




openLooKeng,Big Data Simplified

小伙伴们,
历时3个月多、历经3万多人的角逐
2020 CCF大数据与计算智能大赛
(CCF Big Data & Computing Intelligence Contest)
(以下简称CCF BDCI)
终于迎来大奖揭晓时刻了!

我们赛题 [openLooKeng性能优化]
共吸引了632支队伍,658人参加
经过激(pai)烈(chu)角(wan)逐(nan)
其中3支极具青春活力的可爱队伍
成!功!上!榜!
CCF BDCI 单赛题奖项 openLooKeng 性能优化 | |
奖项 | 团队名 |
一等奖 | 中科大星辰队 |
二等奖 | 进击的巨人 |
二等奖 | 零叉零零 |
恭喜以上获奖的小可爱们
也感谢一直关注我们赛题的小伙伴们

Congratulation
在单赛题的奖项名单中,近70支获奖队伍排名表上,荣获一等奖的中科大星辰队占据表格的第一位。这让不少小伙伴们对这支队伍非常好奇。

▲ CCF BDCI 颁奖现场
据了解,该队队员们在此次比赛中相识,过程中分工合作,共同进步,出色地完成了本次赛题的任务,期间更进行了大量的测试分析,扎实的测试数据,展现了其队名仰望星空,脚踏实地之意,最终摘取大赛硕果。恭喜呀!
本期,中科大星辰队将分享关于本次赛题[openLooKeng 性能优化]的说明论文。让我们一睹这支队伍的风采。

▲ 中科大星辰队队长:徐宇鸣
2020 CCF 大数据与计算智能大赛
赛题名 | openLooKeng 性能优化
BY 中科大星辰队

中科大星辰队,队员均来自于中国科学技术大学先进数据系统实验室(ADSL),由李诚老师带队,两名大四本科生徐宇鸣、陈清源,三名大三本科生王章瀚、高楚晴、刘逸菲组成。

▲ 左起:王章瀚、陈清源、高楚晴、刘逸菲、徐宇鸣
本参赛队(中科大星辰队)面向Query进行优化选型,通过细粒度性能分析,针对分析发现的两个openLooKeng现存的比较严重的性能瓶颈进行优化:通过连接重排提升左深连接树的计算效率;通过预处理Query减少因临时中间表内联产生的重复计算。历经2个月的前期调研、性能分析以及优化实践,将openLooKeng的查询性能提升了近30%。
分布式,大数据,数据库,性能优化
1.
介绍
本参赛队(中科大星辰队)面向Query进行优化选型。通过对openLooKeng的SQL执行流程以及Query的实际特点进行分析,发现两个比较严重的性能瓶颈:
1、左深连接:
多表连接(左深连接)的Query在运行中会出现中间临时数据量相比最终输出数据量过大的现象,其将会带来巨大的计算开销;
2、临时中间表:
openLooKeng将with子句定义的临时中间表内联进主查询中,在with子句被多次调用的情况下,多次创建临时中间表导致重复计算,产生严重的计算开销。
我们最终设计并实现两个优化方案:
1、设计启发式重排算法,优化左深树的计算结构;
2、预处理SQL查询,避免临时中间表的重复计算。
2.
