




今天是PGCONF 2021的第二天,我还是发一篇和PG相关的文章,算是凑个热闹吧。今天我们来一次比较有意义的炒冷饭,把以前很多人讨论过的shared buffers配置策略与double buffering的问题。在今天的分享中,我加入了一些我们最近研究的成果。正是因为PG和ORACLE在存储架构上的不同,形成了PG数据库目前double buffering的优化设计。
关于PG shared buffers的配置策略,在网上一直有很多不同的声音。PG的官方手册上建议shared buffers设置为1/4的物理内存,不用设置太大,让更多的内存可以被OS CACHE使用,通过double buffering机制来优化你的数据库IO,设置过大的shared buffers可能反而会导致数据库性能下降。不过我翻阅了medium、serverfault等IT论坛,以及一些PG大佬的博客,也有一些人说,他们的系统甚至使用了物理内存的80%作为shared buffers,获得了很好的效果,数据库的总体性能得到了极大的提升。
为什么会出现如此截然不同的观点呢?难道其中一种观点是错误的吗?以前我也写过一篇关于PG double buffering的文章,不过我感觉那时候仅仅从PG的shared buffers和OS CACHE出发,并没有考虑PG与Oracle截然不同的文件存储结构。因此并没有抓住问题最关键的那一点,通过这段时间的实践,我们终于把这两个概念联系到一起了,这两个知识点一串联,问题就清晰了,因此今天把这个问题拿出来再来讨论讨论。
首先无论是oracle的DB CACHE还是PG的shared buffers,其目的不外乎几个。第一,减少数据库服务器的物理IO,从而提升数据库的整体效率,减少物理IO的工作大部分可以由shared buffers来做;第二,缓冲数据,削峰填谷,和系统中所有环节上的CACHE一样,OS CACHE也可以削平OS上的大流量IO,从而让系统处于较为平稳的运行状态。
和数据库的缓冲区不同的是,OS CACHE是一种管理更为简单的,更为灵活的缓冲系统,不过文件缓冲对于数据块IO的减少,并不够专业。OS CACHE并不从数据库的角度去缓冲数据,而是通过预读等机制来优化文件系统的IO性能。而shared buffers是和数据库的一致性访问紧密相关的缓冲区,里面存储的都是数据库使用的数据块,对shared buffers的访问都必须通过lwlock来进行并发控制,其访问成本相对较高。因此,通过shared buffers和OS CACHE之间的访问量的平衡,可以更好的控制数据库访问数据的性能。
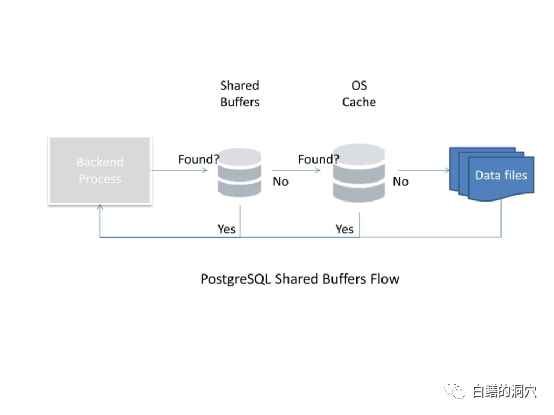
引用一张网络上的图片,当Backend要读取数据的时候,首先要通过lwlock去锁定相关的内存结构,然后对shared buffers进行一致性读取,如果找到了,那么就产生了一个逻辑读,这种情况我们在后面称之为方式1;如果没有找到,那么就会产生一个“逻辑物理读”操作,去操作系统中读取这个数据。这里我用了一个“逻辑物理读”这个十分别扭的词汇,是因为这个物理读有可能并没有产生真正的物理读,而只是从OS CACHE中读取到了这部分数据。这种情况我们在后面称之为方式2;如果在OS CACHE里还是没有找到,那么就要产生实际的物理读了,从数据文件中把数据块读入OS CACHE和shared buffers,这是方式3。
