




openLooKeng
Make Big Data Simplified
openLooKeng是一款开源的高效数据虚拟化分析引擎。在使用openLooKeng过程中,社区一小伙伴遇到数据查询存在不同步的问题;对此,该小伙伴非常给力,向社区提供了解决方案。我们非常感谢他的支持,也希望本篇博客对其他小伙伴有帮助。

欢迎访问openLooKeng官网
https://openlookeng.io
社区代码仓
https://gitee.com/openlookeng
本期分享

问题
openLooKeng的查询存在不同步的问题,现在需要解决这个问题。
经过分析,查询读的是Cache。在AA模式(Active/Active Mode)下,一个节点修改了Metastore ,另外一个节点不会得到通知,所以不会使缓存失效。问题出现在AA模式下缓存不同步的问题。
解决办法
目前openLooKeng的缓存模式只有Guava。
在异步的时候存在数据不同步的问题。解决办法:
使用redis,redis作为分布式缓存是相当优秀。支持很多数据类型,支持cluster模式。但是这个方法会引入新的技术,会让部署困难。最小化部署,尽量不引入第三方依赖服务;
考虑到服务已经有Hazelcast了,可以考虑用Hazelcast作为缓存来使用。(注 其实还有一种方案,让 Hazelcast作为广播用,当发生更新数据的时候,同时通知两个节点的Cache失效) 现在采用Hazelcast作为分布式缓存,同时保留以前的Guava缓存。
两套缓存可以让用户选择,一个是local的,一个是distributed;架构模式如下:
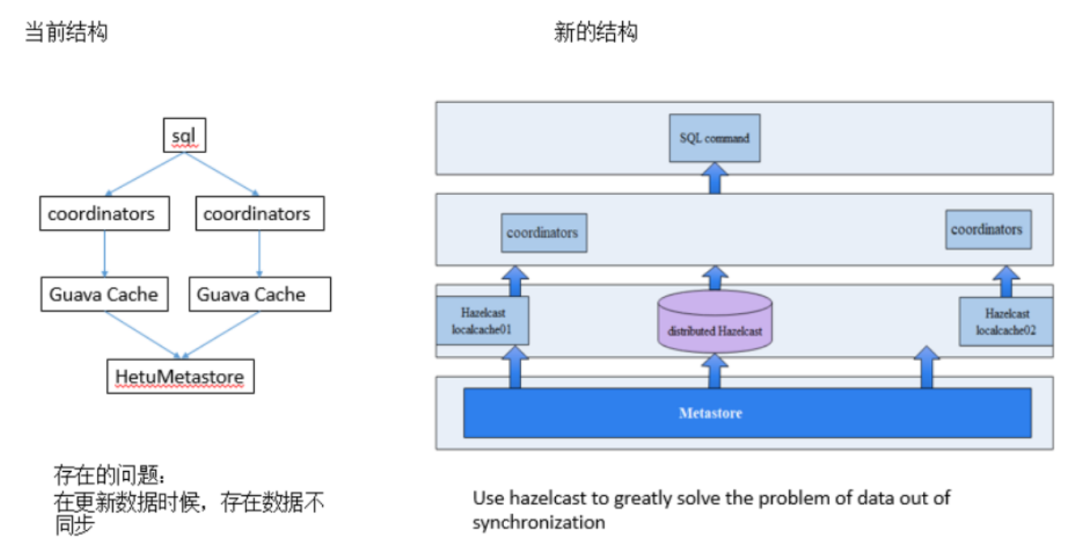
读写策略模式如下:
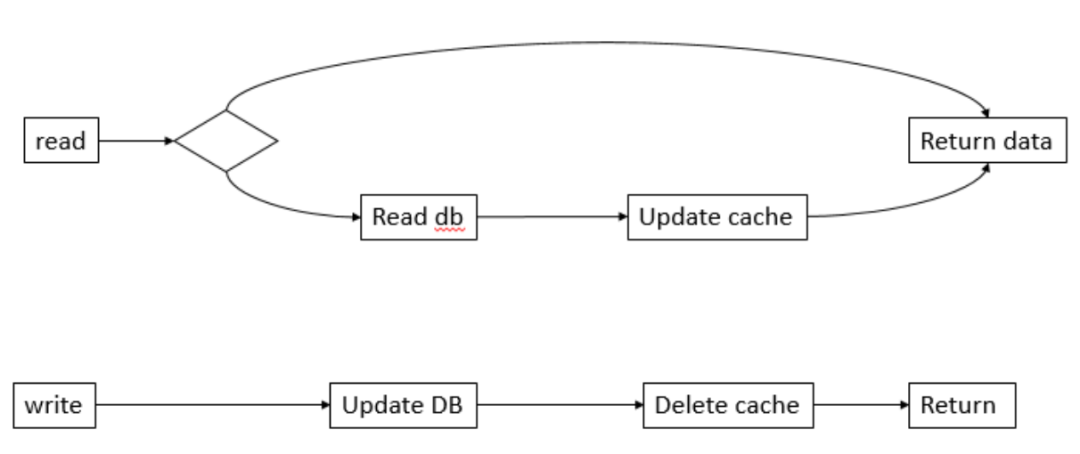
Cache Aside Pattern,Delete the existing Cache when writing the database。Cache Aside Pattern能有效避免并发问题。
Cache Aside的优点:
当写操作发生时,假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
我们假设:两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。所以这个设计是错误的,不建议使用。
一个是查询操作,一个是更新操作的并发,首先,没有了删除Cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。
Hazelcast 学习
Hazelcast作为一个分布式机制,可以用Hazelcast的Imap作为分布式缓存。
这里需要注意的是由于Hetumetastore存储有六个缓存,需要对每个缓存实例化。不能用一套。
IMap<Integer, List<String>> clusterMap1 = instance.getMap("MyMap1");IMap<Integer, List<String>> clusterMap2 = instance.getMap("MyMap2");...