背景知识
openLooKeng是一个开源的分布式 SQL 查询引擎,针对低延迟的临时数据分析进行了优化。它支持 ANSI SQL 标准,包括复杂查询、聚合、连接和窗口函数,支持跨源查询[1][3]。
2.1 比赛描述
本次比赛使用TPC-DS数据集,要求基于openLooKeng社区所提供的比赛分支,进行openLooKeng的代码优化,以提升openLooKeng对接hive数据源(文件使用ORC格式)的执行效率。评测标准为比赛主办方提供的benchmark工具集中SQL运行时间累计(共99个SQL Query)。
2.2 面向Query优化选型
本次比赛的评测标准为给定测试集运行总时间,因此本参赛队主要针对耗时长的Query进行细粒度性能分析,寻找瓶颈从而进行优化方案设计。我们选择了基准测试下耗时超过100秒的Query(图1)进行性能分析及优化选型。
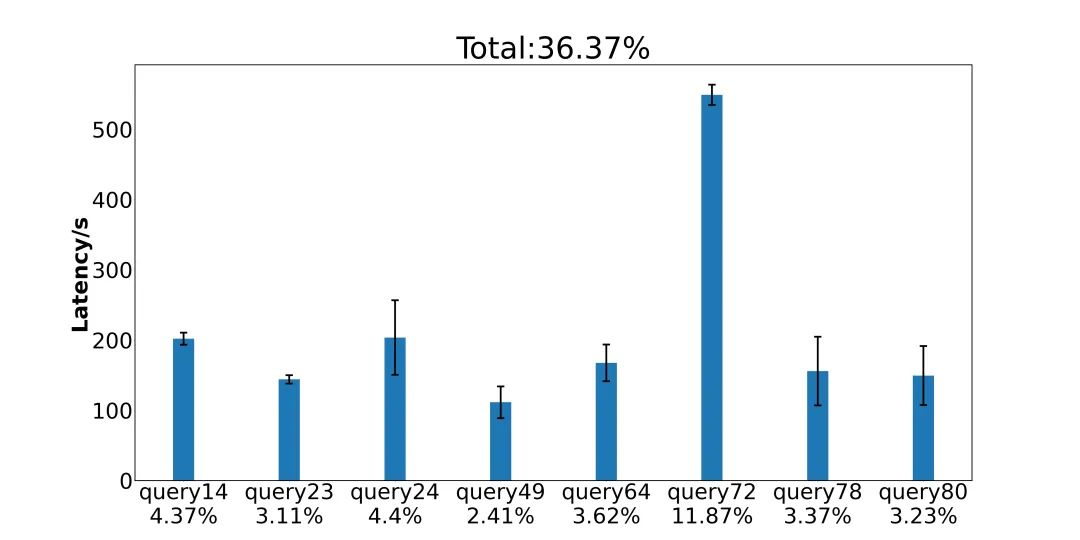
▲ 图1:给定测试集耗时超过100秒的Query(时间占比)
2.3 优化选型
通过细粒度性能分析,我们发现openLooKeng在运行时存在的两个比较严重的性能瓶颈:1.左深连接, 2.临时中间表。
2.3.1 左深连接
左深树,即所有的连接操作都发生在基关系之间的深树[4]。左深树(left-deep tree) 的特点是每个连接操作与一个关系作为另一个连接操作的输入时,该连接操作永远在左边(根结点除外)。在对其余的Query进行分析之后发现:提供的测试集中大部分Query都存在这样的计算结构。
