
当前,基于LSM架构的存储系统很常见,对该架构来说,compaction(合并)是一个重要操作,本文带你了解compaction相关知识。10年前 Google 发表 BigTable的论文,推动了基于LSM的系统架构的流行,用户数据写入先写WAL,再写 Memtable,满足一定条件后冻结Memtable,执行转储操作形成一个数据文件SSTable。随着数据写入不断增多,转储次数也会不断增多,进而转储SSTable也会越来越多。然而,太多SSTable会导致数据查询IO次数增多,因此后台尝试着不断对这些 SSTable 进行合并,这个合并过程称为 Compaction。Compaction 分为两类:Minor Compaction 和 Major Compaction。Minor Compaction 是指选取一个或多个小的、相邻的转储 SSTable 与0个或多个 Frozen Memtable,将它们合并成一个更大的SSTable。一次 Minor Compaction 的结果是更少并且更大的 SSTable。Major Compaction是指将所有的转储SSTable和一个或多个Frozen Memtable合并成一个 SSTable,这个过程会清理被删除的数据。一般情况下,Major Compaction 时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。
通常 Compaction 涉及到三个放大因子,Compaction 需要在三者之间做取舍。Write Amplification : 写放大,假设每秒写入10MB的数据,但观察到硬盘的写入是30MB/s,那么写放大就是3。写分为立即写和延迟写,比如 redo log是立即写,传统基于B-Tree数据库刷脏页和 LSM Compaction 是延迟写。redo log 使用 direct IO 写时至少以512字节对齐,假如 log 记录为100字节,磁盘需要写入512字节,写放大为5。Read Amplification : 读放大,对应于一个简单 query 需要读取硬盘的次数。比如一个简单 query 读取了5个页面,发生了5次IO,那么读放大就是 5。假如B-Tree 非叶子节点都缓存在内存中,point read-amp 为1,一次磁盘读取就可以获取到 Leaf Block;short range read-amp 为1~2,1~2次磁盘读取可以获取到所需的Leaf Block。Space Amplification : 空间放大,假设我需要存储10MB数据,但实际硬盘占用了30MB,那么空间放大就是3。有比较多的因素会影响空间放大,比如在Compaction 过程中需要临时存储空间,空间碎片,Block中有效数据的比例小,旧版本数据未及时删除等等。最近几年很多论文对LSM写放大有比较多的研究,而对于写放大本身而言,是一个很古老的问题,在计算机体系中,如果相邻两层的处理单元不一致或者应用对一致性等有特殊的需求,就很可能出现写放大问题。比如 CPU Cache 和内存 cell,文件系统 Block 和磁盘扇区,数据库 Block 和文件系统 Block,数据库redo/undo,文件系统 journal 等。下图是 PebblesDB 论文中测试了几款流行KV的放大系数对比:
RocksDB 放大系数高达42倍,LevelDB也高达27倍。写放大意味着更多的读写,会造成系统性能波动,比如对SSD来说会加速寿命衰减,从成本角度说也更加耗电,采用更优的避免写放大的算法可以使用成本更低廉的SSD,写放大还影响数据库系统的持续写入的带宽,假如磁盘带宽为500M/s,写放大为10,那么数据库持续写入的的最大带宽为50M/s,所以解决写放大就成了一个很重要的问题。Facebook在Fast 14提交的论文《Analysis of HDFS Under HBase: A Facebook Messages Case Study》所提供的一些测试结论:在Facebook Messages业务系统中,业务读写比为99:1,而最终反映到磁盘中,读写比却变为了36:64。放大问题的本质是一个系统对“随时全局有序"的需求有多么的强烈。所谓随时,就是任何的写入都不能导致系统无序;所谓全局,即系统内任意元单位之间都要保持有序。