




背景
正常使用将近两年的docker 环境出现异常,具体体现: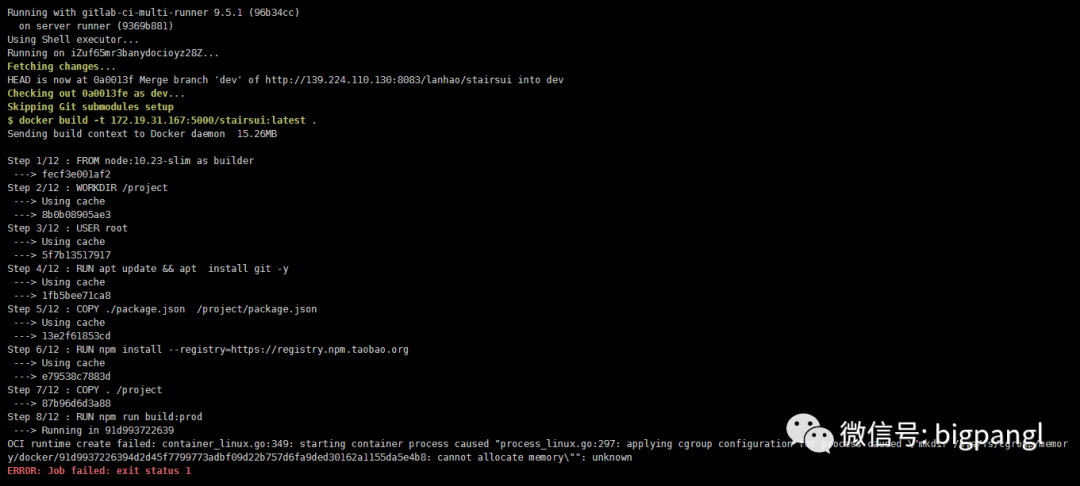
排查
从错误的提示分析,推测关键词是:cgroup、mkdir XXX : cannot allocate momory
将关键词进行搜索,确实查到了很多相似(几乎一样)的现象,以及解决思路。
发生这个问题的大概原因:
docker 默认使用 cgroup 的 kmem accounting 特性
linux 内核4 以下的版本中,cgroup 的kmem accounting 特性存在BUG,无法有效的进行回收
容器频繁的创建关闭,将导致,cgroup 的可分配内存越来越少,直到最后耗尽
从原因反思我们的操作:
linux 内核判断
从购买阿里云 centos 7.8 以后,从未进行内核升级,内核版本保持在3.10+,满足cgroup 的kmem accounting 的BUG 环境
是否频繁的创建容器
因为使用了gitlab 的CI/CD ,必然会导致频繁创建(累计值),同时当容器运行异常(比如第三方服务崩溃时),会导致容器短期内频繁重启、关闭,加速耗尽cgroup 的可分配内存
如何解决
参考链接:
https://blog.csdn.net/qq_33317586/article/details/109285758
网上提供的方案有三种:
升级内核
操作有风险,需在准备充分的情况下进行
禁用cgroup的 kmem 特性
需要调整内核参数后重启
重新编译软件(k8s 或者docker 中的runc),不使用kmem 特性
风险较小,直接替换,基本无缝衔接
另外呢,也有另外一种小众操作:重启服务器。
因为从他的BUG 特性来说,是重启docker 服务无效,但是重启服务器应该是有效的。这大概也能解释,为何一直正常使用了快2年,才爆发这个问题——期间有重启过几次。
实际解决过程
首先是限制内核使用cgroup 的kmem 特性
# 修改/etc/default/grub 为:
GRUB_CMDLINE_LINUX=”** cgroup.memory=nokmem”
# 生成配置:
/usr/sbin/grub2-mkconfig -o /boot/grub2/grub.cfg
# 重启机器:
reboot
# 验证:
cat /sys/fs/cgroup/memory/kubepods/burstable/pod//memory.kmem.slabinfo 无输出即可。
此番操作,能够快速的让docker 集群重新回到正常状态。
简单的重启,和修改内核参数后重启,成本几乎一样,至于为何不选择方案三,更平稳的过度?因为目前所谓的集群环境,只有这一个节点,重新编译runc 将导致集群一段时间内不可用,并且这个时间将长于重启所花费的时间。
夜间升级linux内核,使其大于等于4
参考链接:
https://www.osyunwei.com/?p=11582
首先给系统盘做快照

用于预防内核升级失败时,及时、有效的回滚状态。预估在正确升级后,保存2-3天(视条件而定)升级系统
# 检查当前 CentOS 系统版本
cat /etc/redhat-release
#检查当前 CentOS 系统内核版本
uname -sr
yum clean all #清除缓存
yum makecache fast #重新建立缓存
yum update -y #升级系统
reboot #重启系统


