




Thanos,灭霸,Prometheus的sidecar好伴侣
英文原文:https://www.infoq.com/news/2018/06/thanos-scalable-prometheus/
The Improbable engineering team has open sourced Thanos, a set of components that adds high availability to Prometheus installations by cross-cluster federation, unlimited storage and global querying across clusters.
Improbable团队开源了Thanos,一组通过跨集群联合、跨集群无限存储和全局查询为Prometheus增加高可用性的组件。
Improbable, a British technology company that focuses on large-scale simulations in the cloud, has a large Prometheus deployment for monitoring their dozens of Kubernetes clusters. An out-of-the-box Prometheus setup had difficulty meeting their requirements around querying historical data, querying across distributed Prometheus servers in a single API call, and merging replicated data from multiple Prometheus HA setups.
Improbable部署了一个大型的Prometheus来监控他们的几十个Kubernetes集群。默认的Prometheus设置在查询历史数据、通过单个API调用进行跨分布式Prometheus服务器查询以及合并多个Prometheus数据方面存在困难。
Prometheus has existing high availability features - highly available alerts and federated deployments. In a federation, a global Prometheus server aggregates data across other Prometheus servers, potentially in multiple datacenters. Each server sees only a portion of the metrics. To handle more load per datacenter, multiple Prometheus servers can run in a single datacenter, with horizontal sharding. In a sharding setup, slave servers fetch subsets of the data and a master aggregates them. Querying a specific machine involves querying the specific slave that scraped its data. By default, Prometheus stores time series data for 15 days. To store data for unlimited periods, Prometheus has remote endpoints to write to another datastore along with its regular one. However, de-duplication of data is a problem with this approach. Other solutions like Cortex provide scalable long term storage when used as a remote write endpoint, and a compatible querying API.
高可用警报和联合部署是Prometheus现有的高可用特性。在联合部署中,全局Prometheus服务器可以在其他Prometheus服务器上聚合数据,这些服务区可能分布在多个数据中心。每台服务器只能看到一部分度量指标。为了处理每个数据中心的负载,可以在一个数据中心内运行多台Prometheus服务器,并进行水平分片。在分片设置中,从服务器获取数据的子集,并由主服务器对其进行聚合。在查询特定的服务器时,需要查询拼凑数据的特定从服务器。默认情况下,Prometheus存储15天的时间序列数据。为了无限期存储数据,Prometheus提供了一个远程端点,用于将数据写入另一个数据存储区。不过,在使用这种方法时,数据除重是个问题。其他解决方案(如Cortex)提供了一个远程写入端点和兼容的查询API,实现可伸缩的长期存储。
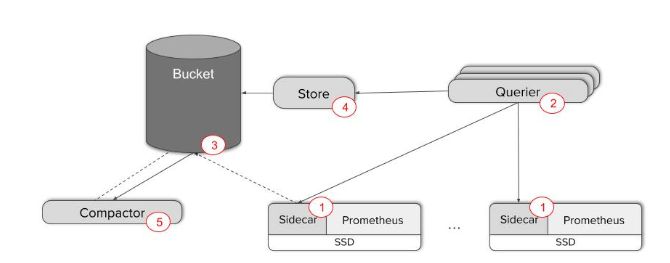
Thanos' architecture introduces a central query layer across all the servers via a sidecar component which sits alongside each Prometheus server, and a central Querier component that responds to PromQL queries. This makes up a Thanos deployment. Inter-component communication is via the memberlist gossip protocol. The Querier can scale horizontally since it is stateless and acts as an intelligent reverse proxy, passing on requests to the sidecars, aggregating their responses and evaluating the PromQL query against them.
Thanos在每一台Prometheus服务器上运行一个边车组件,并提供了一个用于处理PromQL查询的中央Querier组件,因而在所有服务器之间引入了一个中央查询层。这些组件构成了一个Thanos部署,并基于memberlist gossip协议实现组件间通信。Querier可以水平扩展,因为它是无状态的,并且可充当智能逆向代理,将请求转发给边车,汇总它们的响应,并对PromQL查询进行评估。
Thanos solves the storage retention problem by using an object storage as the backend. The sidecar StoreAPI component detects whenever Prometheus writes data to disk, and uploads them to object storage. The same Store component also functions as a retrieval proxy over the gossip protocol, letting the Querier component talk to it to fetch data.
Thanos通过使用后端的对象存储来解决数据保留问题。Prometheus在将数据写入磁盘时,边车的StoreAPI组件会检测到,并将数据上传到对象存储器中。Store组件还可以作为一个基于gossip协议的检索代理,让Querier组件与它进行通信以获取数据。
InfoQ got in touch with Bartłomiej Płotka, software engineer at Improbable, to learn more about how query execution happens in Thanos:
InfoQ采访了Improbable的软件工程师Bartłomiej Płotka,了解了更多关于Thanos如何执行查询的细节:
In Thanos, the query is always evaluated in a single place - in the root, which listens over HTTP for PromQL queries. The vanilla PromQL engine from Prometheus 2.2.1 is used to evaluate the query, which deduces what time series and for what time ranges we need to fetch the data. We use basic filtering (based on time ranges and external labels) to filter out StoreAPIs (leafs) that will not give us the desired data and then invoke the remaining ones. The results are then merged - append together time-wise - from different sources.