B-Tree系列是随时全局有序的典型代表,而Fractal Tree打破了全局的约束,允许局部无序,提升了随机写能力;LSM系列进一步打破了随时的约束,允许通过后台的Compaction来整理排序。在LSM这种依靠后台整理来保序的系统里面,系统对序的要求越强烈,写放大越严重。要同时将写放大,读放大,空间放大优化到最优是很难的,比如SSD内部的碎片整理,碎片越多,空间放大和读放大越严重,为了改善空间放大和读放大,将page中的有效数据拷贝到新的page里(copy-out),这样会带来写放大,如果page中有效数据率越低,那么空间放大越大,copy-out的写放大越低,反之,空间放大越小,copy-out写放大越大。
随着数据写入不断增加,Minor Freeze 不断触发,转储数据不断增多,一次查询可能需要越来越多的 IO 操作,读取延时也在不断变大。而执行 Minor Compaction 会使得转储文件数基本稳定,进而IO Seek次数会比较稳定,延迟就会稳定在一定范围。然而,Minor Compaction 操作重写文件会带来很大的带宽压力以及短时间IO压力。因此可以认为,Minor Compaction 就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。为了换取后续查询的低延迟,除了短时间的读放大之外,Compaction对写入也会有很大的影响。当写请求非常多,导致不断触发 Minor Compaction 生成转储 SSTable,多次 Minor Freeze 会触发Major Freeze,从而导致 Major Compaction,但 Compaction 的速度远远跟不上数据写入速度,Memtable 内存不足时,会限制用户数据写入。如果 Compaction 消耗大量IO和带宽,也会导致读性能急剧下降。为了避免这种情况,在 Memtable 内存紧张时候会限制写请求的速度。Minor Compaction 释放Memtable 内存,清理不必要的多版本数据,同时保证转储 SSTable 数量稳定,降低读延迟;Major Compaction 清除删除和过期的数据,有效降低存储空间,也可以有效降低读取时延。Compaction 会使得数据读取延迟一直比较平稳,但付出的代价是大量的读延迟毛刺和一定的写阻塞。
Compaction 的设计总是会追求一个平衡点,一方面需要保证 Compaction的基本效果,另一方面又不会带来严重的IO压力。然而,并没有一种设计策略能够适用于所有应用场景或所有数据集。Compaction 选择什么样的策略需要根据不同的业务场景、不同数据集特征进行确定。设计 Compaction 策略需要根据业务数据特点,目标就是降低各种放大,不断权衡如下几点:合理控制读放大:避免因 Minor Freeze 增多导致读取时延出现明显增大,避免请求读取过多SSTable;合理控制写放大:避免一次又一次地 Compact 相同的数据;合理控制空间放大:避免让不需要的多版本数据,已经删除的数据和过期的数据长时间占据存储空间,避免在 Compaction 过程中占用过多临时存储空间,及时释放已经 Compact 完成的无用 SSTable 的存储空间;控制 Compaction 使用的资源:在业务高峰期少使用资源,业务低峰期使用更多的资源;控制 Compaction 平滑度:在一定的负载下,业务的响应时间和吞吐量稳定可预期; Memtable(增量数据) + L1(基线数据)
这是一种比较理想的场景,机器的内存比较大,磁盘空间和业务数据比较小,业务每天的修改几乎可以全部存储在 Memtable 中,采用每日Major Compaction 的方式将增量数据与基线数据进行合并,如下图所示: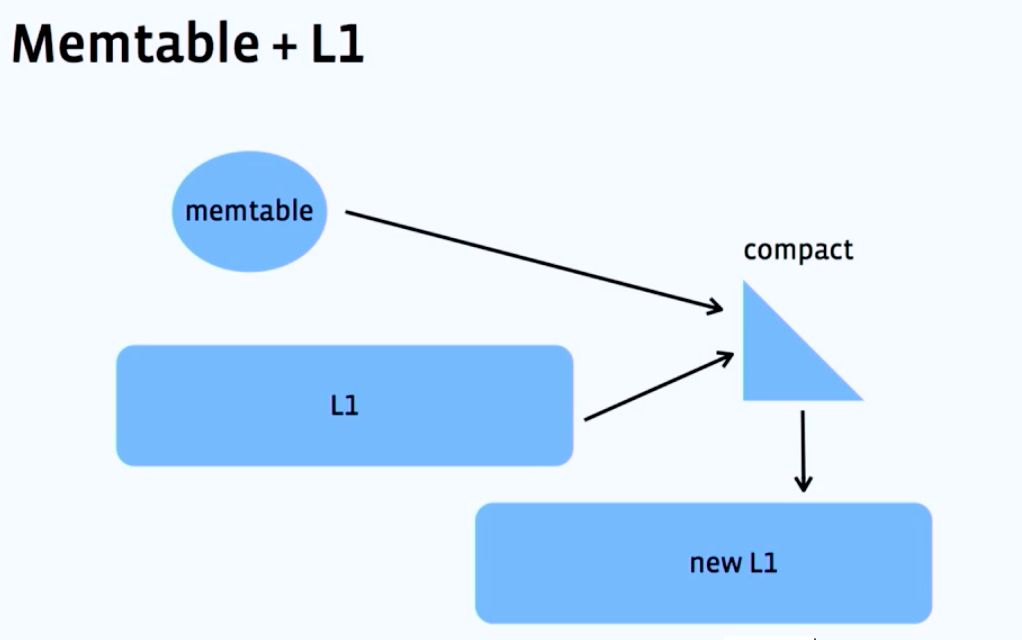
每张表包含一个增量数据 Memtable 和一个基线数据 SSTable,这种每日Major Compaction算法比较简单,point read-amp为1,short range read-amp为1,空间放大为1,写放大为 sizeof(database) / sizeof(memtable) + 1。这种 Compaction 算法保证最优读放大和空间放大,在Memtable内存比较大,磁盘空间和业务数据不大的情况下,写放大也可以接受,但随着业务数据量的增长,采用压缩率更高的压缩算法,以及单机存储空间的快速增长,写放大变得非常巨大,每日 Major Compaction 的速度变得越来越慢。 Memtable(增量数据)+L0(增量转储数据)+L1(基线数据)
