




点击蓝字
关注我们
openLooKeng
哈喽~小伙伴们
大数据与人工智能领域的极具影响力的赛事之一,2020 CCF BDCI 大赛日前成功落下帷幕。在公布的单赛题获奖名单中,参与openLooKeng赛题的其中3支队伍,荣获大赛的一、二等奖。
上期,咱们围观了荣获2020 CCF BDCI 大赛一等奖队伍带来的论文分享(点此回顾)。
本期,我们来欣赏,荣获二等奖的其中一支队伍「进击的巨人」带来的分享。

期待地搓手手……
「进击的巨人」,由来自不同高校不同专业领域的3名学生组成。团队人数不多,但从队名中,我们就能感受到这支队伍旺盛的活力与毅力。相识于同一所高中的他们,赛程中分外团结,十分享受比赛带来的乐趣,最终摘取大赛二等奖的硕果。本期,这支年轻而富有活力的队伍将带来关于本次赛题“openLooKeng 性能优化”的技术分享。
团队介绍 | 团队名:进击的巨人 |
团队成员: | |
刘 祥 中国科学技术大学计算机学院 邱明璞 中国科学技术大学信息科学技术学院 秦杰杰 东北大学计算机科学与技术专业 |

邱明璞
左为秦杰杰; 右为刘祥

方案思路
我们本次设计主要是面向openLooKeng对接Hive数据源(文件采用ORC格式)的执行效率优化,具体的测试指标是openLooKeng引擎执行完100个sql语句的总时间。

由于测试方式的特殊性,使用面向通用查询的openLooKeng参数可能不会带来最优的查询效率,我们使用黑盒调优的方式。

首先建立openLooKeng查询执行时间与任务类型(0~99个查询),集群参数(节点数,核数,内存(只考虑同构情况)),openLooKeng参数之间的性能模型,即求解函数:
T = f (c,t,p)
其中,T代表任务的运行时间,c为集群参数,包括节点数,每个节点的核数和内存数,t为任务类型(0~99,分别代表100个任务),p代表openLooKeng的参数,这里选取了19个影响比较大的参数(包括openLooKeng查询的基本配置参数和关于hive连接器的相关配置参数)。
每个参数都在其取值范围内均匀产生随机数,在集群上开辟相应资源的容器(与集群参数相关)去运行相应的任务,采集运行时间,把参数和最终的运行时间存入训练集库。使用MATLAB的Regression Learner APP中的常用回归模型进行拟合,找到拟合最好的回归模型并保存。
我们的目标是使100个查询任务的运行时间和最短,即最小化目标函数:
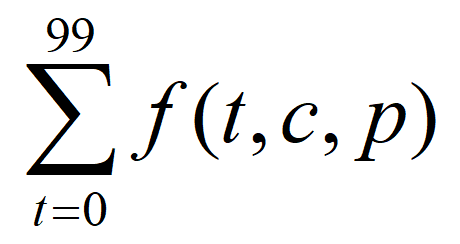
在集群参数c未知的情况下,我们可以使用以下策略求得相对较优的解:集群参数在合理的范围内均匀取值,每个集群参数都可以在参数的搜索空间中采用多起点爬山算法去搜索到一个最优的p,然后对所有的p取均值,最后得到最优的openLooKeng参数作为最后的配置参数。
若测试集群的配置已知,则在集群参数代入后,我们可将目标函数简化为:
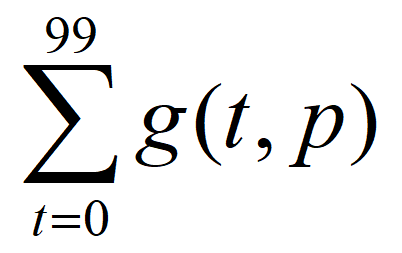
可以直接使用搜索算法求取最优的p,使得目标函数最小。我们采用的搜索算法是带限制条件的多起点爬山算法,可以在可行的时间内搜索到质量较优的解。
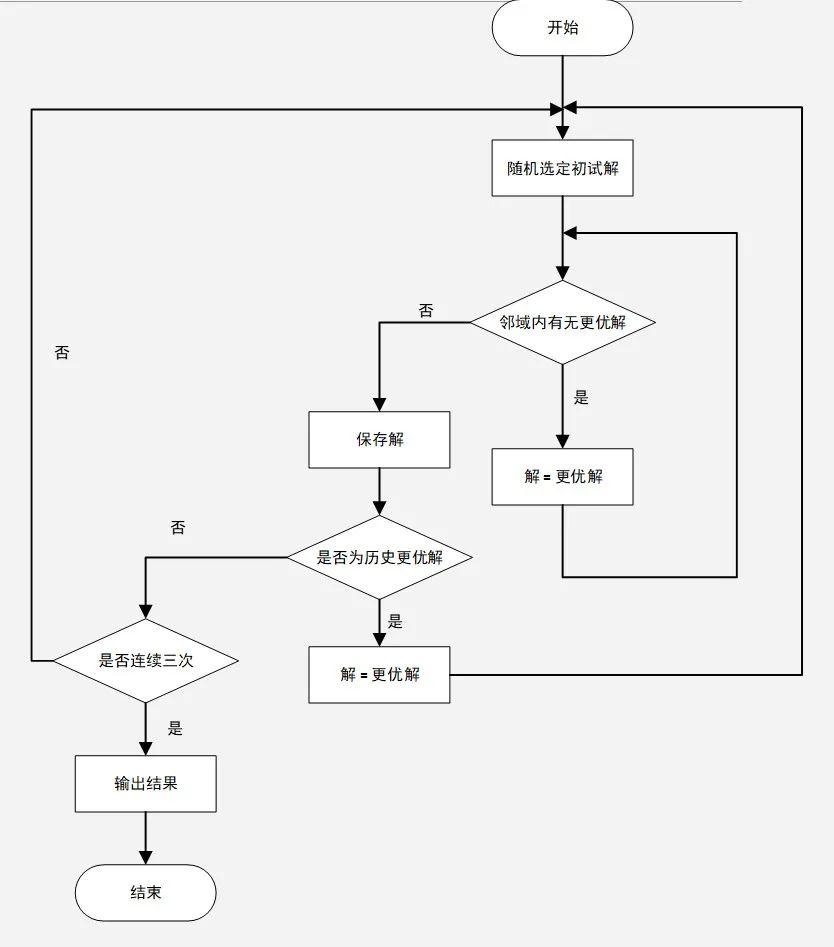
算法是在爬山算法的基础上运行多次,直到连续三次收敛到的局部最优解都不比之前搜索到的最优解更优,则结束搜索,并认为当前最优解即是我们需要的最优解。
总结
总的来说,结合性能建模和最优化搜索可以得到基本上最优的参数组合,在没有改动源码的基础上也能针对特定的运行环境和特定的测试集产生不错的优化效果(5%以上)。
而且由于性能建模会随着数据集的增多越来越准确,最优化搜索算法经过优化之后,也能在很短的时间内(20s)左右给出一个相对较优解。因此,对于参数敏感的黑盒系统都具有不错的调优效果。
openLooKeng, Big Data Simplified
以上便是「进击的巨人队」带来的分享
恭喜感谢这支朝气蓬勃的可爱队伍
愿你们在追梦路上乘风破浪,勇往直前
期待下次再见


如果你觉得开源很酷,欢迎加入我们社区,与志趣相投的朋友一起做点有意思的事儿!
https://openlookeng.io
https://gitee.com/openlookeng
https://github.com/openlookeng

喜欢就点个“赞”,我知道你“在看”哦 