左深连接树的问题在于连接操作之间存在数据相关,不合理的连接顺序会导致中间数据流量急速膨胀。因此,左深连接树的计算顺序会是影响Query运行的一个瓶颈。
以Query72为例:Query72涉及10张表的联表查询,而openLooKeng选择保留其原有连接计算顺序,这样带来的后果就是其中部分连接操作吞吐量过大:如图2所示,中间数据量最高可达215GB,而实际最终吞吐量仅为6.88MB,其中包含大量远超实际需求的计算开销。
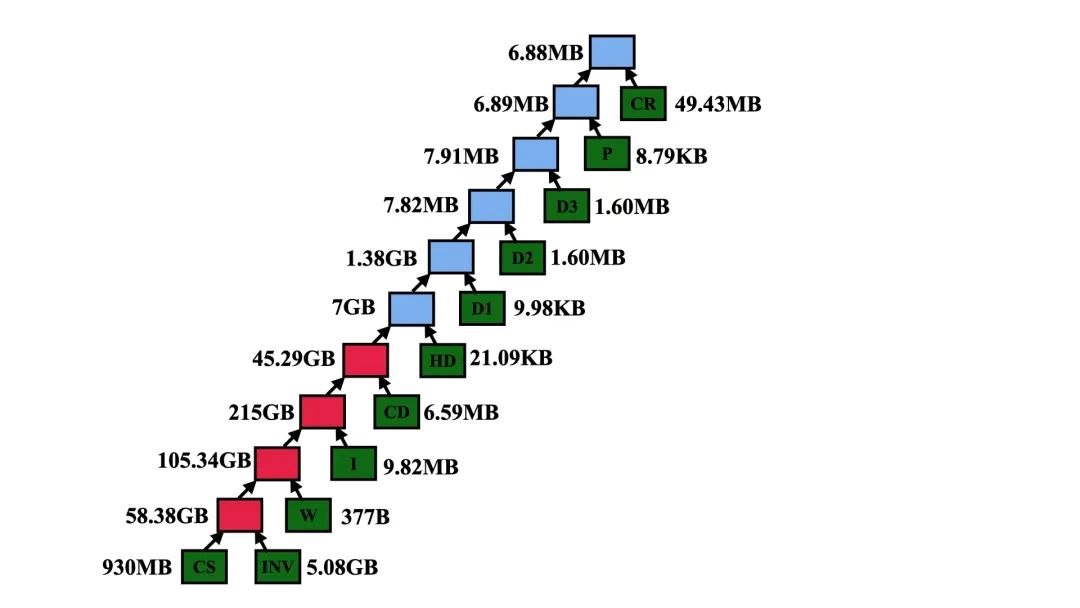
▲ 图2:Query72的连接操作结构吞吐量展示图
2.3.2 临时中间表
对于如14,24,64等存在由with子句创建的临时中间表的Query, openLooKeng处理with子句的方式仅仅是将with子句创建临时中间表的计算内联进主查询之中(如图3),这样对于性能也会有一定的影响:如果临时中间表的生成需要非常大的开销,多次的中间表生成会产生不可容忍的重复计算开销和读取开销,从而导致openLooKeng的性能受到较大的影响。
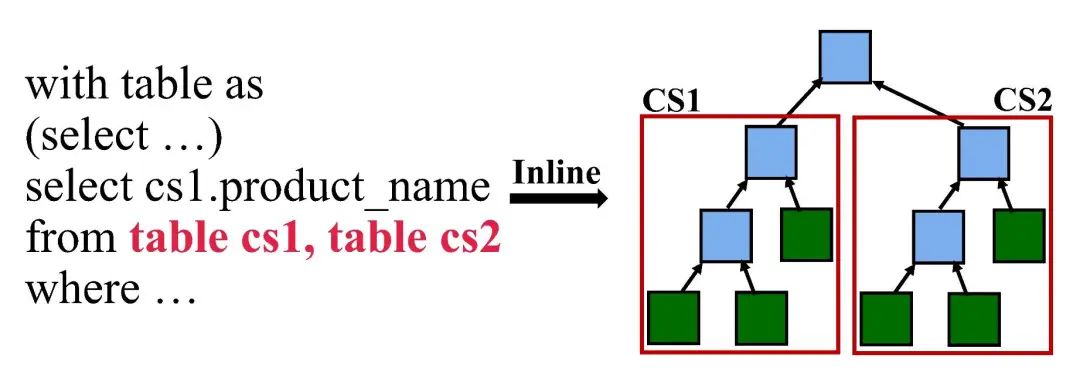
▲ 图3:openLooKeng将临时中间表内联进主查询
3.