随着业务的发展,每日更新的数据越来越大,Memtable 已经不能存储整天的修改数据,当系统内存紧张时,触发 Minor Freeze,然后转储生成SSTable,如下图所示: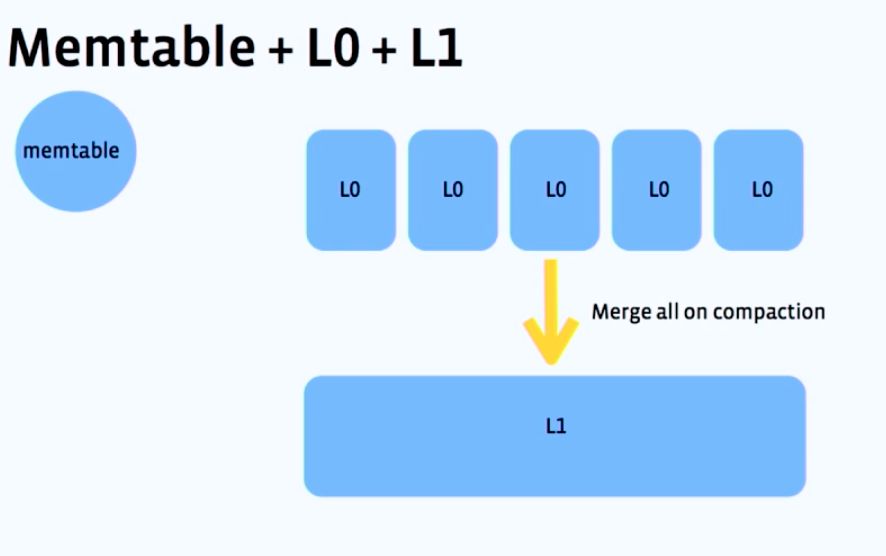
point read-amp为>=1次磁盘读取和多次 bloomfilter 过滤,short range read-amp 为L0+L1 SSTable数量总和次磁盘读取,写放大为 sizeof(database) / sizeof(每日增量数据量) + 2 (redo log,L0);最近几年单机的内存量几乎没有增加,但业务基线数据总量和每天的增量数据增长巨大,所以使用每日Major Compaction算法写放大非常大。随着L0层SSTable个数增加,读放大不断增加,为了限制L0层SSTable的个数,当转储达到一定次数后,发起一次Major Freeze,然后启动Major Compaction。这种策略会导致每天需要执行多次Major Compaction,随着基线数据量的增长,写放大越来越大,Major Compaction也越来越慢。
在不同的场景如何折中选择读放大,写放大和空间放大呢?在系统中统一采用一种 Compaction 策略往往比较难兼顾各种细节需求,而针对不同表配置不同的Compaction 策略能更好的适应表的读写负载。
Workload | Compaction策略 |
递增rowkey的insert/update/delete,无论读写比例多少 | 最优写放大和空间放大,无读放大,采用Memtable + L1模式,如果delete range比较多,则在Memtable中标记delete range。 |
write only,大量随机rowkey insert/update/delete | 优化写放大,采用Memtable + L0 + L1模式,每次转储生成一个SSTable,L0的总大小与L1相同时进行Major Compaction写放大最小。 |
write mostly,大量随机rowkey insert/update/delete | 优化写放大,容忍稍大的读放大,采用Memtable + L0 + L1模式,L0层累积多次Major Freeze的增量SSTable数据,L0层包含多个SSTable,按照优化写放大策略控制L0层SSTable数量和大小,使用Stripe Compaction和渐进合并策略减少Major Compaction的写放大和临时空间放大。 |
read only,或write很少 | 最优写放大,读放大和空间放大,采用Memtable + L1模式,Memtable没有数据或只有少量数据。 |
read mostly,少量随机rowkey insert/update/delete | 优化读放大,采用Memtable + L0 + L1模式,每次转储Frozen Memtable与前一个L0层SSTable合并成一个新的L0层SSTable,如果delete range比较多,则在Memtable和L0层SSTable中标记delete range,L0与L1进行Major Compaction的写放大比较小。 |
read mostly,大量随机rowkey insert/update/delete | 优化写放大和读放大,采用Memtable + L0 + L1模式,L0层累积多次Major Freeze的增量SSTable数据,L0层包含多个SSTable,根据用户的访问热点决定哪些range内的L0层SSTable合并,如果delete range比较多,则在Memtable和L0层SSTable中标记delete range,将L0和L1分成多个sub-range条带,每个sub-range积累了足够增量数据后才进行Major Compaction,类似渐进合并的方式,每次Major Freeze都合并L0和L1的部分range数据。如果delete比较多,空间放大不优,不能即使释放已经删除数据的存储空间。 |





