




1.1 MVCC实现机制
提高并发
1. 插入很简单,就是将元组插入到页面的空闲空间中;
2. 删除则是将元组标记为旧版本,但是即使这个旧版本对所有事务都不可见了,这个元组占用的空间也不会归还给文件系统
3. UPDATE相当于DELETE + INSERT,等于是占用了两条元组的位置,类似DELETE,旧版本的元组依然占用着物理空间。
很明显,在一通增删改操作之后,页面上的旧版本元组势必是占有一定比重的。这就导致了物理文件大小明显高于实际的数据量
1.2 日常清理(vacuum)
vacuum主要作用 : 磁盘清理(清理dead tuple);更新统计信息;重组数据;解决事务ID
回卷问题。
语法结构
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
vacuum :不要求获得排它锁,找到那些旧的“死”数据,标记为不可用状态,不进行空间合并
vacuum full:就是除了vacuum,进行空间合并,它需要lock table
vacuum analyze:更新统计信息,使得优化器能够选择更好的方案执行sql
vacuum freeze: 表记录冻结,可解决事务id回卷的问题
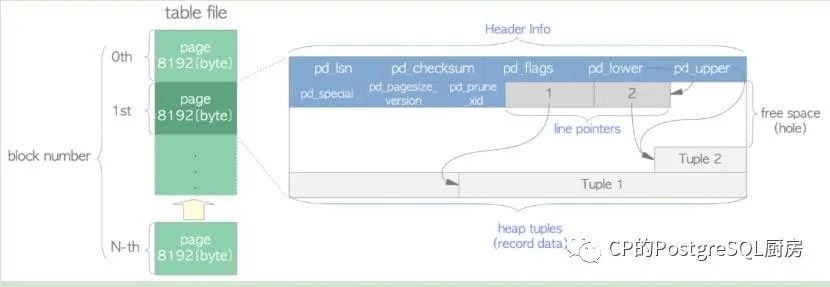
1.2.1 死元祖
vacuum

src/include/storage/itemid.h
typedef ItemIdData *ItemId;
/*
* lp_flags has these possible states. An UNUSED line pointer is available
* for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 未使用 /* unused (should always have lp_len=0) */
#define LP_NORMAL1 已使用/* used (should always have lp_len>0) */
#define LP_REDIRECT2HOT重定向/* HOT redirect (should have lp_len=0) */
#define LP_DEAD3死元祖/* dead, may or may not have storage */
1.2.2 更新统计信息
手工收集统计信息;
手工收集统计信息的命令是analyze命令;此命令收集表的统计信息;然后将结果保存在系统表pg_statistic中。autovacuum守护进程;能自动地分析表;并收集表的统计信息。
analyze的命令格式;
analyze [verbose] [table[(column[,..])]]
verbose;显示处理的进度;以及表的一些统计信息。
table;要分析的表名;如果不指定;则对整个数据库中的所有表作分析。
column;要分析的特定字段的名字默认是分析所有字段。
analyze命令会在表上加读锁。
对于大表;analyze只读取表的部分内容做一个随机抽样;不读取表的所有内容。统计信息只是近似的结果。为了调整所收集的统计信息的准确度;可以增大随机抽样比例;可通过参数default_statistics_target来实现;这个参数可以在session级别设置;可以在列级别设置。
set default_statistics_target to xxx;
alter table tab_name alter column col_name set statistics xxx;
analyze有一个统计项是估计出现在每列的不同值的数目。但因为仅仅抽样部分行;所以这个统计项的估计值有时候会很不准确;为了避免因这个错误导致差的查询计划;可以手工指定这个列有多少个唯一值;alter table tab_name alter column col_name set (n_distinct=xxx;
如果表是有继承关系的其他字表的父表;还可以设置n_distinct_inherited;这样子表会继续使用这个父表的设置值。
1.2.3 重组数据
Vacuum full 重组数据;

首次创建时 oid = relfilenode,relfilenode的值也等于数据文件的命名字。
数据文件超过1GB会创建出OID名.n的分支文件。
当对表或索引执行TRUNCATE、REINDEX、CLUSTER、
vacuum full relfilenode名称会变化。
即oid不等于relfilenode值了。文件被重建了。
1.2.4 事物ID回卷
解决事务ID回卷问题 ;
事务ID由32位数保存,而事务ID递增,当事务ID用完时,会出现事务id回卷问题。
通过VACUUM FREEZE来解决该问题
PostgreSQL有三个事务ID有特殊意义:
0代表invalid事务号 表示无效的事务id
1代表bootstrap事务号 表示系统表初始化时的事务id,比任何普通的事务id都旧。
2代表frozon事务 冻结的事务id,比任何普通的事务id都旧。
大于2的事务id都是普通的事务id,即从3开始就是普通的事务id。
说明:
frozon transaction id比任何事务都要老,可用的有效最小事务ID为3
VACUUM时将所有已提交的事务ID均设置为2,即frozon,之后所有的事务都比frozon事务新
因此VACUUM之前的所有已提交的数据都对之后的事务可见
PostgreSQL通过这种方式实现了事务ID的循环利用
Vacuum freeze
1. Xid是一个环,循环2的32次方循环复用。
2. 对于某一个xid来说, 左半边为过去,右半边为未来。
3. 一个事务只能看到他过去的内容看不到未来
4. 事物回卷
5. Xid=2为特殊事物id,他比所有事物id都要旧。
6. 冻结时将元组的t_infomask字段中的xmin_frozen标记来标识冻结
7. t_xmin修改值为2为标识。

1.2.5 autovacuum优化
http://postgres.cn/docs/12/runtime-config-autovacuum.html
1.autovacuum
什么时候会触发autovacuum
1、当update,delete的tuples数量超过 autovacuum_vacuum_scale_factor * table_size + autovacuum_vacuum_threshold
2、指定表上事务的最大年龄配置参数autovacuum_freeze_max_age,默认为2亿,达到这个阀值将触发 autovacuum进程,从而避免 wraparound 事务回卷。
每个表dead tuples的数量(包括用户表和系统表)
pg_stat_all_tables.n_dead_tup 死亡行得到估计数量
# dead/live tuples在每个表中的比率
(n_dead_tup 死亡行得到估计数量/ n_live_tup 活着的行的估计数量)
# 每一行的空间
(pg_class.relpages / pg_class.reltuples)
relpages
该表磁盘表示的尺寸,以页面计(页面尺寸为BLCKSZ)。这只是一个由规划器使用的估计值。它被VACUUM、ANALYZE以及一些DDL命令(如CREATE INDEX)所更新。
reltuples
表中的存活行数。这只是一个由规划器使用的估计值。它被VACUUM、ANALYZE以及一些DDL命令(如CREATE INDEX)所更新。
其中两个参数分别为:
autovacuum_vacuum_threshold = 50 #阈值
autovacuum_vacuum_scale_factor = 0.2 #比例因子
死亡元组数可以认为是pg_stat_all_tables中n_dead_tup的值
由以上公式可以看出,一般在dead tuple达到20%时,会进行自动清理,50行的阈值是为了防止非常频 繁地清理微小的表。这个默认的比例比较适用于中小表,但如果表较大时,比如10GB大小的表,dead tuple达到2GB时才清理,这在清理的过程中会严重影响性能,一般来说解决方案有两种:
一是调小大表的比例因子
二是放弃比例因子,调大阈值
要注意在postgresql.conf中修改这些参数会产生全局影响,尤其调大阈值或调小比例因子会影响小表的清理,不过综合全局来看,可以忽略一些小表的清理问题。
比较理想的方案
在postgresql.conf中忽略比例因子,设置较大的阈值(例如设置autovacuum_vacuum_scale_factor = 0和autovacuum_vacuum_threshold = 10000),然后根据各个表的delete和update频繁程度以及表的数据量单独为每个表设置阈值:
ALTER TABLE test SET (autovacuum_vacuum_threshold = 100);
触发autovacuum的消耗
autovacuum的清理过程是从数据文件中读取页面(默认8kB数据块),并检查它是否需要清理,如果没有死亡元组,页面就会被丢弃而不做任何更改,否则它被清理(死元组被删除),被标记为“脏页”并最终写出来。成本核算基于postgresql.conf定义三个参数:
vacuum_cost_page_hit = 1 #如果页面是从shared_buffers读取的,则计为1
vacuum_cost_page_miss = 10 #如果在shared_buffers找不到并且需要从操作系统中读取,
则计为10(它 可能仍然从RAM提供,但我们不知道)
vacuum_cost_page_dirty = 20 #当清理修改一个之前干净的块时需要花费的估计代价,它表示
再次把脏块刷 出到磁盘所需要的额外I/O,默认值为20
再加上另外两个参数即可计算出清理操作的成本:
autovacuum_vacuum_cost_delay = 20ms #每次完成清理后睡眠20ms
autovacuum_vacuum_cost_limit = 200 #完成一次清理的消耗限制
比如:延迟20ms,则每秒可以清理50轮,乘以200后,即为10000的成本,那么:
shared_buffers读取是 10000/1*8KB = 80MB/s
os中读取是 10000/10*8KB = 8MB/s