在Thanos中,查询的评估只在一个地方发生,也就是通过HTTP监听PromQL查询的地方。来自Prometheus 2.2.1的PromQL引擎用于评估查询,预测需要获取数据的时间序列和时间范围。我们使用基本的过滤器(基于时间范围和外部标签)过滤掉不会提供所需数据的StoreAPI(叶子),然后执行剩余的查询。然后将来自不同来源的数据按照时间顺序追加的方式合并在一起。
The Querier component can auto-switch between resolutions (e.g. 5 minutes, 1 hour, 24 hours) based on the user zooming in and out. How does Thanos identify which API servers have the data it needs in a query? Płotka explains:
Querier组件可以基于用户规模自动调整密度(例如5分钟、1小时或24小时)。Thanos如何确定哪些API服务器持有所需的数据?Płotka解释说:
StoreAPIs propagate external labels and the time range they have data for. So we can do basic filtering on this. However if you don't specify any of these in query (you just want all the "up" series) the querier concurrently asks all the StoreAPI servers. Also, there might be some duplication of results between sidecar and store data, which might not be easy to avoid.
StoreAPI会对外公布外部标签及其持有数据的时间范围,所以我们可以对此进行基本过滤。但是,如果没有在查询中指定这些条件,Querier就会同时查询所有的StoreAPI服务器。此外,边车和存储的数据之间可能会有重复的结果,这种情况可能不容易避免。
The StoreAPI component understands the Prometheus data format, so it can optimize the query execution plan and also cache specific indices of the blocks to respond fast enough to user queries. This absolves it from the need to cache huge amounts of data. In an HA Prometheus setup with Thanos sidecars, would there be issues with multiple sidecars attempting to upload the same data blocks to object storage? Płotka responded:
StoreAPI组件了解Prometheus的数据格式,因此它可以优化查询执行计划,并缓存数据块的特定索引,以对用户查询做出足够快的响应,避免了缓存大量数据的必要。在使用Thanos边车的Prometheus高可用设置中,是否会有多个边车试图将相同的数据块上传到对象存储的问题?Płotka回应道:
This is handled by having unique external labels for all Prometheus + sidecar instances (even HA replicas). To indicate that all replicas are storing same targets they differ only in one label. So for example:
我们通过为所有Prometheus+边车实例提供唯一的外部标签来解决这个问题。为了表明所有副本都存储相同的数据,它们只有标签是不一样的。例如:
First:
"cluster": "prod1"
"replica": "0"
Second:
"cluster":"prod1"
"replica": "1"
There is no problem with storing them since the label sets are unique. The query layer, however is capable of deduplicating by "replica" label, if specified, on the fly.
由于标签集是唯一的,所以不会有什么问题。不过,如果指定了副本,查询层可以在运行时通过“replica”标签进行除重操作。
图片来源: https://improbable.io/games/blog/thanos-prometheus-at-scale
Thanos also provides compaction and downsampled storage of time series data. Prometheus has an inbuilt compaction model where existing smaller data blocks are rewritten into larger ones, and restructured to improve query performance. Thanos utilizes the same mechanism in a Compactor component that runs as a batch job and compacts the object storage data. The Compactor downsamples the data too, and "the downsampling interval is not configurable at this point but we have chosen some sane intervals - 5m and 1h", says Płotka. Compaction is a common feature in other time series databases like InfluxDB and OpenTSDB.
Thanos还提供了时间序列数据的压缩和降采样(downsample)存储。Prometheus提供了一个内置的压缩模型,现有较小的数据块被重写为较大的数据块,并进行结构重组以提高查询性能。Thanos在Compactor组件(作为批次作业运行)中使用了相同的机制,并压缩对象存储数据。Płotka说,Compactor也对数据进行降采样,“目前降采样时间间隔不可配置,不过我们选择了一些合理的时间间隔——5分钟和1小时”。压缩也是其他时间序列数据库(如InfluxDB和OpenTSDB)的常见功能。
Thanos is written in Go, and is available on Github. Visualization tools like Grafana can use Thanos as-is with the existing Prometheus plugin since the API is the same.
Thanos采用Go开发,托管在Github上。我们可以继续在可视化工具(如Grafana)上使用Thanos,就像现有的Prometheus插件一样,因为API是相同的。

欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:
知识星球是 公众号 工匠人生 忠实读者私密进阶学习圈。这里会有很多超越公众号技术深度的架构原创实战经验,也有私密微信群,分享行业深度洞见,交流碰撞,沉淀优质内容。
【面试专题】昨晚面试过程中关于Maven依赖排除的问题和答案
【猪猪原创时间】车的哲学故事——远光灯和近光灯,当蛮横遇上谦和
微服务Dubbo全链路追踪,使用MDC和SPI生成全局TraceID
