




openLooKeng
近日,随着11支获奖队伍的颁奖典礼举行,2021世界人工智能大会(WAIC)黑客马拉松圆满落下了帷幕。在为期1天的开发竞赛中,参赛队伍【万有引力】,获得了题目「openLooKeng机器学习库支持算法扩展」的冠军,恭喜!

关于WAIC 黑客马拉松
世界人工智能大会(WAIC)是经国务院批准,国家发展改革委、科技部、工业和信息化部、国家互联网信息办公室、中国科学院、中国工程院等部委与上海市政府共同举办的顶级人工智能会议。而 黑客马拉松是 WAIC 期间唯一的一场黑客松,由世界人工智能大会组委会办公室作为指导单位,机器之心,MindSpore 开源社区,Waston Build 创新中心,六七八九集团主办,此次黑客松设计多道赛题,聚焦 AI 技术与应用热点问题,吸引了数十个团队参加。

7月10日,经过一天的开发挑战,「万有引力」团队获得了「openLooKeng 机器学习库支持算法扩展挑战赛」的冠军。据了解,该团队虽然仅有2人,但开发思路与逻辑非常清晰,配合上也十分默契。本期,小助手邀请到该团队队长余杨,来跟我们聊聊此次的参赛经历与体会。

▲ 大赛颁奖现场
团队介绍
团队成员:余扬
重庆交通大学计算机科学专业,研二学生
研究方向:基于深度学习的大规模图像检索、技术栈主要是后端开发涉及到的,擅长编程语言为Java和python。
团队成员:丁海杰
南京邮电大学计算机科学专业,研二学生
研究方向:基于深度学习的自然语言生成,擅长编程语言为Python和Java。

▲ 左:导师刘松灵、队员余扬、丁海杰
我们是2021 WAIC黑客松的“万有引力”团队,很荣幸在openLooKeng赛道的“openLooKeng 机器学习库支持算法扩展”赛题获得冠军,以下是我们团队对本次比赛的一些分享,希望对其他小伙伴有帮助。
赛题分析
openLooKeng机器学习库支持算法扩展挑战
在这道赛题中,挑战者需要在 openLooKeng 现有已经支持的机器学习算法上,扩展支持常见常用的两个聚类算法——DBSCAN 和 KMeans 以及两个个分类算法——KNN 和朴素贝叶斯。
题目要求扩展的这两类算法属于机器学习里面比较经典的算法,算法原理不是很难,实现的时候需要考虑一下如何设计一个数据结构来组织和保存训练之后的模型即可。
而我们觉得主要难点还是如何将实现好的算法扩展到openLooKeng里面,即如何在sql语句里面即可调用对应的算法进行模型训练与预测。
实现思路
由于openLooKeng支持SPI扩展,于是我们想把每个算法封装为一个自定义函数插件,然后提供给openLooKeng即可。每个算法需要训练和预测两个模块,于是一个聚合函数用于训练,一个标量函数用于加载模型然后预测;
训练完成之后将模型序列化,然后在预测的时候将序列化结果输入给预测函数,执行反序列化得到对应的模型,再进行预测;
例如下表鸢尾花数据集部分数据:
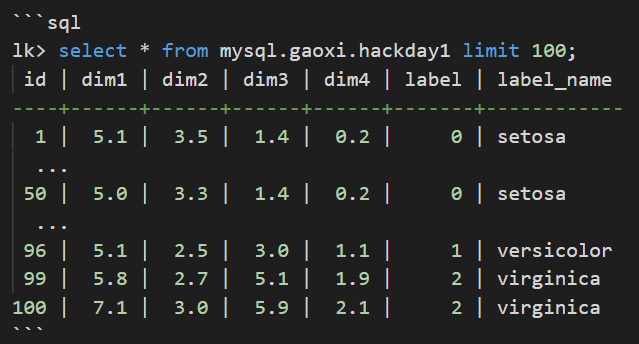
总的来说,我们需要实现两个自定义函数:
1. 训练模型的函数`learn_knn_model`,
这个函数的功能需要具备:数据聚合、模型训练的功能,模型保存。调用这个函数训练模型的sql语句如下:

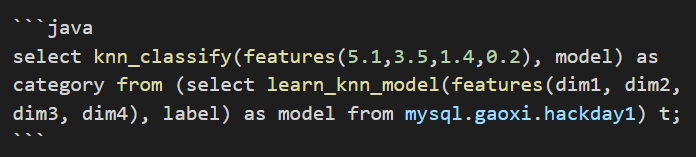
2. 调用模型进行分类的函数`knn_classify`,
这个函数的功能需要具备:加载模型、对输入数据进行分类的功能,返回分类预测结果。结合上面整个sql语句大致如下所示:
利用已有的实现
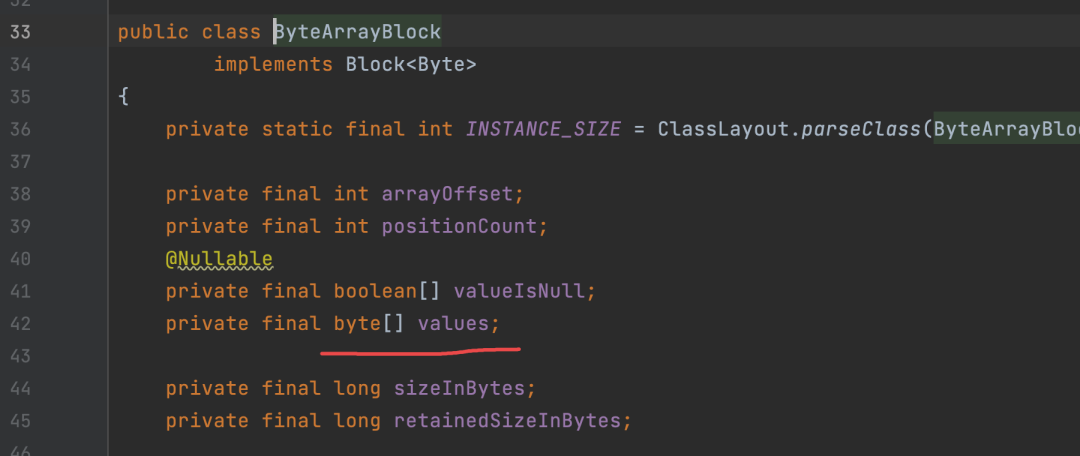
1. Block:这个数据结构对应有很多种不同的实现,作用就是存放相同类型(int、long、byte等)的数据,可以看做一个大的数组,如下的ByteArrayBlock:
2. AccumulatorState:AccumulatorState用于充当一个中间变量的角色,负责保存读取和聚合之后的数据。通过实现此接口来创建符合自己功能的state,然后实现创建state的对应的Factory类(工厂类,用于创建这个state)以及对应的序列化类(表示序列化与反序列化此state的方法,用于在聚合过程中不同节点之间的传输);

3. 在presto-ml这个模块里面,可以发现已经一些造好的轮子了,例如features函数,这个自定义函数是实现将sql读取的每一行数据封装为一个Block;还有用于存放特征向量的FeatureVector,这些已经实现好的都可以利用起来。
我们的实现
总的来说分为如下所示三步:数据从数据库中查出来聚合成数据集,然后用于模型训练,之后将训练好的模型保存起来,后面的预测和分类函数从保存的地方加载模型进行预测和分类;

以knn分类算法为例:
对于用于训练的聚合函数主要分为以下三步,详细的可以参考openLooKeng官方文档的函数一章:
1. input(AccumulatorState state, Block featureData):用于获取每行的输入,将输入的特征数据存放到state里面,而在openLooKeng集群里,input读取数据阶段和下面的combine聚合阶段很有可能在不同节点上进行,因此就需要将state里面的数据序列化传输;
2. combine(AccumulatorState state1, AccumulatorState state2):用于聚合上一步骤得到的state,将结果存放到第一个state1中;
3. output(AccumulatorState state, BlockBuilder out):这里面的state就是最终聚合得到的数据,也是在这一步从state里面取出所有用于训练的数据,然后对模型进行训练,然后将训练好的模型序列化到BlockBuilder里面;
模型,以knn模型为例
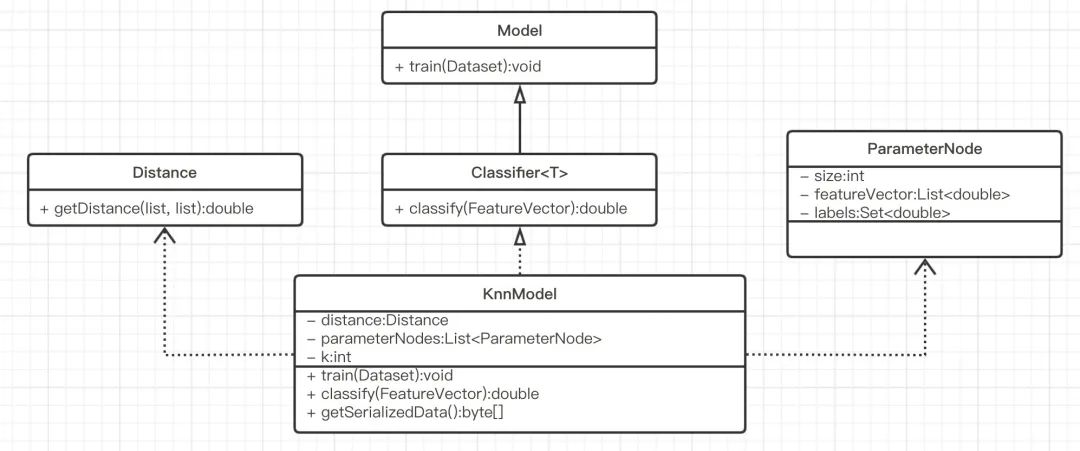
knn算法很简单,在模型训练层面,需要把只需要把训练数据经过预处理之后保存起来即可,KnnModel模型的类图如下所示,其中我们建立了ParameterNode用于保存模型参数:
模型加载使用
在模型保存方面由于openLooKeng目前貌似不支持统一的保存训练好的模型,因此我们选择的是将模型序列化之后传送给classifier,然后分类器再反序列化出来即可;
致谢
感谢赛事主办方和openLooKeng社区提供这个更近一步接触开源的机会,让我们收获良多,也祝愿openLooKeng越来越好。
近期活动
openLooKeng




Summer Time
扫码 ╳ 关注
我们
官方公众号|openLooKeng
小助手微信号|openLooKengoss