vacuum写入是 10000/20*8KB = 4MB/s
可以根据硬件的配置,以及autovacuum主要是顺序读写的情况增加autovacuum_vacuum_cost_limit
参数,比如增加到1000或2000,这会使吞吐量增加5倍或10倍。当然可以调整其他参数(每页操作成本,睡眠延迟),一般来说这几个参数默认足够,如果有明显autocuum问题时,再酌情修改。
Autovaccum 相关参数
autovacuum (boolean)
autovacuum参数控制 autovacuum 进程是否打开,默认为 “on”
log_autovacuum_min_duration(integer)
这个参数用来记录 autovacuum 的执行时间,当 autovaccum 的执行时间超过 log_autovacuum_min_duration 参数设置时,则autovacuum信息记录到日志里,默认为 “-1”, 表示不记录。
autovacuum_max_workers (integer)
指定同时运行的 最大的 autovacuum 进程,默认为3个。
autovacuum_naptime (integer)
指定 autovacuum 进程运行的最小间隔,默认为 1 min。也就是说当前一个 autovacuum 进程运行完成后,第二个 autovacuum 进程至少在一分钟后才会运行。
autovacuum_vacuum_threshold (integer)
autovacuum 进程进行vacuum 操作的阀值条件一,(指修改,删除的记录数。)
autovacuum_analyze_threshold (integer)
autovacuum 进程进行 analyze 操作的阀值条件一,(指插入,修改,删除的记录数。)
autovacuum_vacuum_scale_factor (floating point) autovacuum因子, autovacuum 进程进行 vacuum 操作的阀值条件二,,默认为 0.2 ,autovacuum进程进行 vacuum 触发条件表上(update,delte 记录) >= autovacuum_vacuum_scale_factor* reltuples(表上记录数) + autovacuum_vacuum_threshold
autovacuum_analyze_scale_factor (floating point) autoanalyze 因子,autovacuum 进程进行 analyze 操作的阀值条件二,,默认为 0.1 autovacuum进程进行 analyze 触发条件
表上(insert,update,delte 记录) >= autovacuum_analyze_scale_factor* reltuples(表上记录数) +
autovacuum_analyze_threshold
autovacuum_freeze_max_age (integer)
指定表上事务的最大年龄,默认为2亿,达到这个阀值将触发 autovacuum进程,从而避免 wraparound。表上的事务年龄可以通过 pg_class.relfrozenxid 查询。
例如,查询表 test_1 的事务年龄
skytf=> select relname,age(relfrozenxid) from pg_class where relname='test_1';
relname | age
---------+----------
test_1 | 14208876
(1 row)
autovacuum_vacuum_cost_delay (integer)
当autovacuum进程即将执行时,对 vacuum 执行 cost 进行评估,如果超过 autovacuum_vacuum_cost_limit设置值时,则延迟,这个延迟的时间即为 autovacuum_vacuum_cost_delay。如果值为 -1, 表示使用
vacuum_cost_delay 值,默认值为 20 ms
autovacuum_vacuum_cost_limit (integer)
这个值为 autovacuum 进程的评估阀值, 默认为 -1, 表示使用 “vacuum_cost_limit “ 值,如果在执行
autovacuum 进程期间评估的 cost 超过 autovacuum_vacuum_cost_limit, 则 autovacuum 进程则会休眠。
# 默认为on,表示是否开起autovacuum。默认开起。特别的,当需要冻结xid时,尽管此值为off,PG也会进行vacuum。
autovacuum=on
# 两次vacuum间隔时间,默认10min。这个naptime会被vacuum launcher分配到每个DB上。autovacuum_naptime/num of db。
autovacuum_naptime=1min
# 在规定时长内未完成的vacuum予以记录日志,单位ms,当vacuum动作超过此值时。"-1"表示不记录。"0"表示每次都记录。
log_autovacuum_min_duration=500