重启后,通过 docker stats 观察是否有无容器不断创建的操作。同时检查主服务:mariadb 和gitlab。(此处出现mariadb 未自动重启,进行手动重启后,并再次设置开机自启。较大概率是因为系统升级时,对mariadb 升级了)
一切OK 后,再进行内核升级。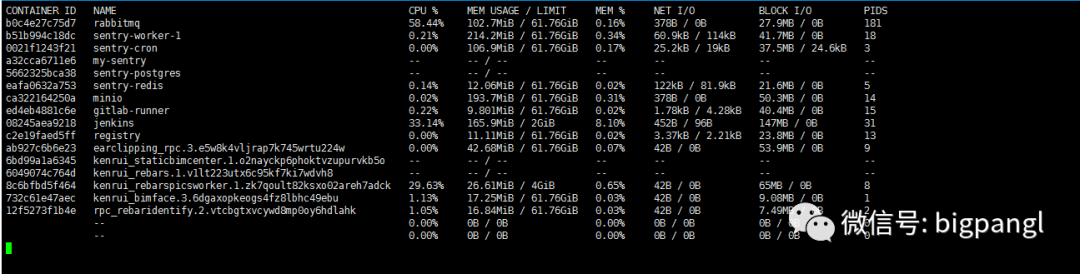
使用elrepo源升级内核
rpm —import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
cp /etc/yum.repos.d/elrepo.repo /etc/yum.repos.d/elrepo.repo.bak #备份文件
#查看最新版内核
yum —disablerepo=”*” —enablerepo=”elrepo-kernel” list available
#kernel-ml #主线版本,比较新
#kernel-lt #长期支持版本,比较旧
#安装新内核,这里安装主线版本
yum —enablerepo=elrepo-kernel install kernel-ml
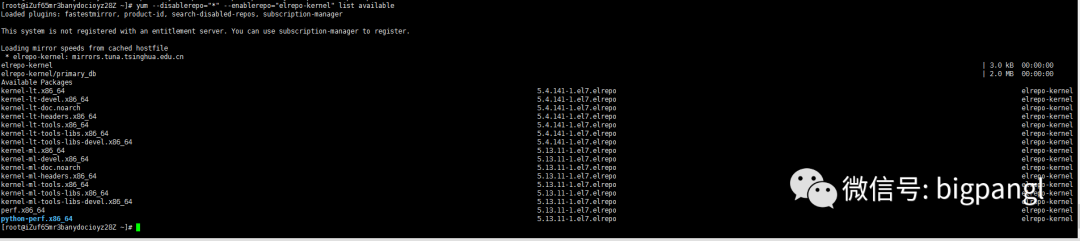
从实际的安装来看,ml
版本指向了版本号较小的5.13,参考链接中的主线版和长期支持版的说明应该是有出入的。
设置系统默认内核
# 查看系统上的所有可用内核
awk -F\’ ‘$1==”menuentry “ {print i++ “ : “ $2}’ /etc/grub2.cfg
# 设置默认内核为我们刚才升级的内核版本
cp /etc/default/grub /etc/default/grub-bak #备份
grub2-set-default 0 #设置默认内核版本
vi /etc/default/grub
GRUB_DEFAULT=saved修改为:
GRUB_DEFAULT=0
:wq! #保存退出
# 重新创建内核配置
grub2-mkconfig -o /boot/grub2/grub.cfg
# 查看默认内核
grubby —default-kernel
grub2-editenv list
yum makecache #更新软件包
reboot #重启,现在系统默认内核已经是我们刚才升级后的最新版本




重启后,检测mariadb,gitlab 相关服务,以及通过 docker stats查看容器是否频繁创建。
恢复linux 的kmem 特性
逆操作1 进行恢复重启,并检查docker 状态,mariadb 和gitlab 状态。
总结
因为集群只有一个节点,所以快速让集群可用成了解决问题的第一指标。
其次,重启(或者修改kmem 特性后重启)只是一个临时采用的方案,是用于当时让集群可用的快速方案,但并不是我所想要的。更优的方案是重新编译docker 的runc 或者升级linux内核。
又因为本台服务器除了docker外,安装服务和应用比较少,所以本次直接选择了升级。如果安装服务很多,依赖很多(比如应用程序依赖于kmem或者3.X 的内核),应该选择重新编译runc,使其在软件层面选择不使用kmem 特性,以使得服务器保持相对稳定的环境。