方式3是成本最高的,其次是方式2,访问成本最低的是方式1。因此无论是什么样的数据块系统,最好都通过方式1来获取数据。把shared buffers的命中率提高到最高,就能让绝大多数的访问都是使用方式1的。对于Oracle数据库来说,因为Oracle使用了表空间这种文件存储结构,文件空间的地址相对固定,因此只要DB CACHE的大小足够大,那么一个数据块被读取到DB CACHE中之后,会被更长时间的保存在DB CACHE里,被多次访问。表中新写入的数据或者UPDATE一条数据,也是尽可能先写入已经放在DB CACHE的块中,或者直接在DB CACHE中修改。
PG数据库的物理存储架构与Oracle大不相同,表数据是存储在独立文件中的,建立一张新的表,就会创建一个新的文件,修改一条数据,也不会在原来的记录上修改,而是会新产生一条记录,这条记录很可能会写在一个不同的块中。因此一个数据块存储到shared buffers中之后,很可能多次被访问的几率没有ORACLE高,这样shared buffers的效率就没有Oracle DB CACHE这么高了。因此,针对某些数据重用率不高的应用,shared buffers设置的太大,反而会挤占OS CACHE的容量,从而让数据库的整体性能变得更差。而实际上,如果我们的应用是能够很好的多次访问相同的数据的情况下,比如写入操作比较少,读操作比例比较高的数据库中,设置一个较大的shared buffers,让逻辑读的比例提高,肯定是能够获得较好的性能的。
如果你的数据库中已经安装了pg_buffercache插件,那么我们可以通过下面的语句来分析shared buffers中缓冲的效率。
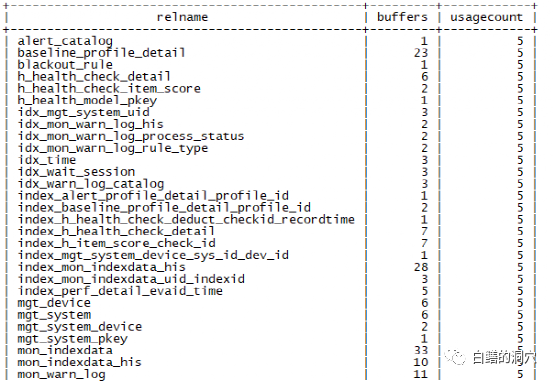
这个图的第二个列是某个关系在shared buffers中缓冲的块的数量,第三列是访问的计数器。从这个图来看,shared buffers中的数据的重复访问率并不高,这套系统如果使用较大的shared buffers可能效果不一定很好。
如果系统中存在一些较为复杂的查询语句,会反复查询某些热数据,那么,如果能把一些热数据的表和索引长期缓冲在shared buffers中,那么对PG数据库的性能提升就十分明显了。通过今天我们对double buffering的再理解,终于真正搞清楚了,为什么会有不同的专家,对shared buffers的设置的建议会如此迥然不同了。
最后划一下重点,总结一下今天这篇文章的主要观点。首先,PG的shared buffers和OS CACHE共同发挥作用,可以让PG数据库有效的减少物理IO,提升数据库的总体性能;其次,Shared buffers的设置并不是越大越好,shared buffers的命中率也没有ORACLE DB CACHE命中率那么有指向性,没有命中的PAGE也可能不需要物理读,可以直接从OS CACHE中读取到;第三,通过对应用系统的访问特性的分析,根据数据页在shared buffers中可能被多次访问的比例,以及这部分数据的大小,可以大致确定shared buffers的合理配置,同时根据应用的访问特性,可以大致确定OS CACHE与SHARED BUFFERS的比例;第四,根据服务器的IO能力和数据库的IO访问流量,通过调整OS层面的脏页写入策略参数和PG数据库的CHECKPOINT相关参数,可以获得一个较匹配的配置,增加系统的IO总吞吐量,降低平均IO延时,这对于大系统上做PG优化十分重要。