# 默认值是3。autovacuum最大线程数,CPU核多,并且IO好的情况下,可多点
autovacuum_max_workers=3
# 每个worker可使用的最大内存数。
autovacuum_work_mem=64MB
# 当update,delete的tuples数量超过 autovacuum_vacuum_scale_factor * table_size + autovacuum_vacuum_threshold 时,进行vacuum。如果要使vacuum清理频繁,则将以下两个参数改小。
# 清理阀值,与autovacuum_vacuum_scale_factor配合使用,默认50。
autovacuum_vacuum_threshold=50
# 清理的缩放系数,默认值为0.2。
autovacuum_vacuum_scale_factor=0.2
# 以下两个参数控制analyze运行,和上面的两个参数配置类似。
#当update,insert,delete的tuples数量超过 autovacuum_analyze_scale_factor * table_size + autovacuum_analyze_threshold时,进行analyze。
# analyze阀值,与autovacuum_analyze_scale_factor配合使用,默认50。
autovacuum_analyze_threshold=50
# analyze的缩放系数,默认值为0.1。
autovacuum_analyze_scale_factor=0.1
# 设置需要强制对数据库进行清理的XID上限值。
autovacuum_freeze_max_age=200000000
autovacuum_multixact_freeze_max_age=400000000
# 运行一次vacuum的时长,如果超过此值则休眠然后起来接着vacuum(vacuum很好I/O),如果为-1,取vacuum_cost_delay值。
autovacuum_vacuum_cost_delay=20ms
# 这个值是所有worker的累加值,如果为-1,取vacuum_cost_limit的值
autovacuum_vacuum_cost_limit=200
1.3 重建索引(REINDEX)
Postgresql重建索引是通过REINDEX命令来实现的
语法:
REINDEX { INDEX | TABLE | DATABASE | SYSTEM } name [ FORCE ];
注释:
INDEX 重构指定的索引;
TABLE 重构指定表的所有索引,包括下级TOAST表;
DATABASE重构指定数据库的所有索引,系统共享索引也会被执行。
SYSTEM 重构这个系统的索引包含当前的数据库。
Name 按照不同级别索引的名称。
FORCE 已经被废除即使写了也是被忽略的。
DATABASE重构指定数据库的所有索引需要注意的是这个级别的重构不能再一个事务块中执行。
SYSTEM 重构这个系统的索引包含当前的数据库。共享系统中的索引页是被包含的,但是用户自己的表是不处理的,同样也不能在一个事务块中执行。
1.3.1 重建索引注意事项
重建索引不同的级别的重构需要不同的权限,比如table那么就需要有这个表的权限即需要有操作索引的权限,如超级用户postgres拥有这个权限。
重构索引的目的是为了当索引的数据不可信时,即对于成本的计算会出现偏差较大,无益于优化器得到最优的执行计划以至于性能优化失败。
重构索引类似于先删除所有再创建一个索引,但是索引的条目是重新开始的。重构时当前索引是不能写的,因为此时有排他锁。
在8,1版本之前REINDEX DATABASE 只包含系统索引,并不是期望的所有指定数据库的索引。7.4版本之前REINDEX TABLE不会自动执行下级TOAST tables。
1.3.2 重建索引的原因
当由于软件bug或者硬件原因导致的索引不可用;
当索引包含许多空的或者近似于空的页,这个在b-tree索引会发生;
数据库系统修改了存储参数,需要重建不然就会失效(如修改fillfactor参数);
创建并发索引时失败,遗留了一个失效的索引
表和索引使用查看
查看数据表和索引所占用的磁盘页面
通过系统表pg_class查看相关字段
relpages只能被VACUUM、ANALYZE和几个DDL命令更新,如CREATE INDEX
通常一个页面的长度为8K字节
postgres=# SELECT relname,relfilenode, relpages FROM pg_class WHERE relname = 't' or relname = 't_n';
relname | relfilenode | relpages
---------+-------------+----------
t | 41189 | 541
t_n | 41195 | 505
(2 rows)
查看数据表和索引“死记录”信息统计
通过统计信息表pg_stat_all_tables查看
依赖于统计信息的更新操作, 譬如系统自动定时执行 vacuum analyze relname.