方案设计
根据上述分析结果进行优化选型,我们最终针对左深树以及临时中间表这两个性能瓶颈设计了优化方案。
3.1 左深树重排
对于查询来说,连接重排是一个非常常见的优化方案,充分利用内/外连接的可交换性,重排可以减少整体连接计算操作的开销。本次优化就考虑对左深连接树这样的计算结构进行连接重排。
3.1.1 代价模型
openLooKeng本身自带一个基于穷举的连接重排优化器,但是openLooKeng中的代价模型不够完善,无法获得连接操作的开销估计,在测试集中重排失效。因此我们设计并实现了一个基于表的大小和连接谓词的左深树重排的贪心算法。
3.1.2 重排算法
在实际的查询中,连接操作的谓词主要存在于事实表(规模大)和维度表(规模小)之间,因此我们需要选择一张能够使得吞吐量稳定或持续减少的表作为左深连接序列的第一张表。
选取第一张表
我们提出两种方法来选取第一张表:
1、选取输出属性最多的表;
2、选取参与连接次数最多的表。
第二种方法更精确但是选取带来的计算开销大,第一种方法粗略但无额外开销。因此对于高度较高的左深树,采用第一种方法选取以减少额外的计算开销,而对于高度较低的左深树,采用第二种方法以获得更优的重排序列。
获得连接序列
左深树的前序遍历序列即我们所需要的连接序列。在获得第一张表之后,每一轮对剩余表进行选择:期望让每一次连接后的吞吐量较小,故优先选择与之前所有已选择的表序列之间存在连接谓词的数据表,其次按表的大小顺序选择,这样的策略可以减少连接时数据吞吐量的膨胀。
左/右连接
除此之外,在保证重排后涉及左右连接的表保持与之前相同的偏序关系的基础上,我们的连接重排支持不可交换的左连接和右连接,以保证可减少吞吐量的左连接及右连接能够优先计算。搜索空间相比原本的穷举算法有较大提升。
3.1.3 左深树推广