关于Hazlcast的学习,请参看另外一篇文章:
Hazelcast真是一个有意思的东西https://www.chkui.com/article/hazelcast/hazelcast_configuration_management
这个网网址打不开的话。参考这个https://my.oschina.net/chkui/blog/732408https://my.oschina.net/chkui/blog/729698
里面涉及到的github地址:https://github.com/dragonetail/Hazelcast-Demo
这个版本比较老,需要更新Hazelcast版本,可以本地跑起来看看Hazelcast的原理。
在这种中间还学习到Inject的使用,相当有意思的一个注入,在一个接口拥有多个实现类的时候,这个方法比较快捷。关于注入的方式我在后面再介绍。
开发过程比较简单,增加一套缓存模式即可。这套缓存模型和Guava的接口保存一致,代码也一样,如果后期需要用到redis cache,那代码就相当冗余。
Inject 学习
当一个接口有多个实现类的时候,如何动态指定。可以采用三种方式来解决这个问题。
(1)@Service 注入。指定bean的具体名字,like this:
@Service("s1")public class TestServiceImpl1 implements ITestService {@Overridepublic void test() {System.out.println("接口1实现类 ...");}}
@Service("s2")public class TestServiceImpl2 implements ITestService {@Overridepublic void test() {System.out.println("接口2实现类 ...");}}
(2)策略设计模式 ,定义一个Map集合,然后把所有的实现类都放入到这个集合中,然后根据当前的会员类型去进行不同的操作。参考代码
具体参考:
https://blog.csdn.net/qq_42087460/article/details/90441298?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control
public class DisCountStrageService {Map<String,DiscountStrategy> discountStrategyMap = new HashMap<>();// 构造函数,如果你是集合接口对象,那么久会把spring容器中所有关于该接口的子类,全部抓出来放入到集合中public DisCountStrageService(List<DiscountStrategy> discountStrategys){for (DiscountStrategy discountStrategy: discountStrategys) {discountStrategyMap.put(discountStrategy.getType(),discountStrategy);}}public double disCount(String type,Double fee){DiscountStrategy discountStrategy =discountStrategyMap.get(type);return discountStrategy.disCount(fee);}}
