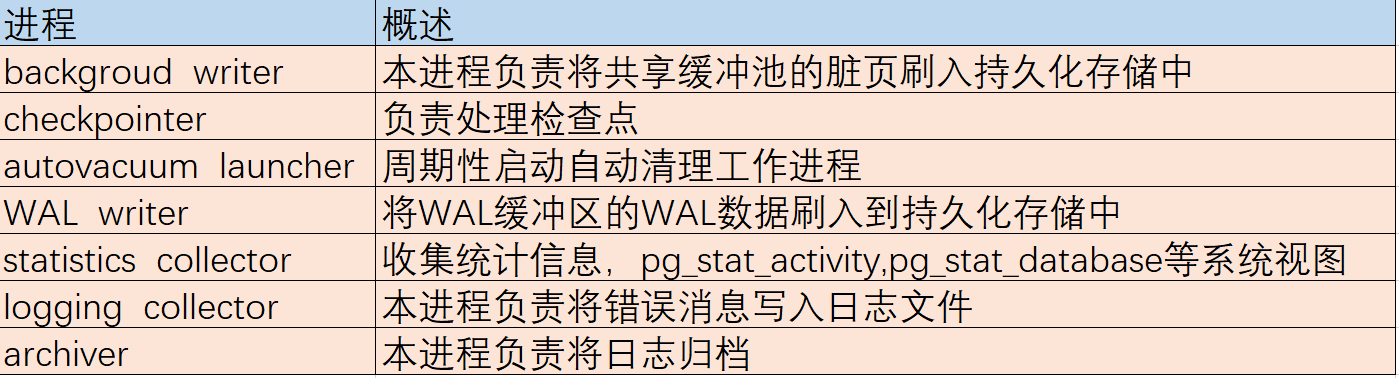
postgresql与oracle一样有多个进程,职责作用如下
现在的openGauss看看有多少个进程,如下只有一个进程
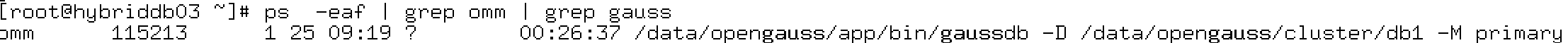
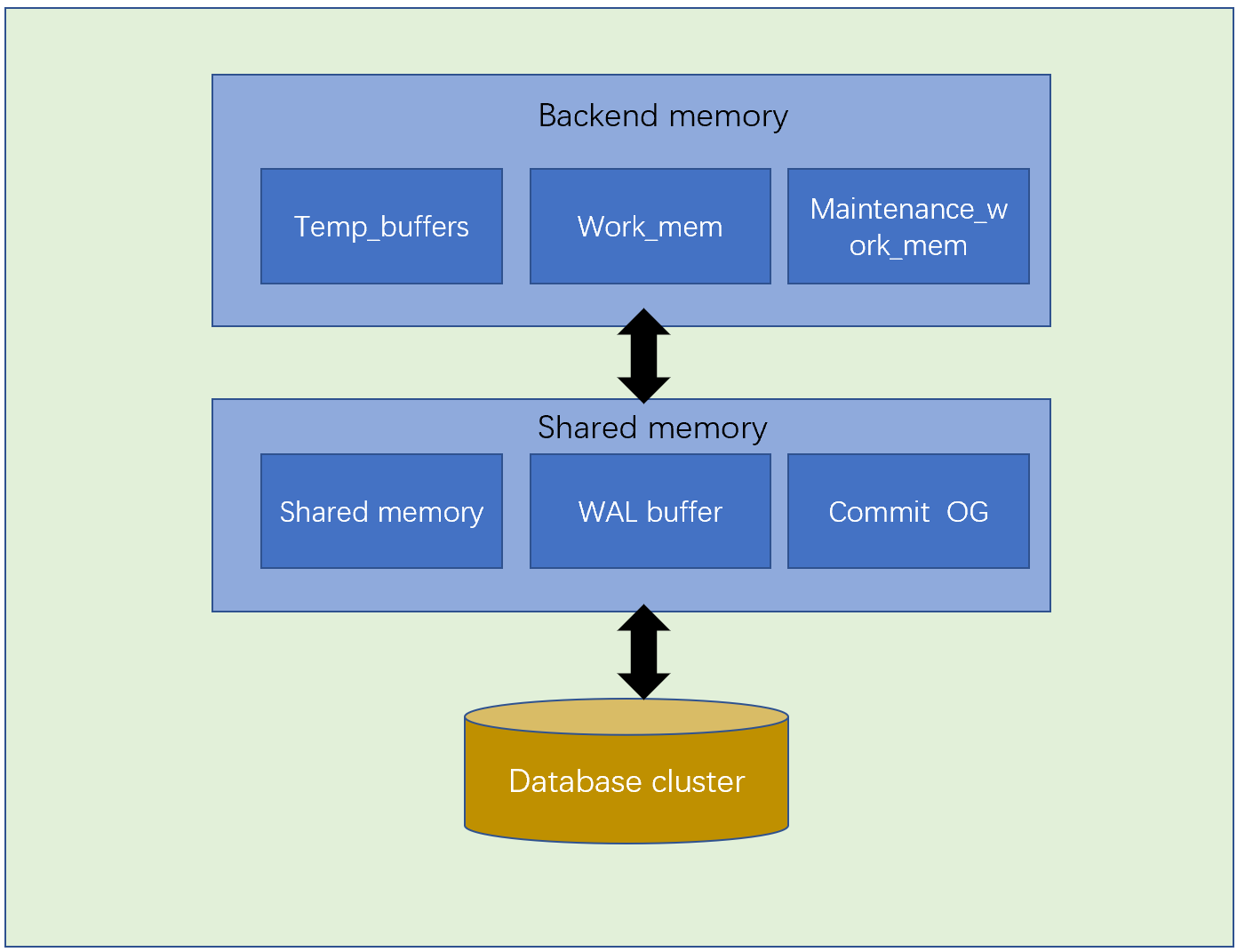
PostgreSQL的内存架构可以分为两个部分:
- 本地内存区域——由每个后端进程分配,供自己使用。
- 共享内存区域——供PostgreSQL服务器的所有进程使用。
每个进程还划分多个区域,每个区域有负责的工作,根据需求定义内存大小
总结,openGauss是单进程多线程结构 ,它的内存管理自然就比PostgreSQL复杂多了,openGauss把pg很多进程管理的事都换成线程管理,所以postgresql的性能影响较大的参数,例如最大连接数max_connections,内存关联参数shared_buffers、wal_buffers、work_mem、effective_cache_size
,wal关联参数 checkpoint_segments、checkpoint_completion_target等都可以在opengauss找到,或者在openGauss里面换了名称的。