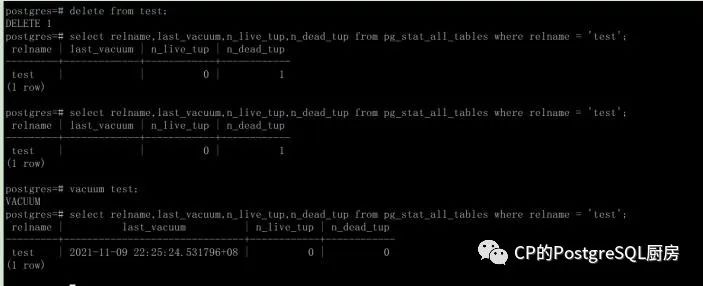
select relname,last_vacuum,n_live_tup,n_dead_tup from pg_stat_all_tables where relname = 't';
relname | last_vacuum | n_live_tup | n_dead_tup
---------+-------------+------------+------------
t | | 100000 | 0PostgreSQL学习随笔8 MVCC、vacuum、REINDEX
(1 row)
PostgreSQL的contrib模块可以提供额外的硬盘使用信息
pgstattuple:
这个模块包含可获得常规行元组数据和索引页面的详细分析的功能
提供了pgstatetuple()和pgstatindex()两个统计表和索引的方法
比较系统表pg_class的表统计信息,这个模块还统计了表中的dead tuples
表未分析前,使用 函数就能精确查询表的 page 数据,而此时 pg_class 还没数据,说明 pg_relpages 查询了表的 page 物理文件信息。
pg_freespacemap:
包含表或索引中的每个页面和对应的空闲空间映射(FSM)的内容
1.4 运行日志配置
运行日志路径默认在目录$PGDATA/log下
日志配置参数文件
logging_collector --是否开启日志收集开关,默认off,开启要重启DB
log_destination --日志记录类型,默认是stderr,只记录错误输出
log_directory --日志路径,默认是$PGDATA/pg_log
log_filename --日志名称,默认是postgresql-%Y-%m-%d_%H%M%S.log
log_connections --用户session登陆时是否写入日志,默认off
log_disconnections --用户session退出时是否写入日志,默认off
log_rotation_age --保留单个文件的最大时长,默认是1d,也有1h,1min,1s
log_rotation_size --保留单个文件的最大尺寸,默认是10MB
ulog_line_prefix = ‘%m %p %u %d %r ’
#日志输出格式
# %a = application name
# %u = user name
# %d = database name
# %r = remote host and port
# %h = remote host
# %p = process ID
# %t = timestamp without milliseconds
# %m = timestamp with milliseconds
# %i = command tag
log_statement 配置
1.用于记录用户登陆数据库后的各种操作,通过参数pg_statement来控制
2.默认的pg_statement参数值是none,即不记录
3.PG日志里分成了3类,可以设置ddl(记录create,drop和alter)、mod(记录ddl+insert,delete,update和truncate)和all(mod+select)
示例:
vi $PGDATA/postgresql.conf
log_statement = ddl
或者
alter system set log_statement = ddl;
select pg_reload_conf();
1.4.1 配置样例
log_destination = 'csvlog'
logging_collector = on
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_file_mode = 0600
log_truncate_on_rotation = on
当logging_collector被启用时,这个参数将导致PostgreSQL截断(覆盖而不是追加)任何已有的同名日志文件。不过,截断只在一个新文件由于基于时间的轮转被打开时发生,在服务器启动或基于尺寸的轮转时不会发生。如果被关闭,在所有情况下以前存在的文件将被追加。例如,使用这个设置和一个类似postgresql-%H.log的log_filename将导致产生 24 个每小时的日志文件,并且循环地覆盖它们。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
例子:要保留 7 天的日志,每天的一个日志文件被命令为server_log.Mon、server_log.Tue等等,并且自动用本周的日志覆盖上一周的日志。可以这样做:将log_filename设置为server_log.%a、将log_truncate_on_rotation设置为on并且将log_rotation_age设置为1440。
log_rotation_age = 1d
当logging_collector被启用时,这个参数决定使用一个单个日志文件的最大时间量,之后将创立一个新的日志文件。如果指定值时没有单位,则以分钟为单位。默认为24小时。将这个参数设置为零将禁用基于时间的新日志文件创建。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
log_rotation_size = 10MB
当logging_collector被启用时,这个参数决定一个个体日志文件的最大尺寸。当这些数据量被发送到一个日志文件后,将创建一个新的日志文件。如果指定值的时候没有单位,则以千字节为单位。默认值是10兆字节。设置为零时将禁用基于大小创建新的日志文件。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