在实际的查询中,除了整体符合左深连接树结构的联表查询外,对于联机视图,其虽然整体不符合左深连接树结构,但其子树部分却符合左深连接树结构要求,我们称之为左深连接子树。我们将我们的算法从左深连接树推广到左深连接子树,从而覆盖了大部分的测试Query。
3.2 中间表复用
openLooKeng提供了一个以内存作为数据源的connector[2]。如图4所示,我们使用其来存储with子句建立的临时中间表。这样可以避免由于with子句内联的策略导致的重复计算与读取。
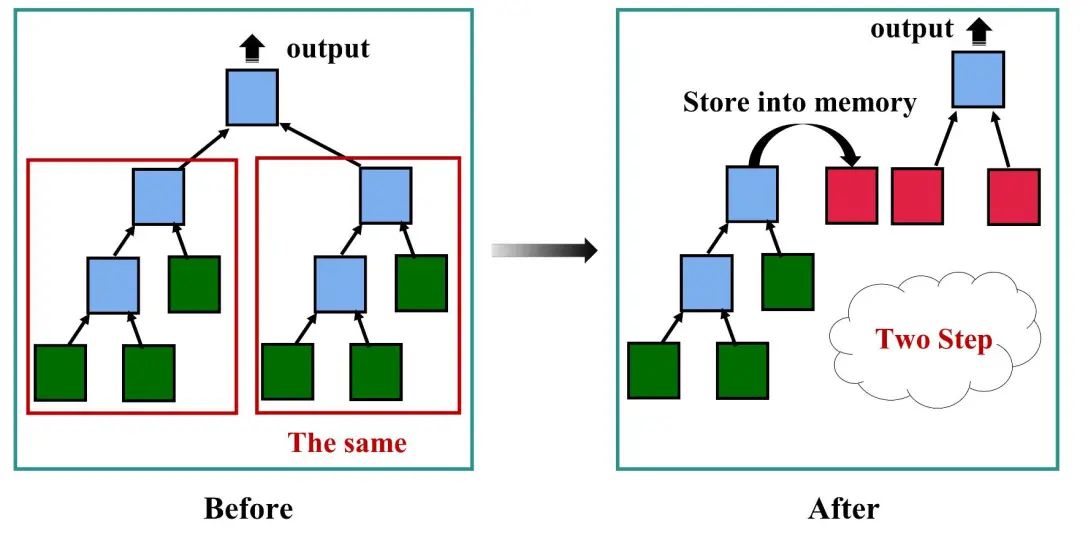
▲ 图4:用memory connector暂存临时中间表
3.2.1 中间表复用策略
扫描一个Query文件内的所有的with子句,在AST层面分别判断每个临时中间表被调用的次数,对于被调用次数大于1的临时中间表采用预处理的方式在内存中保存临时中间表的结果。对于重复定义的临时中间表,我们通过预处理将其进行合并消除冗余。
3.2.2 预处理实现
对文件输入的SQL语句进行预处理,如图5所示将with as形式等价变换成使用内存数据源connector的create table as形式,并在SQL语句结束处对创建出的临时中间表进行drop操作。
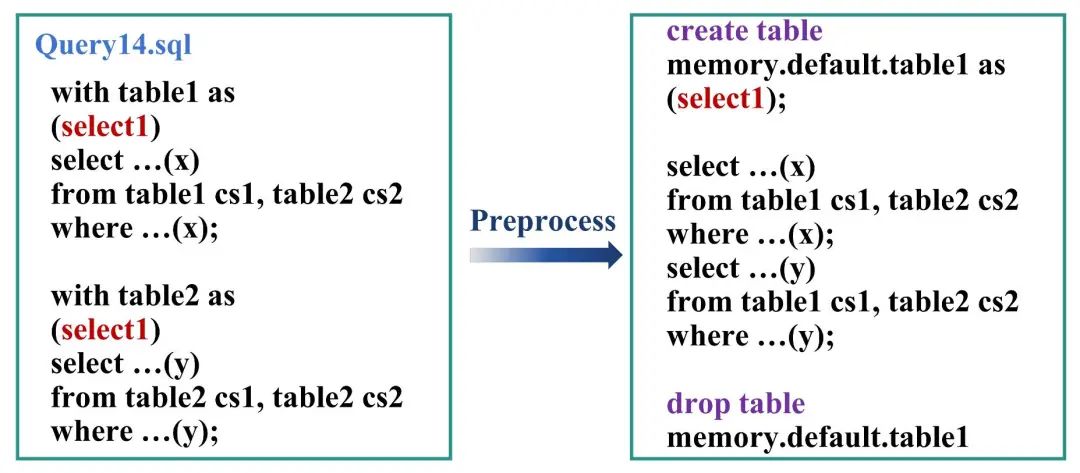
▲ 图5:Query14.SQL预处理示例
3.2.3 中间表复用局限
openLooKeng的内存数据源有存储数据量的限制,经过测试,比赛测试集中99个query的with子句产生的临时中间表的大小均在2GB以下。设置2GB的内存数据源的限制可以在不影响总体性能的情况下让复用取得较好的结果。
4.
结果评测
本文实验结果均来自本队伍所在实验室服务器集群上,实验环境为单节点,所使用CPU为Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz,数据集采用比赛提供的TPC-DS数据集,存放在ST1000NM0023硬盘下,其接口类型为SAS,带宽6Gbps。所使用的测试集为比赛提供测试集。