(3)Inject是guice的一个小巧的框架,他是通过binder来实现注入具体的实现类的,实现modul的接口,重写configure方法。
public class JdbcMetastoreModuleimplements Module{@Overridepublic void configure(Binder binder){configBinder(binder).bindConfig(JdbcMetastoreConfig.class);configBinder(binder).bindConfig(HetuMetastoreCacheConfig.class);binder.bind(HetuMetastore.class).annotatedWith(ForHetuMetastoreCache.class).to(JdbcHetuMetastore.class).in(Scopes.SINGLETON);binder.bind(HetuMetastore.class).to(HetuMetastoreCache.class).in(Scopes.SINGLETON);newExporter(binder).export(HetuMetastore.class).as(generator ->generator.generatedNameOf(HetuMetastoreCache.class));}}
重构
重构思路:需要对外提供一个Cache接口,最后启用具体的实现类,通过配置项来改变。
这个Cache接口可以实现Guava,可以实现Hazelcast。
总体结构变化:
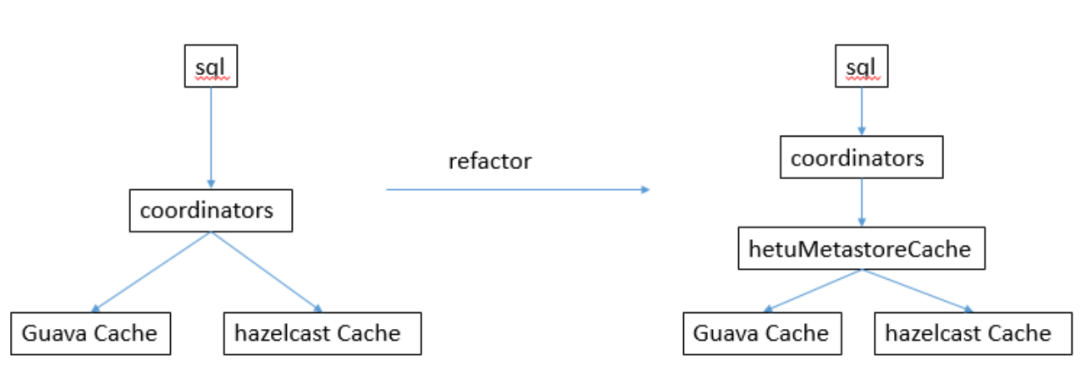
重构难点1:
两套Cache,用HetuMetastoreCache接口来解决。解决办法:用泛型,用泛型,用泛型。
重构难点2 :
对外暴露接口要统一HetuMetastoreCache ,而且需要对声明变量进行初始化。解决办法:善于应用继承Extends;Guava Cache和Hazelcast Cache继承HetuMetastoreCache这个接口。这里面用到Cache变量又要统一使用Hetucache,Hetucache有两种模式Guava的Cache和Hazelcast的Map。
实际实现结构如下:
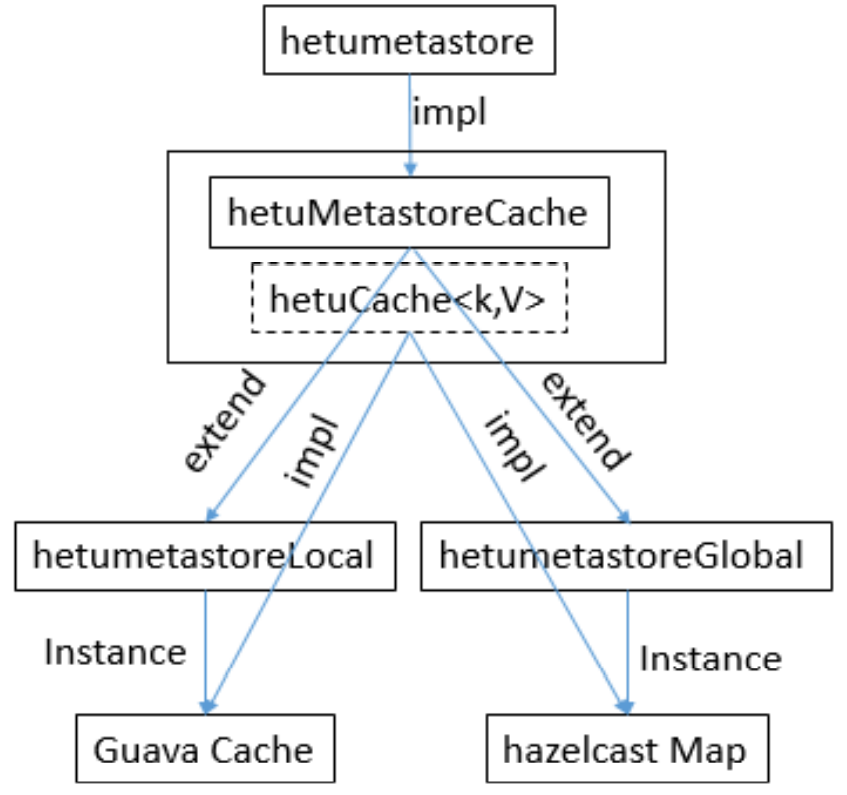
现在结构的优点,对外只暴露HetumetastoreCache。这样易扩充,后期如果需要实现redis的Cache,只需要在后面实现即可。
一些问题的解决方法
由于对Inject的用法存在误解,报错Explicit bindings are required。Java的Guice,如果你需要使用@Inject,那你的构造函数里面所有参数都需要实现的binding。
Hazelcast版本4.0.3由于对序列化有依赖,需要自己定义序列化,这里面涉及到对Optional的序列化,Option序列化存在一定问题。幸运的是查到官方文档4.2的版本提升了对Optional的支持,查看源码的实现,我们可以借签过来。
总结
看源码,多向优秀的朋友和同事咨询,解决问题的角度会让人茅塞顿开。重构果然对语言的掌握能力要求较高。这个项目中,对我这薄弱的Java知识进行了一次深化。
★ openLooKeng,Big Data Simplified ★