4.1 重排效果分析
重排后的部分Query的性能结果如图6所示。可以看到,对于优化目标左深树中最典型的例子Query72,其运行耗时从原来的530秒下降到了现在的40秒,性能提高了12倍。
除此之外,比如Query17、24原来的性能测试结果有着非常大的波动,在使用了重排之后波动降低了很多,分析认为在减少了计算开销之后,读取数据源的任务被阻塞的可能性变小了,从数据源读取数据的耗时就变得稳定了。
测试集中,一共有2%的Query优化了2倍以上,6%优化了1.5倍到2倍,8%优化了1.2倍到1.5倍,11%优化了1.05倍到1.2倍,其余73%均只有5%上下的波动,没有存在负优化。
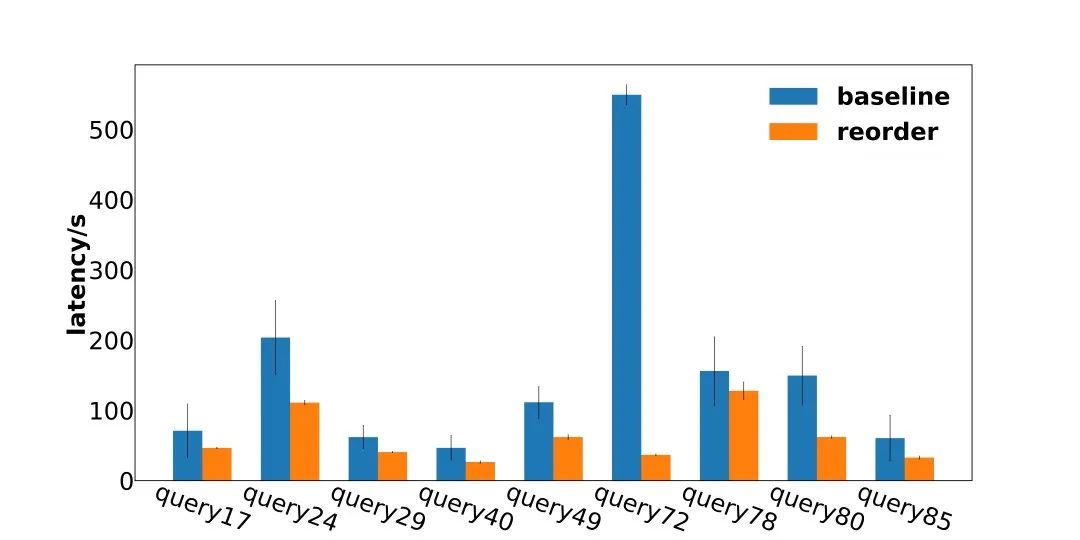
▲ 图6:重排结果展示(部分)
4.2 复用效果分析
在重排的基础上加上了复用之后的效果如图7,可以看到对于Query2和24来说,性能提升到了原来的5倍左右。
测试集中,有7%的Query优化2倍以上,有12%优化了1.5-2倍,9%优化了1.2-1.5倍,8%优化了1.05-1.2倍,其余无明显优化。
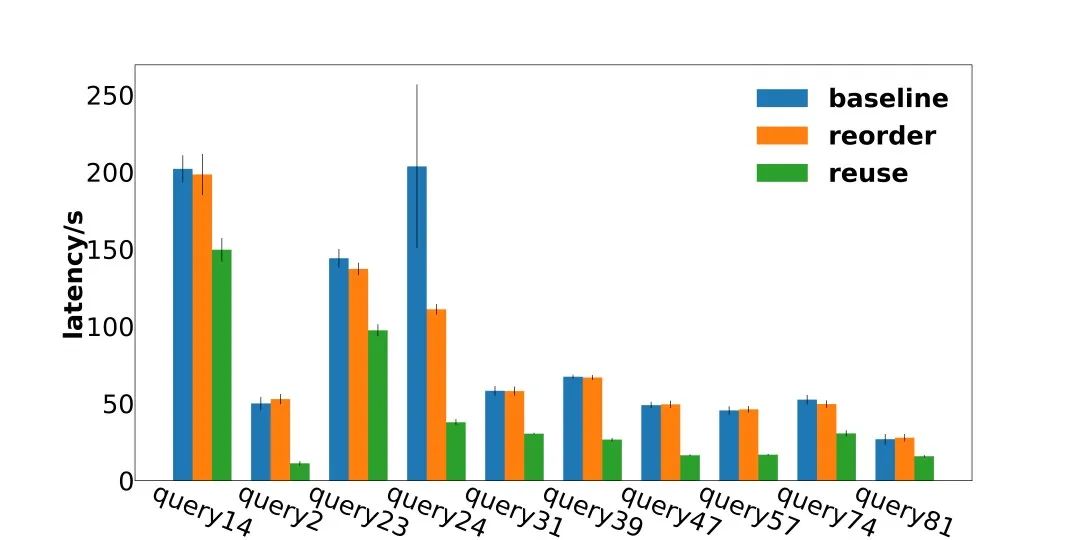
▲ 图7:复用结果展示(部分)
4.3 最终结果
如图8所示,这是99个query总和的优化效果展示,可以看到最终优化效果达到了近30%。
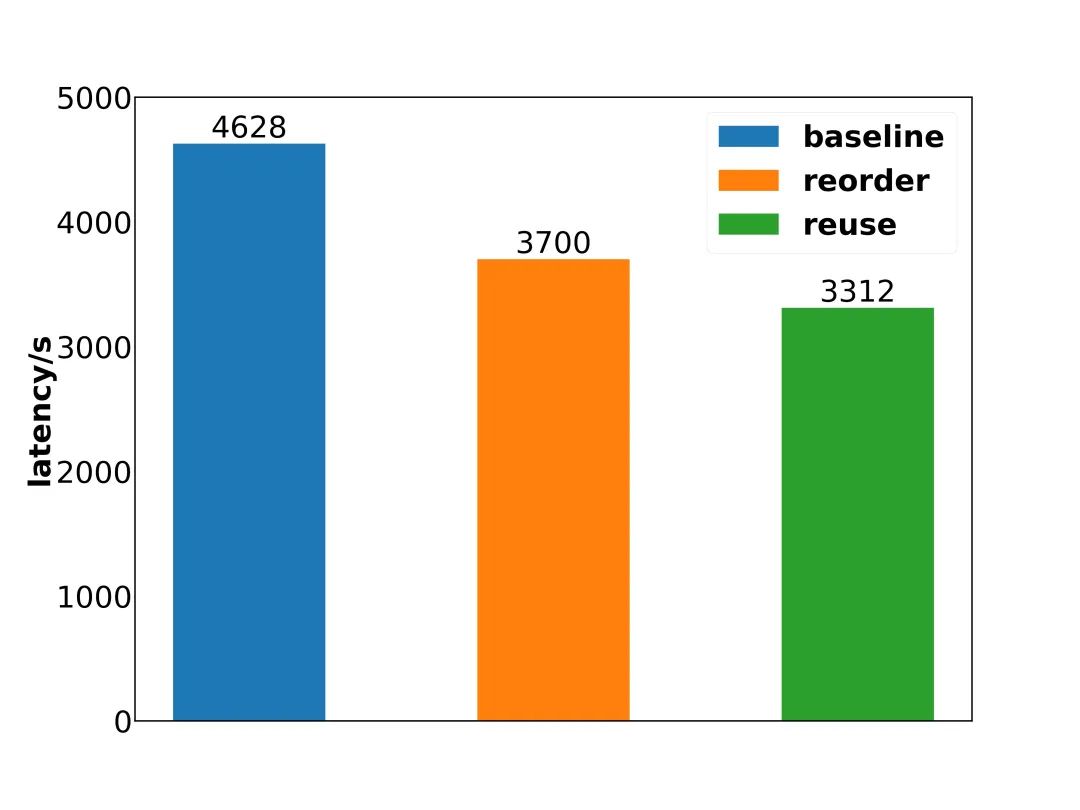
▲ 图8:最终结果
感谢指导老师李诚老师在比赛之中的指导和帮助,感谢中科大ADSL实验室在比赛中提供服务器测试集群。
[1] openLooKeng官方文档,openLooKeng概念,
https://openlookeng.io/zh-cn/docs/docs/overview/concepts.html/
[2] openLooKeng官方文档,内存连接器
https://openlookeng.io/zh-cn/docs/docs/connector/memory.html
[3] R. Sethi, M. Traverso, D. Sundstrom, D. Phillips, W. Xie, Y. Sun, N. Yigitbasi, H. Jin, E. Hwang, N. Shingte, and C. Berner. Presto: SQL on everything. In IEEE 35th Int. Conf. on Data Eng. (ICDE), pages 1802--1813, 2019.
[4] IOANNIDIS,Y.AND KANG, Y. 1991. Left-deep vs. bushy trees: an analysis of strategy spaces and its implications for query optimization. In Proceedings of the ACM SIGMOD Conference on Management of Data (Denver, CO, May), 168- 177.]]
openLooKeng,Big Data Simplified
以上便是「中科大星辰队」带来的分享
恭喜并感谢这支极具青春活力的可爱队伍
愿你们在追梦路上不断前行,不负青春
期待下次再见


如果你觉得开源很酷,欢迎加入我们社区,与志趣相投的朋友一起做点有意思的事儿!
https://openlookeng.io
https://gitee.com/openlookeng
https://github.com/openlookeng

喜欢本文就点个“赞”和“在看”吧 

